 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Stack Temperature Scaling
Nov 18, 2022



Recent works demonstrate that early layers in a neural network contain useful information for prediction. Inspired by this, we show that extending temperature scaling across all layers improves both calibration and accuracy. We call this procedure "layer-stack temperature scaling" (LATES). Informally, LATES grants each layer a weighted vote during inference. We evaluate it on five popular convolutional neural network architectures both in- and out-of-distribution and observe a consistent improvement over temperature scaling in terms of accuracy, calibration, and AUC. All conclusions are supported by comprehensive statistical analyses. Since LATES neither retrains the architecture nor introduces many more parameters, its advantages can be reaped without requiring additional data beyond what is used in temperature scaling. Finally, we show that combining LATES with Monte Carlo Dropout matches state-of-the-art results on CIFAR10/100.
Teaching Algorithmic Reasoning via In-context Learning
Nov 15, 2022



Large language models (LLMs) have shown increasing in-context learning capabilities through scaling up model and data size. Despite this progress, LLMs are still unable to solve algorithmic reasoning problems. While providing a rationale with the final answer has led to further improvements in multi-step reasoning problems, Anil et al. 2022 showed that even simple algorithmic reasoning tasks such as parity are far from solved. In this work, we identify and study four key stages for successfully teaching algorithmic reasoning to LLMs: (1) formulating algorithms as skills, (2) teaching multiple skills simultaneously (skill accumulation), (3) teaching how to combine skills (skill composition) and (4) teaching how to use skills as tools. We show that it is possible to teach algorithmic reasoning to LLMs via in-context learning, which we refer to as algorithmic prompting. We evaluate our approach on a variety of arithmetic and quantitative reasoning tasks, and demonstrate significant boosts in performance over existing prompting techniques. In particular, for long parity, addition, multiplication and subtraction, we achieve an error reduction of approximately 10x, 9x, 5x and 2x respectively compared to the best available baselines.
REPAIR: REnormalizing Permuted Activations for Interpolation Repair
Nov 15, 2022



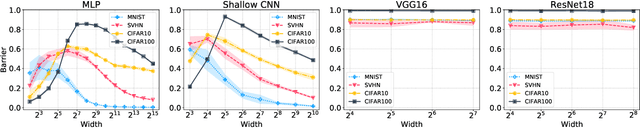
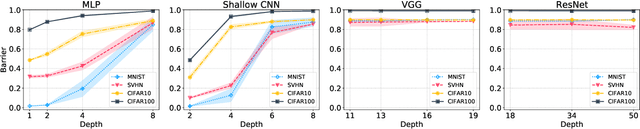
In this paper we look into the conjecture of Entezari et al.(2021) which states that if the permutation invariance of neural networks is taken into account, then there is likely no loss barrier to the linear interpolation between SGD solutions. First, we observe that neuron alignment methods alone are insufficient to establish low-barrier linear connectivity between SGD solutions due to a phenomenon we call variance collapse: interpolated deep networks suffer a collapse in the variance of their activations, causing poor performance. Next, we propose REPAIR (REnormalizing Permuted Activations for Interpolation Repair) which mitigates variance collapse by rescaling the preactivations of such interpolated networks. We explore the interaction between our method and the choice of normalization layer, network width, and depth, and demonstrate that using REPAIR on top of neuron alignment methods leads to 60%-100% relative barrier reduction across a wide variety of architecture families and tasks. In particular, we report a 74% barrier reduction for ResNet50 on ImageNet and 90% barrier reduction for ResNet18 on CIFAR10.
Understanding the effect of sparsity on neural networks robustness
Jun 22, 2022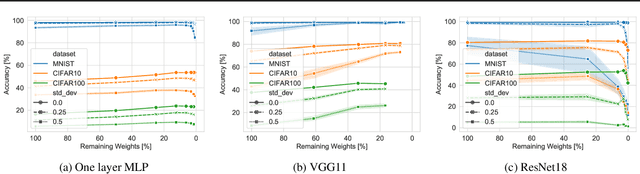
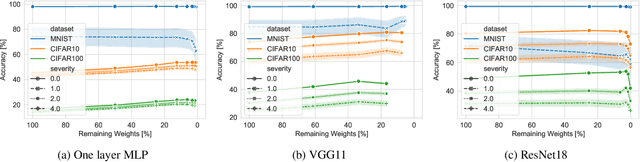
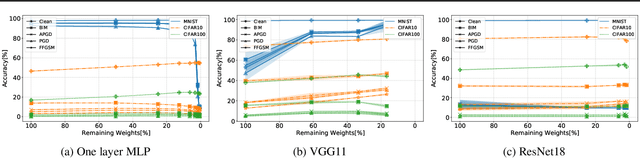
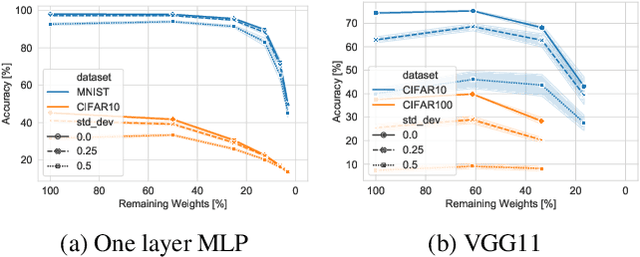
This paper examines the impact of static sparsity on the robustness of a trained network to weight perturbations, data corruption, and adversarial examples. We show that, up to a certain sparsity achieved by increasing network width and depth while keeping the network capacity fixed, sparsified networks consistently match and often outperform their initially dense versions. Robustness and accuracy decline simultaneously for very high sparsity due to loose connectivity between network layers. Our findings show that a rapid robustness drop caused by network compression observed in the literature is due to a reduced network capacity rather than sparsity.
Leveraging Unlabeled Data to Predict Out-of-Distribution Performance
Feb 09, 2022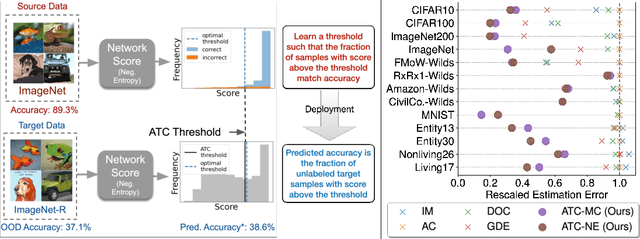
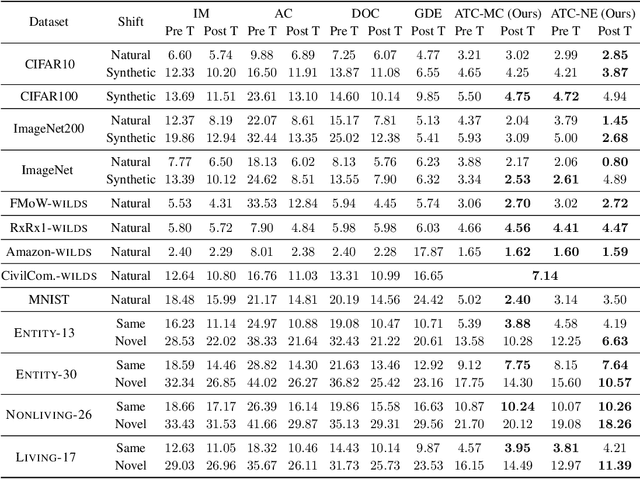
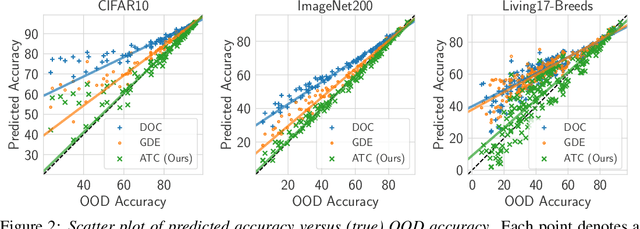
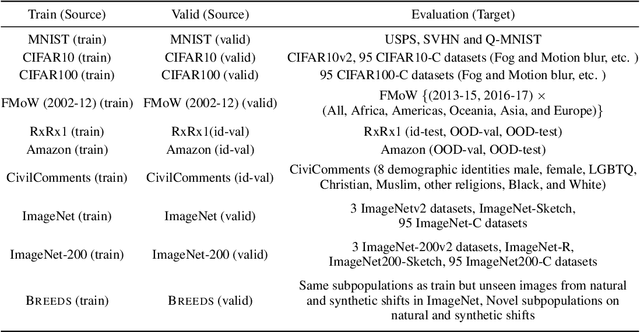
Real-world machine learning deployments are characterized by mismatches between the source (training) and target (test) distributions that may cause performance drops. In this work, we investigate methods for predicting the target domain accuracy using only labeled source data and unlabeled target data. We propose Average Thresholded Confidence (ATC), a practical method that learns a threshold on the model's confidence, predicting accuracy as the fraction of unlabeled examples for which model confidence exceeds that threshold. ATC outperforms previous methods across several model architectures, types of distribution shifts (e.g., due to synthetic corruptions, dataset reproduction, or novel subpopulations), and datasets (Wilds, ImageNet, Breeds, CIFAR, and MNIST). In our experiments, ATC estimates target performance $2$-$4\times$ more accurately than prior methods. We also explore the theoretical foundations of the problem, proving that, in general, identifying the accuracy is just as hard as identifying the optimal predictor and thus, the efficacy of any method rests upon (perhaps unstated) assumptions on the nature of the shift. Finally, analyzing our method on some toy distributions, we provide insights concerning when it works.
The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks
Oct 12, 2021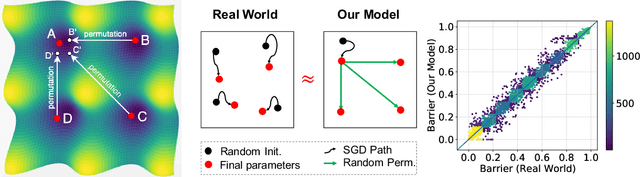
In this paper, we conjecture that if the permutation invariance of neural networks is taken into account, SGD solutions will likely have no barrier in the linear interpolation between them. Although it is a bold conjecture, we show how extensive empirical attempts fall short of refuting it. We further provide a preliminary theoretical result to support our conjecture. Our conjecture has implications for lottery ticket hypothesis, distributed training, and ensemble methods.
Exploring the Limits of Large Scale Pre-training
Oct 05, 2021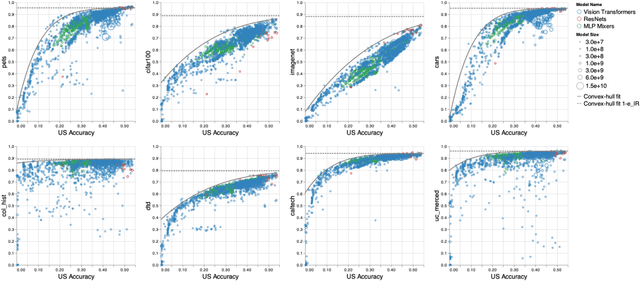
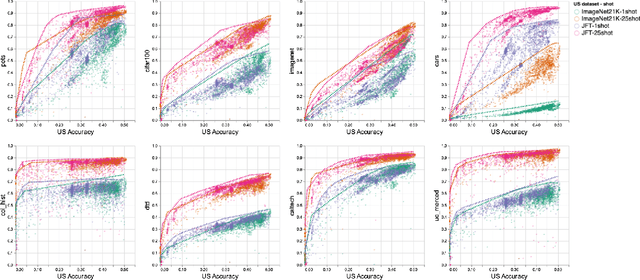
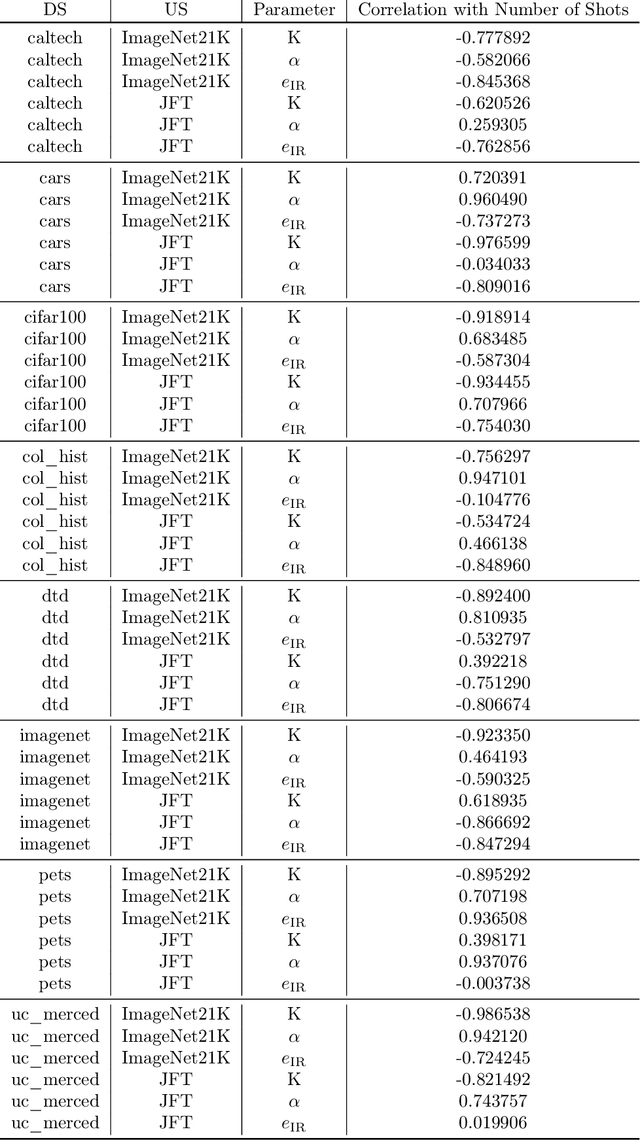
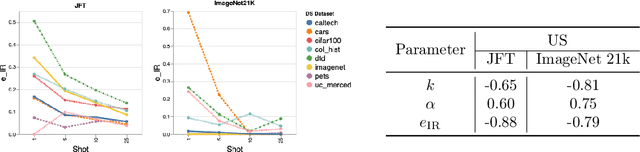
Recent developments in large-scale machine learning suggest that by scaling up data, model size and training time properly, one might observe that improvements in pre-training would transfer favorably to most downstream tasks. In this work, we systematically study this phenomena and establish that, as we increase the upstream accuracy, the performance of downstream tasks saturates. In particular, we investigate more than 4800 experiments on Vision Transformers, MLP-Mixers and ResNets with number of parameters ranging from ten million to ten billion, trained on the largest scale of available image data (JFT, ImageNet21K) and evaluated on more than 20 downstream image recognition tasks. We propose a model for downstream performance that reflects the saturation phenomena and captures the nonlinear relationship in performance of upstream and downstream tasks. Delving deeper to understand the reasons that give rise to these phenomena, we show that the saturation behavior we observe is closely related to the way that representations evolve through the layers of the models. We showcase an even more extreme scenario where performance on upstream and downstream are at odds with each other. That is, to have a better downstream performance, we need to hurt upstream accuracy.
Gradual Domain Adaptation in the Wild:When Intermediate Distributions are Absent
Jun 10, 2021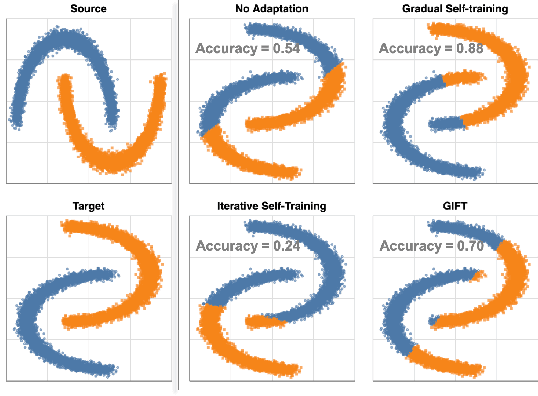
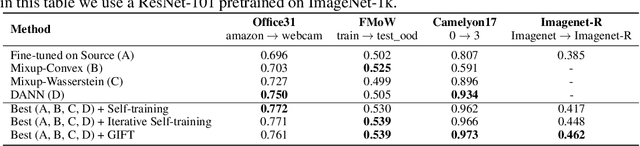

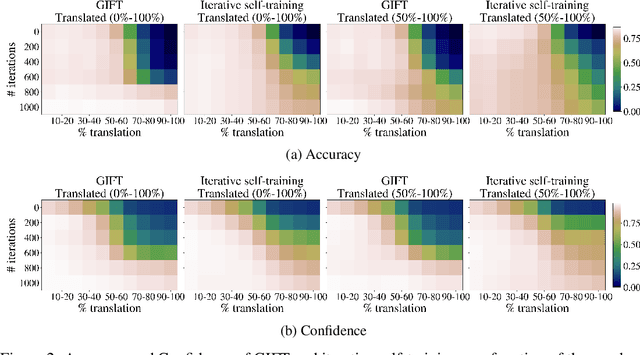
We focus on the problem of domain adaptation when the goal is shifting the model towards the target distribution, rather than learning domain invariant representations. It has been shown that under the following two assumptions: (a) access to samples from intermediate distributions, and (b) samples being annotated with the amount of change from the source distribution, self-training can be successfully applied on gradually shifted samples to adapt the model toward the target distribution. We hypothesize having (a) is enough to enable iterative self-training to slowly adapt the model to the target distribution, by making use of an implicit curriculum. In the case where (a) does not hold, we observe that iterative self-training falls short. We propose GIFT, a method that creates virtual samples from intermediate distributions by interpolating representations of examples from source and target domains. We evaluate an iterative-self-training method on datasets with natural distribution shifts, and show that when applied on top of other domain adaptation methods, it improves the performance of the model on the target dataset. We run an analysis on a synthetic dataset to show that in the presence of (a) iterative-self-training naturally forms a curriculum of samples. Furthermore, we show that when (a) does not hold, GIFT performs better than iterative self-training.
The Deep Bootstrap: Good Online Learners are Good Offline Generalizers
Oct 16, 2020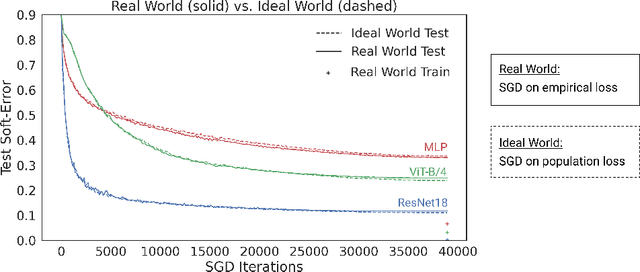

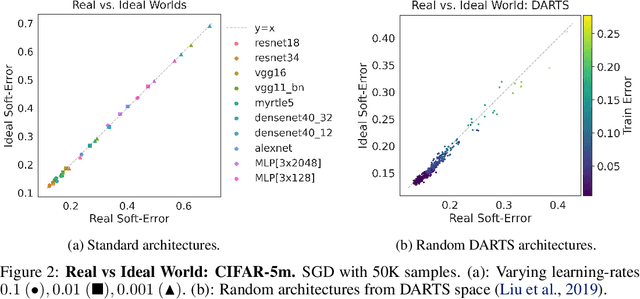

We propose a new framework for reasoning about generalization in deep learning. The core idea is to couple the Real World, where optimizers take stochastic gradient steps on the empirical loss, to an Ideal World, where optimizers take steps on the population loss. This leads to an alternate decomposition of test error into: (1) the Ideal World test error plus (2) the gap between the two worlds. If the gap (2) is universally small, this reduces the problem of generalization in offline learning to the problem of optimization in online learning. We then give empirical evidence that this gap between worlds can be small in realistic deep learning settings, in particular supervised image classification. For example, CNNs generalize better than MLPs on image distributions in the Real World, but this is "because" they optimize faster on the population loss in the Ideal World. This suggests our framework is a useful tool for understanding generalization in deep learning, and lays a foundation for future research in the area.
What is being transferred in transfer learning?
Aug 26, 2020
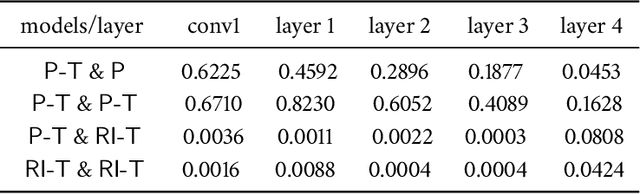

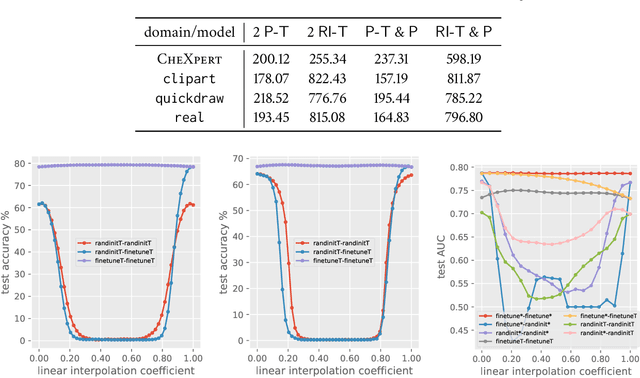
One desired capability for machines is the ability to transfer their knowledge of one domain to another where data is (usually) scarce. Despite ample adaptation of transfer learning in various deep learning applications, we yet do not understand what enables a successful transfer and which part of the network is responsible for that. In this paper, we provide new tools and analyses to address these fundamental questions. Through a series of analyses on transferring to block-shuffled images, we separate the effect of feature reuse from learning low-level statistics of data and show that some benefit of transfer learning comes from the latter. We present that when training from pre-trained weights, the model stays in the same basin in the loss landscape and different instances of such model are similar in feature space and close in parameter space.