 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Face-to-Face Neural Conversation Model
Dec 04, 2018
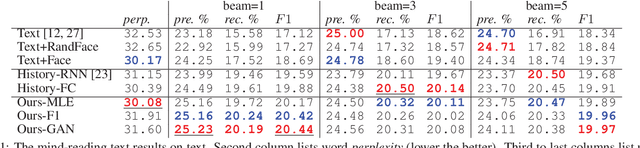

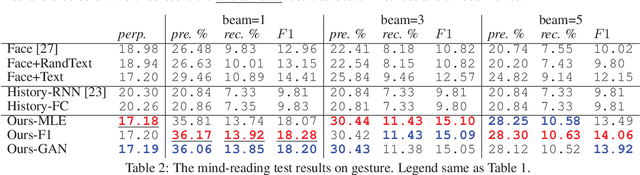
Neural networks have recently become good at engaging in dialog. However, current approaches are based solely on verbal text, lacking the richness of a real face-to-face conversation. We propose a neural conversation model that aims to read and generate facial gestures alongside with text. This allows our model to adapt its response based on the "mood" of the conversation. In particular, we introduce an RNN encoder-decoder that exploits the movement of facial muscles, as well as the verbal conversation. The decoder consists of two layers, where the lower layer aims at generating the verbal response and coarse facial expressions, while the second layer fills in the subtle gestures, making the generated output more smooth and natural. We train our neural network by having it "watch" 250 movies. We showcase our joint face-text model in generating more natural conversations through automatic metrics and a human study. We demonstrate an example application with a face-to-face chatting avatar.
* Published at CVPR 2018
SurfConv: Bridging 3D and 2D Convolution for RGBD Images
Dec 04, 2018
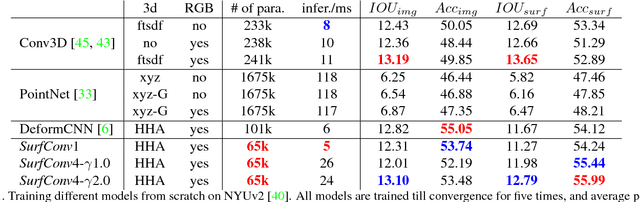
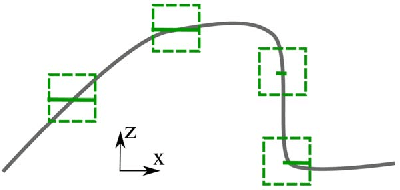
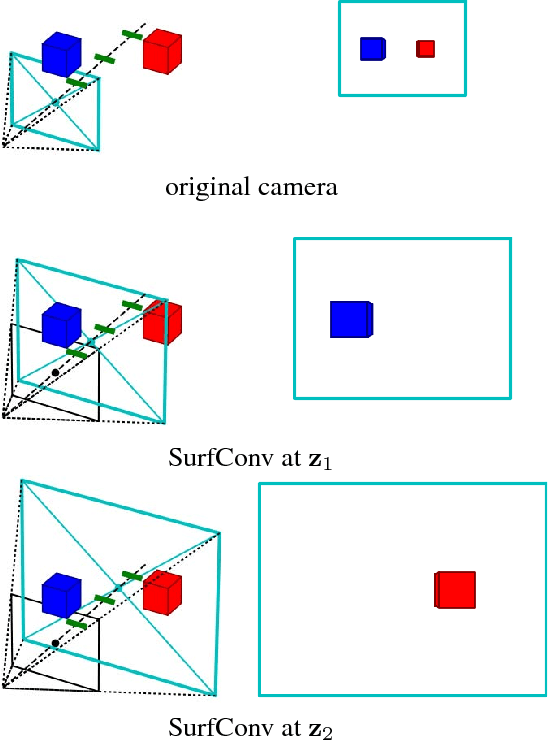
We tackle the problem of using 3D information in convolutional neural networks for down-stream recognition tasks. Using depth as an additional channel alongside the RGB input has the scale variance problem present in image convolution based approaches. On the other hand, 3D convolution wastes a large amount of memory on mostly unoccupied 3D space, which consists of only the surface visible to the sensor. Instead, we propose SurfConv, which "slides" compact 2D filters along the visible 3D surface. SurfConv is formulated as a simple depth-aware multi-scale 2D convolution, through a new Data-Driven Depth Discretization (D4) scheme. We demonstrate the effectiveness of our method on indoor and outdoor 3D semantic segmentation datasets. Our method achieves state-of-the-art performance with less than 30% parameters used by the 3D convolution-based approaches.
* Published at CVPR 2018
TorontoCity: Seeing the World with a Million Eyes
Dec 01, 2016
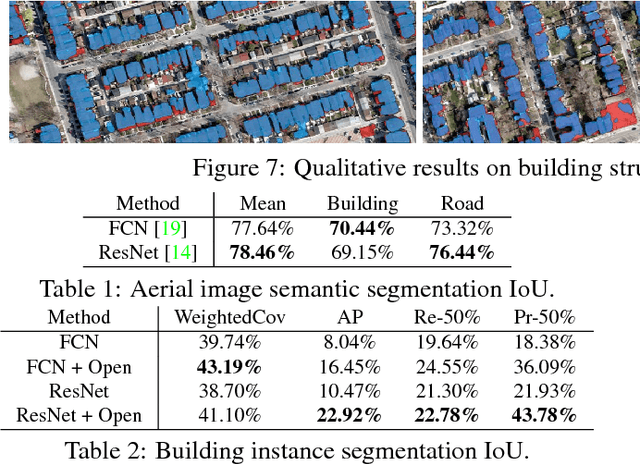
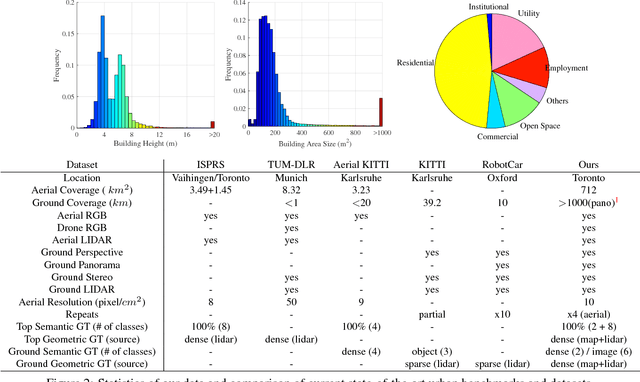

In this paper we introduce the TorontoCity benchmark, which covers the full greater Toronto area (GTA) with 712.5 $km^2$ of land, 8439 $km$ of road and around 400,000 buildings. Our benchmark provides different perspectives of the world captured from airplanes, drones and cars driving around the city. Manually labeling such a large scale dataset is infeasible. Instead, we propose to utilize different sources of high-precision maps to create our ground truth. Towards this goal, we develop algorithms that allow us to align all data sources with the maps while requiring minimal human supervision. We have designed a wide variety of tasks including building height estimation (reconstruction), road centerline and curb extraction, building instance segmentation, building contour extraction (reorganization), semantic labeling and scene type classification (recognition). Our pilot study shows that most of these tasks are still difficult for modern convolutional neural networks.
Song From PI: A Musically Plausible Network for Pop Music Generation
Nov 10, 2016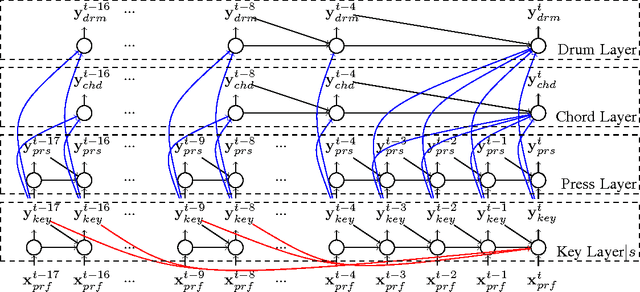


We present a novel framework for generating pop music. Our model is a hierarchical Recurrent Neural Network, where the layers and the structure of the hierarchy encode our prior knowledge about how pop music is composed. In particular, the bottom layers generate the melody, while the higher levels produce the drums and chords. We conduct several human studies that show strong preference of our generated music over that produced by the recent method by Google. We additionally show two applications of our framework: neural dancing and karaoke, as well as neural story singing.
Accurate Vision-based Vehicle Localization using Satellite Imagery
Oct 30, 2015
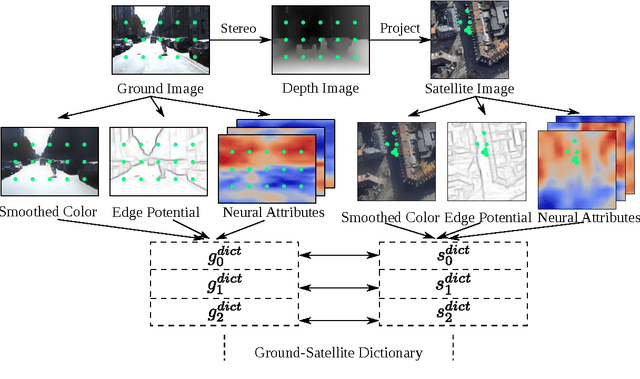

We propose a method for accurately localizing ground vehicles with the aid of satellite imagery. Our approach takes a ground image as input, and outputs the location from which it was taken on a georeferenced satellite image. We perform visual localization by estimating the co-occurrence probabilities between the ground and satellite images based on a ground-satellite feature dictionary. The method is able to estimate likelihoods over arbitrary locations without the need for a dense ground image database. We present a ranking-loss based algorithm that learns location-discriminative feature projection matrices that result in further improvements in accuracy. We evaluate our method on the Malaga and KITTI public datasets and demonstrate significant improvements over a baseline that performs exhaustive search.
A Heat-Map-based Algorithm for Recognizing Group Activities in Videos
Feb 21, 2015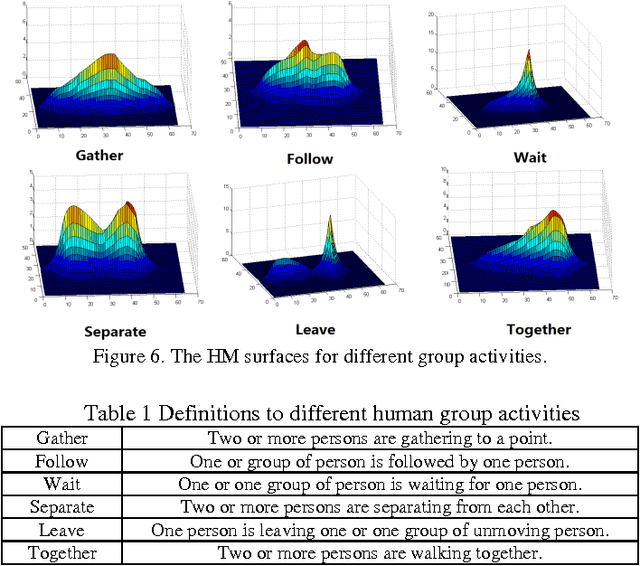
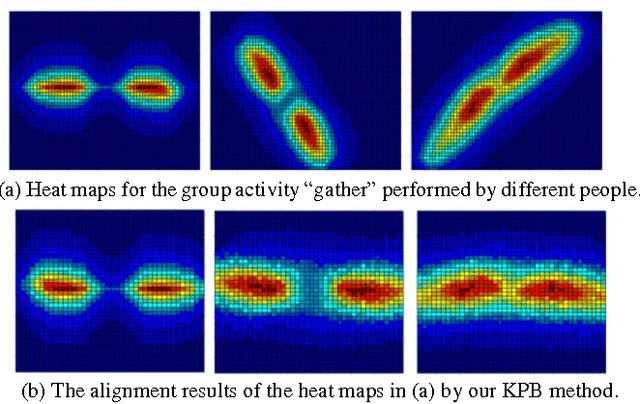
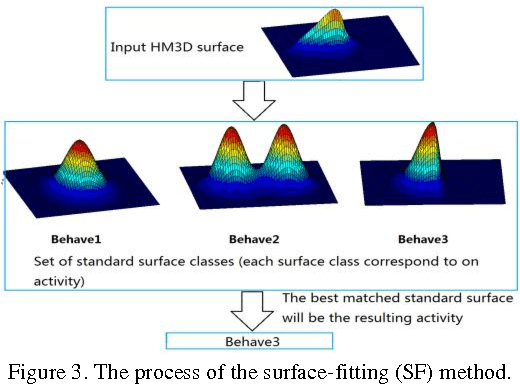
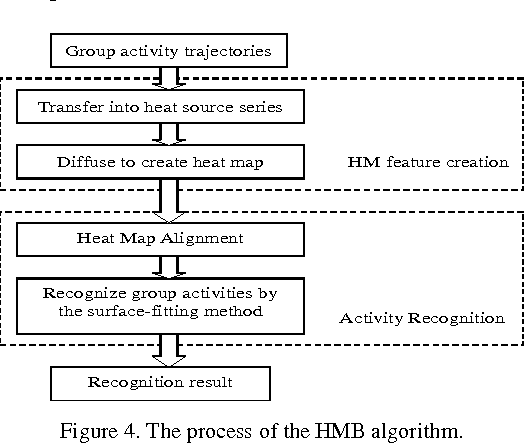
In this paper, a new heat-map-based (HMB) algorithm is proposed for group activity recognition. The proposed algorithm first models human trajectories as series of "heat sources" and then applies a thermal diffusion process to create a heat map (HM) for representing the group activities. Based on this heat map, a new key-point based (KPB) method is used for handling the alignments among heat maps with different scales and rotations. And a surface-fitting (SF) method is also proposed for recognizing group activities. Our proposed HM feature can efficiently embed the temporal motion information of the group activities while the proposed KPB and SF methods can effectively utilize the characteristics of the heat map for activity recognition. Experimental results demonstrate the effectiveness of our proposed algorithms.
* This manuscript is the accepted version for TCSVT(IEEE Transactions on Circuits and Systems for Video Technology)