 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandits Meet Mechanism Design to Combat Clickbait in Online Recommendation
Nov 27, 2023
We study a strategic variant of the multi-armed bandit problem, which we coin the strategic click-bandit. This model is motivated by applications in online recommendation where the choice of recommended items depends on both the click-through rates and the post-click rewards. Like in classical bandits, rewards follow a fixed unknown distribution. However, we assume that the click-rate of each arm is chosen strategically by the arm (e.g., a host on Airbnb) in order to maximize the number of times it gets clicked. The algorithm designer does not know the post-click rewards nor the arms' actions (i.e., strategically chosen click-rates) in advance, and must learn both values over time. To solve this problem, we design an incentive-aware learning algorithm, UCB-S, which achieves two goals simultaneously: (a) incentivizing desirable arm behavior under uncertainty; (b) minimizing regret by learning unknown parameters. We characterize all approximate Nash equilibria among arms under UCB-S and show a $\tilde{\mathcal{O}} (\sqrt{KT})$ regret bound uniformly in every equilibrium. We also show that incentive-unaware algorithms generally fail to achieve low regret in the strategic click-bandit. Finally, we support our theoretical results by simulations of strategic arm behavior which confirm the effectiveness and robustness of our proposed incentive design.
Sample Complexity of Opinion Formation on Networks
Nov 04, 2023Consider public health officials aiming to spread awareness about a new vaccine in a community interconnected by a social network. How can they distribute information with minimal resources, ensuring community-wide understanding that aligns with the actual facts? This concern mirrors numerous real-world situations. In this paper, we initialize the study of sample complexity in opinion formation to solve this problem. Our model is built on the recognized opinion formation game, where we regard each agent's opinion as a data-derived model parameter, not just a real number as in prior studies. Such an extension offers a wider understanding of opinion formation and ties closely with federated learning. Through this formulation, we characterize the sample complexity bounds for any network and also show asymptotically tight bounds for specific network structures. Intriguingly, we discover optimal strategies often allocate samples inversely to the degree, hinting at vital policy implications. Our findings are empirically validated on both synthesized and real-world networks.
A Data-Centric Online Market for Machine Learning: From Discovery to Pricing
Oct 27, 2023



Data fuels machine learning (ML) - rich and high-quality training data is essential to the success of ML. However, to transform ML from the race among a few large corporations to an accessible technology that serves numerous normal users' data analysis requests, there still exist important challenges. One gap we observed is that many ML users can benefit from new data that other data owners possess, whereas these data owners sit on piles of data without knowing who can benefit from it. This gap creates the opportunity for building an online market that can automatically connect supply with demand. While online matching markets are prevalent (e.g., ride-hailing systems), designing a data-centric market for ML exhibits many unprecedented challenges. This paper develops new techniques to tackle two core challenges in designing such a market: (a) to efficiently match demand with supply, we design an algorithm to automatically discover useful data for any ML task from a pool of thousands of datasets, achieving high-quality matching between ML models and data; (b) to encourage market participation of ML users without much ML expertise, we design a new pricing mechanism for selling data-augmented ML models. Furthermore, our market is designed to be API-compatible with existing online ML markets like Vertex AI and Sagemaker, making it easy to use while providing better results due to joint data and model search. We envision that the synergy of our data and model discovery algorithm and pricing mechanism will be an important step towards building a new data-centric online market that serves ML users effectively.
Follow-ups Also Matter: Improving Contextual Bandits via Post-serving Contexts
Sep 25, 2023



Standard contextual bandit problem assumes that all the relevant contexts are observed before the algorithm chooses an arm. This modeling paradigm, while useful, often falls short when dealing with problems in which valuable additional context can be observed after arm selection. For example, content recommendation platforms like Youtube, Instagram, Tiktok also observe valuable follow-up information pertinent to the user's reward after recommendation (e.g., how long the user stayed, what is the user's watch speed, etc.). To improve online learning efficiency in these applications, we study a novel contextual bandit problem with post-serving contexts and design a new algorithm, poLinUCB, that achieves tight regret under standard assumptions. Core to our technical proof is a robustified and generalized version of the well-known Elliptical Potential Lemma (EPL), which can accommodate noise in data. Such robustification is necessary for tackling our problem, and we believe it could also be of general interest. Extensive empirical tests on both synthetic and real-world datasets demonstrate the significant benefit of utilizing post-serving contexts as well as the superior performance of our algorithm over the state-of-the-art approaches.
Incentivized Communication for Federated Bandits
Sep 21, 2023Most existing works on federated bandits take it for granted that all clients are altruistic about sharing their data with the server for the collective good whenever needed. Despite their compelling theoretical guarantee on performance and communication efficiency, this assumption is overly idealistic and oftentimes violated in practice, especially when the algorithm is operated over self-interested clients, who are reluctant to share data without explicit benefits. Negligence of such self-interested behaviors can significantly affect the learning efficiency and even the practical operability of federated bandit learning. In light of this, we aim to spark new insights into this under-explored research area by formally introducing an incentivized communication problem for federated bandits, where the server shall motivate clients to share data by providing incentives. Without loss of generality, we instantiate this bandit problem with the contextual linear setting and propose the first incentivized communication protocol, namely, Inc-FedUCB, that achieves near-optimal regret with provable communication and incentive cost guarantees. Extensive empirical experiments on both synthetic and real-world datasets further validate the effectiveness of the proposed method across various environments.
How Bad is Top-$K$ Recommendation under Competing Content Creators?
Feb 03, 2023



Content creators compete for exposure on recommendation platforms, and such strategic behavior leads to a dynamic shift over the content distribution. However, how the creators' competition impacts user welfare and how the relevance-driven recommendation influences the dynamics in the long run are still largely unknown. This work provides theoretical insights into these research questions. We model the creators' competition under the assumptions that: 1) the platform employs an innocuous top-$K$ recommendation policy; 2) user decisions follow the Random Utility model; 3) content creators compete for user engagement and, without knowing their utility function in hindsight, apply arbitrary no-regret learning algorithms to update their strategies. We study the user welfare guarantee through the lens of Price of Anarchy and show that the fraction of user welfare loss due to creator competition is always upper bounded by a small constant depending on $K$ and randomness in user decisions; we also prove the tightness of this bound. Our result discloses an intrinsic merit of the myopic approach to the recommendation, i.e., relevance-driven matching performs reasonably well in the long run, as long as users' decisions involve randomness and the platform provides reasonably many alternatives to its users.
Multi-Player Bandits Robust to Adversarial Collisions
Nov 15, 2022Motivated by cognitive radios, stochastic Multi-Player Multi-Armed Bandits has been extensively studied in recent years. In this setting, each player pulls an arm, and receives a reward corresponding to the arm if there is no collision, namely the arm was selected by one single player. Otherwise, the player receives no reward if collision occurs. In this paper, we consider the presence of malicious players (or attackers) who obstruct the cooperative players (or defenders) from maximizing their rewards, by deliberately colliding with them. We provide the first decentralized and robust algorithm RESYNC for defenders whose performance deteriorates gracefully as $\tilde{O}(C)$ as the number of collisions $C$ from the attackers increases. We show that this algorithm is order-optimal by proving a lower bound which scales as $\Omega(C)$. This algorithm is agnostic to the algorithm used by the attackers and agnostic to the number of collisions $C$ faced from attackers.
CS-Shapley: Class-wise Shapley Values for Data Valuation in Classification
Nov 13, 2022



Data valuation, or the valuation of individual datum contributions, has seen growing interest in machine learning due to its demonstrable efficacy for tasks such as noisy label detection. In particular, due to the desirable axiomatic properties, several Shapley value approximation methods have been proposed. In these methods, the value function is typically defined as the predictive accuracy over the entire development set. However, this limits the ability to differentiate between training instances that are helpful or harmful to their own classes. Intuitively, instances that harm their own classes may be noisy or mislabeled and should receive a lower valuation than helpful instances. In this work, we propose CS-Shapley, a Shapley value with a new value function that discriminates between training instances' in-class and out-of-class contributions. Our theoretical analysis shows the proposed value function is (essentially) the unique function that satisfies two desirable properties for evaluating data values in classification. Further, our experiments on two benchmark evaluation tasks (data removal and noisy label detection) and four classifiers demonstrate the effectiveness of CS-Shapley over existing methods. Lastly, we evaluate the "transferability" of data values estimated from one classifier to others, and our results suggest Shapley-based data valuation is transferable for application across different models.
Understanding the Limits of Poisoning Attacks in Episodic Reinforcement Learning
Aug 29, 2022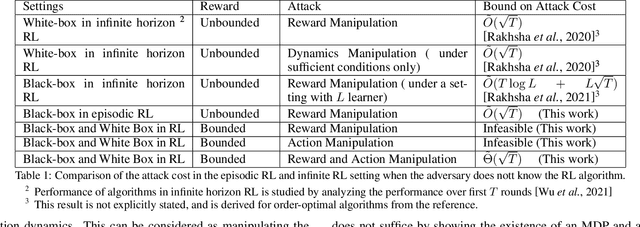
To understand the security threats to reinforcement learning (RL) algorithms, this paper studies poisoning attacks to manipulate \emph{any} order-optimal learning algorithm towards a targeted policy in episodic RL and examines the potential damage of two natural types of poisoning attacks, i.e., the manipulation of \emph{reward} and \emph{action}. We discover that the effect of attacks crucially depend on whether the rewards are bounded or unbounded. In bounded reward settings, we show that only reward manipulation or only action manipulation cannot guarantee a successful attack. However, by combining reward and action manipulation, the adversary can manipulate any order-optimal learning algorithm to follow any targeted policy with $\tilde{\Theta}(\sqrt{T})$ total attack cost, which is order-optimal, without any knowledge of the underlying MDP. In contrast, in unbounded reward settings, we show that reward manipulation attacks are sufficient for an adversary to successfully manipulate any order-optimal learning algorithm to follow any targeted policy using $\tilde{O}(\sqrt{T})$ amount of contamination. Our results reveal useful insights about what can or cannot be achieved by poisoning attacks, and are set to spur more works on the design of robust RL algorithms.
Incrementality Bidding via Reinforcement Learning under Mixed and Delayed Rewards
Jun 02, 2022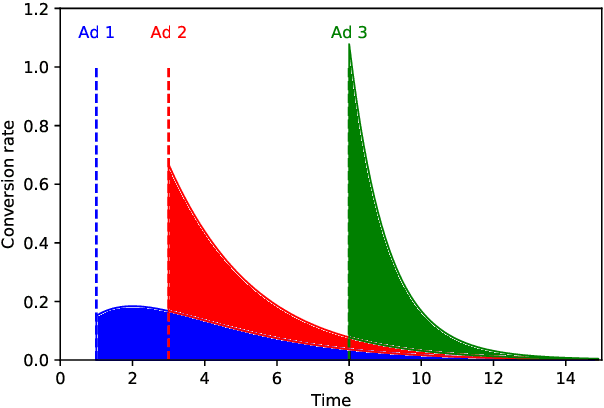
Incrementality, which is used to measure the causal effect of showing an ad to a potential customer (e.g. a user in an internet platform) versus not, is a central object for advertisers in online advertising platforms. This paper investigates the problem of how an advertiser can learn to optimize the bidding sequence in an online manner \emph{without} knowing the incrementality parameters in advance. We formulate the offline version of this problem as a specially structured episodic Markov Decision Process (MDP) and then, for its online learning counterpart, propose a novel reinforcement learning (RL) algorithm with regret at most $\widetilde{O}(H^2\sqrt{T})$, which depends on the number of rounds $H$ and number of episodes $T$, but does not depend on the number of actions (i.e., possible bids). A fundamental difference between our learning problem from standard RL problems is that the realized reward feedback from conversion incrementality is \emph{mixed} and \emph{delayed}. To handle this difficulty we propose and analyze a novel pairwise moment-matching algorithm to learn the conversion incrementality, which we believe is of independent of interest.