 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel feature selection method based on quantum support vector machine
Nov 29, 2023Feature selection is critical in machine learning to reduce dimensionality and improve model accuracy and efficiency. The exponential growth in feature space dimensionality for modern datasets directly results in ambiguous samples and redundant features, which can severely degrade classification accuracy. Quantum machine learning offers potential advantages for addressing this challenge. In this paper, we propose a novel method, quantum support vector machine feature selection (QSVMF), integrating quantum support vector machines with multi-objective genetic algorithm. QSVMF optimizes multiple simultaneous objectives: maximizing classification accuracy, minimizing selected features and quantum circuit costs, and reducing feature covariance. We apply QSVMF for feature selection on a breast cancer dataset, comparing the performance of QSVMF against classical approaches with the selected features. Experimental results show that QSVMF achieves superior performance. Furthermore, The Pareto front solutions of QSVMF enable analysis of accuracy versus feature set size trade-offs, identifying extremely sparse yet accurate feature subsets. We contextualize the biological relevance of the selected features in terms of known breast cancer biomarkers. This work highlights the potential of quantum-based feature selection to enhance machine learning efficiency and performance on complex real-world data.
Several fitness functions and entanglement gates in quantum kernel generation
Sep 11, 2023Quantum machine learning (QML) represents a promising frontier in the realm of quantum technologies. In this pursuit of quantum advantage, the quantum kernel method for support vector machine has emerged as a powerful approach. Entanglement, a fundamental concept in quantum mechanics, assumes a central role in quantum computing. In this paper, we study the necessities of entanglement gates in the quantum kernel methods. We present several fitness functions for a multi-objective genetic algorithm that simultaneously maximizes classification accuracy while minimizing both the local and non-local gate costs of the quantum feature map's circuit. We conduct comparisons with classical classifiers to gain insights into the benefits of employing entanglement gates. Surprisingly, our experiments reveal that the optimal configuration of quantum circuits for the quantum kernel method incorporates a proportional number of non-local gates for entanglement, contrary to previous literature where non-local gates were largely suppressed. Furthermore, we demonstrate that the separability indexes of data can be effectively leveraged to determine the number of non-local gates required for the quantum support vector machine's feature maps. This insight can significantly aid in selecting appropriate parameters, such as the entanglement parameter, in various quantum programming packages like https://qiskit.org/ based on data analysis. Our findings offer valuable guidance for enhancing the efficiency and accuracy of quantum machine learning algorithm
A Functional approach for Two Way Dimension Reduction in Time Series
Jan 01, 2023



The rise in data has led to the need for dimension reduction techniques, especially in the area of non-scalar variables, including time series, natural language processing, and computer vision. In this paper, we specifically investigate dimension reduction for time series through functional data analysis. Current methods for dimension reduction in functional data are functional principal component analysis and functional autoencoders, which are limited to linear mappings or scalar representations for the time series, which is inefficient. In real data applications, the nature of the data is much more complex. We propose a non-linear function-on-function approach, which consists of a functional encoder and a functional decoder, that uses continuous hidden layers consisting of continuous neurons to learn the structure inherent in functional data, which addresses the aforementioned concerns in the existing approaches. Our approach gives a low dimension latent representation by reducing the number of functional features as well as the timepoints at which the functions are observed. The effectiveness of the proposed model is demonstrated through multiple simulations and real data examples.
* 10 pages, 4 figures, 4 tables
ISA-Net: Improved spatial attention network for PET-CT tumor segmentation
Nov 04, 2022



Achieving accurate and automated tumor segmentation plays an important role in both clinical practice and radiomics research. Segmentation in medicine is now often performed manually by experts, which is a laborious, expensive and error-prone task. Manual annotation relies heavily on the experience and knowledge of these experts. In addition, there is much intra- and interobserver variation. Therefore, it is of great significance to develop a method that can automatically segment tumor target regions. In this paper, we propose a deep learning segmentation method based on multimodal positron emission tomography-computed tomography (PET-CT), which combines the high sensitivity of PET and the precise anatomical information of CT. We design an improved spatial attention network(ISA-Net) to increase the accuracy of PET or CT in detecting tumors, which uses multi-scale convolution operation to extract feature information and can highlight the tumor region location information and suppress the non-tumor region location information. In addition, our network uses dual-channel inputs in the coding stage and fuses them in the decoding stage, which can take advantage of the differences and complementarities between PET and CT. We validated the proposed ISA-Net method on two clinical datasets, a soft tissue sarcoma(STS) and a head and neck tumor(HECKTOR) dataset, and compared with other attention methods for tumor segmentation. The DSC score of 0.8378 on STS dataset and 0.8076 on HECKTOR dataset show that ISA-Net method achieves better segmentation performance and has better generalization. Conclusions: The method proposed in this paper is based on multi-modal medical image tumor segmentation, which can effectively utilize the difference and complementarity of different modes. The method can also be applied to other multi-modal data or single-modal data by proper adjustment.
Distributional Actor-Critic Ensemble for Uncertainty-Aware Continuous Control
Jul 27, 2022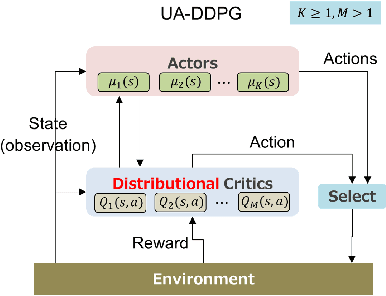
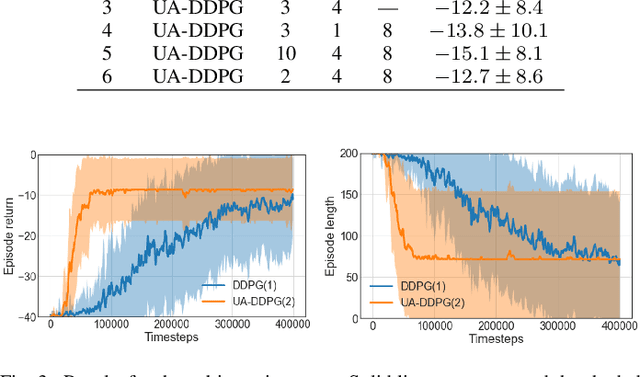
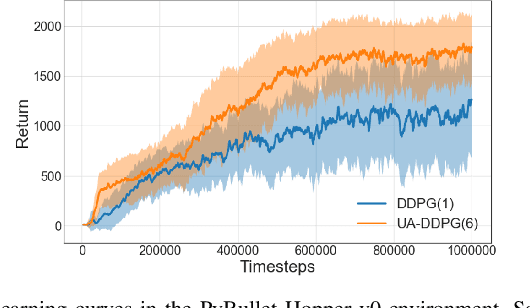
Uncertainty quantification is one of the central challenges for machine learning in real-world applications. In reinforcement learning, an agent confronts two kinds of uncertainty, called epistemic uncertainty and aleatoric uncertainty. Disentangling and evaluating these uncertainties simultaneously stands a chance of improving the agent's final performance, accelerating training, and facilitating quality assurance after deployment. In this work, we propose an uncertainty-aware reinforcement learning algorithm for continuous control tasks that extends the Deep Deterministic Policy Gradient algorithm (DDPG). It exploits epistemic uncertainty to accelerate exploration and aleatoric uncertainty to learn a risk-sensitive policy. We conduct numerical experiments showing that our variant of DDPG outperforms vanilla DDPG without uncertainty estimation in benchmark tasks on robotic control and power-grid optimization.
Delay-Doppler Reversal for OTFS System in Doubly-selective Fading Channels
Jul 22, 2022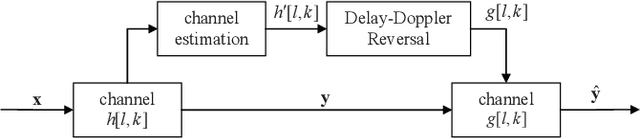
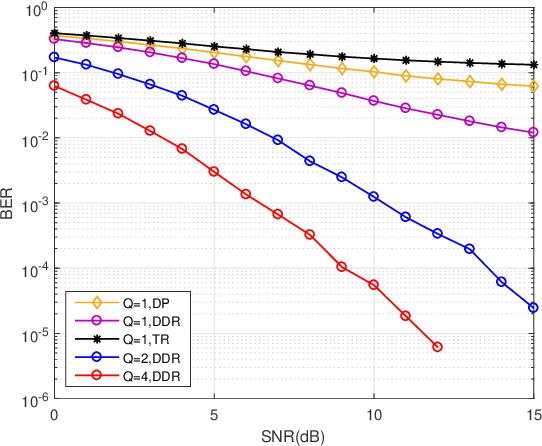
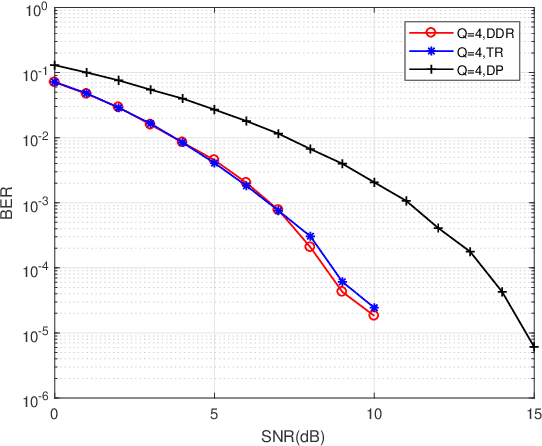
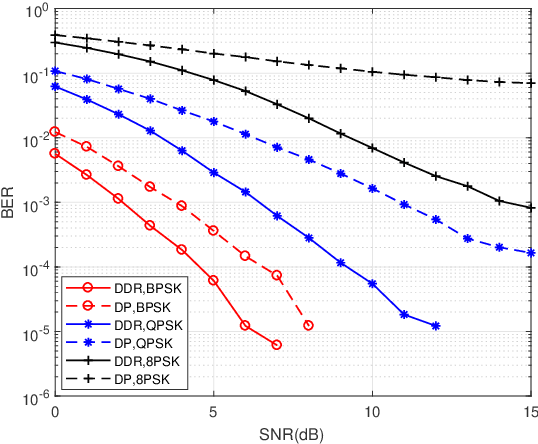
The recent proposed orthogonal time frequency space (OTFS) modulation shows signifcant advantages than conventional orthogonal frequency division multiplexing (OFDM) for high mobility wireless communications. However, a challenging problem is the development of effcient receivers for practical OTFS systems with low complexity. In this paper, we propose a novel delay-Doppler reversal (DDR) technology for OTFS system with desired performance and low complexity. We present the DDR technology from a perspective of two-dimensional cascaded channel model, analyze its computational complexity and also analyze its performance gain compared to the direct processing (DP) receiver without DDR. Simulation results demonstrate that our proposed DDR receiver outperforms traditional receivers in doubly-selective fading channels.
Sequential Point Clouds: A Survey
Apr 21, 2022
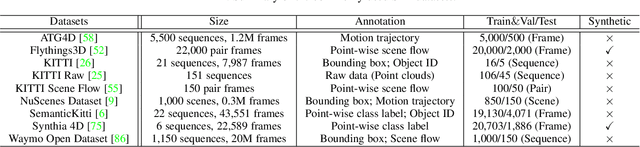
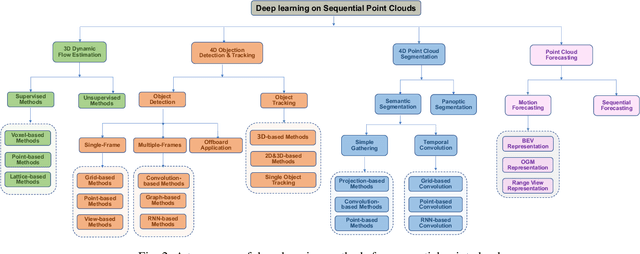
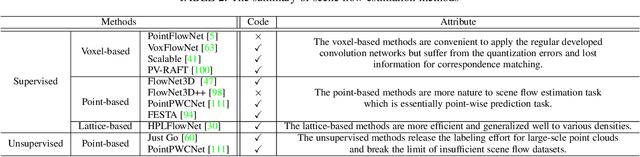
Point cloud has drawn more and more research attention as well as real-world applications. However, many of these applications (e.g. autonomous driving and robotic manipulation) are actually based on sequential point clouds (i.e. four dimensions) because the information of the static point cloud data could provide is still limited. Recently, researchers put more and more effort into sequential point clouds. This paper presents an extensive review of the deep learning-based methods for sequential point cloud research including dynamic flow estimation, object detection \& tracking, point cloud segmentation, and point cloud forecasting. This paper further summarizes and compares the quantitative results of the reviewed methods over the public benchmark datasets. Finally, this paper is concluded by discussing the challenges in the current sequential point cloud research and pointing out insightful potential future research directions.
Service resource allocation problem in the IoT driven personalized healthcare information platform
Apr 05, 2022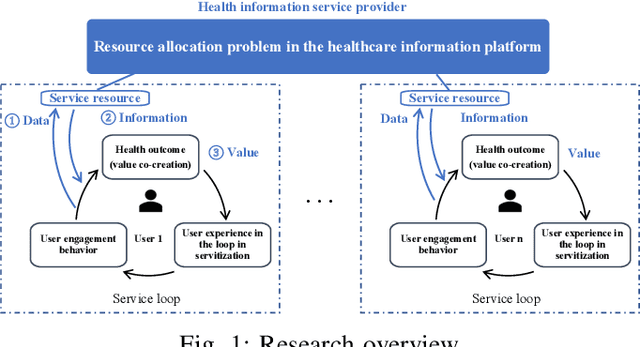
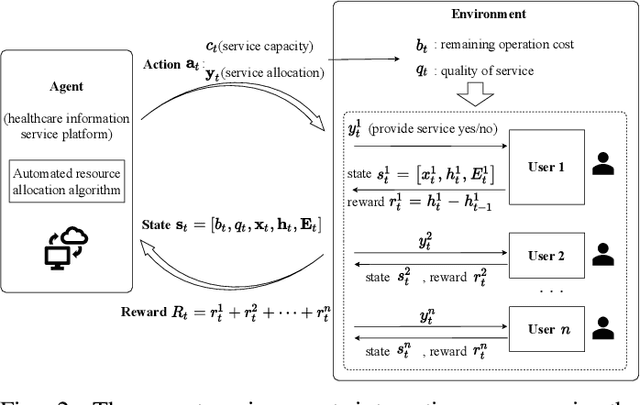
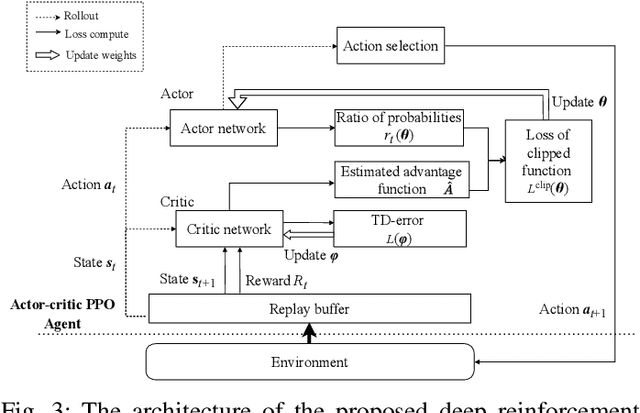
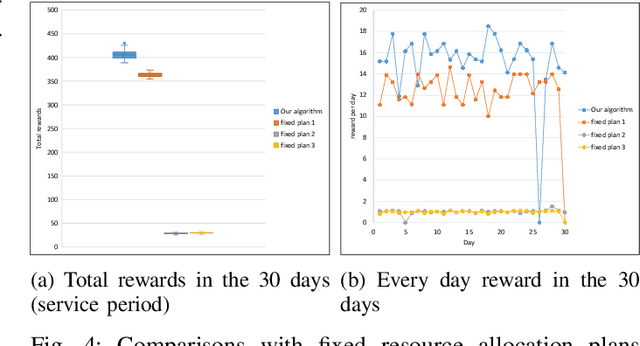
With real-time monitoring of the personalized healthcare condition, the IoT wearables collect the health data and transfer it to the healthcare information platform. The platform processes the data into healthcare recommendations and then delivers them to the users. The IoT structures in the personalized healthcare information service allows the users to engage in the loop in servitization more convenient in the COVID-19 pandemic. However, the uncertainty of the engagement behavior among the individual may result in inefficient of the service resource allocation. This paper seeks an efficient way to allocate the service resource by controlling the service capacity and pushing the service to the active users automatically. In this study, we propose a deep reinforcement learning method to solve the service resource allocation problem based on the proximal policy optimization (PPO) algorithm. Experimental results using the real world (open source) sport dataset reveal that our proposed proximal policy optimization adapts well to the users' changing behavior and with improved performance over fixed service resource policies.
Dynamic physical activity recommendation on personalised mobile health information service: A deep reinforcement learning approach
Apr 03, 2022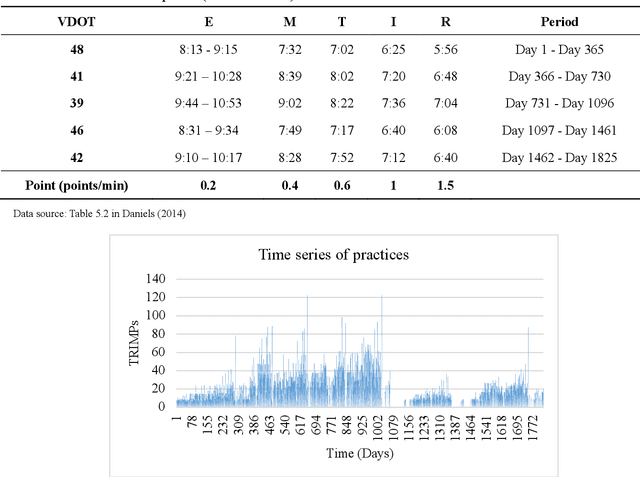


Mobile health (mHealth) information service makes healthcare management easier for users, who want to increase physical activity and improve health. However, the differences in activity preference among the individual, adherence problems, and uncertainty of future health outcomes may reduce the effect of the mHealth information service. The current health service system usually provides recommendations based on fixed exercise plans that do not satisfy the user specific needs. This paper seeks an efficient way to make physical activity recommendation decisions on physical activity promotion in personalised mHealth information service by establishing data-driven model. In this study, we propose a real-time interaction model to select the optimal exercise plan for the individual considering the time-varying characteristics in maximising the long-term health utility of the user. We construct a framework for mHealth information service system comprising a personalised AI module, which is based on the scientific knowledge about physical activity to evaluate the individual exercise performance, which may increase the awareness of the mHealth artificial intelligence system. The proposed deep reinforcement learning (DRL) methodology combining two classes of approaches to improve the learning capability for the mHealth information service system. A deep learning method is introduced to construct the hybrid neural network combing long-short term memory (LSTM) network and deep neural network (DNN) techniques to infer the individual exercise behavior from the time series data. A reinforcement learning method is applied based on the asynchronous advantage actor-critic algorithm to find the optimal policy through exploration and exploitation.
PSMNet: Position-aware Stereo Merging Network for Room Layout Estimation
Mar 30, 2022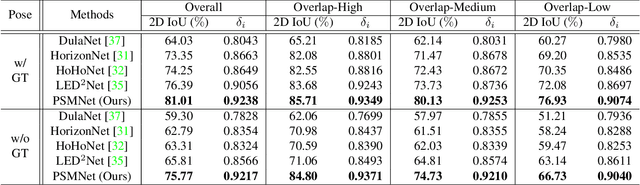
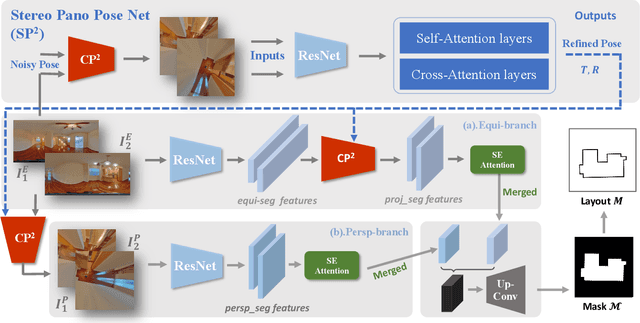
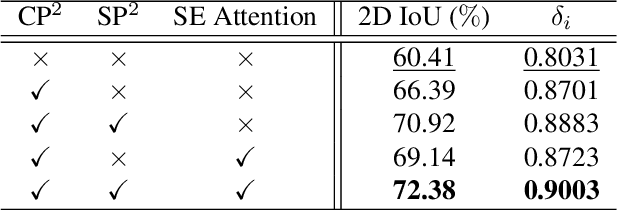

In this paper, we propose a new deep learning-based method for estimating room layout given a pair of 360 panoramas. Our system, called Position-aware Stereo Merging Network or PSMNet, is an end-to-end joint layout-pose estimator. PSMNet consists of a Stereo Pano Pose (SP2) transformer and a novel Cross-Perspective Projection (CP2) layer. The stereo-view SP2 transformer is used to implicitly infer correspondences between views, and can handle noisy poses. The pose-aware CP2 layer is designed to render features from the adjacent view to the anchor (reference) view, in order to perform view fusion and estimate the visible layout. Our experiments and analysis validate our method, which significantly outperforms the state-of-the-art layout estimators, especially for large and complex room spaces.