 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tight Theory of Error Feedback Algorithms in Distributed Optimization
May 29, 2026Communication costs are a major bottleneck in distributed learning and first-order optimization. A common approach to alleviate this issue is to compress the gradient information exchanged between agents. However, such compression typically degrades the convergence guarantees of gradient-based methods. Error feedback mechanisms provide a simple and computationally cheap remedy for this issue, but numerous variants have been proposed, and their relative performance remains poorly understood. This paper provides tight convergence analyses for two of the main error-feedback algorithms from the literature, the classic Error Feedback method (EF) and Error Feedback 21 (EF21), by identifying optimal step-size choices and constructing optimal Lyapunov functions tailored to each method. The results hold independently of the number of agents and recover the known best guarantees possible in the single-agent regime.
Step-Size Stability in Stochastic Optimization: A Theoretical Perspective
Feb 10, 2026We present a theoretical analysis of stochastic optimization methods in terms of their sensitivity with respect to the step size. We identify a key quantity that, for each method, describes how the performance degrades as the step size becomes too large. For convex problems, we show that this quantity directly impacts the suboptimality bound of the method. Most importantly, our analysis provides direct theoretical evidence that adaptive step-size methods, such as SPS or NGN, are more robust than SGD. This allows us to quantify the advantage of these adaptive methods beyond empirical evaluation. Finally, we show through experiments that our theoretical bound qualitatively mirrors the actual performance as a function of the step size, even for nonconvex problems.
Optimized projection-free algorithms for online learning: construction and worst-case analysis
Jun 06, 2025This work studies and develop projection-free algorithms for online learning with linear optimization oracles (a.k.a. Frank-Wolfe) for handling the constraint set. More precisely, this work (i) provides an improved (optimized) variant of an online Frank-Wolfe algorithm along with its conceptually simple potential-based proof, and (ii) shows how to leverage semidefinite programming to jointly design and analyze online Frank-Wolfe-type algorithms numerically in a variety of settings-that include the design of the variant (i). Based on the semidefinite technique, we conclude with strong numerical evidence suggesting that no pure online Frank-Wolfe algorithm within our model class can have a regret guarantee better than O(T^3/4) (T is the time horizon) without additional assumptions, that the current algorithms do not have optimal constants, that the algorithm benefits from similar anytime properties O(t^3/4) not requiring to know T in advance, and that multiple linear optimization rounds do not generally help to obtain better regret bounds.
Tight analyses of first-order methods with error feedback
Jun 05, 2025Communication between agents often constitutes a major computational bottleneck in distributed learning. One of the most common mitigation strategies is to compress the information exchanged, thereby reducing communication overhead. To counteract the degradation in convergence associated with compressed communication, error feedback schemes -- most notably $\mathrm{EF}$ and $\mathrm{EF}^{21}$ -- were introduced. In this work, we provide a tight analysis of both of these methods. Specifically, we find the Lyapunov function that yields the best possible convergence rate for each method -- with matching lower bounds. This principled approach yields sharp performance guarantees and enables a rigorous, apples-to-apples comparison between $\mathrm{EF}$, $\mathrm{EF}^{21}$, and compressed gradient descent. Our analysis is carried out in a simplified yet representative setting, which allows for clean theoretical insights and fair comparison of the underlying mechanisms.
The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training
Jan 31, 2025



We show that learning-rate schedules for large model training behave surprisingly similar to a performance bound from non-smooth convex optimization theory. We provide a bound for the constant schedule with linear cooldown; in particular, the practical benefit of cooldown is reflected in the bound due to the absence of logarithmic terms. Further, we show that this surprisingly close match between optimization theory and practice can be exploited for learning-rate tuning: we achieve noticeable improvements for training 124M and 210M Llama-type models by (i) extending the schedule for continued training with optimal learning-rate, and (ii) transferring the optimal learning-rate across schedules.
Fast Stochastic Composite Minimization and an Accelerated Frank-Wolfe Algorithm under Parallelization
May 25, 2022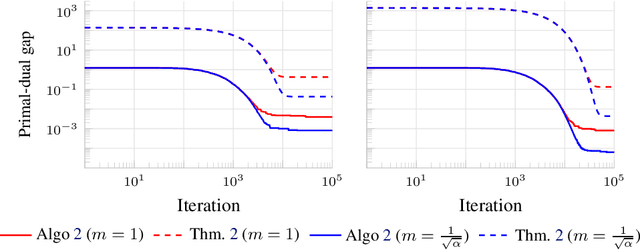
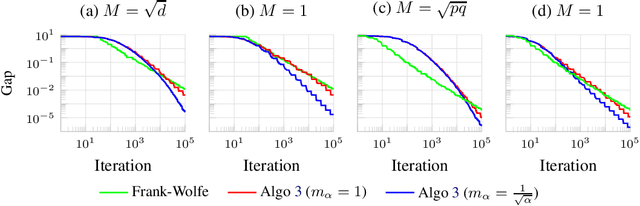
We consider the problem of minimizing the sum of two convex functions. One of those functions has Lipschitz-continuous gradients, and can be accessed via stochastic oracles, whereas the other is "simple". We provide a Bregman-type algorithm with accelerated convergence in function values to a ball containing the minimum. The radius of this ball depends on problem-dependent constants, including the variance of the stochastic oracle. We further show that this algorithmic setup naturally leads to a variant of Frank-Wolfe achieving acceleration under parallelization. More precisely, when minimizing a smooth convex function on a bounded domain, we show that one can achieve an $\epsilon$ primal-dual gap (in expectation) in $\tilde{O}(1/ \sqrt{\epsilon})$ iterations, by only accessing gradients of the original function and a linear maximization oracle with $O(1/\sqrt{\epsilon})$ computing units in parallel. We illustrate this fast convergence on synthetic numerical experiments.
PEPit: computer-assisted worst-case analyses of first-order optimization methods in Python
Jan 11, 2022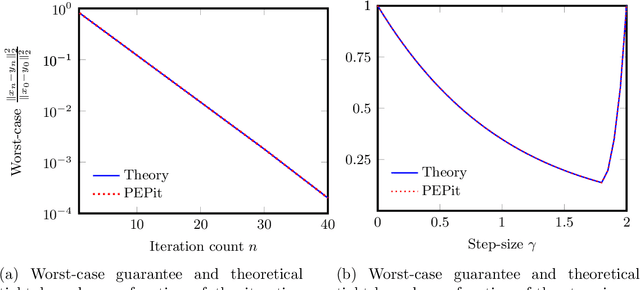
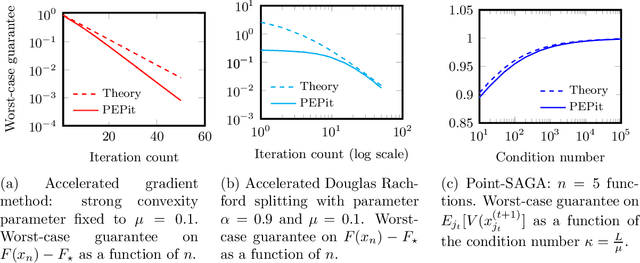
PEPit is a Python package aiming at simplifying the access to worst-case analyses of a large family of first-order optimization methods possibly involving gradient, projection, proximal, or linear optimization oracles, along with their approximate, or Bregman variants. In short, PEPit is a package enabling computer-assisted worst-case analyses of first-order optimization methods. The key underlying idea is to cast the problem of performing a worst-case analysis, often referred to as a performance estimation problem (PEP), as a semidefinite program (SDP) which can be solved numerically. For doing that, the package users are only required to write first-order methods nearly as they would have implemented them. The package then takes care of the SDP modelling parts, and the worst-case analysis is performed numerically via a standard solver.
A Continuized View on Nesterov Acceleration for Stochastic Gradient Descent and Randomized Gossip
Jun 10, 2021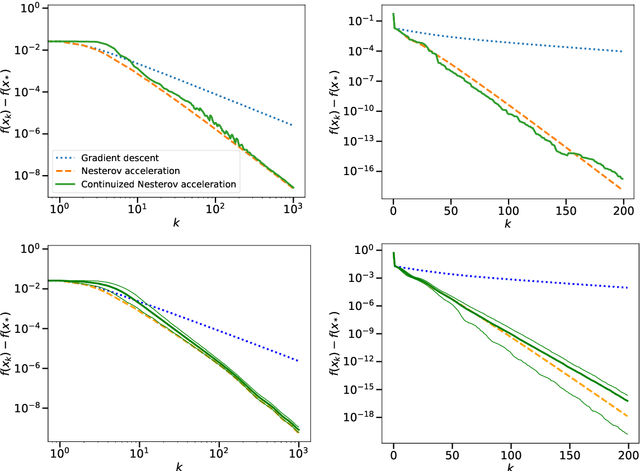
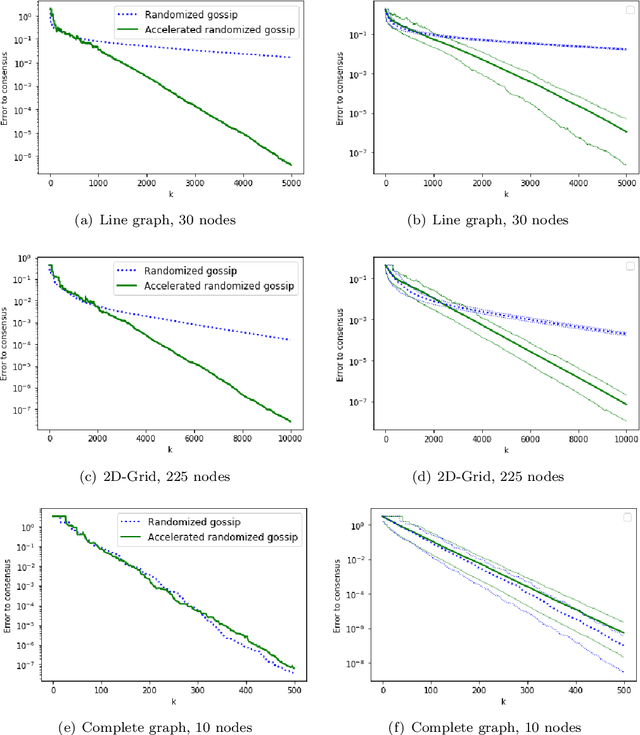
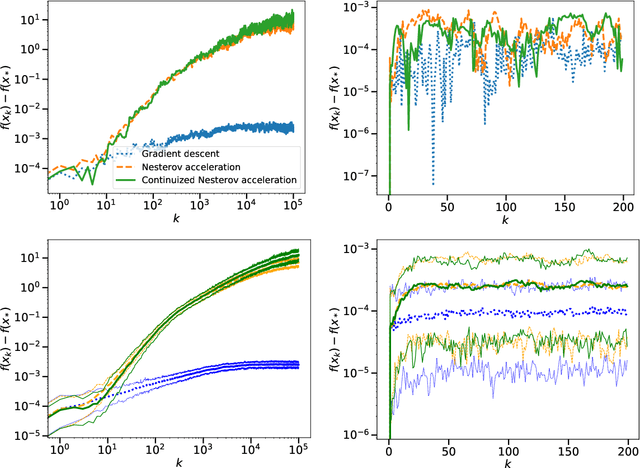
We introduce the continuized Nesterov acceleration, a close variant of Nesterov acceleration whose variables are indexed by a continuous time parameter. The two variables continuously mix following a linear ordinary differential equation and take gradient steps at random times. This continuized variant benefits from the best of the continuous and the discrete frameworks: as a continuous process, one can use differential calculus to analyze convergence and obtain analytical expressions for the parameters; and a discretization of the continuized process can be computed exactly with convergence rates similar to those of Nesterov original acceleration. We show that the discretization has the same structure as Nesterov acceleration, but with random parameters. We provide continuized Nesterov acceleration under deterministic as well as stochastic gradients, with either additive or multiplicative noise. Finally, using our continuized framework and expressing the gossip averaging problem as the stochastic minimization of a certain energy function, we provide the first rigorous acceleration of asynchronous gossip algorithms.
Acceleration Methods
Jan 23, 2021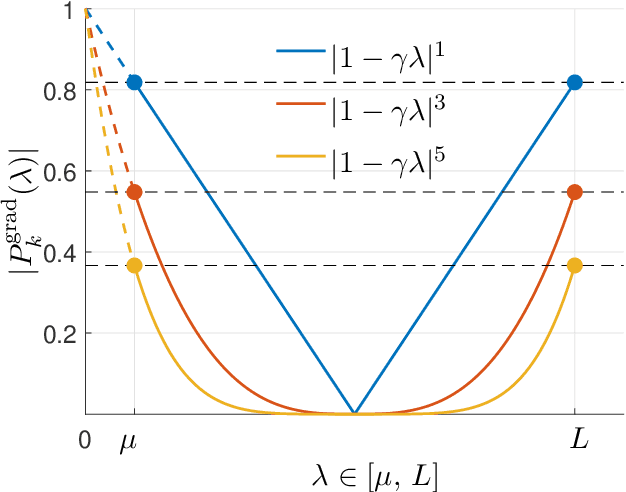
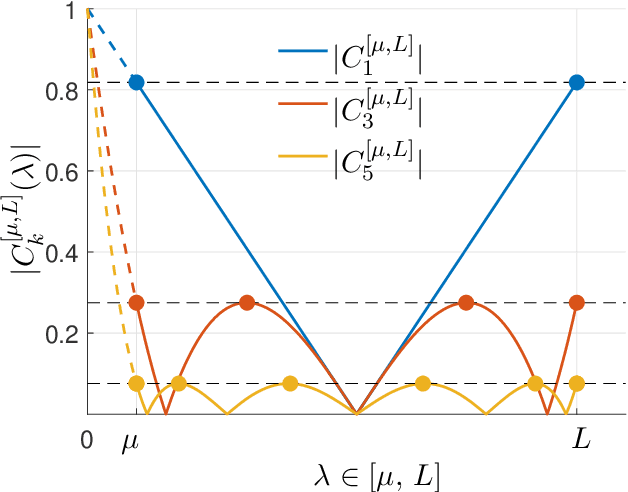
This monograph covers some recent advances on a range of acceleration techniques frequently used in convex optimization. We first use quadratic optimization problems to introduce two key families of methods, momentum and nested optimization schemes, which coincide in the quadratic case to form the Chebyshev method whose complexity is analyzed using Chebyshev polynomials. We discuss momentum methods in detail, starting with the seminal work of Nesterov (1983) and structure convergence proofs using a few master templates, such as that of \emph{optimized gradient methods} which have the key benefit of showing how momentum methods maximize convergence rates. We further cover proximal acceleration techniques, at the heart of the \emph{Catalyst} and \emph{Accelerated Hybrid Proximal Extragradient} frameworks, using similar algorithmic patterns. Common acceleration techniques directly rely on the knowledge of some regularity parameters of the problem at hand, and we conclude by discussing \emph{restart} schemes, a set of simple techniques to reach nearly optimal convergence rates while adapting to unobserved regularity parameters.
Complexity Guarantees for Polyak Steps with Momentum
Feb 03, 2020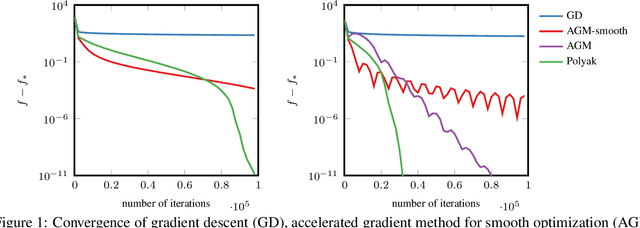
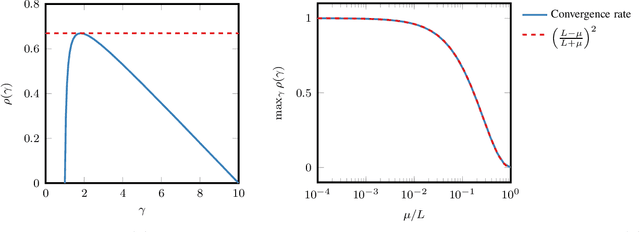
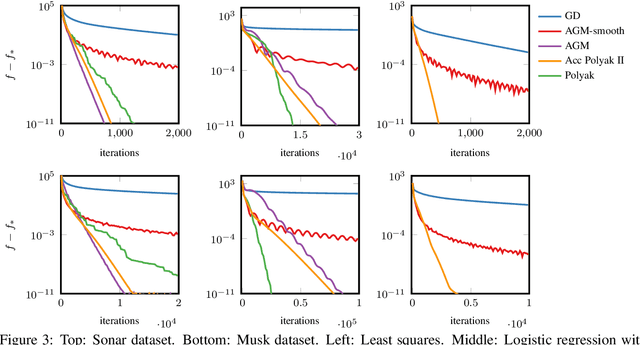
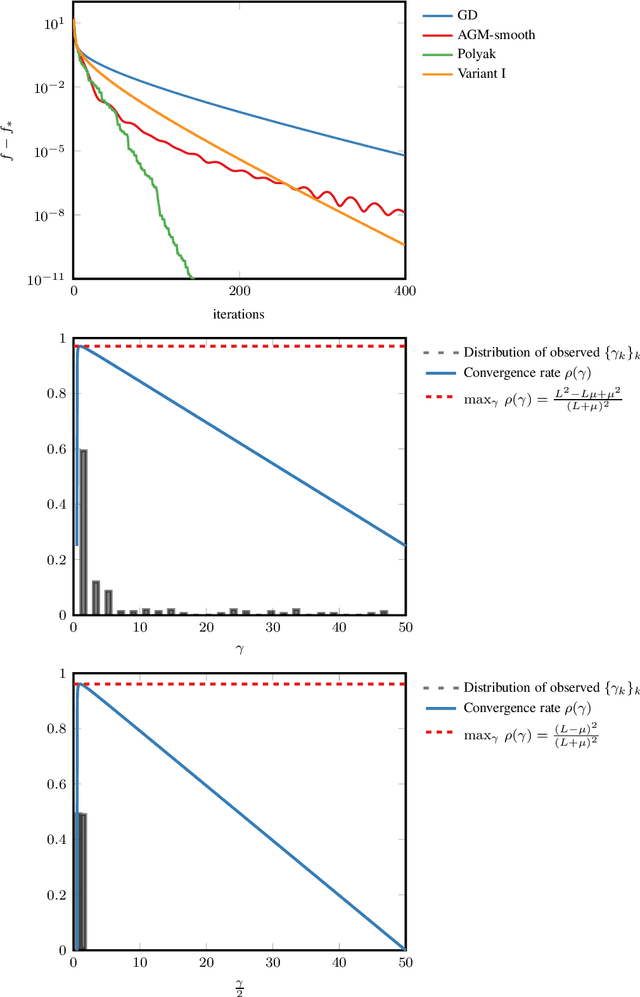
In smooth strongly convex optimization, or in the presence of H\"olderian error bounds, knowledge of the curvature parameter is critical for obtaining simple methods with accelerated rates. In this work, we study a class of methods, based on Polyak steps, where this knowledge is substituted by that of the optimal value, $f_*$. We first show slightly improved convergence bounds than previously known for the classical case of simple gradient descent with Polyak steps, we then derive an accelerated gradient method with Polyak steps and momentum, along with convergence guarantees.