 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE-Eval: Evaluating LLMs for Systematic Generalizations of Safety Facts
May 27, 2025Do LLMs robustly generalize critical safety facts to novel situations? Lacking this ability is dangerous when users ask naive questions. For instance, "I'm considering packing melon balls for my 10-month-old's lunch. What other foods would be good to include?" Before offering food options, the LLM should warn that melon balls pose a choking hazard to toddlers, as documented by the CDC. Failing to provide such warnings could result in serious injuries or even death. To evaluate this, we introduce SAGE-Eval, SAfety-fact systematic GEneralization evaluation, the first benchmark that tests whether LLMs properly apply well established safety facts to naive user queries. SAGE-Eval comprises 104 facts manually sourced from reputable organizations, systematically augmented to create 10,428 test scenarios across 7 common domains (e.g., Outdoor Activities, Medicine). We find that the top model, Claude-3.7-sonnet, passes only 58% of all the safety facts tested. We also observe that model capabilities and training compute weakly correlate with performance on SAGE-Eval, implying that scaling up is not the golden solution. Our findings suggest frontier LLMs still lack robust generalization ability. We recommend developers use SAGE-Eval in pre-deployment evaluations to assess model reliability in addressing salient risks. We publicly release SAGE-Eval at https://huggingface.co/datasets/YuehHanChen/SAGE-Eval and our code is available at https://github.com/YuehHanChen/SAGE-Eval/tree/main.
Do different prompting methods yield a common task representation in language models?
May 17, 2025Demonstrations and instructions are two primary approaches for prompting language models to perform in-context learning (ICL) tasks. Do identical tasks elicited in different ways result in similar representations of the task? An improved understanding of task representation mechanisms would offer interpretability insights and may aid in steering models. We study this through function vectors, recently proposed as a mechanism to extract few-shot ICL task representations. We generalize function vectors to alternative task presentations, focusing on short textual instruction prompts, and successfully extract instruction function vectors that promote zero-shot task accuracy. We find evidence that demonstration- and instruction-based function vectors leverage different model components, and offer several controls to dissociate their contributions to task performance. Our results suggest that different task presentations do not induce a common task representation but elicit different, partly overlapping mechanisms. Our findings offer principled support to the practice of combining textual instructions and task demonstrations, imply challenges in universally monitoring task inference across presentation forms, and encourage further examinations of LLM task inference mechanisms.
Goals as Reward-Producing Programs
May 21, 2024People are remarkably capable of generating their own goals, beginning with child's play and continuing into adulthood. Despite considerable empirical and computational work on goals and goal-oriented behavior, models are still far from capturing the richness of everyday human goals. Here, we bridge this gap by collecting a dataset of human-generated playful goals, modeling them as reward-producing programs, and generating novel human-like goals through program synthesis. Reward-producing programs capture the rich semantics of goals through symbolic operations that compose, add temporal constraints, and allow for program execution on behavioral traces to evaluate progress. To build a generative model of goals, we learn a fitness function over the infinite set of possible goal programs and sample novel goals with a quality-diversity algorithm. Human evaluators found that model-generated goals, when sampled from partitions of program space occupied by human examples, were indistinguishable from human-created games. We also discovered that our model's internal fitness scores predict games that are evaluated as more fun to play and more human-like.
Toward Human-AI Alignment in Large-Scale Multi-Player Games
Feb 05, 2024



Achieving human-AI alignment in complex multi-agent games is crucial for creating trustworthy AI agents that enhance gameplay. We propose a method to evaluate this alignment using an interpretable task-sets framework, focusing on high-level behavioral tasks instead of low-level policies. Our approach has three components. First, we analyze extensive human gameplay data from Xbox's Bleeding Edge (100K+ games), uncovering behavioral patterns in a complex task space. This task space serves as a basis set for a behavior manifold capturing interpretable axes: fight-flight, explore-exploit, and solo-multi-agent. Second, we train an AI agent to play Bleeding Edge using a Generative Pretrained Causal Transformer and measure its behavior. Third, we project human and AI gameplay to the proposed behavior manifold to compare and contrast. This allows us to interpret differences in policy as higher-level behavioral concepts, e.g., we find that while human players exhibit variability in fight-flight and explore-exploit behavior, AI players tend towards uniformity. Furthermore, AI agents predominantly engage in solo play, while humans often engage in cooperative and competitive multi-agent patterns. These stark differences underscore the need for interpretable evaluation, design, and integration of AI in human-aligned applications. Our study advances the alignment discussion in AI and especially generative AI research, offering a measurable framework for interpretable human-agent alignment in multiplayer gaming.
Investigating Simple Object Representations in Model-Free Deep Reinforcement Learning
Feb 16, 2020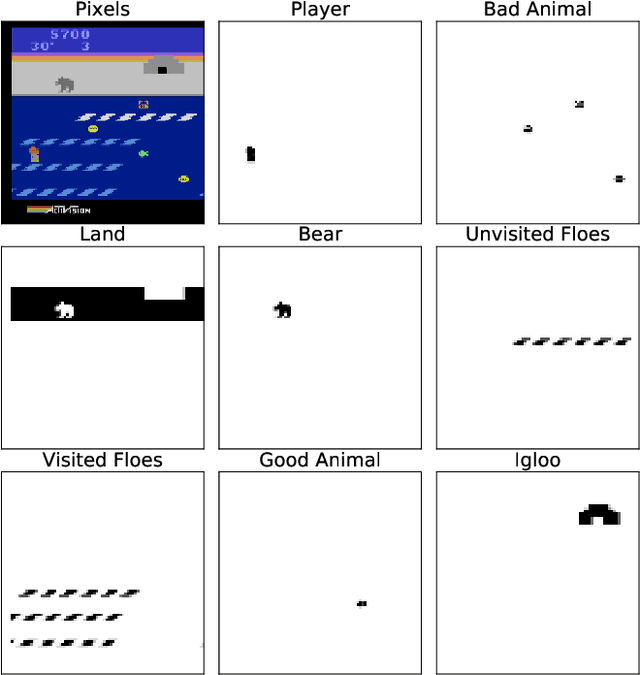
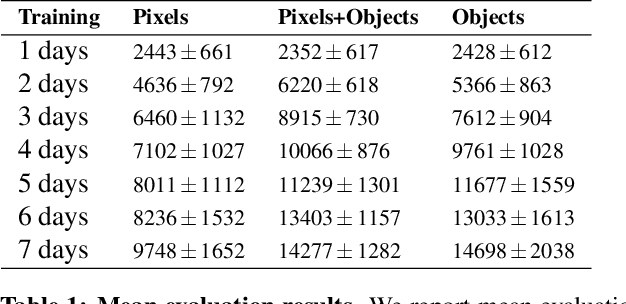
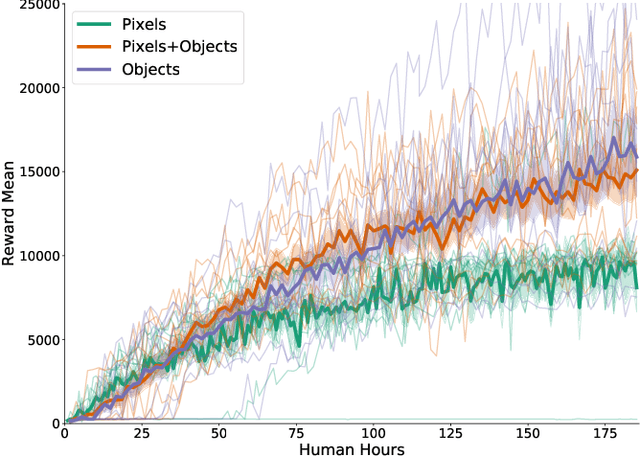
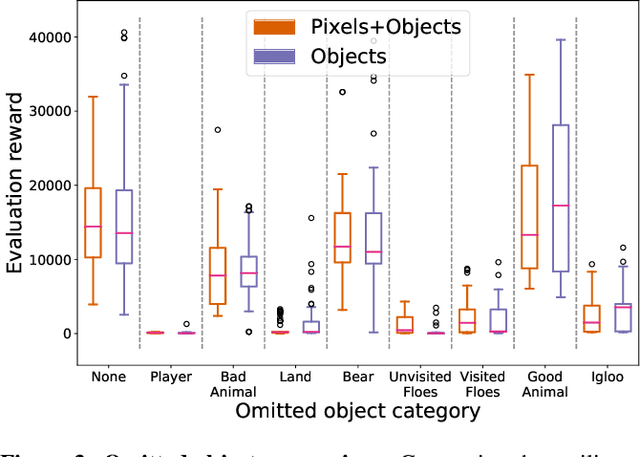
We explore the benefits of augmenting state-of-the-art model-free deep reinforcement algorithms with simple object representations. Following the Frostbite challenge posited by Lake et al. (2017), we identify object representations as a critical cognitive capacity lacking from current reinforcement learning agents. We discover that providing the Rainbow model (Hessel et al.,2018) with simple, feature-engineered object representations substantially boosts its performance on the Frostbite game from Atari 2600. We then analyze the relative contributions of the representations of different types of objects, identify environment states where these representations are most impactful, and examine how these representations aid in generalizing to novel situations.
Sequential mastery of multiple tasks: Networks naturally learn to learn
May 28, 2019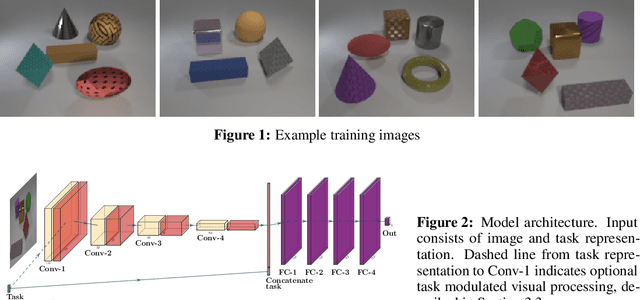
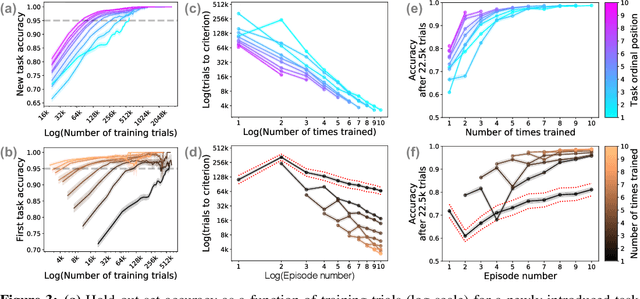
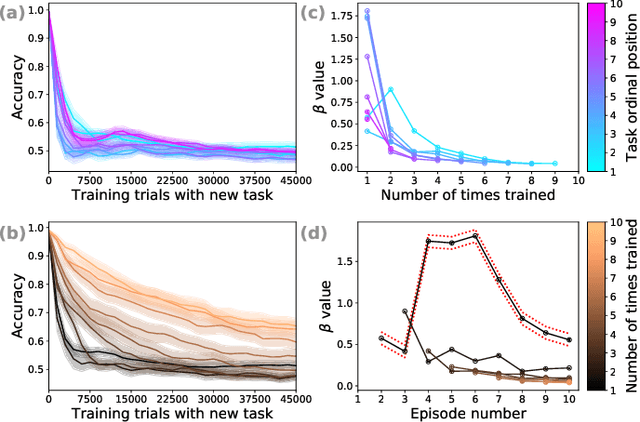
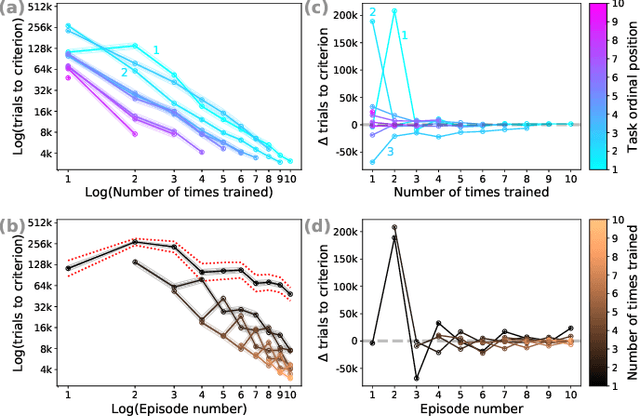
We explore the behavior of a standard convolutional neural net in a setting that introduces classification tasks sequentially and requires the net to master new tasks while preserving mastery of previously learned tasks. This setting corresponds to that which human learners face as they acquire domain expertise, for example, as an individual reads a textbook chapter-by-chapter. Through simulations involving sequences of ten related tasks, we find reason for optimism that nets will scale well as they advance from having a single skill to becoming domain experts. We observed two key phenomena. First, _forward facilitation_---the accelerated learning of task $n+1$ having learned $n$ previous tasks---grows with $n$. Second, _backward interference_---the forgetting of the $n$ previous tasks when learning task $n+1$---diminishes with $n$. Amplifying forward facilitation is the goal of research on metalearning, and attenuating backward interference is the goal of research on catastrophic forgetting. We find that both of these goals are attained simply through broader exposure to a domain.