 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText + Sketch: Image Compression at Ultra Low Rates
Jul 04, 2023



Recent advances in text-to-image generative models provide the ability to generate high-quality images from short text descriptions. These foundation models, when pre-trained on billion-scale datasets, are effective for various downstream tasks with little or no further training. A natural question to ask is how such models may be adapted for image compression. We investigate several techniques in which the pre-trained models can be directly used to implement compression schemes targeting novel low rate regimes. We show how text descriptions can be used in conjunction with side information to generate high-fidelity reconstructions that preserve both semantics and spatial structure of the original. We demonstrate that at very low bit-rates, our method can significantly improve upon learned compressors in terms of perceptual and semantic fidelity, despite no end-to-end training.
On a Relation Between the Rate-Distortion Function and Optimal Transport
Jul 01, 2023

We discuss a relationship between rate-distortion and optimal transport (OT) theory, even though they seem to be unrelated at first glance. In particular, we show that a function defined via an extremal entropic OT distance is equivalent to the rate-distortion function. We numerically verify this result as well as previous results that connect the Monge and Kantorovich problems to optimal scalar quantization. Thus, we unify solving scalar quantization and rate-distortion functions in an alternative fashion by using their respective optimal transport solvers.
Adversarial Training Should Be Cast as a Non-Zero-Sum Game
Jun 19, 2023


One prominent approach toward resolving the adversarial vulnerability of deep neural networks is the two-player zero-sum paradigm of adversarial training, in which predictors are trained against adversarially-chosen perturbations of data. Despite the promise of this approach, algorithms based on this paradigm have not engendered sufficient levels of robustness, and suffer from pathological behavior like robust overfitting. To understand this shortcoming, we first show that the commonly used surrogate-based relaxation used in adversarial training algorithms voids all guarantees on the robustness of trained classifiers. The identification of this pitfall informs a novel non-zero-sum bilevel formulation of adversarial training, wherein each player optimizes a different objective function. Our formulation naturally yields a simple algorithmic framework that matches and in some cases outperforms state-of-the-art attacks, attains comparable levels of robustness to standard adversarial training algorithms, and does not suffer from robust overfitting.
Optimal Heterogeneous Collaborative Linear Regression and Contextual Bandits
Jun 09, 2023



Large and complex datasets are often collected from several, possibly heterogeneous sources. Collaborative learning methods improve efficiency by leveraging commonalities across datasets while accounting for possible differences among them. Here we study collaborative linear regression and contextual bandits, where each instance's associated parameters are equal to a global parameter plus a sparse instance-specific term. We propose a novel two-stage estimator called MOLAR that leverages this structure by first constructing an entry-wise median of the instances' linear regression estimates, and then shrinking the instance-specific estimates towards the median. MOLAR improves the dependence of the estimation error on the data dimension, compared to independent least squares estimates. We then apply MOLAR to develop methods for sparsely heterogeneous collaborative contextual bandits, which lead to improved regret guarantees compared to independent bandit methods. We further show that our methods are minimax optimal by providing a number of lower bounds. Finally, we support the efficiency of our methods by performing experiments on both synthetic data and the PISA dataset on student educational outcomes from heterogeneous countries.
Federated Neural Compression Under Heterogeneous Data
May 25, 2023



We discuss a federated learned compression problem, where the goal is to learn a compressor from real-world data which is scattered across clients and may be statistically heterogeneous, yet share a common underlying representation. We propose a distributed source model that encompasses both characteristics, and naturally suggests a compressor architecture that uses analysis and synthesis transforms shared by clients. Inspired by personalized federated learning methods, we employ an entropy model that is personalized to each client. This allows for a global latent space to be learned across clients, and personalized entropy models that adapt to the clients' latent distributions. We show empirically that this strategy outperforms solely local methods, which indicates that learned compression also benefits from a shared global representation in statistically heterogeneous federated settings.
Federated Temporal Difference Learning with Linear Function Approximation under Environmental Heterogeneity
Feb 04, 2023


We initiate the study of federated reinforcement learning under environmental heterogeneity by considering a policy evaluation problem. Our setup involves $N$ agents interacting with environments that share the same state and action space but differ in their reward functions and state transition kernels. Assuming agents can communicate via a central server, we ask: Does exchanging information expedite the process of evaluating a common policy? To answer this question, we provide the first comprehensive finite-time analysis of a federated temporal difference (TD) learning algorithm with linear function approximation, while accounting for Markovian sampling, heterogeneity in the agents' environments, and multiple local updates to save communication. Our analysis crucially relies on several novel ingredients: (i) deriving perturbation bounds on TD fixed points as a function of the heterogeneity in the agents' underlying Markov decision processes (MDPs); (ii) introducing a virtual MDP to closely approximate the dynamics of the federated TD algorithm; and (iii) using the virtual MDP to make explicit connections to federated optimization. Putting these pieces together, we rigorously prove that in a low-heterogeneity regime, exchanging model estimates leads to linear convergence speedups in the number of agents.
Demystifying Disagreement-on-the-Line in High Dimensions
Jan 31, 2023



Evaluating the performance of machine learning models under distribution shift is challenging, especially when we only have unlabeled data from the shifted (target) domain, along with labeled data from the original (source) domain. Recent work suggests that the notion of disagreement, the degree to which two models trained with different randomness differ on the same input, is a key to tackle this problem. Experimentally, disagreement and prediction error have been shown to be strongly connected, which has been used to estimate model performance. Experiments have lead to the discovery of the disagreement-on-the-line phenomenon, whereby the classification error under the target domain is often a linear function of the classification error under the source domain; and whenever this property holds, disagreement under the source and target domain follow the same linear relation. In this work, we develop a theoretical foundation for analyzing disagreement in high-dimensional random features regression; and study under what conditions the disagreement-on-the-line phenomenon occurs in our setting. Experiments on CIFAR-10-C, Tiny ImageNet-C, and Camelyon17 are consistent with our theory and support the universality of the theoretical findings.
Temporal Difference Learning with Compressed Updates: Error-Feedback meets Reinforcement Learning
Jan 03, 2023In large-scale machine learning, recent works have studied the effects of compressing gradients in stochastic optimization in order to alleviate the communication bottleneck. These works have collectively revealed that stochastic gradient descent (SGD) is robust to structured perturbations such as quantization, sparsification, and delays. Perhaps surprisingly, despite the surge of interest in large-scale, multi-agent reinforcement learning, almost nothing is known about the analogous question: Are common reinforcement learning (RL) algorithms also robust to similar perturbations? In this paper, we investigate this question by studying a variant of the classical temporal difference (TD) learning algorithm with a perturbed update direction, where a general compression operator is used to model the perturbation. Our main technical contribution is to show that compressed TD algorithms, coupled with an error-feedback mechanism used widely in optimization, exhibit the same non-asymptotic theoretical guarantees as their SGD counterparts. We then extend our results significantly to nonlinear stochastic approximation algorithms and multi-agent settings. In particular, we prove that for multi-agent TD learning, one can achieve linear convergence speedups in the number of agents while communicating just $\tilde{O}(1)$ bits per agent at each time step. Our work is the first to provide finite-time results in RL that account for general compression operators and error-feedback in tandem with linear function approximation and Markovian sampling. Our analysis hinges on studying the drift of a novel Lyapunov function that captures the dynamics of a memory variable introduced by error feedback.
Fundamental Limits of Two-layer Autoencoders, and Achieving Them with Gradient Methods
Dec 27, 2022Autoencoders are a popular model in many branches of machine learning and lossy data compression. However, their fundamental limits, the performance of gradient methods and the features learnt during optimization remain poorly understood, even in the two-layer setting. In fact, earlier work has considered either linear autoencoders or specific training regimes (leading to vanishing or diverging compression rates). Our paper addresses this gap by focusing on non-linear two-layer autoencoders trained in the challenging proportional regime in which the input dimension scales linearly with the size of the representation. Our results characterize the minimizers of the population risk, and show that such minimizers are achieved by gradient methods; their structure is also unveiled, thus leading to a concise description of the features obtained via training. For the special case of a sign activation function, our analysis establishes the fundamental limits for the lossy compression of Gaussian sources via (shallow) autoencoders. Finally, while the results are proved for Gaussian data, numerical simulations on standard datasets display the universality of the theoretical predictions.
Probable Domain Generalization via Quantile Risk Minimization
Jul 20, 2022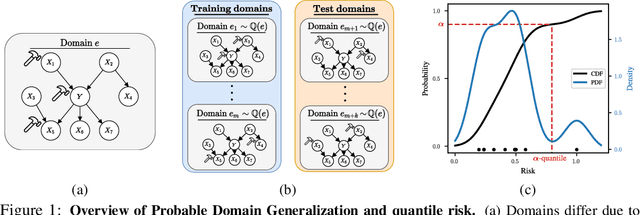
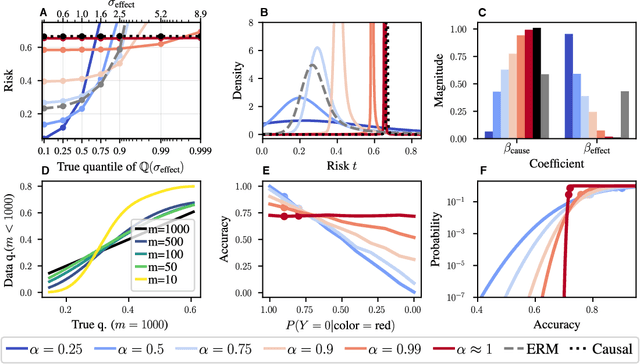
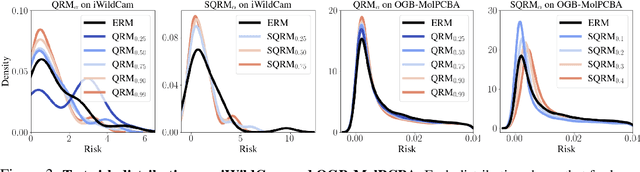
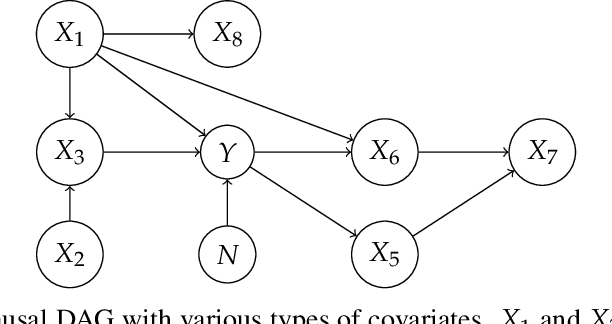
Domain generalization (DG) seeks predictors which perform well on unseen test distributions by leveraging labeled training data from multiple related distributions or domains. To achieve this, the standard formulation optimizes for worst-case performance over the set of all possible domains. However, with worst-case shifts very unlikely in practice, this generally leads to overly-conservative solutions. In fact, a recent study found that no DG algorithm outperformed empirical risk minimization in terms of average performance. In this work, we argue that DG is neither a worst-case problem nor an average-case problem, but rather a probabilistic one. To this end, we propose a probabilistic framework for DG, which we call Probable Domain Generalization, wherein our key idea is that distribution shifts seen during training should inform us of probable shifts at test time. To realize this, we explicitly relate training and test domains as draws from the same underlying meta-distribution, and propose a new optimization problem -- Quantile Risk Minimization (QRM) -- which requires that predictors generalize with high probability. We then prove that QRM: (i) produces predictors that generalize to new domains with a desired probability, given sufficiently many domains and samples; and (ii) recovers the causal predictor as the desired probability of generalization approaches one. In our experiments, we introduce a more holistic quantile-focused evaluation protocol for DG, and show that our algorithms outperform state-of-the-art baselines on real and synthetic data.