 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo different prompting methods yield a common task representation in language models?
May 17, 2025Demonstrations and instructions are two primary approaches for prompting language models to perform in-context learning (ICL) tasks. Do identical tasks elicited in different ways result in similar representations of the task? An improved understanding of task representation mechanisms would offer interpretability insights and may aid in steering models. We study this through function vectors, recently proposed as a mechanism to extract few-shot ICL task representations. We generalize function vectors to alternative task presentations, focusing on short textual instruction prompts, and successfully extract instruction function vectors that promote zero-shot task accuracy. We find evidence that demonstration- and instruction-based function vectors leverage different model components, and offer several controls to dissociate their contributions to task performance. Our results suggest that different task presentations do not induce a common task representation but elicit different, partly overlapping mechanisms. Our findings offer principled support to the practice of combining textual instructions and task demonstrations, imply challenges in universally monitoring task inference across presentation forms, and encourage further examinations of LLM task inference mechanisms.
H-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark
Sep 02, 2024



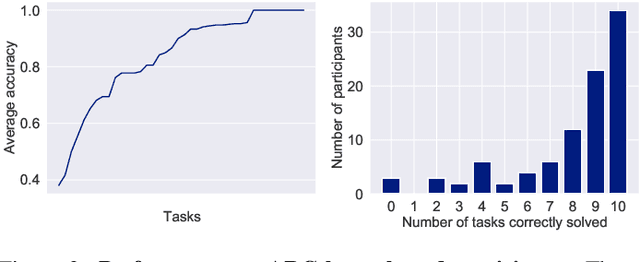
The Abstraction and Reasoning Corpus (ARC) is a visual program synthesis benchmark designed to test challenging out-of-distribution generalization in humans and machines. Since 2019, limited progress has been observed on the challenge using existing artificial intelligence methods. Comparing human and machine performance is important for the validity of the benchmark. While previous work explored how well humans can solve tasks from the ARC benchmark, they either did so using only a subset of tasks from the original dataset, or from variants of ARC, and therefore only provided a tentative estimate of human performance. In this work, we obtain a more robust estimate of human performance by evaluating 1729 humans on the full set of 400 training and 400 evaluation tasks from the original ARC problem set. We estimate that average human performance lies between 73.3% and 77.2% correct with a reported empirical average of 76.2% on the training set, and between 55.9% and 68.9% correct with a reported empirical average of 64.2% on the public evaluation set. However, we also find that 790 out of the 800 tasks were solvable by at least one person in three attempts, suggesting that the vast majority of the publicly available ARC tasks are in principle solvable by typical crowd-workers recruited over the internet. Notably, while these numbers are slightly lower than earlier estimates, human performance still greatly exceeds current state-of-the-art approaches for solving ARC. To facilitate research on ARC, we publicly release our dataset, called H-ARC (human-ARC), which includes all of the submissions and action traces from human participants.
Goals as Reward-Producing Programs
May 21, 2024People are remarkably capable of generating their own goals, beginning with child's play and continuing into adulthood. Despite considerable empirical and computational work on goals and goal-oriented behavior, models are still far from capturing the richness of everyday human goals. Here, we bridge this gap by collecting a dataset of human-generated playful goals, modeling them as reward-producing programs, and generating novel human-like goals through program synthesis. Reward-producing programs capture the rich semantics of goals through symbolic operations that compose, add temporal constraints, and allow for program execution on behavioral traces to evaluate progress. To build a generative model of goals, we learn a fitness function over the infinite set of possible goal programs and sample novel goals with a quality-diversity algorithm. Human evaluators found that model-generated goals, when sampled from partitions of program space occupied by human examples, were indistinguishable from human-created games. We also discovered that our model's internal fitness scores predict games that are evaluated as more fun to play and more human-like.
Fast and flexible: Human program induction in abstract reasoning tasks
Mar 10, 2021

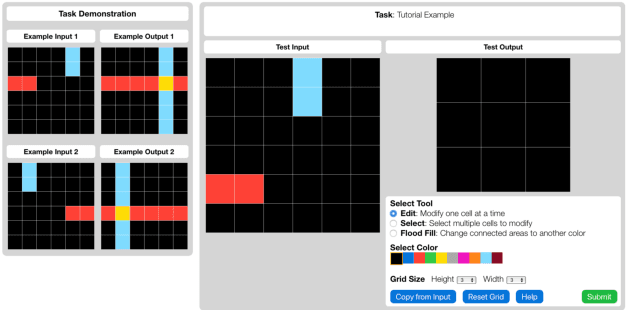
The Abstraction and Reasoning Corpus (ARC) is a challenging program induction dataset that was recently proposed by Chollet (2019). Here, we report the first set of results collected from a behavioral study of humans solving a subset of tasks from ARC (40 out of 1000). Although this subset of tasks contains considerable variation, our results showed that humans were able to infer the underlying program and generate the correct test output for a novel test input example, with an average of 80% of tasks solved per participant, and with 65% of tasks being solved by more than 80% of participants. Additionally, we find interesting patterns of behavioral consistency and variability within the action sequences during the generation process, the natural language descriptions to describe the transformations for each task, and the errors people made. Our findings suggest that people can quickly and reliably determine the relevant features and properties of a task to compose a correct solution. Future modeling work could incorporate these findings, potentially by connecting the natural language descriptions we collected here to the underlying semantics of ARC.
Question Asking as Program Generation
Nov 16, 2017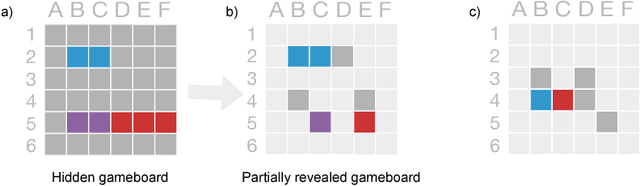

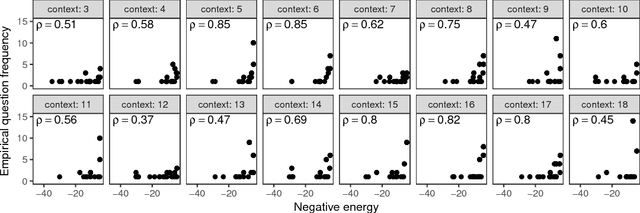

A hallmark of human intelligence is the ability to ask rich, creative, and revealing questions. Here we introduce a cognitive model capable of constructing human-like questions. Our approach treats questions as formal programs that, when executed on the state of the world, output an answer. The model specifies a probability distribution over a complex, compositional space of programs, favoring concise programs that help the agent learn in the current context. We evaluate our approach by modeling the types of open-ended questions generated by humans who were attempting to learn about an ambiguous situation in a game. We find that our model predicts what questions people will ask, and can creatively produce novel questions that were not present in the training set. In addition, we compare a number of model variants, finding that both question informativeness and complexity are important for producing human-like questions.
* Published in Advances in Neural Information Processing Systems (NIPS) 30, December 2017