 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised 3D Pose Transfer with Cross Consistency and Dual Reconstruction
Nov 18, 2022



The goal of 3D pose transfer is to transfer the pose from the source mesh to the target mesh while preserving the identity information (e.g., face, body shape) of the target mesh. Deep learning-based methods improved the efficiency and performance of 3D pose transfer. However, most of them are trained under the supervision of the ground truth, whose availability is limited in real-world scenarios. In this work, we present X-DualNet, a simple yet effective approach that enables unsupervised 3D pose transfer. In X-DualNet, we introduce a generator $G$ which contains correspondence learning and pose transfer modules to achieve 3D pose transfer. We learn the shape correspondence by solving an optimal transport problem without any key point annotations and generate high-quality meshes with our elastic instance normalization (ElaIN) in the pose transfer module. With $G$ as the basic component, we propose a cross consistency learning scheme and a dual reconstruction objective to learn the pose transfer without supervision. Besides that, we also adopt an as-rigid-as-possible deformer in the training process to fine-tune the body shape of the generated results. Extensive experiments on human and animal data demonstrate that our framework can successfully achieve comparable performance as the state-of-the-art supervised approaches.
IntegratedPIFu: Integrated Pixel Aligned Implicit Function for Single-view Human Reconstruction
Nov 15, 2022We propose IntegratedPIFu, a new pixel aligned implicit model that builds on the foundation set by PIFuHD. IntegratedPIFu shows how depth and human parsing information can be predicted and capitalised upon in a pixel-aligned implicit model. In addition, IntegratedPIFu introduces depth oriented sampling, a novel training scheme that improve any pixel aligned implicit model ability to reconstruct important human features without noisy artefacts. Lastly, IntegratedPIFu presents a new architecture that, despite using less model parameters than PIFuHD, is able to improves the structural correctness of reconstructed meshes. Our results show that IntegratedPIFu significantly outperforms existing state of the arts methods on single view human reconstruction. Our code has been made available online.
Indoor Smartphone SLAM with Learned Echoic Location Features
Oct 16, 2022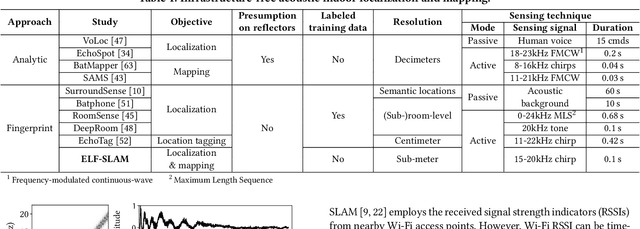
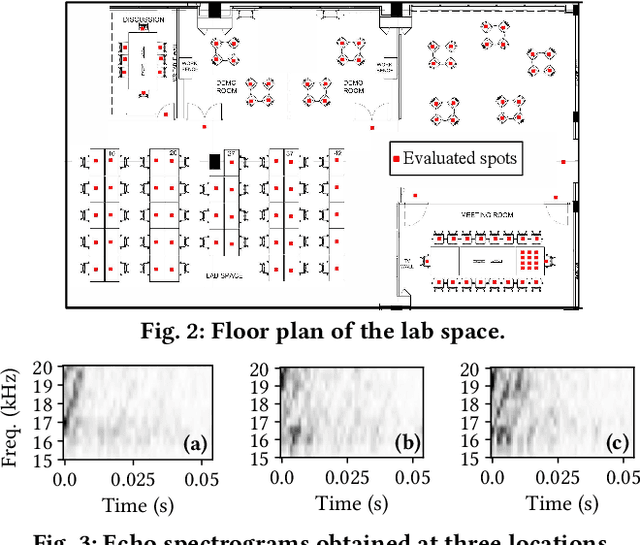
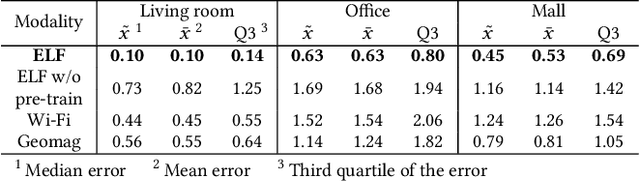
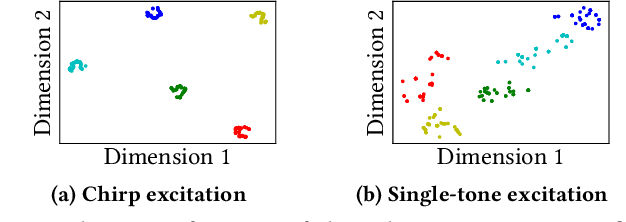
Indoor self-localization is a highly demanded system function for smartphones. The current solutions based on inertial, radio frequency, and geomagnetic sensing may have degraded performance when their limiting factors take effect. In this paper, we present a new indoor simultaneous localization and mapping (SLAM) system that utilizes the smartphone's built-in audio hardware and inertial measurement unit (IMU). Our system uses a smartphone's loudspeaker to emit near-inaudible chirps and then the microphone to record the acoustic echoes from the indoor environment. Our profiling measurements show that the echoes carry location information with sub-meter granularity. To enable SLAM, we apply contrastive learning to construct an echoic location feature (ELF) extractor, such that the loop closures on the smartphone's trajectory can be accurately detected from the associated ELF trace. The detection results effectively regulate the IMU-based trajectory reconstruction. Extensive experiments show that our ELF-based SLAM achieves median localization errors of $0.1\,\text{m}$, $0.53\,\text{m}$, and $0.4\,\text{m}$ on the reconstructed trajectories in a living room, an office, and a shopping mall, and outperforms the Wi-Fi and geomagnetic SLAM systems.
ManiCLIP: Multi-Attribute Face Manipulation from Text
Oct 02, 2022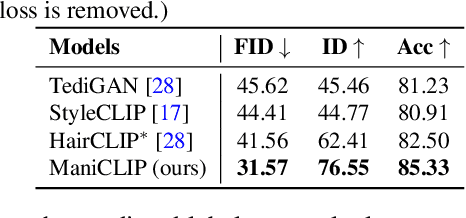


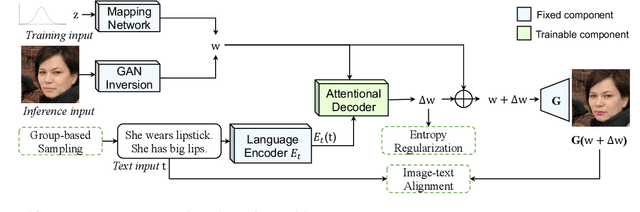
In this paper we present a novel multi-attribute face manipulation method based on textual descriptions. Previous text-based image editing methods either require test-time optimization for each individual image or are restricted to single attribute editing. Extending these methods to multi-attribute face image editing scenarios will introduce undesired excessive attribute change, e.g., text-relevant attributes are overly manipulated and text-irrelevant attributes are also changed. In order to address these challenges and achieve natural editing over multiple face attributes, we propose a new decoupling training scheme where we use group sampling to get text segments from same attribute categories, instead of whole complex sentences. Further, to preserve other existing face attributes, we encourage the model to edit the latent code of each attribute separately via a entropy constraint. During the inference phase, our model is able to edit new face images without any test-time optimization, even from complex textual prompts. We show extensive experiments and analysis to demonstrate the efficacy of our method, which generates natural manipulated faces with minimal text-irrelevant attribute editing. Code and pre-trained model will be released.
SymmNeRF: Learning to Explore Symmetry Prior for Single-View View Synthesis
Sep 29, 2022
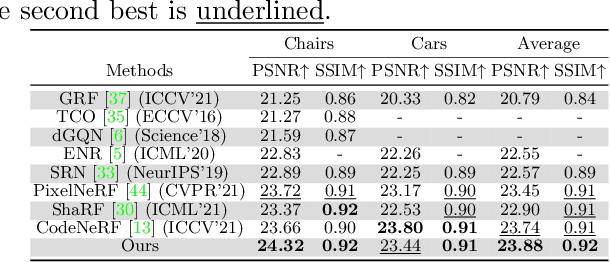
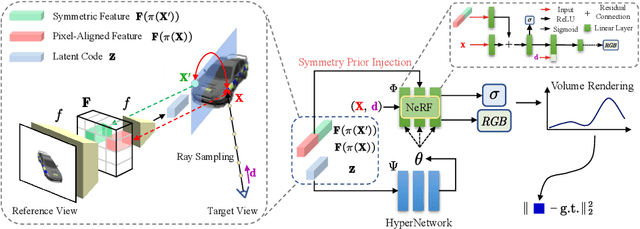
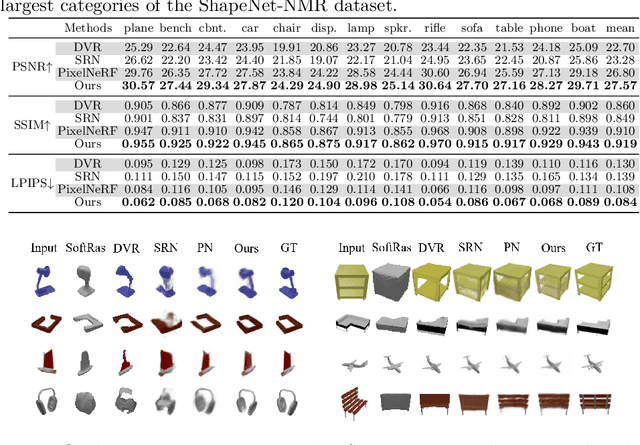
We study the problem of novel view synthesis of objects from a single image. Existing methods have demonstrated the potential in single-view view synthesis. However, they still fail to recover the fine appearance details, especially in self-occluded areas. This is because a single view only provides limited information. We observe that manmade objects usually exhibit symmetric appearances, which introduce additional prior knowledge. Motivated by this, we investigate the potential performance gains of explicitly embedding symmetry into the scene representation. In this paper, we propose SymmNeRF, a neural radiance field (NeRF) based framework that combines local and global conditioning under the introduction of symmetry priors. In particular, SymmNeRF takes the pixel-aligned image features and the corresponding symmetric features as extra inputs to the NeRF, whose parameters are generated by a hypernetwork. As the parameters are conditioned on the image-encoded latent codes, SymmNeRF is thus scene-independent and can generalize to new scenes. Experiments on synthetic and realworld datasets show that SymmNeRF synthesizes novel views with more details regardless of the pose transformation, and demonstrates good generalization when applied to unseen objects. Code is available at: https://github.com/xingyi-li/SymmNeRF.
CRCNet: Few-shot Segmentation with Cross-Reference and Region-Global Conditional Networks
Aug 23, 2022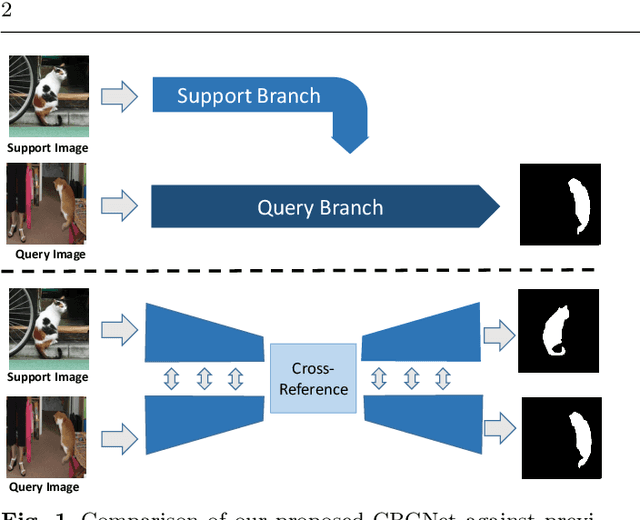

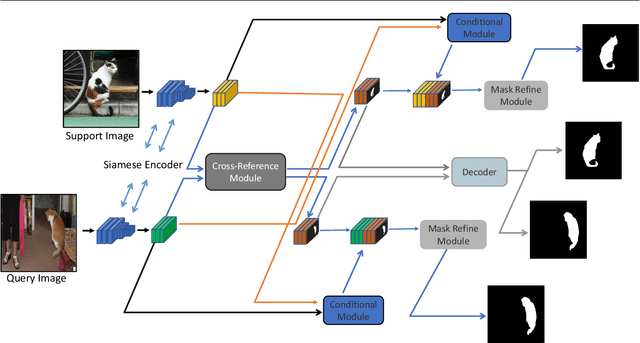

Few-shot segmentation aims to learn a segmentation model that can be generalized to novel classes with only a few training images. In this paper, we propose a Cross-Reference and Local-Global Conditional Networks (CRCNet) for few-shot segmentation. Unlike previous works that only predict the query image's mask, our proposed model concurrently makes predictions for both the support image and the query image. Our network can better find the co-occurrent objects in the two images with a cross-reference mechanism, thus helping the few-shot segmentation task. To further improve feature comparison, we develop a local-global conditional module to capture both global and local relations. We also develop a mask refinement module to refine the prediction of the foreground regions recurrently. Experiments on the PASCAL VOC 2012, MS COCO, and FSS-1000 datasets show that our network achieves new state-of-the-art performance.
RWSeg: Cross-graph Competing Random Walks for Weakly Supervised 3D Instance Segmentation
Aug 11, 2022

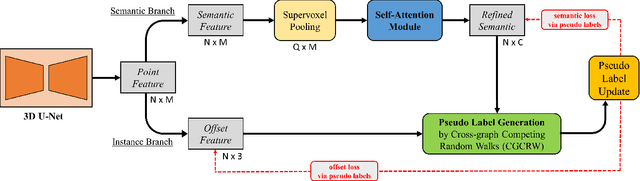

Instance segmentation on 3D point clouds has been attracting increasing attention due to its wide applications, especially in scene understanding areas. However, most existing methods require training data to be fully annotated. Manually preparing ground-truth labels at point-level is very cumbersome and labor-intensive. To address this issue, we propose a novel weakly supervised method RWSeg that only requires labeling one object with one point. With these sparse weak labels, we introduce a unified framework with two branches to propagate semantic and instance information respectively to unknown regions, using self-attention and random walk. Furthermore, we propose a Cross-graph Competing Random Walks (CGCRW) algorithm which encourages competition among different instance graphs to resolve ambiguities in closely placed objects and improve the performance on instance assignment. RWSeg can generate qualitative instance-level pseudo labels. Experimental results on ScanNet-v2 and S3DIS datasets show that our approach achieves comparable performance with fully-supervised methods and outperforms previous weakly-supervised methods by large margins. This is the first work that bridges the gap between weak and full supervision in the area.
ZeroMesh: Zero-shot Single-view 3D Mesh Reconstruction
Aug 04, 2022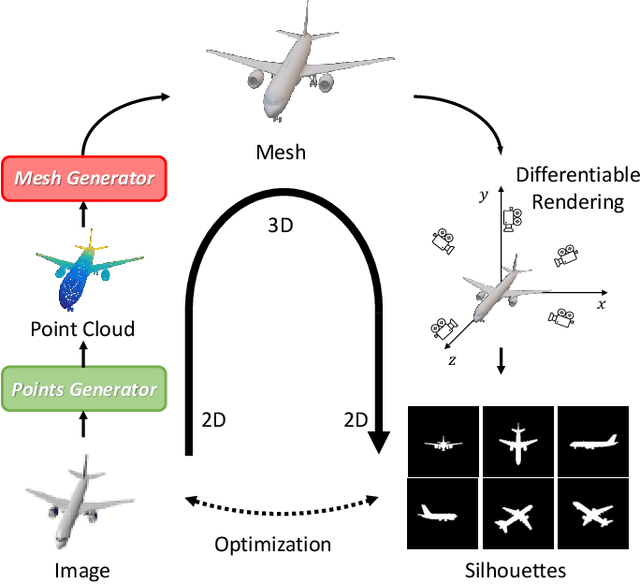
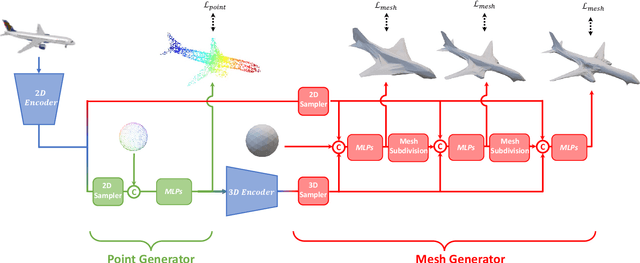
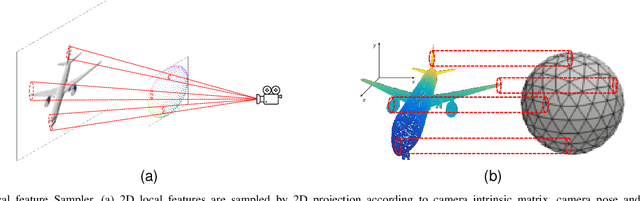
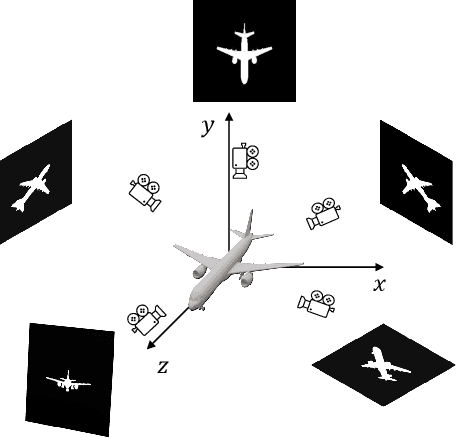
Single-view 3D object reconstruction is a fundamental and challenging computer vision task that aims at recovering 3D shapes from single-view RGB images. Most existing deep learning based reconstruction methods are trained and evaluated on the same categories, and they cannot work well when handling objects from novel categories that are not seen during training. Focusing on this issue, this paper tackles Zero-shot Single-view 3D Mesh Reconstruction, to study the model generalization on unseen categories and encourage models to reconstruct objects literally. Specifically, we propose an end-to-end two-stage network, ZeroMesh, to break the category boundaries in reconstruction. Firstly, we factorize the complicated image-to-mesh mapping into two simpler mappings, i.e., image-to-point mapping and point-to-mesh mapping, while the latter is mainly a geometric problem and less dependent on object categories. Secondly, we devise a local feature sampling strategy in 2D and 3D feature spaces to capture the local geometry shared across objects to enhance model generalization. Thirdly, apart from the traditional point-to-point supervision, we introduce a multi-view silhouette loss to supervise the surface generation process, which provides additional regularization and further relieves the overfitting problem. The experimental results show that our method significantly outperforms the existing works on the ShapeNet and Pix3D under different scenarios and various metrics, especially for novel objects.
Paired Cross-Modal Data Augmentation for Fine-Grained Image-to-Text Retrieval
Jul 29, 2022
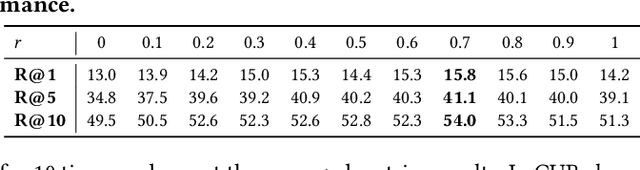
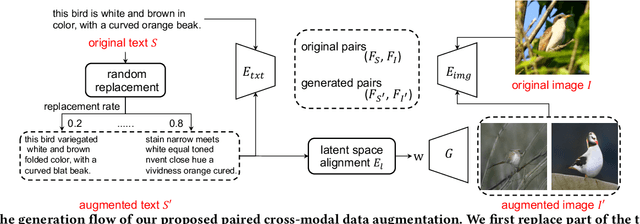
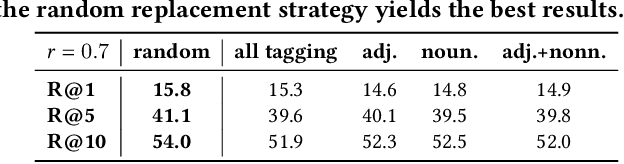
This paper investigates an open research problem of generating text-image pairs to improve the training of fine-grained image-to-text cross-modal retrieval task, and proposes a novel framework for paired data augmentation by uncovering the hidden semantic information of StyleGAN2 model. Specifically, we first train a StyleGAN2 model on the given dataset. We then project the real images back to the latent space of StyleGAN2 to obtain the latent codes. To make the generated images manipulatable, we further introduce a latent space alignment module to learn the alignment between StyleGAN2 latent codes and the corresponding textual caption features. When we do online paired data augmentation, we first generate augmented text through random token replacement, then pass the augmented text into the latent space alignment module to output the latent codes, which are finally fed to StyleGAN2 to generate the augmented images. We evaluate the efficacy of our augmented data approach on two public cross-modal retrieval datasets, in which the promising experimental results demonstrate the augmented text-image pair data can be trained together with the original data to boost the image-to-text cross-modal retrieval performance.
3D Cartoon Face Generation with Controllable Expressions from a Single GAN Image
Jul 29, 2022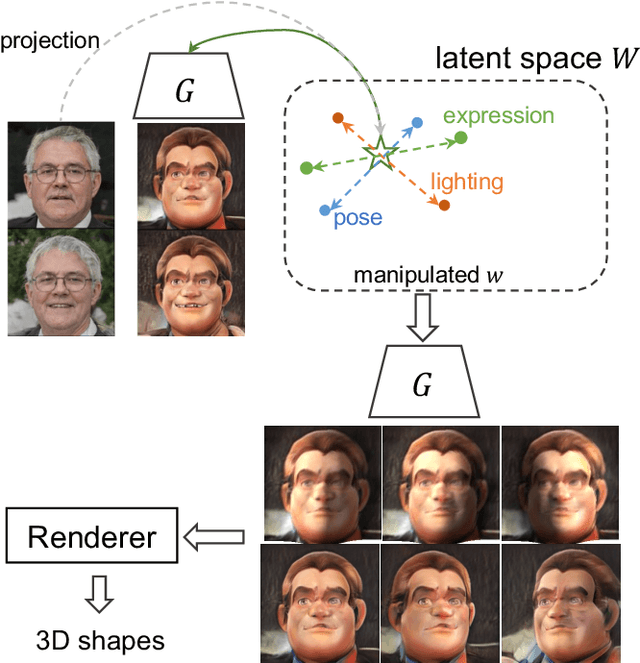


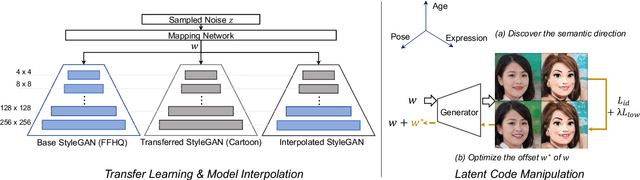
In this paper, we investigate an open research task of generating 3D cartoon face shapes from single 2D GAN generated human faces and without 3D supervision, where we can also manipulate the facial expressions of the 3D shapes. To this end, we discover the semantic meanings of StyleGAN latent space, such that we are able to produce face images of various expressions, poses, and lighting by controlling the latent codes. Specifically, we first finetune the pretrained StyleGAN face model on the cartoon datasets. By feeding the same latent codes to face and cartoon generation models, we aim to realize the translation from 2D human face images to cartoon styled avatars. We then discover semantic directions of the GAN latent space, in an attempt to change the facial expressions while preserving the original identity. As we do not have any 3D annotations for cartoon faces, we manipulate the latent codes to generate images with different poses and lighting, such that we can reconstruct the 3D cartoon face shapes. We validate the efficacy of our method on three cartoon datasets qualitatively and quantitatively.