 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBURT: BERT-inspired Universal Representation from Learning Meaningful Segment
Dec 31, 2020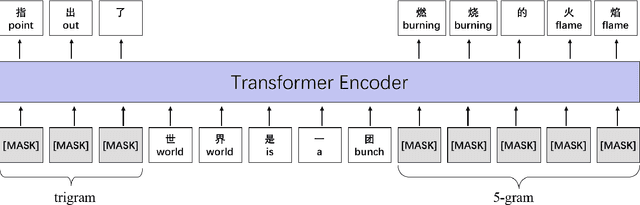
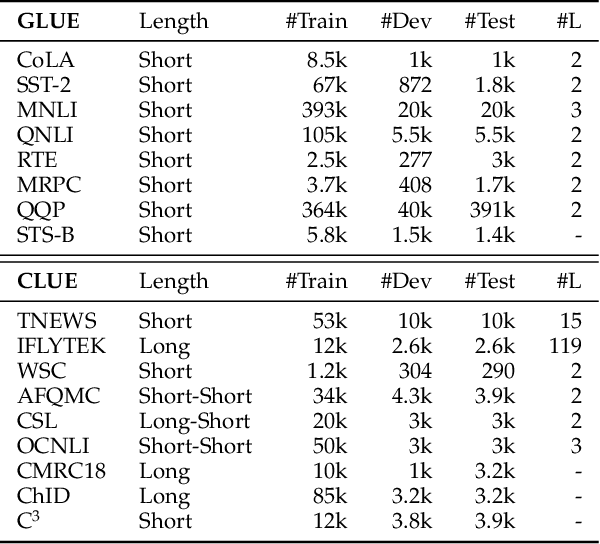
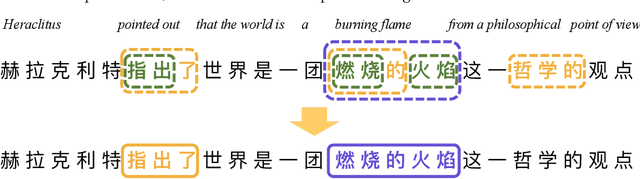
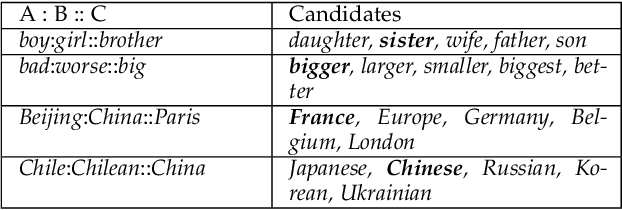
Although pre-trained contextualized language models such as BERT achieve significant performance on various downstream tasks, current language representation still only focuses on linguistic objective at a specific granularity, which may not applicable when multiple levels of linguistic units are involved at the same time. Thus this work introduces and explores the universal representation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space. We present a universal representation model, BURT (BERT-inspired Universal Representation from learning meaningful segmenT), to encode different levels of linguistic unit into the same vector space. Specifically, we extract and mask meaningful segments based on point-wise mutual information (PMI) to incorporate different granular objectives into the pre-training stage. We conduct experiments on datasets for English and Chinese including the GLUE and CLUE benchmarks, where our model surpasses its baselines and alternatives on a wide range of downstream tasks. We present our approach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation models to examine geometric properties of the learned vector space through a task-independent evaluation. Finally, we verify the effectiveness of our unified pre-training strategy in two real-world text matching scenarios. As a result, our model significantly outperforms existing information retrieval (IR) methods and yields universal representations that can be directly applied to retrieval-based question-answering and natural language generation tasks.
Accurate Word Representations with Universal Visual Guidance
Dec 30, 2020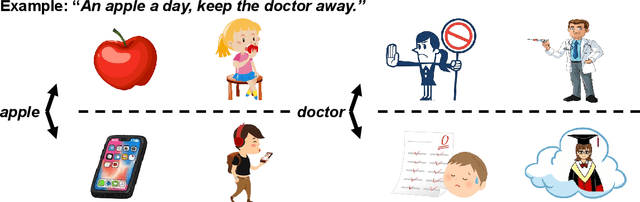

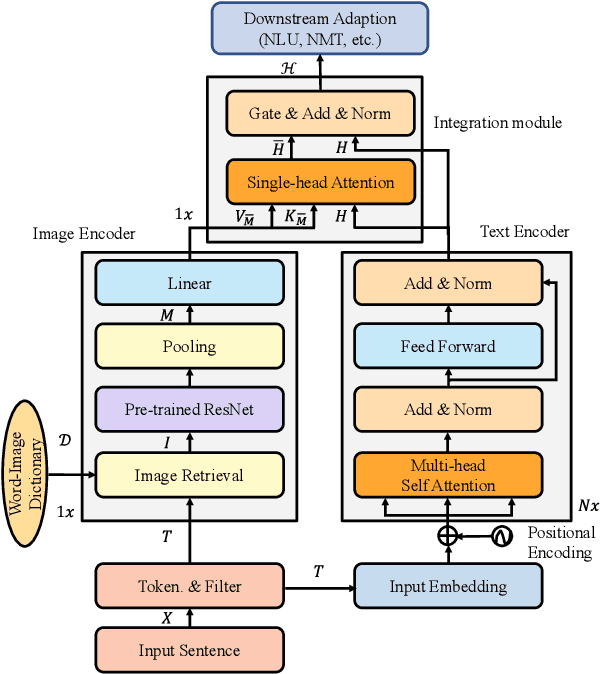

Word representation is a fundamental component in neural language understanding models. Recently, pre-trained language models (PrLMs) offer a new performant method of contextualized word representations by leveraging the sequence-level context for modeling. Although the PrLMs generally give more accurate contextualized word representations than non-contextualized models do, they are still subject to a sequence of text contexts without diverse hints for word representation from multimodality. This paper thus proposes a visual representation method to explicitly enhance conventional word embedding with multiple-aspect senses from visual guidance. In detail, we build a small-scale word-image dictionary from a multimodal seed dataset where each word corresponds to diverse related images. The texts and paired images are encoded in parallel, followed by an attention layer to integrate the multimodal representations. We show that the method substantially improves the accuracy of disambiguation. Experiments on 12 natural language understanding and machine translation tasks further verify the effectiveness and the generalization capability of the proposed approach.
Enhancing Pre-trained Language Model with Lexical Simplification
Dec 30, 2020

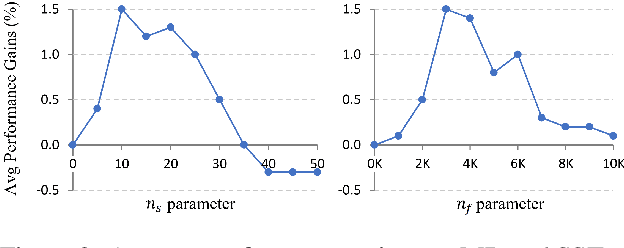
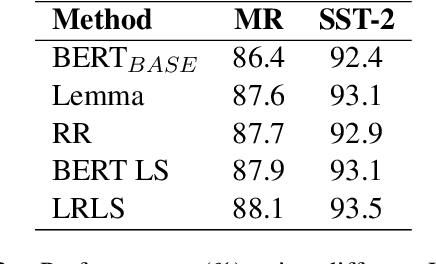
For both human readers and pre-trained language models (PrLMs), lexical diversity may lead to confusion and inaccuracy when understanding the underlying semantic meanings of given sentences. By substituting complex words with simple alternatives, lexical simplification (LS) is a recognized method to reduce such lexical diversity, and therefore to improve the understandability of sentences. In this paper, we leverage LS and propose a novel approach which can effectively improve the performance of PrLMs in text classification. A rule-based simplification process is applied to a given sentence. PrLMs are encouraged to predict the real label of the given sentence with auxiliary inputs from the simplified version. Using strong PrLMs (BERT and ELECTRA) as baselines, our approach can still further improve the performance in various text classification tasks.
Dialogue Graph Modeling for Conversational Machine Reading
Dec 29, 2020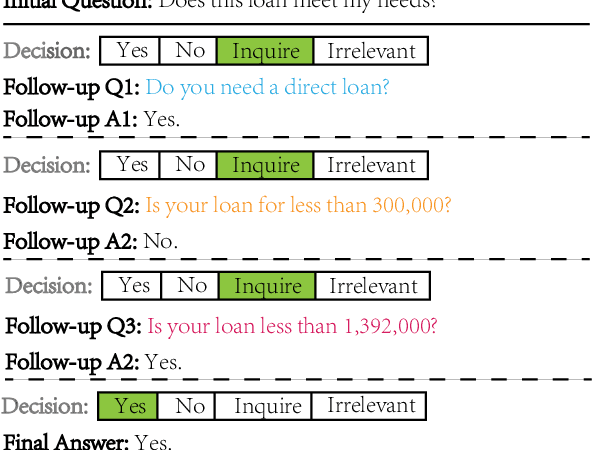
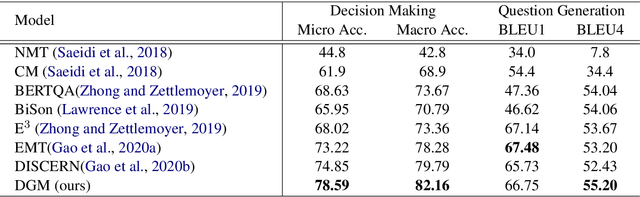
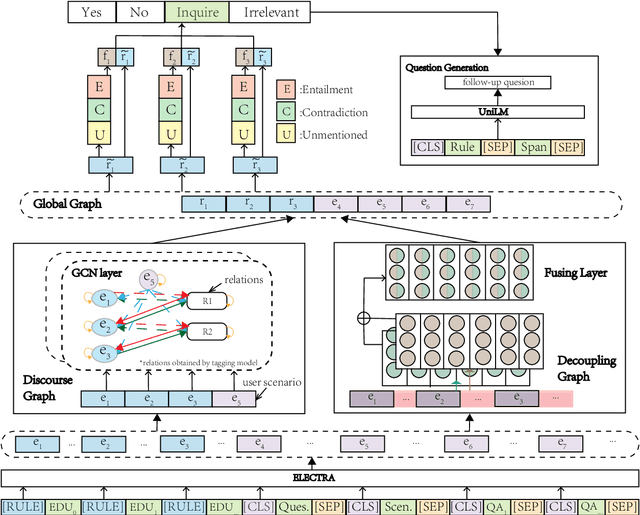
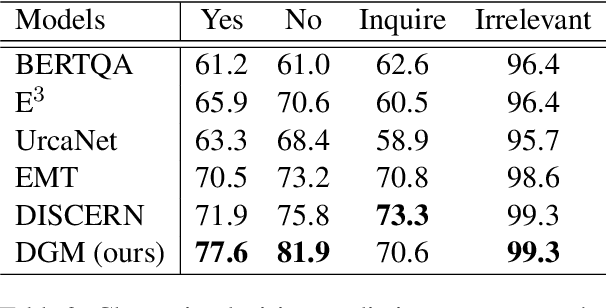
Conversational Machine Reading (CMR) aims at answering questions in a complicated manner. Machine needs to answer questions through interactions with users based on given rule document, user scenario and dialogue history, and ask questions to clarify if necessary. In this paper, we propose a dialogue graph modeling framework to improve the understanding and reasoning ability of machine on CMR task. There are three types of graph in total. Specifically, Discourse Graph is designed to learn explicitly and extract the discourse relation among rule texts as well as the extra knowledge of scenario; Decoupling Graph is used for understanding local and contextualized connection within rule texts. And finally a global graph for fusing the information together and reply to the user with our final decision being either ``Yes/No/Irrelevant" or to ask a follow-up question to clarify.
SIT3: Code Summarization with Structure-Induced Transformer
Dec 29, 2020

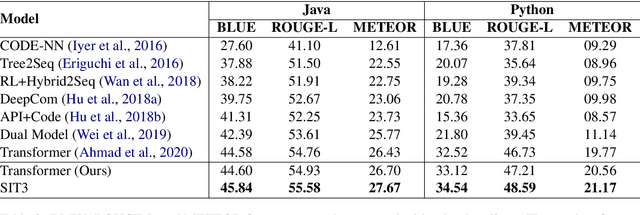
Code summarization (CS) is becoming a promising area in recent natural language understanding, which aims to generate sensible annotations automatically for source code and is known as programmer oriented. Previous works attempt to apply structure-based traversal (SBT) or non-sequential models like Tree-LSTM and GNN to learn structural program semantics. They both meet the following drawbacks: 1) it is shown ineffective to incorporate SBT into Transformer; 2) it is limited to capture global information through GNN; 3) it is underestimated to capture structural semantics only using Transformer. In this paper, we propose a novel model based on structure-induced self-attention, which encodes sequential inputs with highly-effective structure modeling. Extensive experiments show that our newly-proposed model achieves new state-of-the-art results on popular benchmarks. To our best knowledge, it is the first work on code summarization that uses Transformer to model structural information with high efficiency and no extra parameters. We also provide a tutorial on how we pre-process.
Adaptive Convolution for Semantic Role Labeling
Dec 27, 2020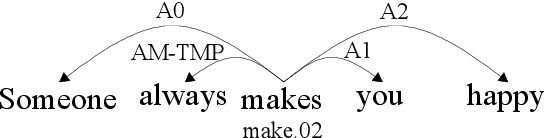
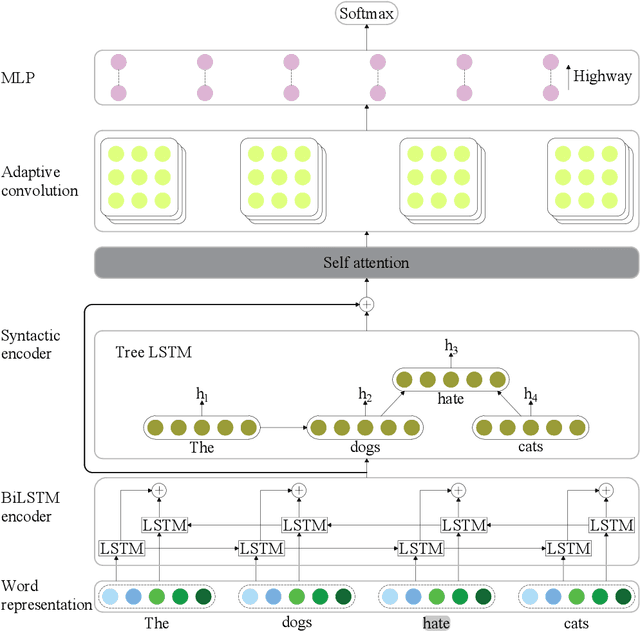
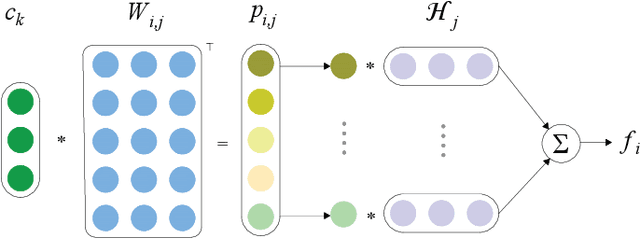
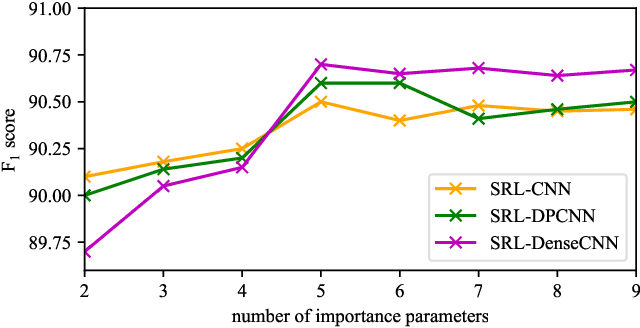
Semantic role labeling (SRL) aims at elaborating the meaning of a sentence by forming a predicate-argument structure. Recent researches depicted that the effective use of syntax can improve SRL performance. However, syntax is a complicated linguistic clue and is hard to be effectively applied in a downstream task like SRL. This work effectively encodes syntax using adaptive convolution which endows strong flexibility to existing convolutional networks. The existing CNNs may help in encoding a complicated structure like syntax for SRL, but it still has shortcomings. Contrary to traditional convolutional networks that use same filters for different inputs, adaptive convolution uses adaptively generated filters conditioned on syntactically informed inputs. We achieve this with the integration of a filter generation network which generates the input specific filters. This helps the model to focus on important syntactic features present inside the input, thus enlarging the gap between syntax-aware and syntax-agnostic SRL systems. We further study a hashing technique to compress the size of the filter generation network for SRL in terms of trainable parameters. Experiments on CoNLL-2009 dataset confirm that the proposed model substantially outperforms most previous SRL systems for both English and Chinese languages
Cross-lingual Dependency Parsing as Domain Adaptation
Dec 24, 2020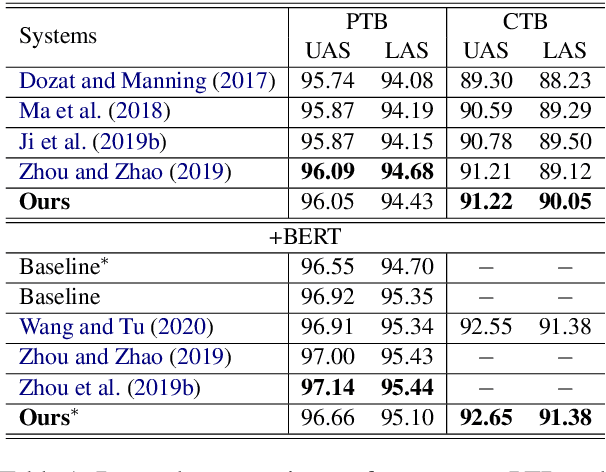
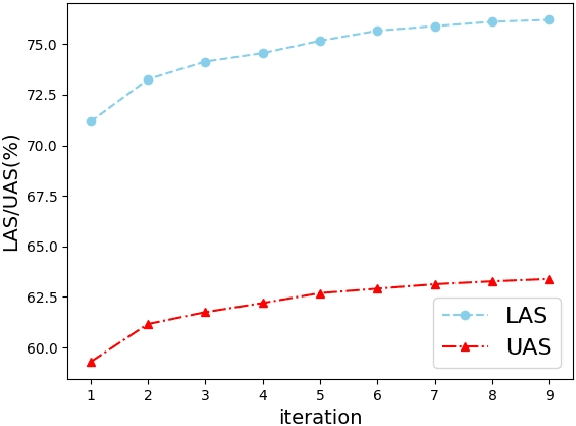
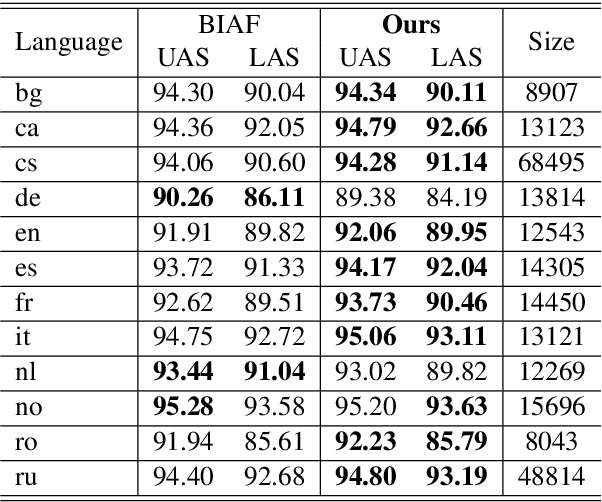
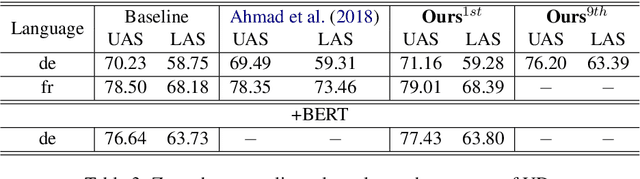
In natural language processing (NLP), cross-lingual transfer learning is as essential as in-domain learning due to the unavailability of annotated resources for low-resource languages. In this paper, we use the ability of a pre-training task that extracts universal features without supervision. We add two pre-training tasks as the auxiliary task into dependency parsing as multi-tasking, which improves the performance of the model in both in-domain and cross-lingual aspects. Moreover, inspired by the usefulness of self-training in cross-domain learning, we combine the traditional self-training and the two pre-training tasks. In this way, we can continuously extract universal features not only in training corpus but also in extra unannotated data and gain further improvement.
Reference Knowledgeable Network for Machine Reading Comprehension
Dec 07, 2020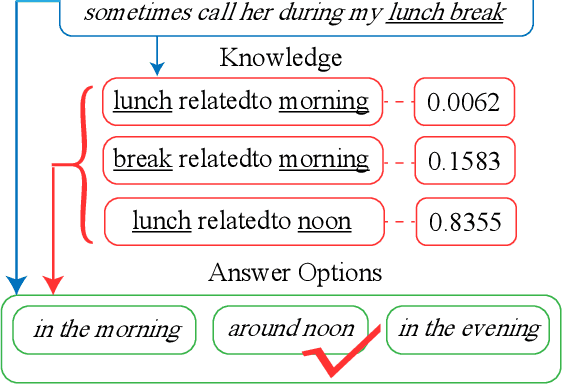

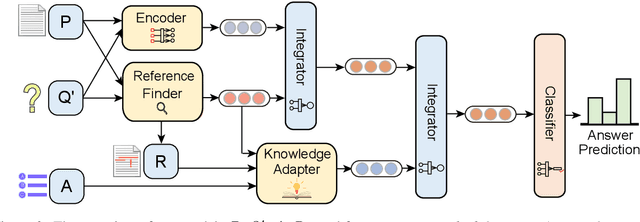
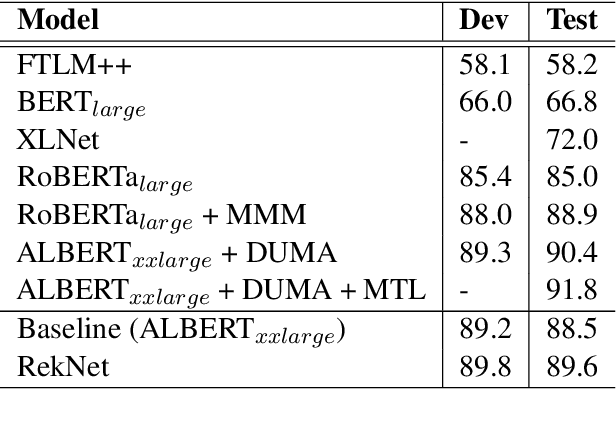
Multi-choice Machine Reading Comprehension (MRC) is a major and challenging form of MRC tasks that requires model to select the most appropriate answer from a set of candidates given passage and question. Most of the existing researches focus on the modeling of the task datasets without explicitly referring to external fine-grained commonsense sources, which is a well-known challenge in multi-choice tasks. Thus we propose a novel reference-based knowledge enhancement model based on span extraction called Reference Knowledgeable Network (RekNet), which simulates human reading strategy to refine critical information from the passage and quote external knowledge in necessity. In detail, RekNet refines fine-grained critical information and defines it as Reference Span, then quotes external knowledge quadruples by the co-occurrence information of Reference Span and answer options. Our proposed method is evaluated on two multi-choice MRC benchmarks: RACE and DREAM, which shows remarkable performance improvement with observable statistical significance level over strong baselines.
SJTU-NICT's Supervised and Unsupervised Neural Machine Translation Systems for the WMT20 News Translation Task
Oct 11, 2020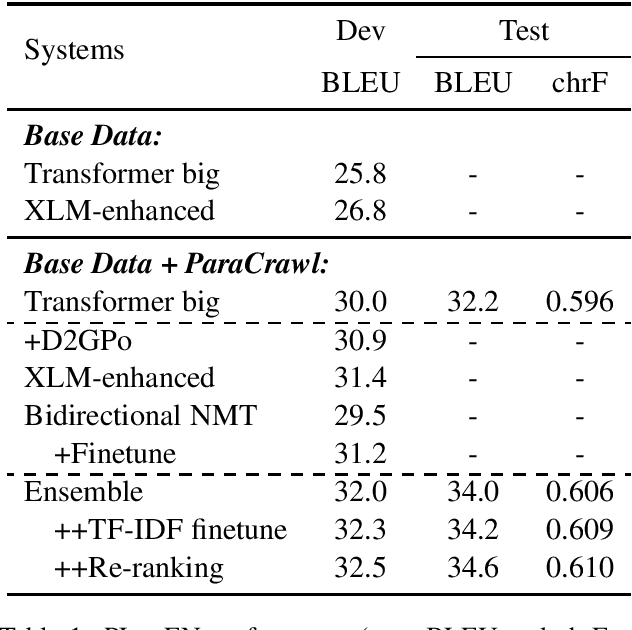
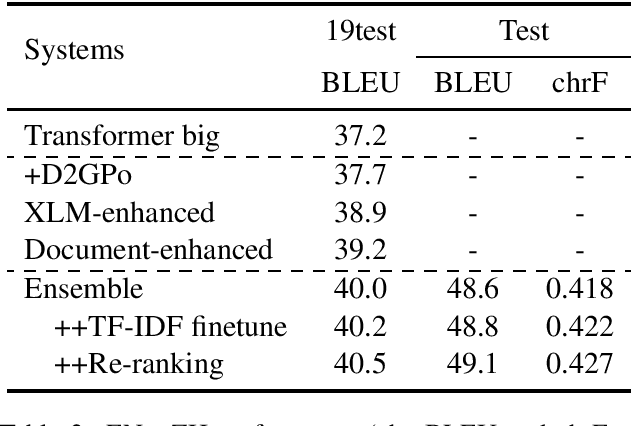
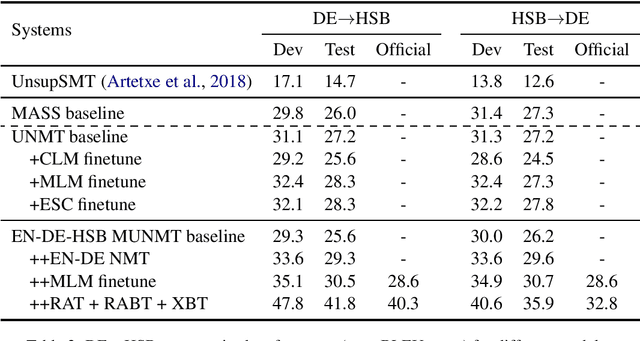
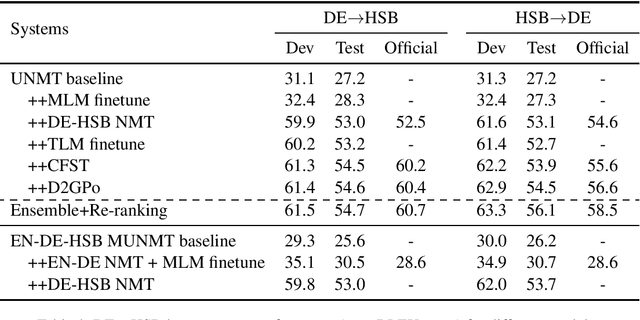
In this paper, we introduced our joint team SJTU-NICT 's participation in the WMT 2020 machine translation shared task. In this shared task, we participated in four translation directions of three language pairs: English-Chinese, English-Polish on supervised machine translation track, German-Upper Sorbian on low-resource and unsupervised machine translation tracks. Based on different conditions of language pairs, we have experimented with diverse neural machine translation (NMT) techniques: document-enhanced NMT, XLM pre-trained language model enhanced NMT, bidirectional translation as a pre-training, reference language based UNMT, data-dependent gaussian prior objective, and BT-BLEU collaborative filtering self-training. We also used the TF-IDF algorithm to filter the training set to obtain a domain more similar set with the test set for finetuning. In our submissions, the primary systems won the first place on English to Chinese, Polish to English, and German to Upper Sorbian translation directions.
High-order Semantic Role Labeling
Oct 09, 2020
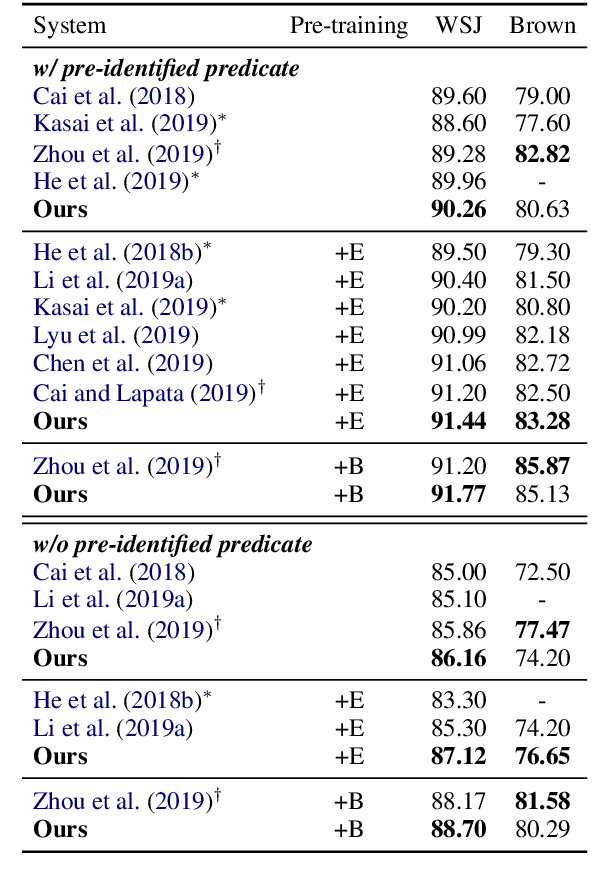
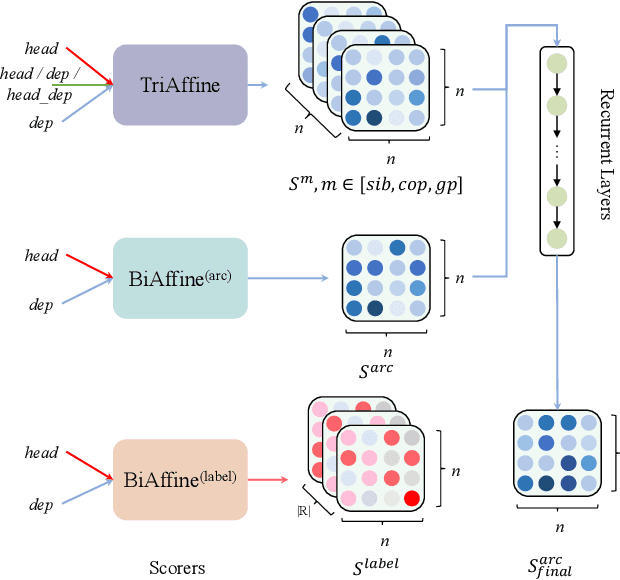
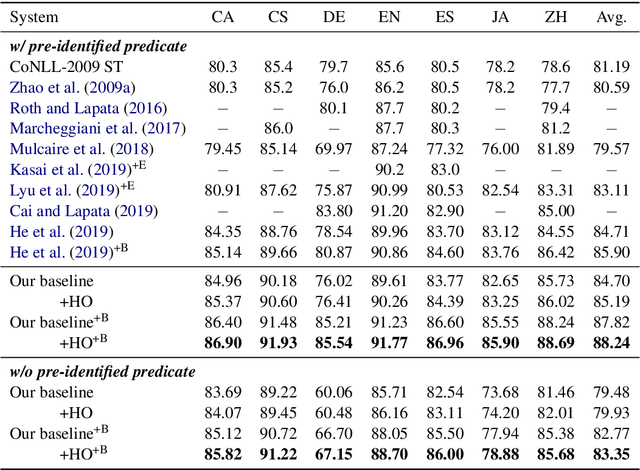
Semantic role labeling is primarily used to identify predicates, arguments, and their semantic relationships. Due to the limitations of modeling methods and the conditions of pre-identified predicates, previous work has focused on the relationships between predicates and arguments and the correlations between arguments at most, while the correlations between predicates have been neglected for a long time. High-order features and structure learning were very common in modeling such correlations before the neural network era. In this paper, we introduce a high-order graph structure for the neural semantic role labeling model, which enables the model to explicitly consider not only the isolated predicate-argument pairs but also the interaction between the predicate-argument pairs. Experimental results on 7 languages of the CoNLL-2009 benchmark show that the high-order structural learning techniques are beneficial to the strong performing SRL models and further boost our baseline to achieve new state-of-the-art results.