 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAIT: Legged Robot Proprioceptive State Estimation with Attention over Inertial-Leg Tokens
Jun 12, 2026In this paper, we propose a method that applies Inertial-Leg (IL) tokenization to an attention-based network for proprioceptive state estimation in legged robots. Unlike existing learning-based state estimators that concatenate all sensor measurements into a single flat vector, the proposed architecture represents inertial measurements and leg-wise measurements as individual tokens and uses an attention mechanism to learn the relative importance of each measurement.This design allows the network to reweight each measurement according to the current contact condition, reflecting the fact that the reliability of forward kinematic measurements depends on whether the corresponding foot is in contact. Unlike conventional contact-aided estimators, however, the proposed method learns this behavior without relying on an explicit contact estimator or on explicit measurement updates based on a stationary contact assumption. To validate the proposed method, we conducted experiments on a Unitree Go1 robot, including debris terrain not modeled in simulation and gait patterns not seen during training. Experimental results show that the proposed method achieves better estimation performance than existing learning-based state estimators under unseen gait patterns and also improves performance over contact-aided model-based methods.
Dynamic Policy Learning for Legged Robot with Simplified Model Pretraining and Model Homotopy Transfer
Dec 31, 2025Generating dynamic motions for legged robots remains a challenging problem. While reinforcement learning has achieved notable success in various legged locomotion tasks, producing highly dynamic behaviors often requires extensive reward tuning or high-quality demonstrations. Leveraging reduced-order models can help mitigate these challenges. However, the model discrepancy poses a significant challenge when transferring policies to full-body dynamics environments. In this work, we introduce a continuation-based learning framework that combines simplified model pretraining and model homotopy transfer to efficiently generate and refine complex dynamic behaviors. First, we pretrain the policy using a single rigid body model to capture core motion patterns in a simplified environment. Next, we employ a continuation strategy to progressively transfer the policy to the full-body environment, minimizing performance loss. To define the continuation path, we introduce a model homotopy from the single rigid body model to the full-body model by gradually redistributing mass and inertia between the trunk and legs. The proposed method not only achieves faster convergence but also demonstrates superior stability during the transfer process compared to baseline methods. Our framework is validated on a range of dynamic tasks, including flips and wall-assisted maneuvers, and is successfully deployed on a real quadrupedal robot.
EL-AGHF: Extended Lagrangian Affine Geometric Heat Flow
May 30, 2025



We propose a constrained Affine Geometric Heat Flow (AGHF) method that evolves so as to suppress the dynamics gaps associated with inadmissible control directions. AGHF provides a unified framework applicable to a wide range of motion planning problems, including both holonomic and non-holonomic systems. However, to generate admissible trajectories, it requires assigning infinite penalties to inadmissible control directions. This design choice, while theoretically valid, often leads to high computational cost or numerical instability when the penalty becomes excessively large. To overcome this limitation, we extend AGHF in an Augmented Lagrangian method approach by introducing a dual trajectory related to dynamics gaps in inadmissible control directions. This method solves the constrained variational problem as an extended parabolic partial differential equation defined over both the state and dual trajectorys, ensuring the admissibility of the resulting trajectory. We demonstrate the effectiveness of our algorithm through simulation examples.
Learning Impact-Rich Rotational Maneuvers via Centroidal Velocity Rewards and Sim-to-Real Techniques: A One-Leg Hopper Flip Case Study
May 18, 2025


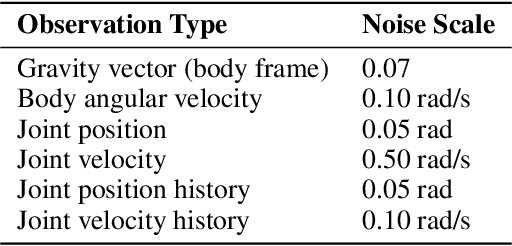
Dynamic rotational maneuvers, such as front flips, inherently involve large angular momentum generation and intense impact forces, presenting major challenges for reinforcement learning and sim-to-real transfer. In this work, we propose a general framework for learning and deploying impact-rich, rotation-intensive behaviors through centroidal velocity-based rewards and actuator-aware sim-to-real techniques. We identify that conventional link-level reward formulations fail to induce true whole-body rotation and introduce a centroidal angular velocity reward that accurately captures system-wide rotational dynamics. To bridge the sim-to-real gap under extreme conditions, we model motor operating regions (MOR) and apply transmission load regularization to ensure realistic torque commands and mechanical robustness. Using the one-leg hopper front flip as a representative case study, we demonstrate the first successful hardware realization of a full front flip. Our results highlight that incorporating centroidal dynamics and actuator constraints is critical for reliably executing highly dynamic motions.
Design of a 3-DOF Hopping Robot with an Optimized Gearbox: An Intermediate Platform Toward Bipedal Robots
May 18, 2025



This paper presents a 3-DOF hopping robot with a human-like lower-limb joint configuration and a flat foot, capable of performing dynamic and repetitive jumping motions. To achieve both high torque output and a large hollow shaft diameter for efficient cable routing, a compact 3K compound planetary gearbox was designed using mixed-integer nonlinear programming for gear tooth optimization. To meet performance requirements within the constrained joint geometry, all major components-including the actuator, motor driver, and communication interface-were custom-designed. The robot weighs 12.45 kg, including a dummy mass, and measures 840 mm in length when the knee joint is fully extended. A reinforcement learning-based controller was employed, and robot's performance was validated through hardware experiments, demonstrating stable and repetitive hopping motions in response to user inputs. These experimental results indicate that the platform serves as a solid foundation for future bipedal robot development.
Multi-Sensor Fusion for Quadruped Robot State Estimation using Invariant Filtering and Smoothing
Apr 29, 2025



This letter introduces two multi-sensor state estimation frameworks for quadruped robots, built on the Invariant Extended Kalman Filter (InEKF) and Invariant Smoother (IS). The proposed methods, named E-InEKF and E-IS, fuse kinematics, IMU, LiDAR, and GPS data to mitigate position drift, particularly along the z-axis, a common issue in proprioceptive-based approaches. We derived observation models that satisfy group-affine properties to integrate LiDAR odometry and GPS into InEKF and IS. LiDAR odometry is incorporated using Iterative Closest Point (ICP) registration on a parallel thread, preserving the computational efficiency of proprioceptive-based state estimation. We evaluate E-InEKF and E-IS with and without exteroceptive sensors, benchmarking them against LiDAR-based odometry methods in indoor and outdoor experiments using the KAIST HOUND2 robot. Our methods achieve lower Relative Position Errors (RPE) and significantly reduce Absolute Trajectory Error (ATE), with improvements of up to 28% indoors and 40% outdoors compared to LIO-SAM and FAST-LIO2. Additionally, we compare E-InEKF and E-IS in terms of computational efficiency and accuracy.
PreCi: Pretraining and Continual Improvement of Humanoid Locomotion via Model-Assumption-Based Regularization
Apr 14, 2025



Humanoid locomotion is a challenging task due to its inherent complexity and high-dimensional dynamics, as well as the need to adapt to diverse and unpredictable environments. In this work, we introduce a novel learning framework for effectively training a humanoid locomotion policy that imitates the behavior of a model-based controller while extending its capabilities to handle more complex locomotion tasks, such as more challenging terrain and higher velocity commands. Our framework consists of three key components: pre-training through imitation of the model-based controller, fine-tuning via reinforcement learning, and model-assumption-based regularization (MAR) during fine-tuning. In particular, MAR aligns the policy with actions from the model-based controller only in states where the model assumption holds to prevent catastrophic forgetting. We evaluate the proposed framework through comprehensive simulation tests and hardware experiments on a full-size humanoid robot, Digit, demonstrating a forward speed of 1.5 m/s and robust locomotion across diverse terrains, including slippery, sloped, uneven, and sandy terrains.
Online Friction Coefficient Identification for Legged Robots on Slippery Terrain Using Smoothed Contact Gradients
Feb 24, 2025



This paper proposes an online friction coefficient identification framework for legged robots on slippery terrain. The approach formulates the optimization problem to minimize the sum of residuals between actual and predicted states parameterized by the friction coefficient in rigid body contact dynamics. Notably, the proposed framework leverages the analytic smoothed gradient of contact impulses, obtained by smoothing the complementarity condition of Coulomb friction, to solve the issue of non-informative gradients induced from the nonsmooth contact dynamics. Moreover, we introduce the rejection method to filter out data with high normal contact velocity following contact initiations during friction coefficient identification for legged robots. To validate the proposed framework, we conduct the experiments using a quadrupedal robot platform, KAIST HOUND, on slippery and nonslippery terrain. We observe that our framework achieves fast and consistent friction coefficient identification within various initial conditions.
* 8 pages, IEEE RA-L (2025) accepted
A Learning Framework for Diverse Legged Robot Locomotion Using Barrier-Based Style Rewards
Sep 26, 2024



This work introduces a model-free reinforcement learning framework that enables various modes of motion (quadruped, tripod, or biped) and diverse tasks for legged robot locomotion. We employ a motion-style reward based on a relaxed logarithmic barrier function as a soft constraint, to bias the learning process toward the desired motion style, such as gait, foot clearance, joint position, or body height. The predefined gait cycle is encoded in a flexible manner, facilitating gait adjustments throughout the learning process. Extensive experiments demonstrate that KAIST HOUND, a 45 kg robotic system, can achieve biped, tripod, and quadruped locomotion using the proposed framework; quadrupedal capabilities include traversing uneven terrain, galloping at 4.67 m/s, and overcoming obstacles up to 58 cm (67 cm for HOUND2); bipedal capabilities include running at 3.6 m/s, carrying a 7.5 kg object, and ascending stairs-all performed without exteroceptive input.
Actuator-Constrained Reinforcement Learning for High-Speed Quadrupedal Locomotion
Dec 29, 2023This paper presents a method for achieving high-speed running of a quadruped robot by considering the actuator torque-speed operating region in reinforcement learning. The physical properties and constraints of the actuator are included in the training process to reduce state transitions that are infeasible in the real world due to motor torque-speed limitations. The gait reward is designed to distribute motor torque evenly across all legs, contributing to more balanced power usage and mitigating performance bottlenecks due to single-motor saturation. Additionally, we designed a lightweight foot to enhance the robot's agility. We observed that applying the motor operating region as a constraint helps the policy network avoid infeasible areas during sampling. With the trained policy, KAIST Hound, a 45 kg quadruped robot, can run up to 6.5 m/s, which is the fastest speed among electric motor-based quadruped robots.