 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-specific kernel-based hidden Markov model for time series analysis
Jan 24, 2023



Traditional hidden Markov models have been a useful tool to understand and model stochastic dynamic linear data; in the case of non-Gaussian data or not linear in mean data, models such as mixture of Gaussian hidden Markov models suffer from the computation of precision matrices and have a lot of unnecessary parameters. As a consequence, such models often perform better when it is assumed that all variables are independent, a hypothesis that may be unrealistic. Hidden Markov models based on kernel density estimation is also capable of modeling non Gaussian data, but they assume independence between variables. In this article, we introduce a new hidden Markov model based on kernel density estimation, which is capable of introducing kernel dependencies using context-specific Bayesian networks. The proposed model is described, together with a learning algorithm based on the expectation-maximization algorithm. Additionally, the model is compared with related HMMs using synthetic and real data. From the results, the benefits in likelihood and classification accuracy from the proposed model are quantified and analyzed.
A Comprehensive Review of Data-Driven Co-Speech Gesture Generation
Jan 13, 2023Gestures that accompany speech are an essential part of natural and efficient embodied human communication. The automatic generation of such co-speech gestures is a long-standing problem in computer animation and is considered an enabling technology in film, games, virtual social spaces, and for interaction with social robots. The problem is made challenging by the idiosyncratic and non-periodic nature of human co-speech gesture motion, and by the great diversity of communicative functions that gestures encompass. Gesture generation has seen surging interest recently, owing to the emergence of more and larger datasets of human gesture motion, combined with strides in deep-learning-based generative models, that benefit from the growing availability of data. This review article summarizes co-speech gesture generation research, with a particular focus on deep generative models. First, we articulate the theory describing human gesticulation and how it complements speech. Next, we briefly discuss rule-based and classical statistical gesture synthesis, before delving into deep learning approaches. We employ the choice of input modalities as an organizing principle, examining systems that generate gestures from audio, text, and non-linguistic input. We also chronicle the evolution of the related training data sets in terms of size, diversity, motion quality, and collection method. Finally, we identify key research challenges in gesture generation, including data availability and quality; producing human-like motion; grounding the gesture in the co-occurring speech in interaction with other speakers, and in the environment; performing gesture evaluation; and integration of gesture synthesis into applications. We highlight recent approaches to tackling the various key challenges, as well as the limitations of these approaches, and point toward areas of future development.
Prosody-controllable spontaneous TTS with neural HMMs
Nov 24, 2022Spontaneous speech has many affective and pragmatic functions that are interesting and challenging to model in TTS (text-to-speech). However, the presence of reduced articulation, fillers, repetitions, and other disfluencies mean that text and acoustics are less well aligned than in read speech. This is problematic for attention-based TTS. We propose a TTS architecture that is particularly suited for rapidly learning to speak from irregular and small datasets while also reproducing the diversity of expressive phenomena present in spontaneous speech. Specifically, we modify an existing neural HMM-based TTS system, which is capable of stable, monotonic alignments for spontaneous speech, and add utterance-level prosody control, so that the system can represent the wide range of natural variability in a spontaneous speech corpus. We objectively evaluate control accuracy and perform a subjective listening test to compare to a system without prosody control. To exemplify the power of combining mid-level prosody control and ecologically valid data for reproducing intricate spontaneous speech phenomena, we evaluate the system's capability of synthesizing two types of creaky phonation. Audio samples are available at https://hfkml.github.io/pc_nhmm_tts/
Listen, denoise, action! Audio-driven motion synthesis with diffusion models
Nov 17, 2022



Diffusion models have experienced a surge of interest as highly expressive yet efficiently trainable probabilistic models. We show that these models are an excellent fit for synthesising human motion that co-occurs with audio, for example co-speech gesticulation, since motion is complex and highly ambiguous given audio, calling for a probabilistic description. Specifically, we adapt the DiffWave architecture to model 3D pose sequences, putting Conformers in place of dilated convolutions for improved accuracy. We also demonstrate control over motion style, using classifier-free guidance to adjust the strength of the stylistic expression. Gesture-generation experiments on the Trinity Speech-Gesture and ZeroEGGS datasets confirm that the proposed method achieves top-of-the-line motion quality, with distinctive styles whose expression can be made more or less pronounced. We also synthesise dance motion and path-driven locomotion using the same model architecture. Finally, we extend the guidance procedure to perform style interpolation in a manner that is appealing for synthesis tasks and has connections to product-of-experts models, a contribution we believe is of independent interest. Video examples are available at https://www.speech.kth.se/research/listen-denoise-action/
OverFlow: Putting flows on top of neural transducers for better TTS
Nov 13, 2022



Neural HMMs are a type of neural transducer recently proposed for sequence-to-sequence modelling in text-to-speech. They combine the best features of classic statistical speech synthesis and modern neural TTS, requiring less data and fewer training updates, and are less prone to gibberish output caused by neural attention failures. In this paper, we combine neural HMM TTS with normalising flows for describing the highly non-Gaussian distribution of speech acoustics. The result is a powerful, fully probabilistic model of durations and acoustics that can be trained using exact maximum likelihood. Compared to dominant flow-based acoustic models, our approach integrates autoregression for improved modelling of long-range dependences such as utterance-level prosody. Experiments show that a system based on our proposal gives more accurate pronunciations and better subjective speech quality than comparable methods, whilst retaining the original advantages of neural HMMs. Audio examples and code are available at https://shivammehta25.github.io/OverFlow/
Autovocoder: Fast Waveform Generation from a Learned Speech Representation using Differentiable Digital Signal Processing
Nov 13, 2022Most state-of-the-art Text-to-Speech systems use the mel-spectrogram as an intermediate representation, to decompose the task into acoustic modelling and waveform generation. A mel-spectrogram is extracted from the waveform by a simple, fast DSP operation, but generating a high-quality waveform from a mel-spectrogram requires computationally expensive machine learning: a neural vocoder. Our proposed ``autovocoder'' reverses this arrangement. We use machine learning to obtain a representation that replaces the mel-spectrogram, and that can be inverted back to a waveform using simple, fast operations including a differentiable implementation of the inverse STFT. The autovocoder generates a waveform 5 times faster than the DSP-based Griffin-Lim algorithm, and 14 times faster than the neural vocoder HiFi-GAN. We provide perceptual listening test results to confirm that the speech is of comparable quality to HiFi-GAN in the copy synthesis task.
Predicting pairwise preferences between TTS audio stimuli using parallel ratings data and anti-symmetric twin neural networks
Sep 22, 2022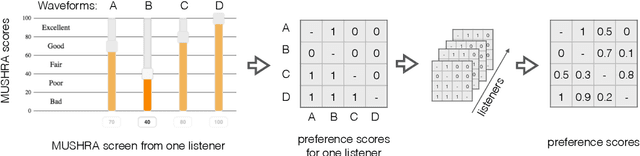
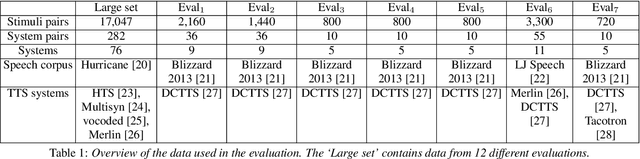
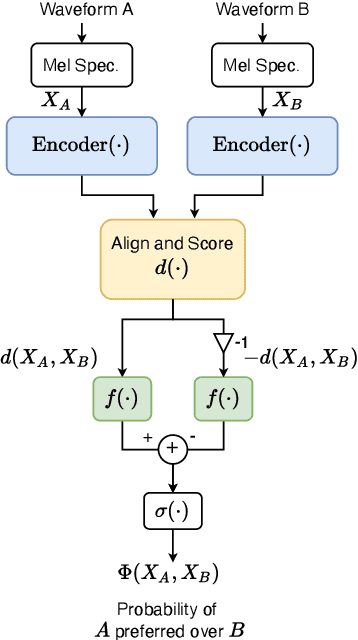
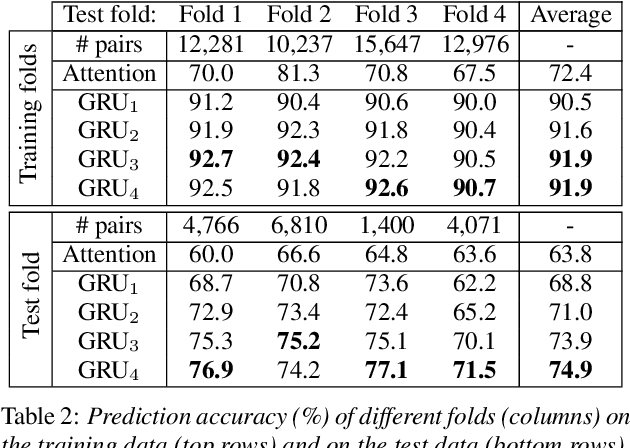
Automatically predicting the outcome of subjective listening tests is a challenging task. Ratings may vary from person to person even if preferences are consistent across listeners. While previous work has focused on predicting listeners' ratings (mean opinion scores) of individual stimuli, we focus on the simpler task of predicting subjective preference given two speech stimuli for the same text. We propose a model based on anti-symmetric twin neural networks, trained on pairs of waveforms and their corresponding preference scores. We explore both attention and recurrent neural nets to account for the fact that stimuli in a pair are not time aligned. To obtain a large training set we convert listeners' ratings from MUSHRA tests to values that reflect how often one stimulus in the pair was rated higher than the other. Specifically, we evaluate performance on data obtained from twelve MUSHRA evaluations conducted over five years, containing different TTS systems, built from data of different speakers. Our results compare favourably to a state-of-the-art model trained to predict MOS scores.
The GENEA Challenge 2022: A large evaluation of data-driven co-speech gesture generation
Aug 22, 2022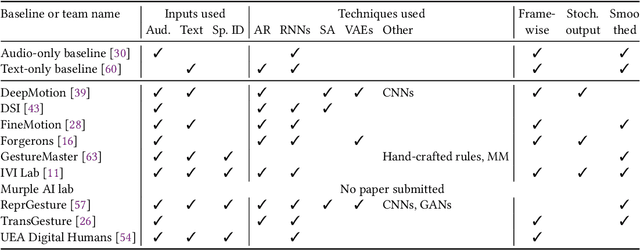
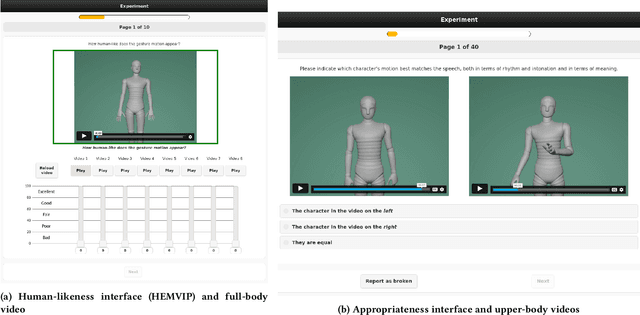
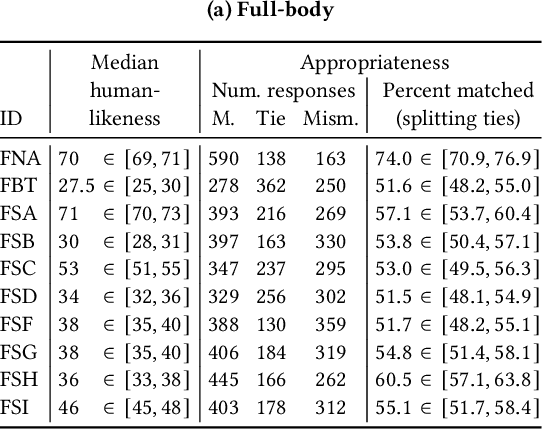
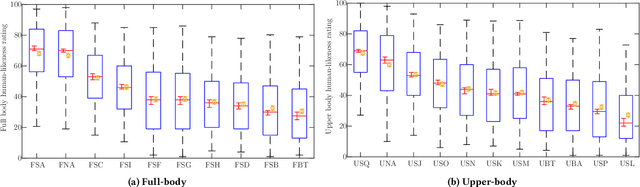
This paper reports on the second GENEA Challenge to benchmark data-driven automatic co-speech gesture generation. Participating teams used the same speech and motion dataset to build gesture-generation systems. Motion generated by all these systems was rendered to video using a standardised visualisation pipeline and evaluated in several large, crowdsourced user studies. Unlike when comparing different research papers, differences in results are here only due to differences between methods, enabling direct comparison between systems. This year's dataset was based on 18 hours of full-body motion capture, including fingers, of different persons engaging in dyadic conversation. Ten teams participated in the challenge across two tiers: full-body and upper-body gesticulation. For each tier we evaluated both the human-likeness of the gesture motion and its appropriateness for the specific speech signal. Our evaluations decouple human-likeness from gesture appropriateness, which previously was a major challenge in the field. The evaluation results are a revolution, and a revelation. Some synthetic conditions are rated as significantly more human-like than human motion capture. To the best of our knowledge, this has never been shown before on a high-fidelity avatar. On the other hand, all synthetic motion is found to be vastly less appropriate for the speech than the original motion-capture recordings. Additional material is available via the project website at https://youngwoo-yoon.github.io/GENEAchallenge2022/
Wavebender GAN: An architecture for phonetically meaningful speech manipulation
Feb 22, 2022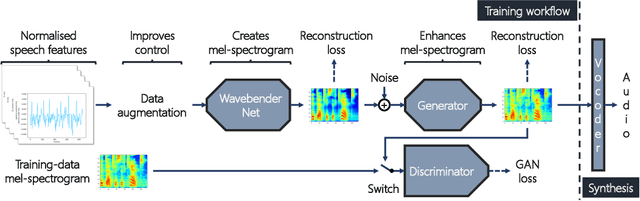
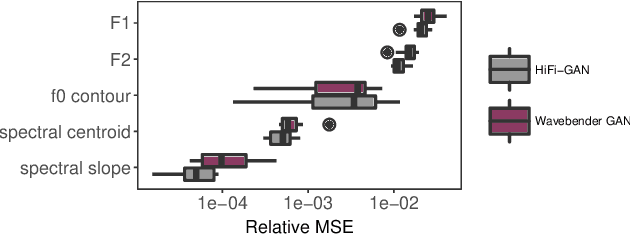
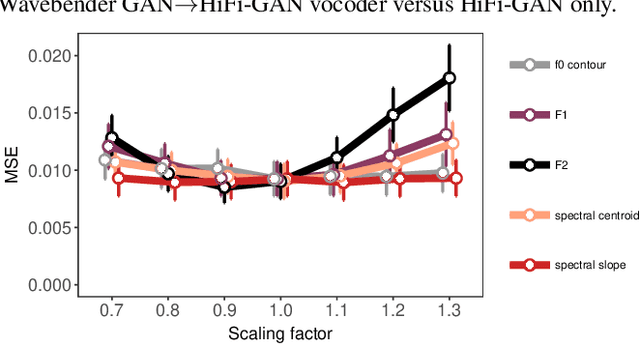
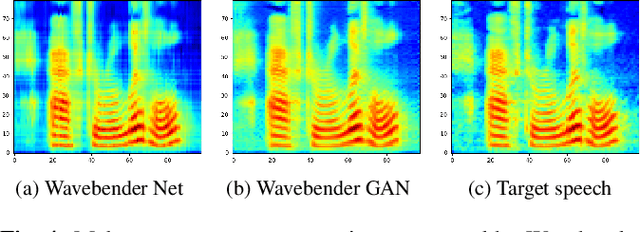
Deep learning has revolutionised synthetic speech quality. However, it has thus far delivered little value to the speech science community. The new methods do not meet the controllability demands that practitioners in this area require e.g.: in listening tests with manipulated speech stimuli. Instead, control of different speech properties in such stimuli is achieved by using legacy signal-processing methods. This limits the range, accuracy, and speech quality of the manipulations. Also, audible artefacts have a negative impact on the methodological validity of results in speech perception studies. This work introduces a system capable of manipulating speech properties through learning rather than design. The architecture learns to control arbitrary speech properties and leverages progress in neural vocoders to obtain realistic output. Experiments with copy synthesis and manipulation of a small set of core speech features (pitch, formants, and voice quality measures) illustrate the promise of the approach for producing speech stimuli that have accurate control and high perceptual quality.
Neural HMMs are all you need (for high-quality attention-free TTS)
Sep 03, 2021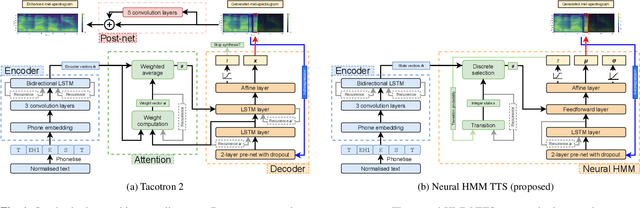
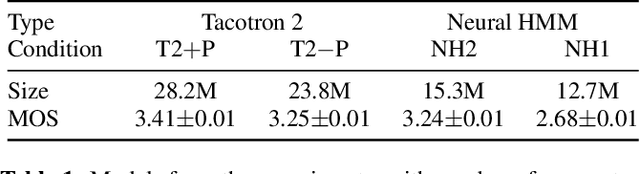
Neural sequence-to-sequence TTS has demonstrated significantly better output quality over classical statistical parametric speech synthesis using HMMs. However, the new paradigm is not probabilistic and the use of non-monotonic attention both increases training time and introduces "babbling" failure modes that are unacceptable in production. In this paper, we demonstrate that the old and new paradigms can be combined to obtain the advantages of both worlds, by replacing the attention in Tacotron 2 with an autoregressive left-right no-skip hidden Markov model defined by a neural network. This leads to an HMM-based neural TTS model with monotonic alignment, trained to maximise the full sequence likelihood without approximations. We discuss how to combine innovations from both classical and contemporary TTS for best results. The final system is smaller and simpler than Tacotron 2 and learns to align and speak with fewer iterations, whilst achieving the same naturalness prior to the post-net. Our system also allows easy control over speaking rate. Audio examples and code are available at https://shivammehta007.github.io/Neural-HMM/