 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRehearsalNeRF: Decoupling Intrinsic Neural Fields of Dynamic Illuminations for Scene Editing
Apr 02, 2026Although there has been significant progress in neural radiance fields, an issue on dynamic illumination changes still remains unsolved. Different from relevant works that parameterize time-variant/-invariant components in scenes, subjects' radiance is highly entangled with their own emitted radiance and lighting colors in spatio-temporal domain. In this paper, we present a new effective method to learn disentangled neural fields under the severe illumination changes, named RehearsalNeRF. Our key idea is to leverage scenes captured under stable lighting like rehearsal stages, easily taken before dynamic illumination occurs, to enforce geometric consistency between the different lighting conditions. In particular, RehearsalNeRF employs a learnable vector for lighting effects which represents illumination colors in a temporal dimension and is used to disentangle projected light colors from scene radiance. Furthermore, our RehearsalNeRF is also able to reconstruct the neural fields of dynamic objects by simply adopting off-the-shelf interactive masks. To decouple the dynamic objects, we propose a new regularization leveraging optical flow, which provides coarse supervision for the color disentanglement. We demonstrate the effectiveness of RehearsalNeRF by showing robust performances on novel view synthesis and scene editing under dynamic illumination conditions. Our source code and video datasets will be publicly available.
Learning Depth from Focus in the Wild
Jul 20, 2022
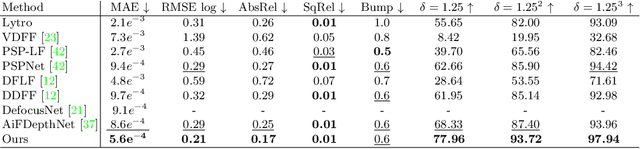
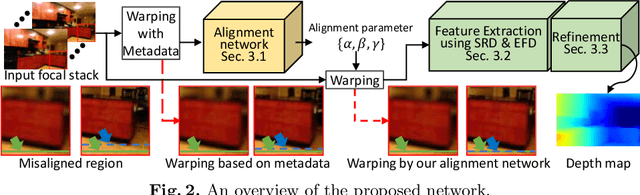
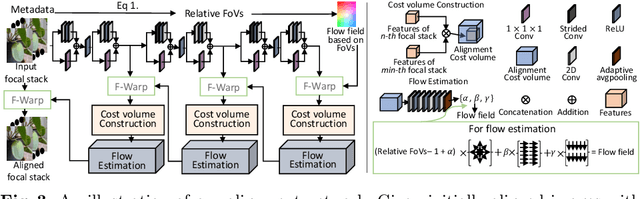
For better photography, most recent commercial cameras including smartphones have either adopted large-aperture lens to collect more light or used a burst mode to take multiple images within short times. These interesting features lead us to examine depth from focus/defocus. In this work, we present a convolutional neural network-based depth estimation from single focal stacks. Our method differs from relevant state-of-the-art works with three unique features. First, our method allows depth maps to be inferred in an end-to-end manner even with image alignment. Second, we propose a sharp region detection module to reduce blur ambiguities in subtle focus changes and weakly texture-less regions. Third, we design an effective downsampling module to ease flows of focal information in feature extractions. In addition, for the generalization of the proposed network, we develop a simulator to realistically reproduce the features of commercial cameras, such as changes in field of view, focal length and principal points. By effectively incorporating these three unique features, our network achieves the top rank in the DDFF 12-Scene benchmark on most metrics. We also demonstrate the effectiveness of the proposed method on various quantitative evaluations and real-world images taken from various off-the-shelf cameras compared with state-of-the-art methods. Our source code is publicly available at https://github.com/wcy199705/DfFintheWild.