 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveness Detection Using Implicit 3D Features
Apr 19, 2018
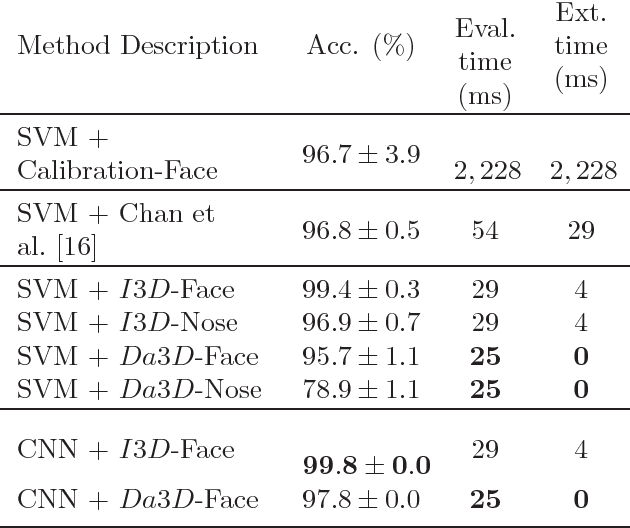


Spoofing attacks are a threat to modern face recognition systems. In this work we present a simple yet effective liveness detection approach to enhance 2D face recognition methods and make them robust against spoofing attacks. We show that the risk to spoofing attacks can be re- duced through the use of an additional source of light, for example a flash. From a pair of input images taken under different illumination, we define discriminative features that implicitly contain facial three-dimensional in- formation. Furthermore, we show that when multiple sources of light are considered, we are able to validate which one has been activated. This makes possible the design of a highly secure active-light authentication framework. Finally, further investigating the use of 3D features without 3D reconstruction, we introduce an approximated disparity-based implicit 3D feature obtained from an uncalibrated stereo-pair of cameras. Valida- tion experiments show that the proposed methods produce state-of-the-art results in challenging scenarios with nearly no feature extraction latency.
Virtual CNN Branching: Efficient Feature Ensemble for Person Re-Identification
Mar 15, 2018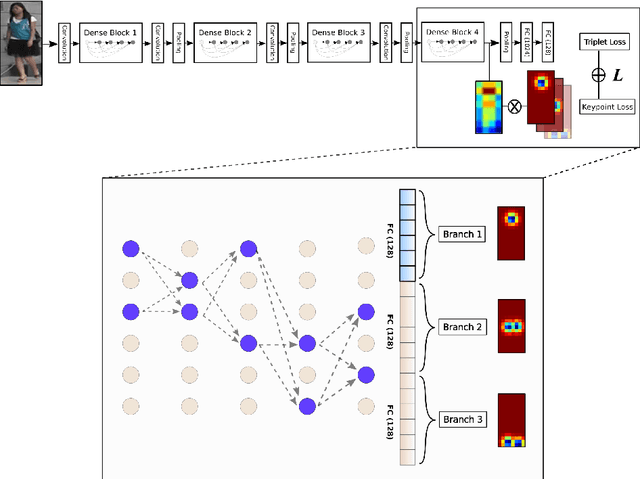
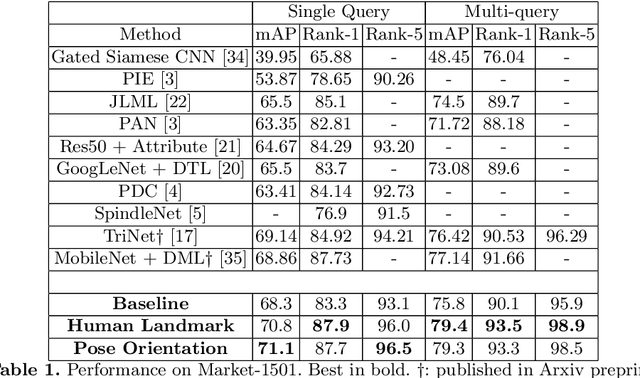

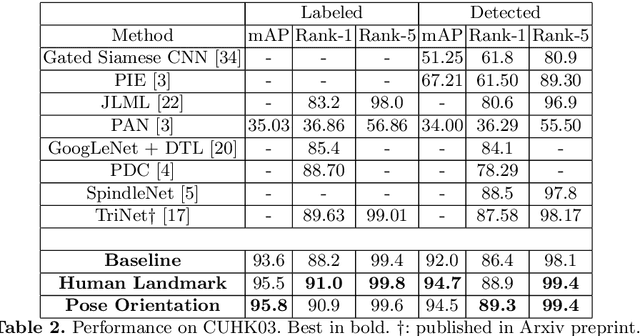
In this paper we introduce an ensemble method for convolutional neural network (CNN), called "virtual branching," which can be implemented with nearly no additional parameters and computation on top of standard CNNs. We propose our method in the context of person re-identification (re-ID). Our CNN model consists of shared bottom layers, followed by "virtual" branches, where neurons from a block of regular convolutional and fully-connected layers are partitioned into multiple sets. Each virtual branch is trained with different data to specialize in different aspects, e.g., a specific body region or pose orientation. In this way, robust ensemble representations are obtained against human body misalignment, deformations, or variations in viewing angles, at nearly no any additional cost. The proposed method achieves competitive performance on multiple person re-ID benchmark datasets, including Market-1501, CUHK03, and DukeMTMC-reID.
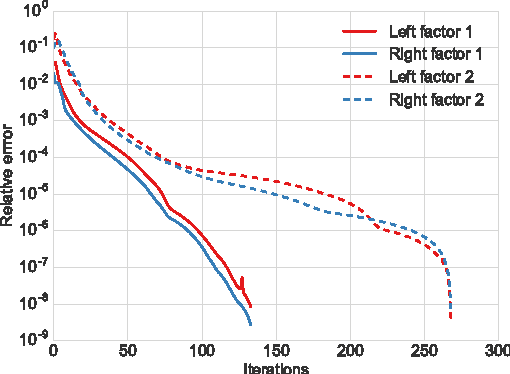
Tradeoffs between Convergence Speed and Reconstruction Accuracy in Inverse Problems
Feb 15, 2018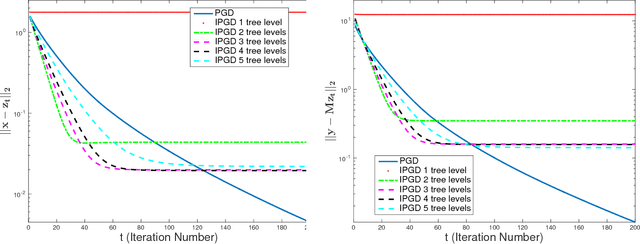
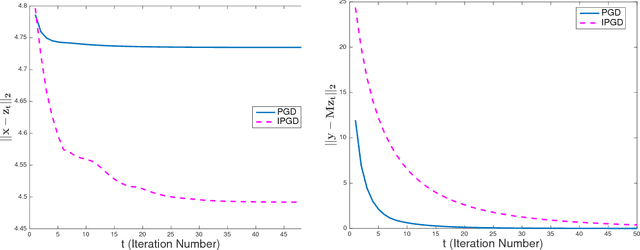
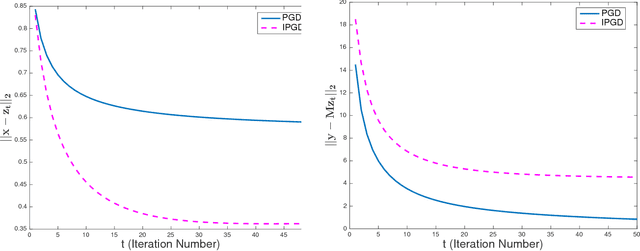
Solving inverse problems with iterative algorithms is popular, especially for large data. Due to time constraints, the number of possible iterations is usually limited, potentially affecting the achievable accuracy. Given an error one is willing to tolerate, an important question is whether it is possible to modify the original iterations to obtain faster convergence to a minimizer achieving the allowed error without increasing the computational cost of each iteration considerably. Relying on recent recovery techniques developed for settings in which the desired signal belongs to some low-dimensional set, we show that using a coarse estimate of this set may lead to faster convergence at the cost of an additional reconstruction error related to the accuracy of the set approximation. Our theory ties to recent advances in sparse recovery, compressed sensing, and deep learning. Particularly, it may provide a possible explanation to the successful approximation of the l1-minimization solution by neural networks with layers representing iterations, as practiced in the learned iterative shrinkage-thresholding algorithm (LISTA).
OLÉ: Orthogonal Low-rank Embedding, A Plug and Play Geometric Loss for Deep Learning
Dec 05, 2017

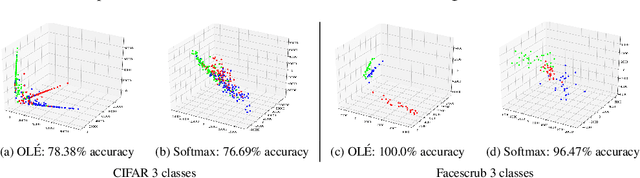
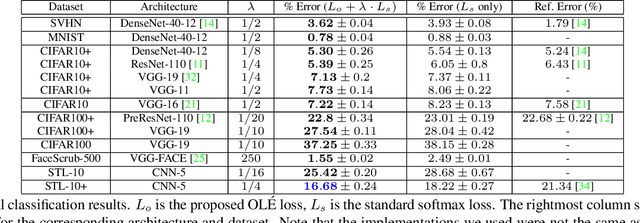
Deep neural networks trained using a softmax layer at the top and the cross-entropy loss are ubiquitous tools for image classification. Yet, this does not naturally enforce intra-class similarity nor inter-class margin of the learned deep representations. To simultaneously achieve these two goals, different solutions have been proposed in the literature, such as the pairwise or triplet losses. However, such solutions carry the extra task of selecting pairs or triplets, and the extra computational burden of computing and learning for many combinations of them. In this paper, we propose a plug-and-play loss term for deep networks that explicitly reduces intra-class variance and enforces inter-class margin simultaneously, in a simple and elegant geometric manner. For each class, the deep features are collapsed into a learned linear subspace, or union of them, and inter-class subspaces are pushed to be as orthogonal as possible. Our proposed Orthogonal Low-rank Embedding (OL\'E) does not require carefully crafting pairs or triplets of samples for training, and works standalone as a classification loss, being the first reported deep metric learning framework of its kind. Because of the improved margin between features of different classes, the resulting deep networks generalize better, are more discriminative, and more robust. We demonstrate improved classification performance in general object recognition, plugging the proposed loss term into existing off-the-shelf architectures. In particular, we show the advantage of the proposed loss in the small data/model scenario, and we significantly advance the state-of-the-art on the Stanford STL-10 benchmark.
LDMNet: Low Dimensional Manifold Regularized Neural Networks
Nov 16, 2017
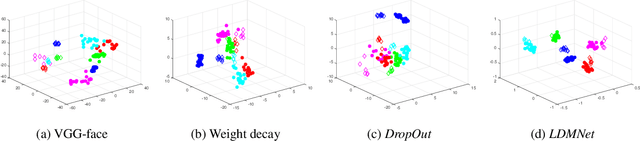
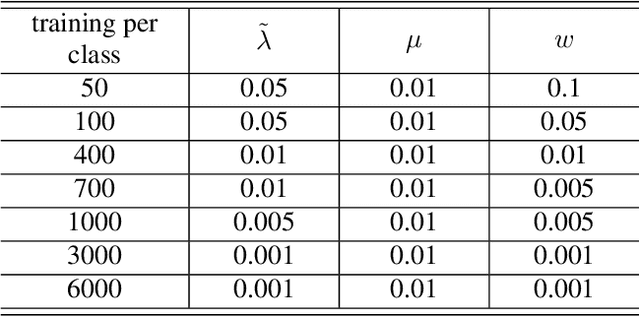
Deep neural networks have proved very successful on archetypal tasks for which large training sets are available, but when the training data are scarce, their performance suffers from overfitting. Many existing methods of reducing overfitting are data-independent, and their efficacy is often limited when the training set is very small. Data-dependent regularizations are mostly motivated by the observation that data of interest lie close to a manifold, which is typically hard to parametrize explicitly and often requires human input of tangent vectors. These methods typically only focus on the geometry of the input data, and do not necessarily encourage the networks to produce geometrically meaningful features. To resolve this, we propose a new framework, the Low-Dimensional-Manifold-regularized neural Network (LDMNet), which incorporates a feature regularization method that focuses on the geometry of both the input data and the output features. In LDMNet, we regularize the network by encouraging the combination of the input data and the output features to sample a collection of low dimensional manifolds, which are searched efficiently without explicit parametrization. To achieve this, we directly use the manifold dimension as a regularization term in a variational functional. The resulting Euler-Lagrange equation is a Laplace-Beltrami equation over a point cloud, which is solved by the point integral method without increasing the computational complexity. We demonstrate two benefits of LDMNet in the experiments. First, we show that LDMNet significantly outperforms widely-used network regularizers such as weight decay and DropOut. Second, we show that LDMNet can be designed to extract common features of an object imaged via different modalities, which proves to be very useful in real-world applications such as cross-spectral face recognition.
Generalization Error of Invariant Classifiers
Jul 02, 2017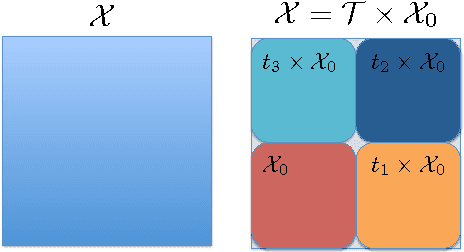
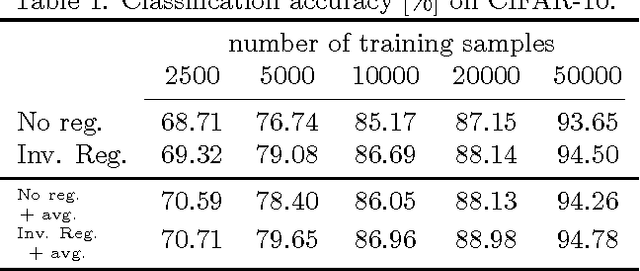
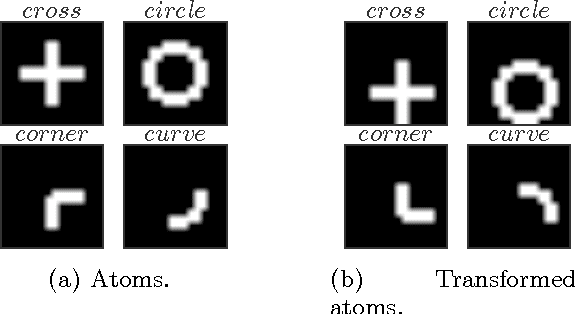
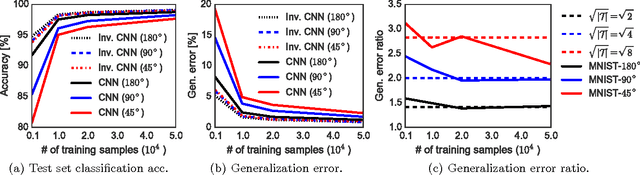
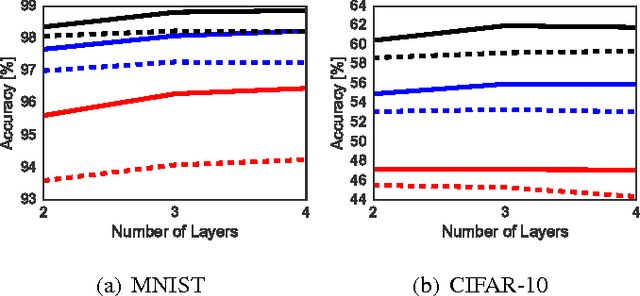
This paper studies the generalization error of invariant classifiers. In particular, we consider the common scenario where the classification task is invariant to certain transformations of the input, and that the classifier is constructed (or learned) to be invariant to these transformations. Our approach relies on factoring the input space into a product of a base space and a set of transformations. We show that whereas the generalization error of a non-invariant classifier is proportional to the complexity of the input space, the generalization error of an invariant classifier is proportional to the complexity of the base space. We also derive a set of sufficient conditions on the geometry of the base space and the set of transformations that ensure that the complexity of the base space is much smaller than the complexity of the input space. Our analysis applies to general classifiers such as convolutional neural networks. We demonstrate the implications of the developed theory for such classifiers with experiments on the MNIST and CIFAR-10 datasets.
* Accepted to AISTATS. This version has updated references
Learning to Succeed while Teaching to Fail: Privacy in Closed Machine Learning Systems
May 23, 2017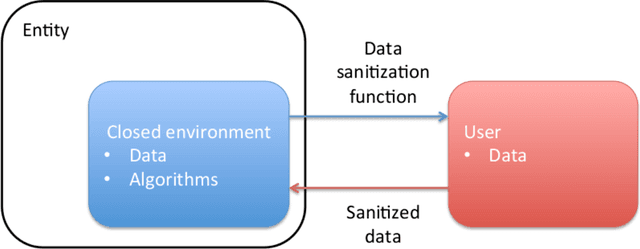



Security, privacy, and fairness have become critical in the era of data science and machine learning. More and more we see that achieving universally secure, private, and fair systems is practically impossible. We have seen for example how generative adversarial networks can be used to learn about the expected private training data; how the exploitation of additional data can reveal private information in the original one; and how what looks like unrelated features can teach us about each other. Confronted with this challenge, in this paper we open a new line of research, where the security, privacy, and fairness is learned and used in a closed environment. The goal is to ensure that a given entity (e.g., the company or the government), trusted to infer certain information with our data, is blocked from inferring protected information from it. For example, a hospital might be allowed to produce diagnosis on the patient (the positive task), without being able to infer the gender of the subject (negative task). Similarly, a company can guarantee that internally it is not using the provided data for any undesired task, an important goal that is not contradicting the virtually impossible challenge of blocking everybody from the undesired task. We design a system that learns to succeed on the positive task while simultaneously fail at the negative one, and illustrate this with challenging cases where the positive task is actually harder than the negative one being blocked. Fairness, to the information in the negative task, is often automatically obtained as a result of this proposed approach. The particular framework and examples open the door to security, privacy, and fairness in very important closed scenarios, ranging from private data accumulation companies like social networks to law-enforcement and hospitals.
Robust Large Margin Deep Neural Networks
May 23, 2017
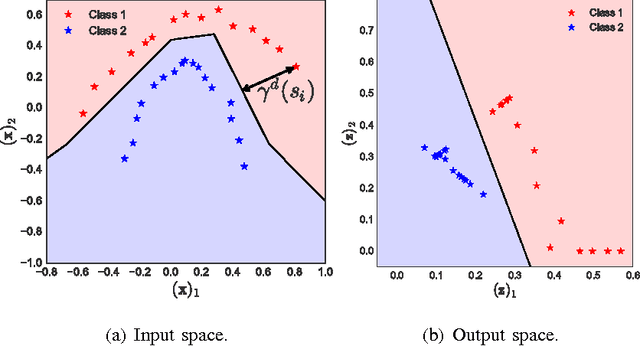
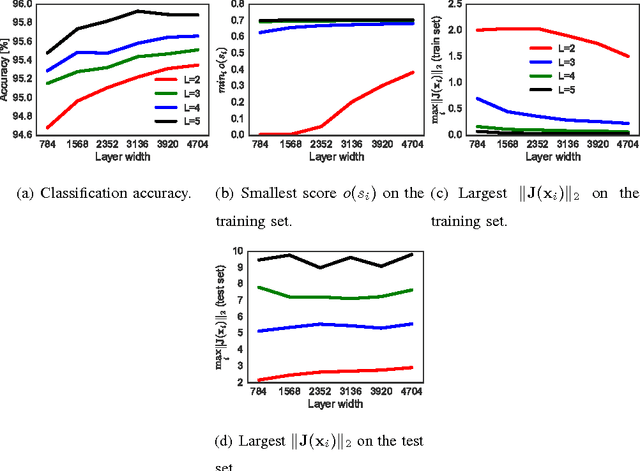
The generalization error of deep neural networks via their classification margin is studied in this work. Our approach is based on the Jacobian matrix of a deep neural network and can be applied to networks with arbitrary non-linearities and pooling layers, and to networks with different architectures such as feed forward networks and residual networks. Our analysis leads to the conclusion that a bounded spectral norm of the network's Jacobian matrix in the neighbourhood of the training samples is crucial for a deep neural network of arbitrary depth and width to generalize well. This is a significant improvement over the current bounds in the literature, which imply that the generalization error grows with either the width or the depth of the network. Moreover, it shows that the recently proposed batch normalization and weight normalization re-parametrizations enjoy good generalization properties, and leads to a novel network regularizer based on the network's Jacobian matrix. The analysis is supported with experimental results on the MNIST, CIFAR-10, LaRED and ImageNet datasets.
Nonnegative Matrix Underapproximation for Robust Multiple Model Fitting
Apr 10, 2017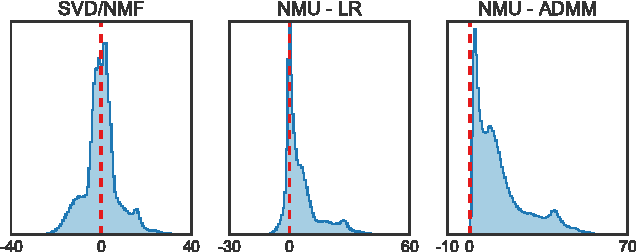
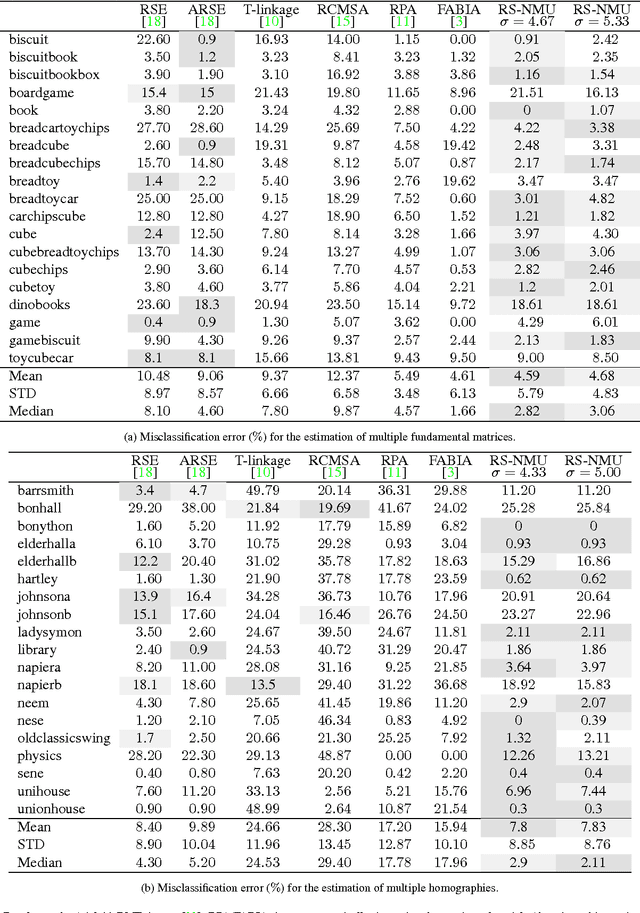
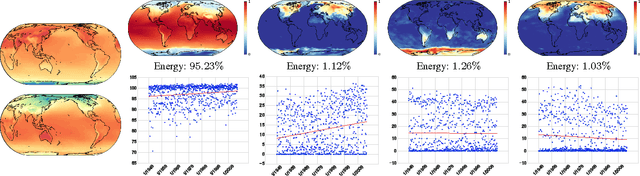
In this work, we introduce a highly efficient algorithm to address the nonnegative matrix underapproximation (NMU) problem, i.e., nonnegative matrix factorization (NMF) with an additional underapproximation constraint. NMU results are interesting as, compared to traditional NMF, they present additional sparsity and part-based behavior, explaining unique data features. To show these features in practice, we first present an application to the analysis of climate data. We then present an NMU-based algorithm to robustly fit multiple parametric models to a dataset. The proposed approach delivers state-of-the-art results for the estimation of multiple fundamental matrices and homographies, outperforming other alternatives in the literature and exemplifying the use of efficient NMU computations.
Deep Video Deblurring
Nov 25, 2016
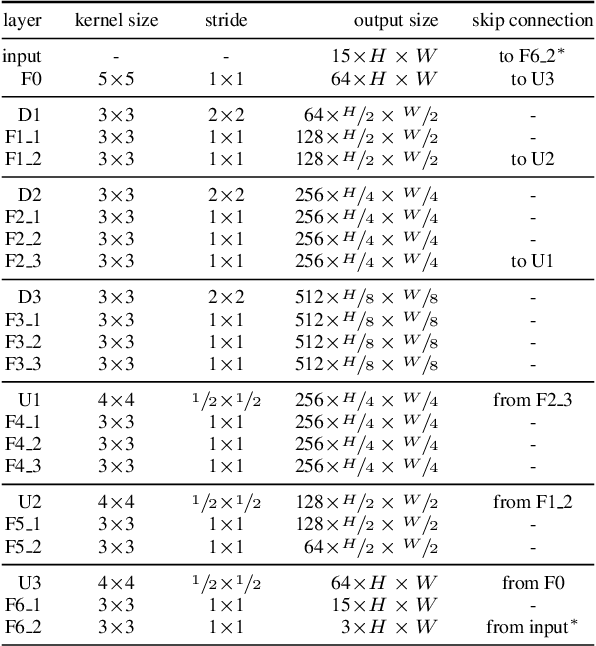
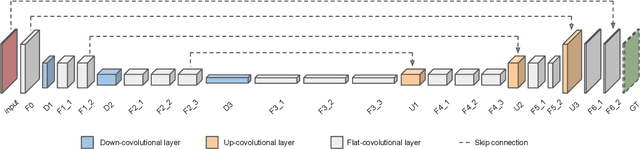

Motion blur from camera shake is a major problem in videos captured by hand-held devices. Unlike single-image deblurring, video-based approaches can take advantage of the abundant information that exists across neighboring frames. As a result the best performing methods rely on aligning nearby frames. However, aligning images is a computationally expensive and fragile procedure, and methods that aggregate information must therefore be able to identify which regions have been accurately aligned and which have not, a task which requires high level scene understanding. In this work, we introduce a deep learning solution to video deblurring, where a CNN is trained end-to-end to learn how to accumulate information across frames. To train this network, we collected a dataset of real videos recorded with a high framerate camera, which we use to generate synthetic motion blur for supervision. We show that the features learned from this dataset extend to deblurring motion blur that arises due to camera shake in a wide range of videos, and compare the quality of results to a number of other baselines.