 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Deep Networks Transfer Invariances Across Classes?
Mar 18, 2022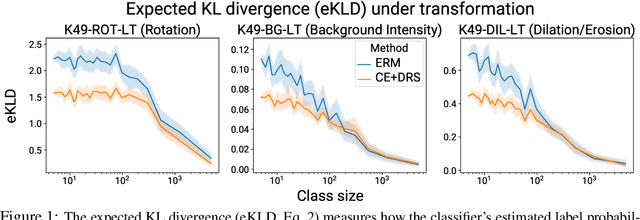
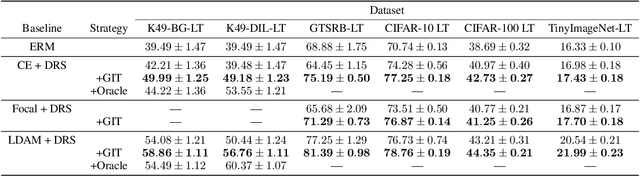
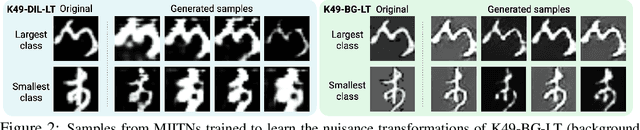
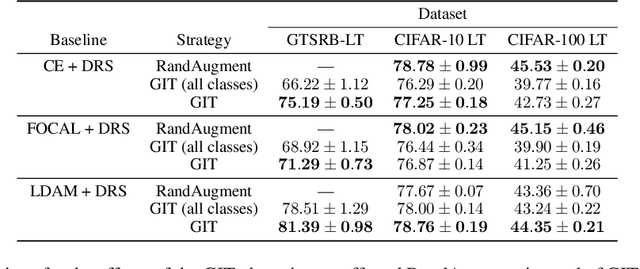
To generalize well, classifiers must learn to be invariant to nuisance transformations that do not alter an input's class. Many problems have "class-agnostic" nuisance transformations that apply similarly to all classes, such as lighting and background changes for image classification. Neural networks can learn these invariances given sufficient data, but many real-world datasets are heavily class imbalanced and contain only a few examples for most of the classes. We therefore pose the question: how well do neural networks transfer class-agnostic invariances learned from the large classes to the small ones? Through careful experimentation, we observe that invariance to class-agnostic transformations is still heavily dependent on class size, with the networks being much less invariant on smaller classes. This result holds even when using data balancing techniques, and suggests poor invariance transfer across classes. Our results provide one explanation for why classifiers generalize poorly on unbalanced and long-tailed distributions. Based on this analysis, we show how a generative approach for learning the nuisance transformations can help transfer invariances across classes and improve performance on a set of imbalanced image classification benchmarks. Source code for our experiments is available at https://github.com/AllanYangZhou/generative-invariance-transfer.
Binary Classification Under $\ell_0$ Attacks for General Noise Distribution
Mar 09, 2022Adversarial examples have recently drawn considerable attention in the field of machine learning due to the fact that small perturbations in the data can result in major performance degradation. This phenomenon is usually modeled by a malicious adversary that can apply perturbations to the data in a constrained fashion, such as being bounded in a certain norm. In this paper, we study this problem when the adversary is constrained by the $\ell_0$ norm; i.e., it can perturb a certain number of coordinates in the input, but has no limit on how much it can perturb those coordinates. Due to the combinatorial nature of this setting, we need to go beyond the standard techniques in robust machine learning to address this problem. We consider a binary classification scenario where $d$ noisy data samples of the true label are provided to us after adversarial perturbations. We introduce a classification method which employs a nonlinear component called truncation, and show in an asymptotic scenario, as long as the adversary is restricted to perturb no more than $\sqrt{d}$ data samples, we can almost achieve the optimal classification error in the absence of the adversary, i.e. we can completely neutralize adversary's effect. Surprisingly, we observe a phase transition in the sense that using a converse argument, we show that if the adversary can perturb more than $\sqrt{d}$ coordinates, no classifier can do better than a random guess.
Linear Stochastic Bandits over a Bit-Constrained Channel
Mar 02, 2022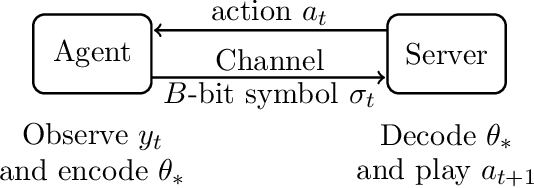
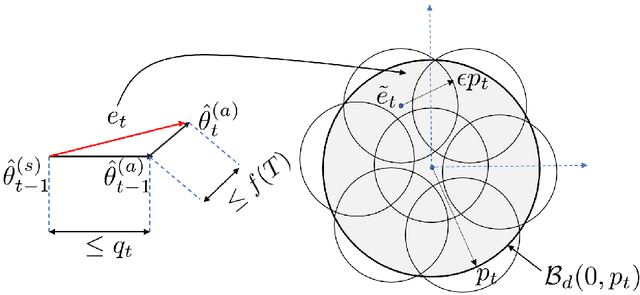
One of the primary challenges in large-scale distributed learning stems from stringent communication constraints. While several recent works address this challenge for static optimization problems, sequential decision-making under uncertainty has remained much less explored in this regard. Motivated by this gap, we introduce a new linear stochastic bandit formulation over a bit-constrained channel. Specifically, in our setup, an agent interacting with an environment transmits encoded estimates of an unknown model parameter to a server over a communication channel of finite capacity. The goal of the server is to take actions based on these estimates to minimize cumulative regret. To this end, we develop a novel and general algorithmic framework that hinges on two main components: (i) an adaptive encoding mechanism that exploits statistical concentration bounds, and (ii) a decision-making principle based on confidence sets that account for encoding errors. As our main result, we prove that when the unknown model is $d$-dimensional, a channel capacity of $O(d)$ bits suffices to achieve order-optimal regret. To demonstrate the generality of our approach, we then show that the same result continues to hold for non-linear observation models satisfying standard regularity conditions. Finally, we establish that for the simpler unstructured multi-armed bandit problem, $1$ bit channel-capacity is sufficient for achieving optimal regret bounds. Overall, our work takes a significant first step towards paving the way for statistical decision-making over finite-capacity channels.
The Exact Class of Graph Functions Generated by Graph Neural Networks
Feb 17, 2022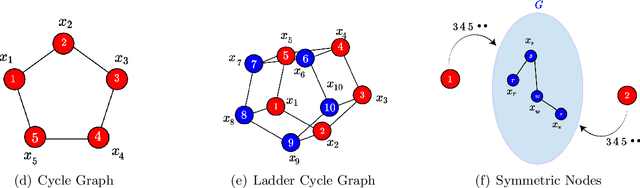
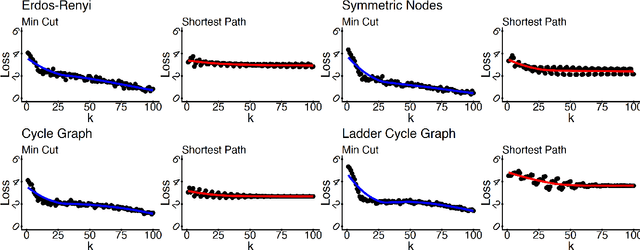
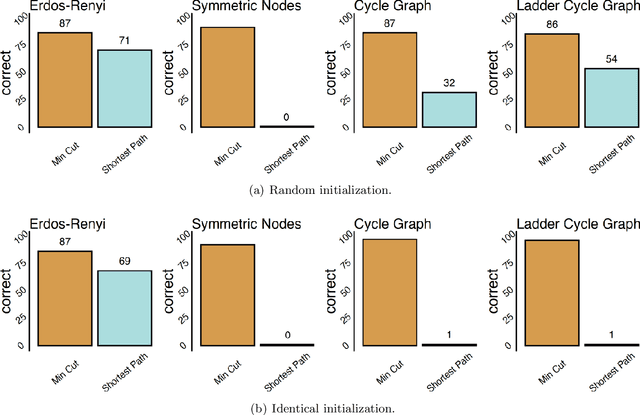
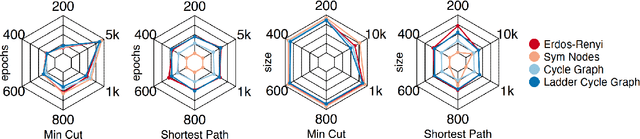
Given a graph function, defined on an arbitrary set of edge weights and node features, does there exist a Graph Neural Network (GNN) whose output is identical to the graph function? In this paper, we fully answer this question and characterize the class of graph problems that can be represented by GNNs. We identify an algebraic condition, in terms of the permutation of edge weights and node features, which proves to be necessary and sufficient for a graph problem to lie within the reach of GNNs. Moreover, we show that this condition can be efficiently verified by checking quadratically many constraints. Note that our refined characterization on the expressive power of GNNs are orthogonal to those theoretical results showing equivalence between GNNs and Weisfeiler-Lehman graph isomorphism heuristic. For instance, our characterization implies that many natural graph problems, such as min-cut value, max-flow value, and max-clique size, can be represented by a GNN. In contrast, and rather surprisingly, there exist very simple graphs for which no GNN can correctly find the length of the shortest paths between all nodes. Note that finding shortest paths is one of the most classical problems in Dynamic Programming (DP). Thus, the aforementioned negative example highlights the misalignment between DP and GNN, even though (conceptually) they follow very similar iterative procedures. Finally, we support our theoretical results by experimental simulations.
Probabilistically Robust Learning: Balancing Average- and Worst-case Performance
Feb 02, 2022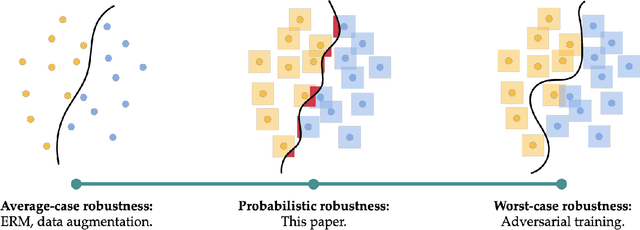
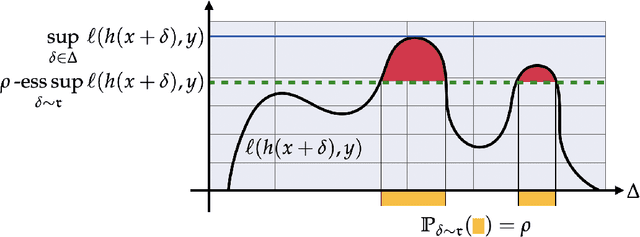
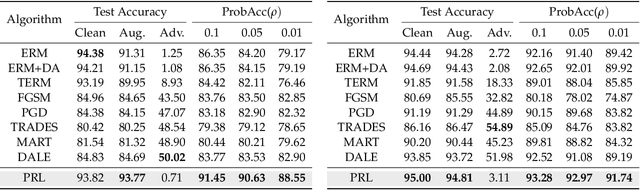
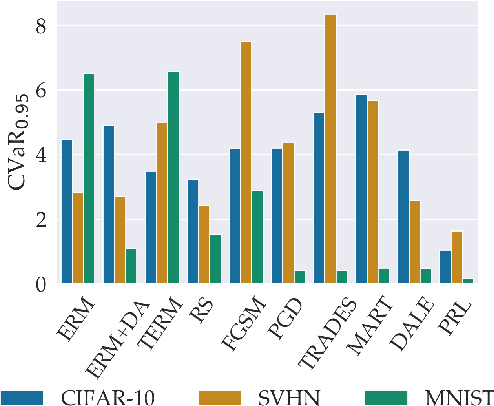
Many of the successes of machine learning are based on minimizing an averaged loss function. However, it is well-known that this paradigm suffers from robustness issues that hinder its applicability in safety-critical domains. These issues are often addressed by training against worst-case perturbations of data, a technique known as adversarial training. Although empirically effective, adversarial training can be overly conservative, leading to unfavorable trade-offs between nominal performance and robustness. To this end, in this paper we propose a framework called probabilistic robustness that bridges the gap between the accurate, yet brittle average case and the robust, yet conservative worst case by enforcing robustness to most rather than to all perturbations. From a theoretical point of view, this framework overcomes the trade-offs between the performance and the sample-complexity of worst-case and average-case learning. From a practical point of view, we propose a novel algorithm based on risk-aware optimization that effectively balances average- and worst-case performance at a considerably lower computational cost relative to adversarial training. Our results on MNIST, CIFAR-10, and SVHN illustrate the advantages of this framework on the spectrum from average- to worst-case robustness.
Efficient and Robust Classification for Sparse Attacks
Jan 23, 2022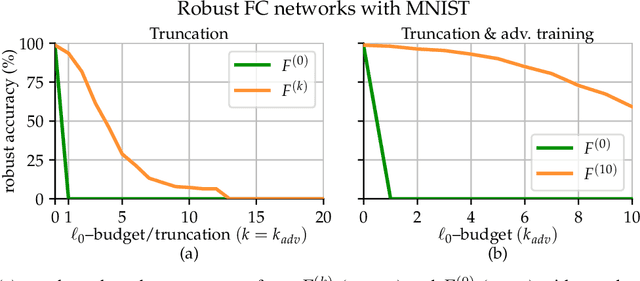
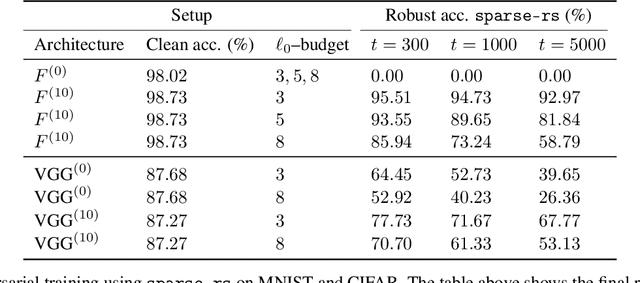
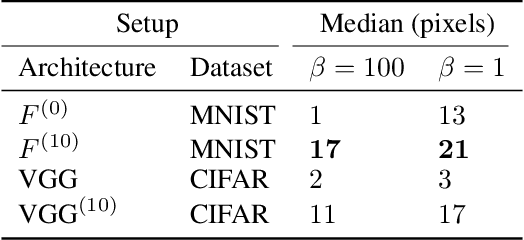

In the past two decades we have seen the popularity of neural networks increase in conjunction with their classification accuracy. Parallel to this, we have also witnessed how fragile the very same prediction models are: tiny perturbations to the inputs can cause misclassification errors throughout entire datasets. In this paper, we consider perturbations bounded by the $\ell_0$--norm, which have been shown as effective attacks in the domains of image-recognition, natural language processing, and malware-detection. To this end, we propose a novel defense method that consists of "truncation" and "adversarial training". We then theoretically study the Gaussian mixture setting and prove the asymptotic optimality of our proposed classifier. Motivated by the insights we obtain, we extend these components to neural network classifiers. We conduct numerical experiments in the domain of computer vision using the MNIST and CIFAR datasets, demonstrating significant improvement for the robust classification error of neural networks.
The curse of overparametrization in adversarial training: Precise analysis of robust generalization for random features regression
Jan 13, 2022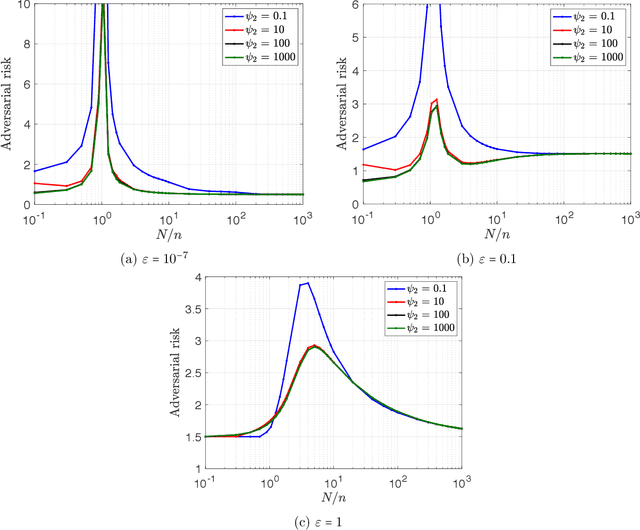
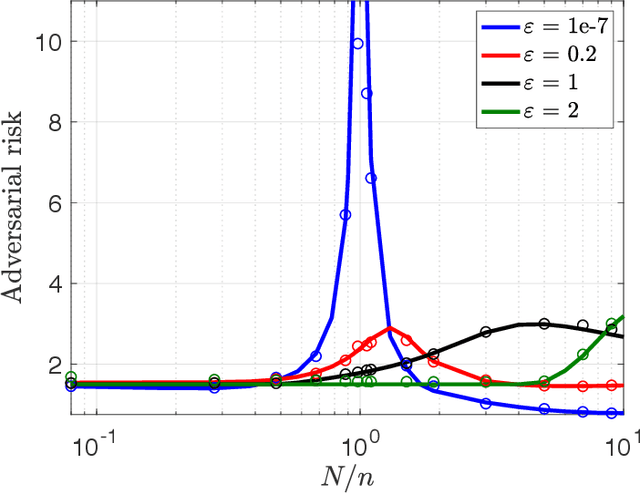
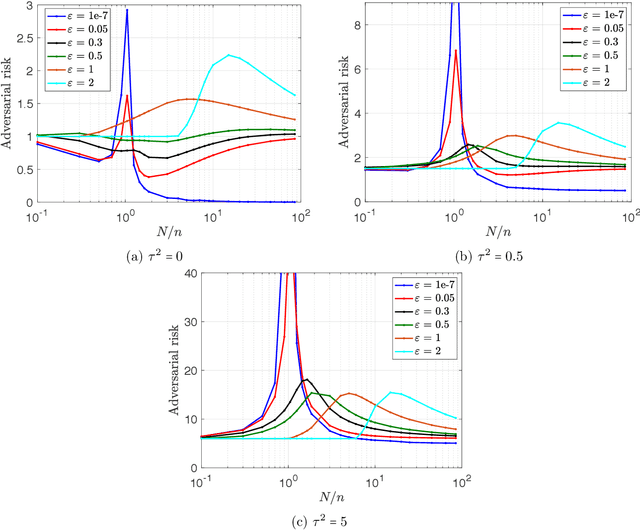
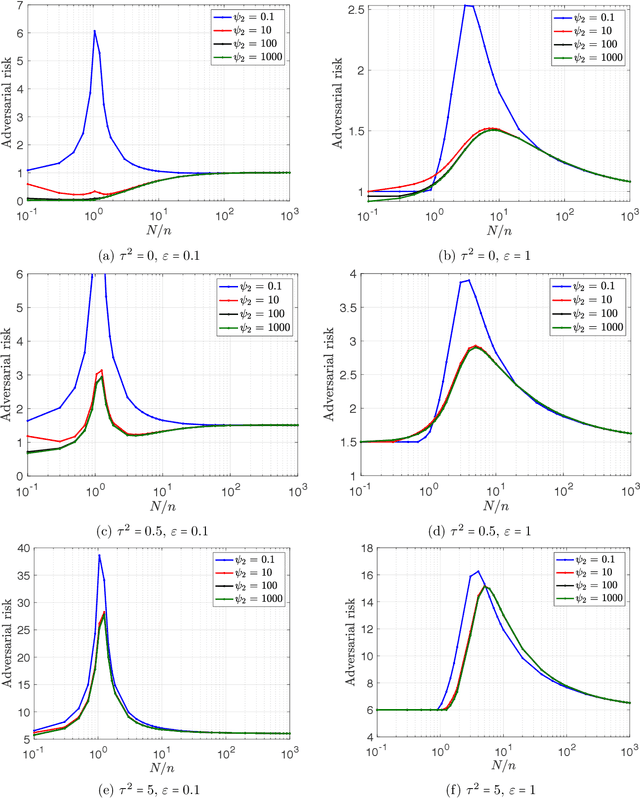
Successful deep learning models often involve training neural network architectures that contain more parameters than the number of training samples. Such overparametrized models have been extensively studied in recent years, and the virtues of overparametrization have been established from both the statistical perspective, via the double-descent phenomenon, and the computational perspective via the structural properties of the optimization landscape. Despite the remarkable success of deep learning architectures in the overparametrized regime, it is also well known that these models are highly vulnerable to small adversarial perturbations in their inputs. Even when adversarially trained, their performance on perturbed inputs (robust generalization) is considerably worse than their best attainable performance on benign inputs (standard generalization). It is thus imperative to understand how overparametrization fundamentally affects robustness. In this paper, we will provide a precise characterization of the role of overparametrization on robustness by focusing on random features regression models (two-layer neural networks with random first layer weights). We consider a regime where the sample size, the input dimension and the number of parameters grow in proportion to each other, and derive an asymptotically exact formula for the robust generalization error when the model is adversarially trained. Our developed theory reveals the nontrivial effect of overparametrization on robustness and indicates that for adversarially trained random features models, high overparametrization can hurt robust generalization.
Minimax Optimization: The Case of Convex-Submodular
Nov 01, 2021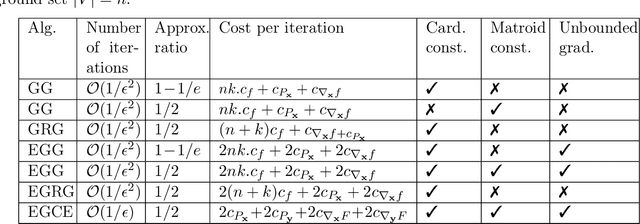
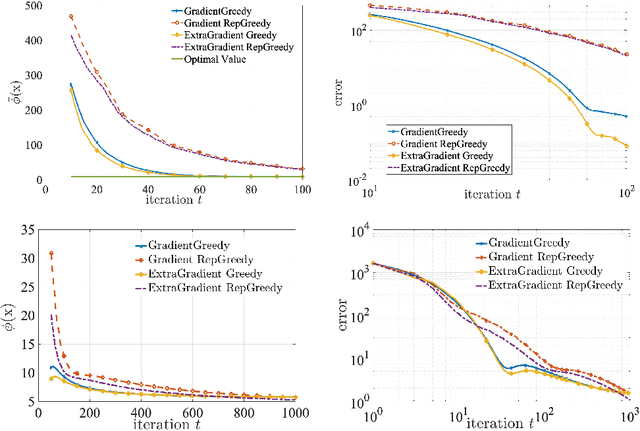
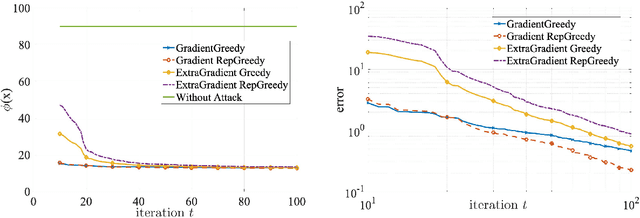
Minimax optimization has been central in addressing various applications in machine learning, game theory, and control theory. Prior literature has thus far mainly focused on studying such problems in the continuous domain, e.g., convex-concave minimax optimization is now understood to a significant extent. Nevertheless, minimax problems extend far beyond the continuous domain to mixed continuous-discrete domains or even fully discrete domains. In this paper, we study mixed continuous-discrete minimax problems where the minimization is over a continuous variable belonging to Euclidean space and the maximization is over subsets of a given ground set. We introduce the class of convex-submodular minimax problems, where the objective is convex with respect to the continuous variable and submodular with respect to the discrete variable. Even though such problems appear frequently in machine learning applications, little is known about how to address them from algorithmic and theoretical perspectives. For such problems, we first show that obtaining saddle points are hard up to any approximation, and thus introduce new notions of (near-) optimality. We then provide several algorithmic procedures for solving convex and monotone-submodular minimax problems and characterize their convergence rates, computational complexity, and quality of the final solution according to our notions of optimally. Our proposed algorithms are iterative and combine tools from both discrete and continuous optimization. Finally, we provide numerical experiments to showcase the effectiveness of our purposed methods.
Adversarial Robustness with Semi-Infinite Constrained Learning
Oct 29, 2021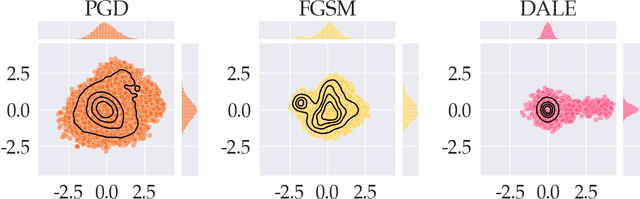
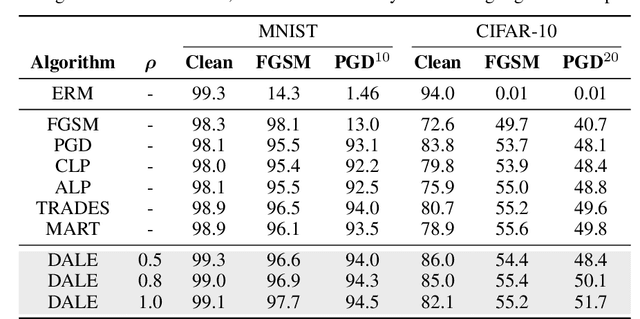
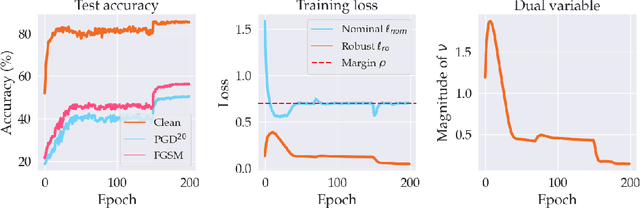
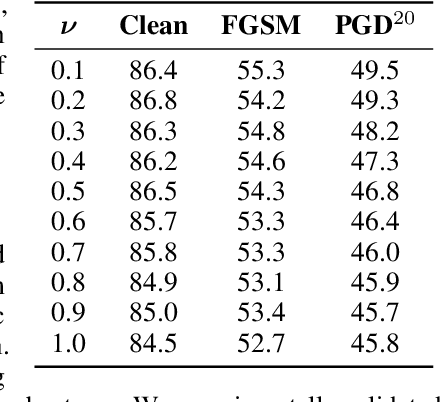
Despite strong performance in numerous applications, the fragility of deep learning to input perturbations has raised serious questions about its use in safety-critical domains. While adversarial training can mitigate this issue in practice, state-of-the-art methods are increasingly application-dependent, heuristic in nature, and suffer from fundamental trade-offs between nominal performance and robustness. Moreover, the problem of finding worst-case perturbations is non-convex and underparameterized, both of which engender a non-favorable optimization landscape. Thus, there is a gap between the theory and practice of adversarial training, particularly with respect to when and why adversarial training works. In this paper, we take a constrained learning approach to address these questions and to provide a theoretical foundation for robust learning. In particular, we leverage semi-infinite optimization and non-convex duality theory to show that adversarial training is equivalent to a statistical problem over perturbation distributions, which we characterize completely. Notably, we show that a myriad of previous robust training techniques can be recovered for particular, sub-optimal choices of these distributions. Using these insights, we then propose a hybrid Langevin Monte Carlo approach of which several common algorithms (e.g., PGD) are special cases. Finally, we show that our approach can mitigate the trade-off between nominal and robust performance, yielding state-of-the-art results on MNIST and CIFAR-10. Our code is available at: https://github.com/arobey1/advbench.
Out-of-Distribution Robustness in Deep Learning Compression
Oct 13, 2021
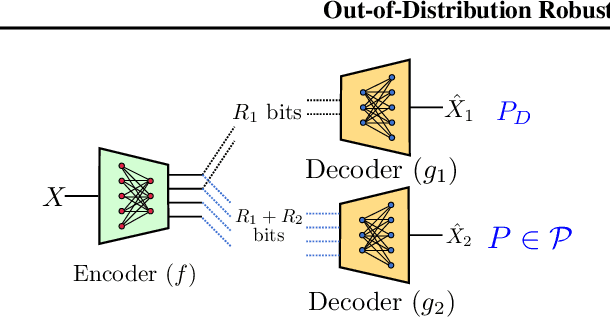
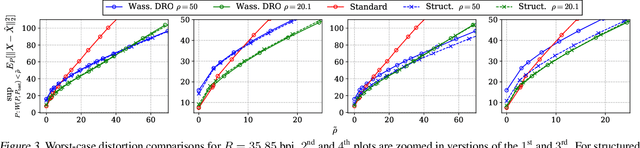
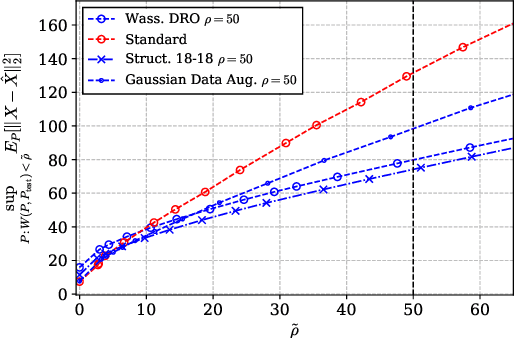
In recent years, deep neural network (DNN) compression systems have proved to be highly effective for designing source codes for many natural sources. However, like many other machine learning systems, these compressors suffer from vulnerabilities to distribution shifts as well as out-of-distribution (OOD) data, which reduces their real-world applications. In this paper, we initiate the study of OOD robust compression. Considering robustness to two types of ambiguity sets (Wasserstein balls and group shifts), we propose algorithmic and architectural frameworks built on two principled methods: one that trains DNN compressors using distributionally-robust optimization (DRO), and the other which uses a structured latent code. Our results demonstrate that both methods enforce robustness compared to a standard DNN compressor, and that using a structured code can be superior to the DRO compressor. We observe tradeoffs between robustness and distortion and corroborate these findings theoretically for a specific class of sources.