 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Speech and Gesture Synthesis
Aug 25, 2021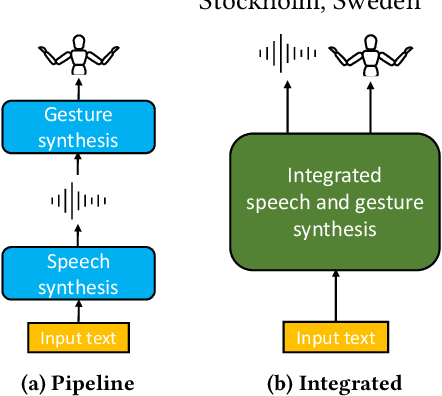

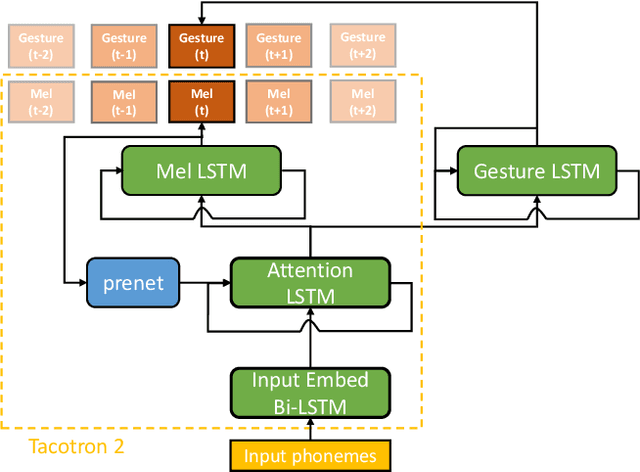
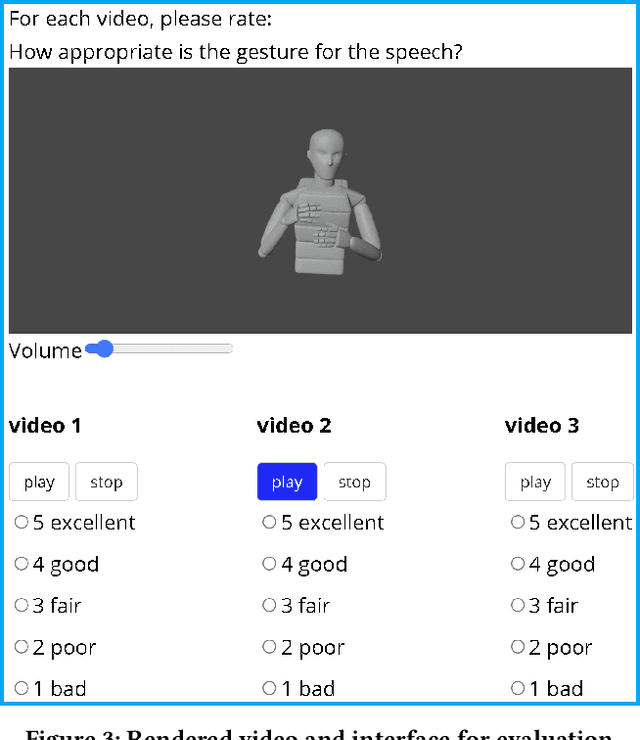
Text-to-speech and co-speech gesture synthesis have until now been treated as separate areas by two different research communities, and applications merely stack the two technologies using a simple system-level pipeline. This can lead to modeling inefficiencies and may introduce inconsistencies that limit the achievable naturalness. We propose to instead synthesize the two modalities in a single model, a new problem we call integrated speech and gesture synthesis (ISG). We also propose a set of models modified from state-of-the-art neural speech-synthesis engines to achieve this goal. We evaluate the models in three carefully-designed user studies, two of which evaluate the synthesized speech and gesture in isolation, plus a combined study that evaluates the models like they will be used in real-world applications -- speech and gesture presented together. The results show that participants rate one of the proposed integrated synthesis models as being as good as the state-of-the-art pipeline system we compare against, in all three tests. The model is able to achieve this with faster synthesis time and greatly reduced parameter count compared to the pipeline system, illustrating some of the potential benefits of treating speech and gesture synthesis together as a single, unified problem. Videos and code are available on our project page at https://swatsw.github.io/isg_icmi21/
Multimodal analysis of the predictability of hand-gesture properties
Aug 12, 2021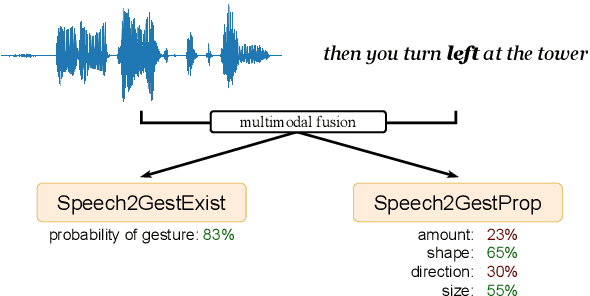
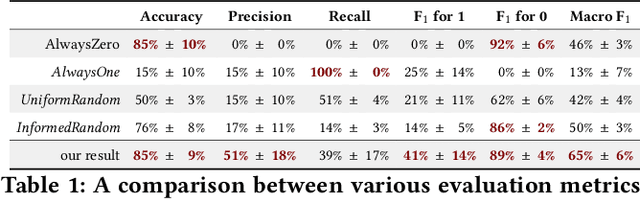
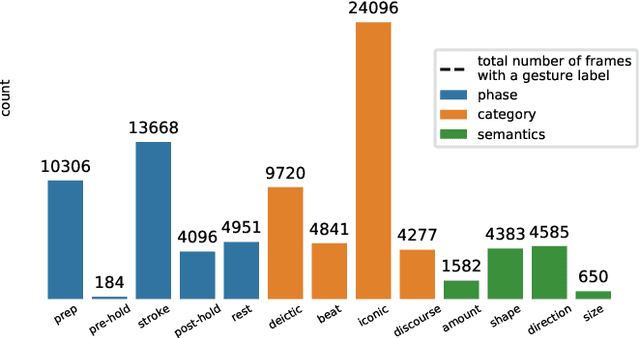
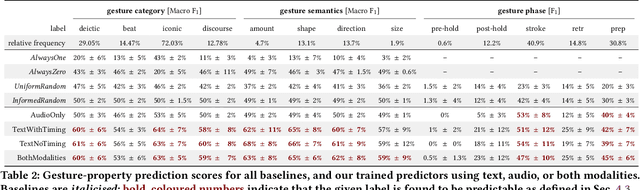
Embodied conversational agents benefit from being able to accompany their speech with gestures. Although many data-driven approaches to gesture generation have been proposed in recent years, it is still unclear whether such systems can consistently generate gestures that convey meaning. We investigate which gesture properties (phase, category, and semantics) can be predicted from speech text and/or audio using contemporary deep learning. In extensive experiments, we show that gesture properties related to gesture meaning (semantics and category) are predictable from text features (time-aligned BERT embeddings) alone, but not from prosodic audio features, while rhythm-related gesture properties (phase) on the other hand can be predicted from either audio, text (with word-level timing information), or both. These results are encouraging as they indicate that it is possible to equip an embodied agent with content-wise meaningful co-speech gestures using a machine-learning model.
Normalizing Flow based Hidden Markov Models for Classification of Speech Phones with Explainability
Jul 01, 2021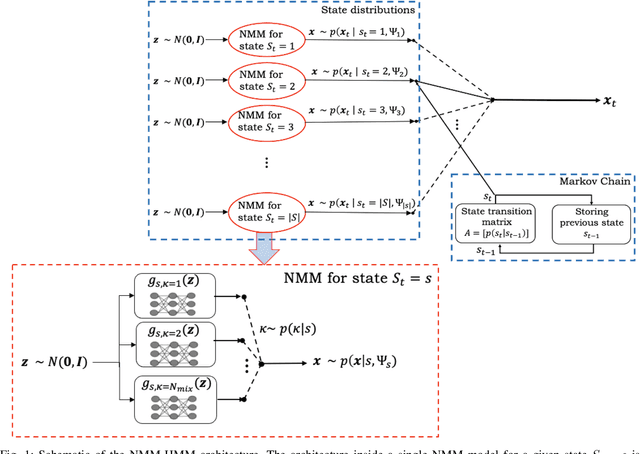
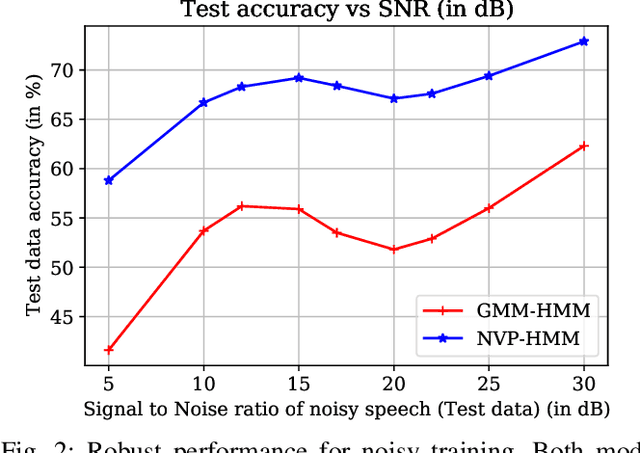
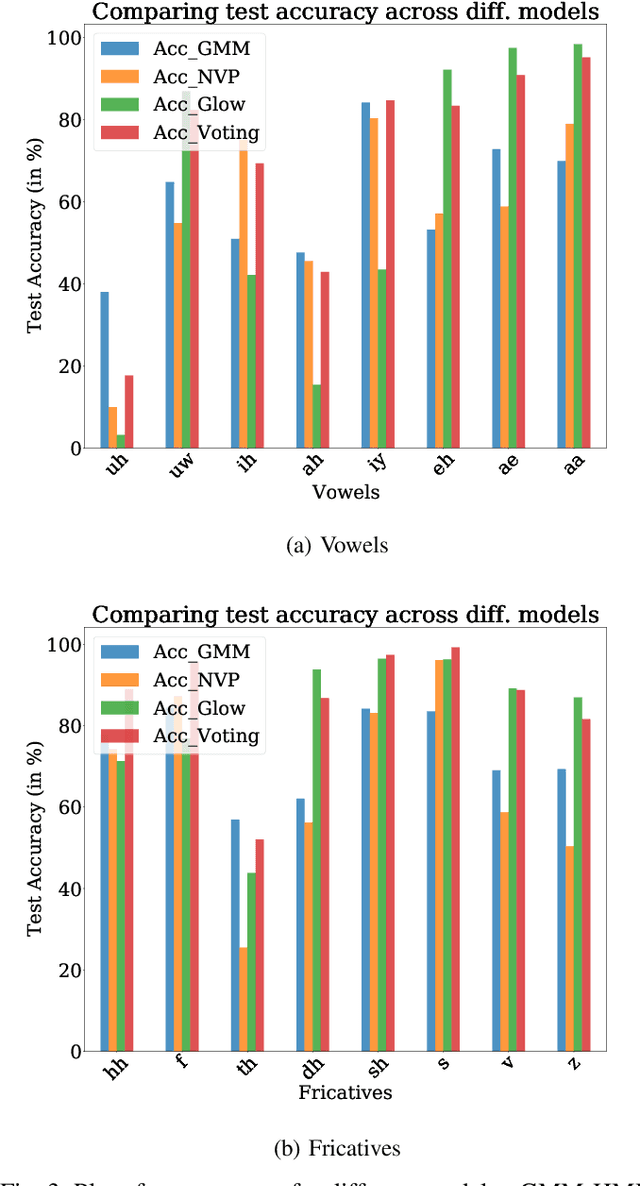

In pursuit of explainability, we develop generative models for sequential data. The proposed models provide state-of-the-art classification results and robust performance for speech phone classification. We combine modern neural networks (normalizing flows) and traditional generative models (hidden Markov models - HMMs). Normalizing flow-based mixture models (NMMs) are used to model the conditional probability distribution given the hidden state in the HMMs. Model parameters are learned through judicious combinations of time-tested Bayesian learning methods and contemporary neural network learning methods. We mainly combine expectation-maximization (EM) and mini-batch gradient descent. The proposed generative models can compute likelihood of a data and hence directly suitable for maximum-likelihood (ML) classification approach. Due to structural flexibility of HMMs, we can use different normalizing flow models. This leads to different types of HMMs providing diversity in data modeling capacity. The diversity provides an opportunity for easy decision fusion from different models. For a standard speech phone classification setup involving 39 phones (classes) and the TIMIT dataset, we show that the use of standard features called mel-frequency-cepstral-coeffcients (MFCCs), the proposed generative models, and the decision fusion together can achieve $86.6\%$ accuracy by generative training only. This result is close to state-of-the-art results, for examples, $86.2\%$ accuracy of PyTorch-Kaldi toolkit [1], and $85.1\%$ accuracy using light gated recurrent units [2]. We do not use any discriminative learning approach and related sophisticated features in this article.
Speech2Properties2Gestures: Gesture-Property Prediction as a Tool for Generating Representational Gestures from Speech
Jun 28, 2021
We propose a new framework for gesture generation, aiming to allow data-driven approaches to produce more semantically rich gestures. Our approach first predicts whether to gesture, followed by a prediction of the gesture properties. Those properties are then used as conditioning for a modern probabilistic gesture-generation model capable of high-quality output. This empowers the approach to generate gestures that are both diverse and representational.
Transflower: probabilistic autoregressive dance generation with multimodal attention
Jun 25, 2021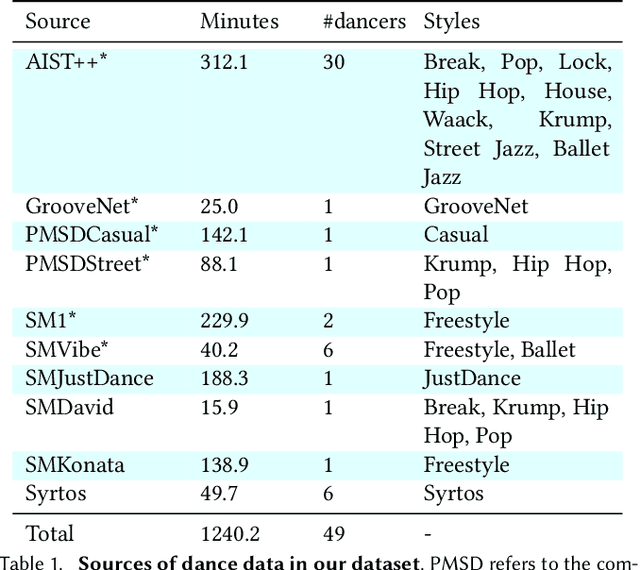
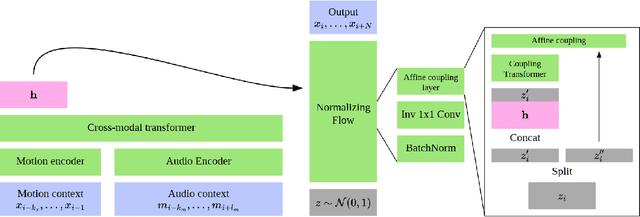
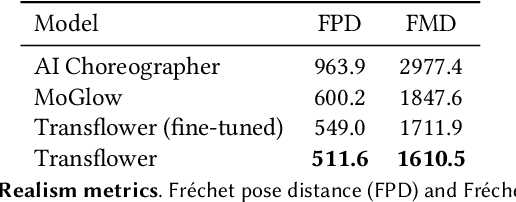

Dance requires skillful composition of complex movements that follow rhythmic, tonal and timbral features of music. Formally, generating dance conditioned on a piece of music can be expressed as a problem of modelling a high-dimensional continuous motion signal, conditioned on an audio signal. In this work we make two contributions to tackle this problem. First, we present a novel probabilistic autoregressive architecture that models the distribution over future poses with a normalizing flow conditioned on previous poses as well as music context, using a multimodal transformer encoder. Second, we introduce the currently largest 3D dance-motion dataset, obtained with a variety of motion-capture technologies, and including both professional and casual dancers. Using this dataset, we compare our new model against two baselines, via objective metrics and a user study, and show that both the ability to model a probability distribution, as well as being able to attend over a large motion and music context are necessary to produce interesting, diverse, and realistic dance that matches the music.
The Case for Translation-Invariant Self-Attention in Transformer-Based Language Models
Jun 03, 2021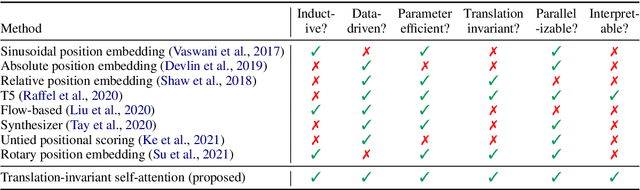
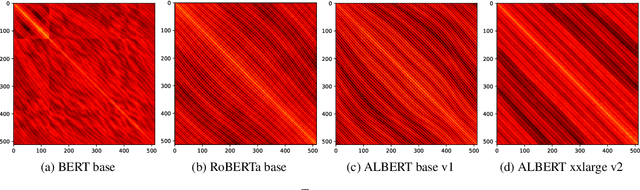
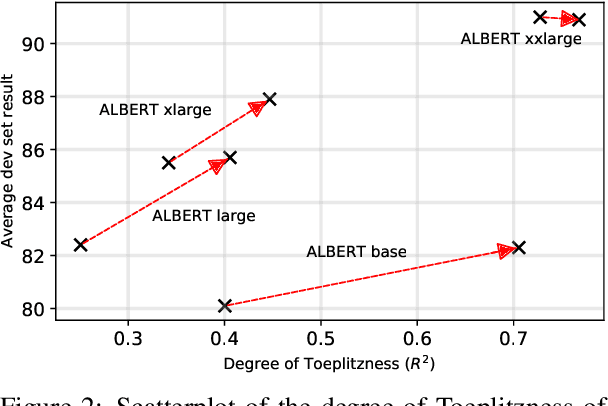
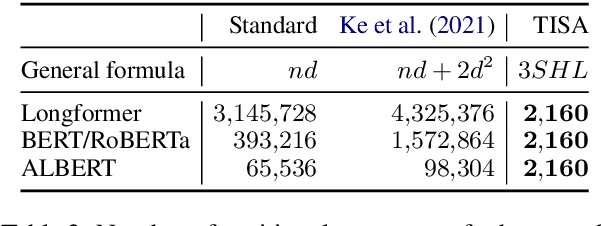
Mechanisms for encoding positional information are central for transformer-based language models. In this paper, we analyze the position embeddings of existing language models, finding strong evidence of translation invariance, both for the embeddings themselves and for their effect on self-attention. The degree of translation invariance increases during training and correlates positively with model performance. Our findings lead us to propose translation-invariant self-attention (TISA), which accounts for the relative position between tokens in an interpretable fashion without needing conventional position embeddings. Our proposal has several theoretical advantages over existing position-representation approaches. Experiments show that it improves on regular ALBERT on GLUE tasks, while only adding orders of magnitude less positional parameters.
Robust Classification using Hidden Markov Models and Mixtures of Normalizing Flows
Feb 15, 2021

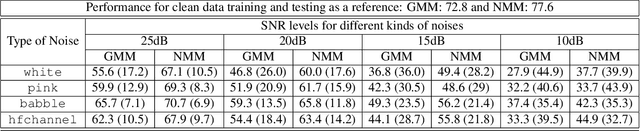
We test the robustness of a maximum-likelihood (ML) based classifier where sequential data as observation is corrupted by noise. The hypothesis is that a generative model, that combines the state transitions of a hidden Markov model (HMM) and the neural network based probability distributions for the hidden states of the HMM, can provide a robust classification performance. The combined model is called normalizing-flow mixture model based HMM (NMM-HMM). It can be trained using a combination of expectation-maximization (EM) and backpropagation. We verify the improved robustness of NMM-HMM classifiers in an application to speech recognition.
Generating coherent spontaneous speech and gesture from text
Jan 14, 2021
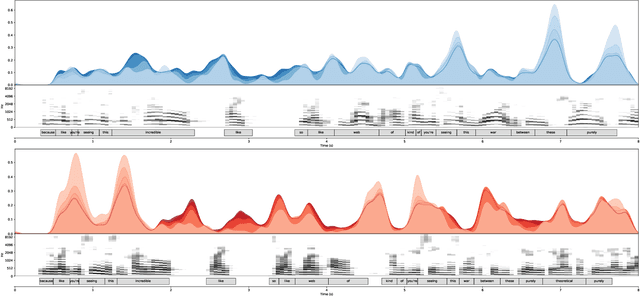
Embodied human communication encompasses both verbal (speech) and non-verbal information (e.g., gesture and head movements). Recent advances in machine learning have substantially improved the technologies for generating synthetic versions of both of these types of data: On the speech side, text-to-speech systems are now able to generate highly convincing, spontaneous-sounding speech using unscripted speech audio as the source material. On the motion side, probabilistic motion-generation methods can now synthesise vivid and lifelike speech-driven 3D gesticulation. In this paper, we put these two state-of-the-art technologies together in a coherent fashion for the first time. Concretely, we demonstrate a proof-of-concept system trained on a single-speaker audio and motion-capture dataset, that is able to generate both speech and full-body gestures together from text input. In contrast to previous approaches for joint speech-and-gesture generation, we generate full-body gestures from speech synthesis trained on recordings of spontaneous speech from the same person as the motion-capture data. We illustrate our results by visualising gesture spaces and text-speech-gesture alignments, and through a demonstration video at https://simonalexanderson.github.io/IVA2020 .
* 3 pages, 2 figures, published at the ACM International Conference on Intelligent Virtual Agents (IVA) 2020
Full-Glow: Fully conditional Glow for more realistic image generation
Dec 10, 2020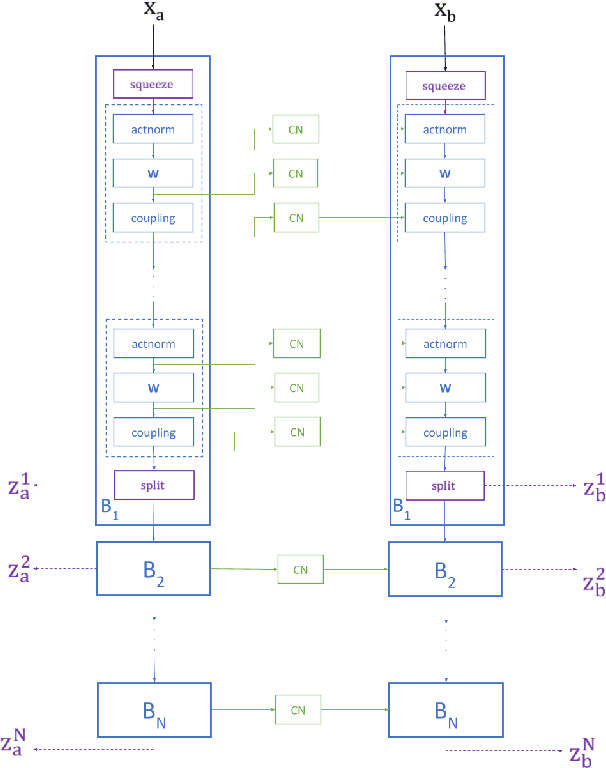
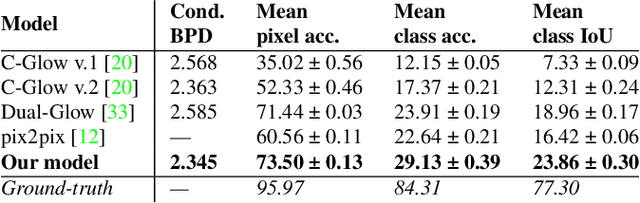


Autonomous agents, such as driverless cars, require large amounts of labeled visual data for their training. A viable approach for acquiring such data is training a generative model with collected real data, and then augmenting the collected real dataset with synthetic images from the model, generated with control of the scene layout and ground truth labeling. In this paper we propose Full-Glow, a fully conditional Glow-based architecture for generating plausible and realistic images of novel street scenes given a semantic segmentation map indicating the scene layout. Benchmark comparisons show our model to outperform recent works in terms of the semantic segmentation performance of a pretrained PSPNet. This indicates that images from our model are, to a higher degree than from other models, similar to real images of the same kinds of scenes and objects, making them suitable as training data for a visual semantic segmentation or object recognition system.
Moving fast and slow: Analysis of representations and post-processing in speech-driven automatic gesture generation
Jul 16, 2020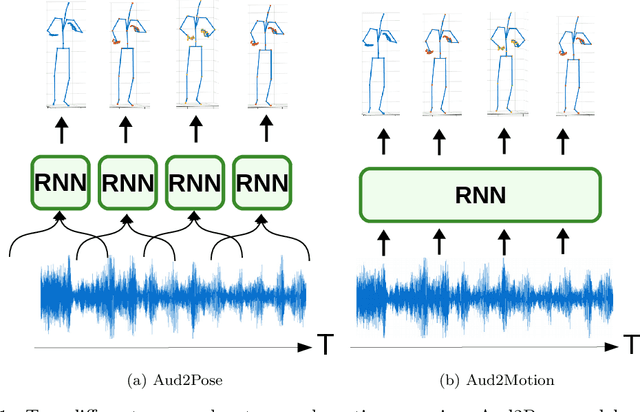
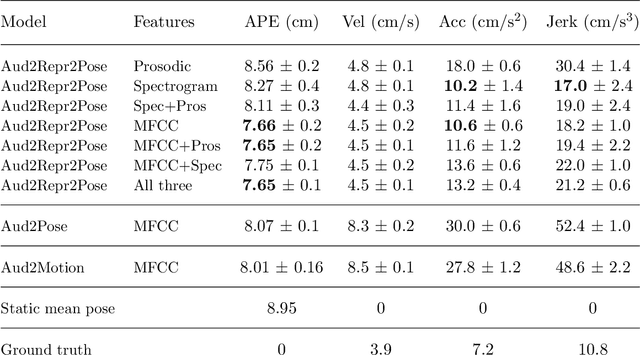


This paper presents a novel framework for speech-driven gesture production, applicable to virtual agents to enhance human-computer interaction. Specifically, we extend recent deep-learning-based, data-driven methods for speech-driven gesture generation by incorporating representation learning. Our model takes speech as input and produces gestures as output, in the form of a sequence of 3D coordinates. We provide an analysis of different representations for the input (speech) and the output (motion) of the network by both objective and subjective evaluations. We also analyse the importance of smoothing of the produced motion. Our results indicated that the proposed method improved on our baseline in terms of objective measures. For example, it better captured the motion dynamics and better matched the motion-speed distribution. Moreover, we performed user studies on two different datasets. The studies confirmed that our proposed method is perceived as more natural than the baseline, although the difference in the studies was eliminated by appropriate post-processing: hip-centering and smoothing. We conclude that it is important to take both feature representation, model architecture and post-processing into account when designing an automatic gesture-production method.