 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact3D: Compressing Gaussian Splat Radiance Field Models with Vector Quantization
Nov 30, 20233D Gaussian Splatting is a new method for modeling and rendering 3D radiance fields that achieves much faster learning and rendering time compared to SOTA NeRF methods. However, it comes with a drawback in the much larger storage demand compared to NeRF methods since it needs to store the parameters for several 3D Gaussians. We notice that many Gaussians may share similar parameters, so we introduce a simple vector quantization method based on \kmeans algorithm to quantize the Gaussian parameters. Then, we store the small codebook along with the index of the code for each Gaussian. Moreover, we compress the indices further by sorting them and using a method similar to run-length encoding. We do extensive experiments on standard benchmarks as well as a new benchmark which is an order of magnitude larger than the standard benchmarks. We show that our simple yet effective method can reduce the storage cost for the original 3D Gaussian Splatting method by a factor of almost $20\times$ with a very small drop in the quality of rendered images.
BrainWash: A Poisoning Attack to Forget in Continual Learning
Nov 24, 2023



Continual learning has gained substantial attention within the deep learning community, offering promising solutions to the challenging problem of sequential learning. Yet, a largely unexplored facet of this paradigm is its susceptibility to adversarial attacks, especially with the aim of inducing forgetting. In this paper, we introduce "BrainWash," a novel data poisoning method tailored to impose forgetting on a continual learner. By adding the BrainWash noise to a variety of baselines, we demonstrate how a trained continual learner can be induced to forget its previously learned tasks catastrophically, even when using these continual learning baselines. An important feature of our approach is that the attacker requires no access to previous tasks' data and is armed merely with the model's current parameters and the data belonging to the most recent task. Our extensive experiments highlight the efficacy of BrainWash, showcasing degradation in performance across various regularization-based continual learning methods.
NOLA: Networks as Linear Combination of Low Rank Random Basis
Oct 04, 2023Large Language Models (LLMs) have recently gained popularity due to their impressive few-shot performance across various downstream tasks. However, fine-tuning all parameters and storing a unique model for each downstream task or domain becomes impractical because of the massive size of checkpoints (e.g., 350GB in GPT-3). Current literature, such as LoRA, showcases the potential of low-rank modifications to the original weights of an LLM, enabling efficient adaptation and storage for task-specific models. These methods can reduce the number of parameters needed to fine-tune an LLM by several orders of magnitude. Yet, these methods face two primary limitations: 1) the parameter reduction is lower-bounded by the rank one decomposition, and 2) the extent of reduction is heavily influenced by both the model architecture and the chosen rank. For instance, in larger models, even a rank one decomposition might exceed the number of parameters truly needed for adaptation. In this paper, we introduce NOLA, which overcomes the rank one lower bound present in LoRA. It achieves this by re-parameterizing the low-rank matrices in LoRA using linear combinations of randomly generated matrices (basis) and optimizing the linear mixture coefficients only. This approach allows us to decouple the number of trainable parameters from both the choice of rank and the network architecture. We present adaptation results using GPT-2 and ViT in natural language and computer vision tasks. NOLA performs as well as, or better than models with equivalent parameter counts. Furthermore, we demonstrate that we can halve the parameters in larger models compared to LoRA with rank one, without sacrificing performance.
SlowFormer: Universal Adversarial Patch for Attack on Compute and Energy Efficiency of Inference Efficient Vision Transformers
Oct 04, 2023Recently, there has been a lot of progress in reducing the computation of deep models at inference time. These methods can reduce both the computational needs and power usage of deep models. Some of these approaches adaptively scale the compute based on the input instance. We show that such models can be vulnerable to a universal adversarial patch attack, where the attacker optimizes for a patch that when pasted on any image, can increase the compute and power consumption of the model. We run experiments with three different efficient vision transformer methods showing that in some cases, the attacker can increase the computation to the maximum possible level by simply pasting a patch that occupies only 8\% of the image area. We also show that a standard adversarial training defense method can reduce some of the attack's success. We believe adaptive efficient methods will be necessary for the future to lower the power usage of deep models, so we hope our paper encourages the community to study the robustness of these methods and develop better defense methods for the proposed attack.
A Cookbook of Self-Supervised Learning
Apr 24, 2023



Self-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high barrier to entry. While many components are familiar, successfully training a SSL method involves a dizzying set of choices from the pretext tasks to training hyper-parameters. Our goal is to lower the barrier to entry into SSL research by laying the foundations and latest SSL recipes in the style of a cookbook. We hope to empower the curious researcher to navigate the terrain of methods, understand the role of the various knobs, and gain the know-how required to explore how delicious SSL can be.
Defending Against Patch-based Backdoor Attacks on Self-Supervised Learning
Apr 04, 2023



Recently, self-supervised learning (SSL) was shown to be vulnerable to patch-based data poisoning backdoor attacks. It was shown that an adversary can poison a small part of the unlabeled data so that when a victim trains an SSL model on it, the final model will have a backdoor that the adversary can exploit. This work aims to defend self-supervised learning against such attacks. We use a three-step defense pipeline, where we first train a model on the poisoned data. In the second step, our proposed defense algorithm (PatchSearch) uses the trained model to search the training data for poisoned samples and removes them from the training set. In the third step, a final model is trained on the cleaned-up training set. Our results show that PatchSearch is an effective defense. As an example, it improves a model's accuracy on images containing the trigger from 38.2% to 63.7% which is very close to the clean model's accuracy, 64.6%. Moreover, we show that PatchSearch outperforms baselines and state-of-the-art defense approaches including those using additional clean, trusted data. Our code is available at https://github.com/UCDvision/PatchSearch
Is Multi-Task Learning an Upper Bound for Continual Learning?
Oct 26, 2022



Continual and multi-task learning are common machine learning approaches to learning from multiple tasks. The existing works in the literature often assume multi-task learning as a sensible performance upper bound for various continual learning algorithms. While this assumption is empirically verified for different continual learning benchmarks, it is not rigorously justified. Moreover, it is imaginable that when learning from multiple tasks, a small subset of these tasks could behave as adversarial tasks reducing the overall learning performance in a multi-task setting. In contrast, continual learning approaches can avoid the performance drop caused by such adversarial tasks to preserve their performance on the rest of the tasks, leading to better performance than a multi-task learner. This paper proposes a novel continual self-supervised learning setting, where each task corresponds to learning an invariant representation for a specific class of data augmentations. In this setting, we show that continual learning often beats multi-task learning on various benchmark datasets, including MNIST, CIFAR-10, and CIFAR-100.
SimA: Simple Softmax-free Attention for Vision Transformers
Jun 17, 2022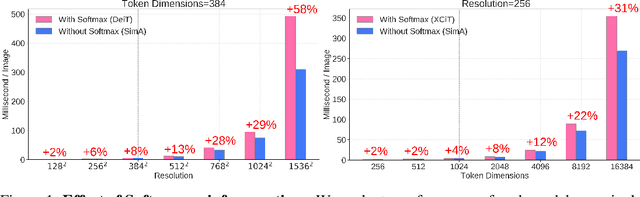
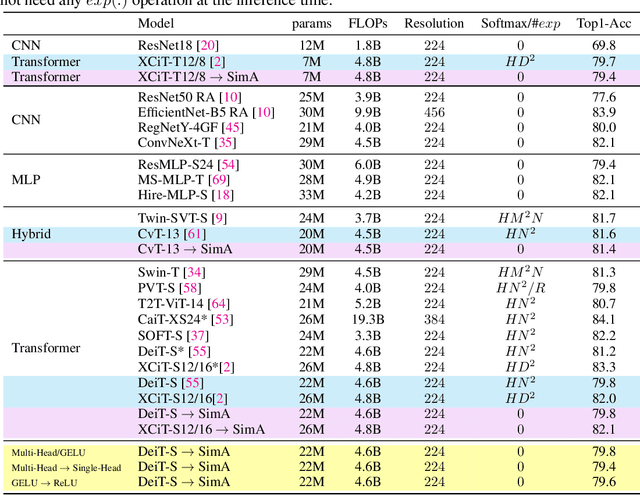
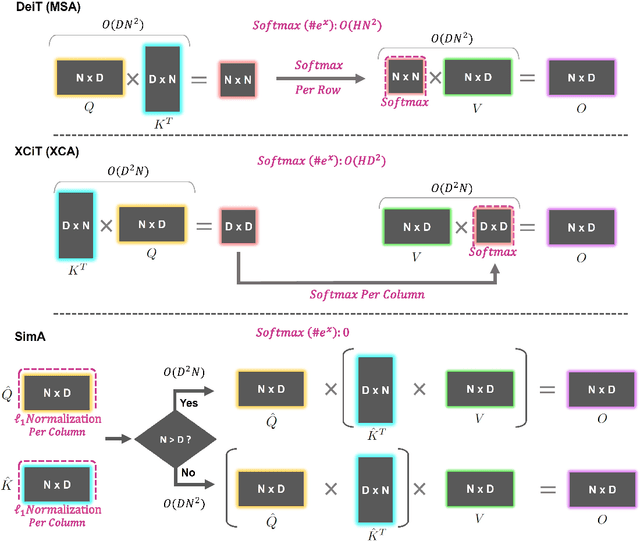
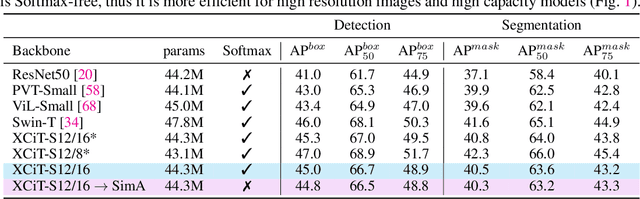
Recently, vision transformers have become very popular. However, deploying them in many applications is computationally expensive partly due to the Softmax layer in the attention block. We introduce a simple but effective, Softmax-free attention block, SimA, which normalizes query and key matrices with simple $\ell_1$-norm instead of using Softmax layer. Then, the attention block in SimA is a simple multiplication of three matrices, so SimA can dynamically change the ordering of the computation at the test time to achieve linear computation on the number of tokens or the number of channels. We empirically show that SimA applied to three SOTA variations of transformers, DeiT, XCiT, and CvT, results in on-par accuracy compared to the SOTA models, without any need for Softmax layer. Interestingly, changing SimA from multi-head to single-head has only a small effect on the accuracy, which simplifies the attention block further. The code is available here: $\href{https://github.com/UCDvision/sima}{\text{This https URL}}$
Backdoor Attacks on Vision Transformers
Jun 16, 2022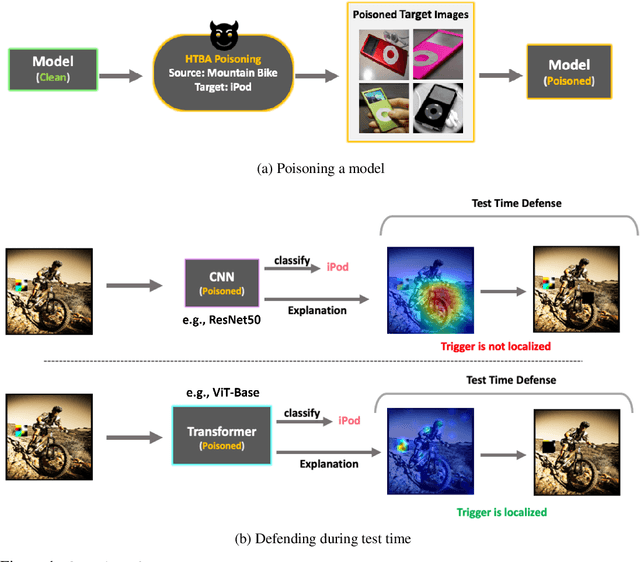
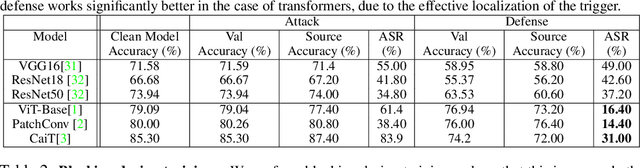


Vision Transformers (ViT) have recently demonstrated exemplary performance on a variety of vision tasks and are being used as an alternative to CNNs. Their design is based on a self-attention mechanism that processes images as a sequence of patches, which is quite different compared to CNNs. Hence it is interesting to study if ViTs are vulnerable to backdoor attacks. Backdoor attacks happen when an attacker poisons a small part of the training data for malicious purposes. The model performance is good on clean test images, but the attacker can manipulate the decision of the model by showing the trigger at test time. To the best of our knowledge, we are the first to show that ViTs are vulnerable to backdoor attacks. We also find an intriguing difference between ViTs and CNNs - interpretation algorithms effectively highlight the trigger on test images for ViTs but not for CNNs. Based on this observation, we propose a test-time image blocking defense for ViTs which reduces the attack success rate by a large margin. Code is available here: https://github.com/UCDvision/backdoor_transformer.git
PRANC: Pseudo RAndom Networks for Compacting deep models
Jun 16, 2022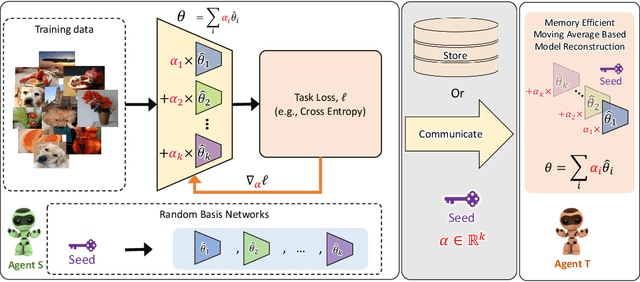
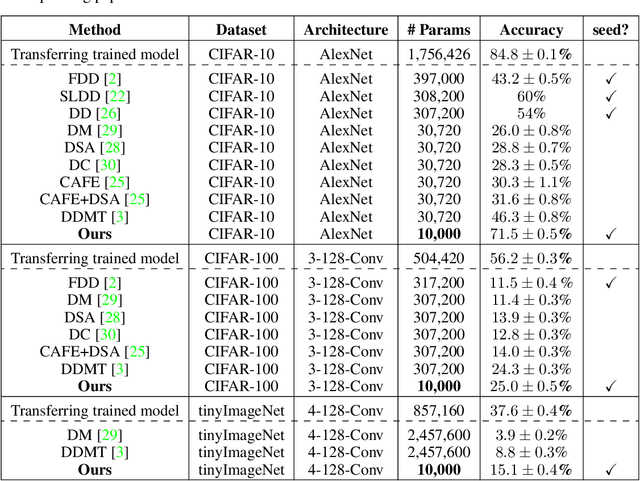
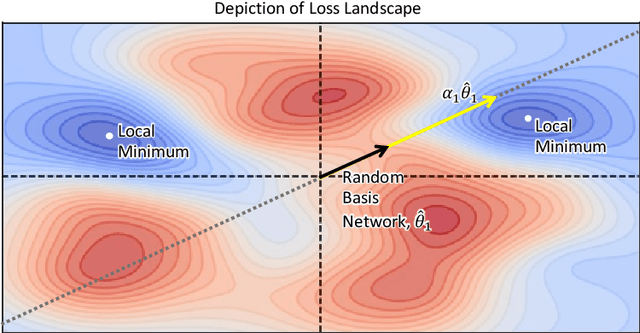
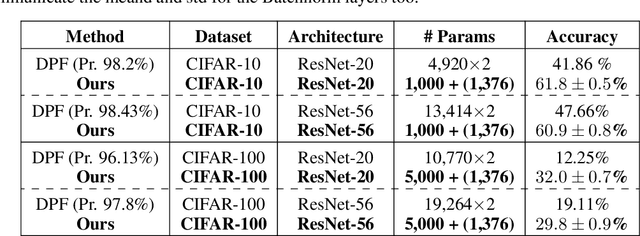
Communication becomes a bottleneck in various distributed Machine Learning settings. Here, we propose a novel training framework that leads to highly efficient communication of models between agents. In short, we train our network to be a linear combination of many pseudo-randomly generated frozen models. For communication, the source agent transmits only the `seed' scalar used to generate the pseudo-random `basis' networks along with the learned linear mixture coefficients. Our method, denoted as PRANC, learns almost $100\times$ fewer parameters than a deep model and still performs well on several datasets and architectures. PRANC enables 1) efficient communication of models between agents, 2) efficient model storage, and 3) accelerated inference by generating layer-wise weights on the fly. We test PRANC on CIFAR-10, CIFAR-100, tinyImageNet, and ImageNet-100 with various architectures like AlexNet, LeNet, ResNet18, ResNet20, and ResNet56 and demonstrate a massive reduction in the number of parameters while providing satisfactory performance on these benchmark datasets. The code is available \href{https://github.com/UCDvision/PRANC}{https://github.com/UCDvision/PRANC}