 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformers with Natural Language Semantics
Feb 27, 2024



Tokens or patches within Vision Transformers (ViT) lack essential semantic information, unlike their counterparts in natural language processing (NLP). Typically, ViT tokens are associated with rectangular image patches that lack specific semantic context, making interpretation difficult and failing to effectively encapsulate information. We introduce a novel transformer model, Semantic Vision Transformers (sViT), which leverages recent progress on segmentation models to design novel tokenizer strategies. sViT effectively harnesses semantic information, creating an inductive bias reminiscent of convolutional neural networks while capturing global dependencies and contextual information within images that are characteristic of transformers. Through validation using real datasets, sViT demonstrates superiority over ViT, requiring less training data while maintaining similar or superior performance. Furthermore, sViT demonstrates significant superiority in out-of-distribution generalization and robustness to natural distribution shifts, attributed to its scale invariance semantic characteristic. Notably, the use of semantic tokens significantly enhances the model's interpretability. Lastly, the proposed paradigm facilitates the introduction of new and powerful augmentation techniques at the token (or segment) level, increasing training data diversity and generalization capabilities. Just as sentences are made of words, images are formed by semantic objects; our proposed methodology leverages recent progress in object segmentation and takes an important and natural step toward interpretable and robust vision transformers.
Federated Fairness without Access to Sensitive Groups
Feb 22, 2024Current approaches to group fairness in federated learning assume the existence of predefined and labeled sensitive groups during training. However, due to factors ranging from emerging regulations to dynamics and location-dependency of protected groups, this assumption may be unsuitable in many real-world scenarios. In this work, we propose a new approach to guarantee group fairness that does not rely on any predefined definition of sensitive groups or additional labels. Our objective allows the federation to learn a Pareto efficient global model ensuring worst-case group fairness and it enables, via a single hyper-parameter, trade-offs between fairness and utility, subject only to a group size constraint. This implies that any sufficiently large subset of the population is guaranteed to receive at least a minimum level of utility performance from the model. The proposed objective encompasses existing approaches as special cases, such as empirical risk minimization and subgroup robustness objectives from centralized machine learning. We provide an algorithm to solve this problem in federation that enjoys convergence and excess risk guarantees. Our empirical results indicate that the proposed approach can effectively improve the worst-performing group that may be present without unnecessarily hurting the average performance, exhibits superior or comparable performance to relevant baselines, and achieves a large set of solutions with different fairness-utility trade-offs.
Simulation-based Inference for Cardiovascular Models
Jul 29, 2023Over the past decades, hemodynamics simulators have steadily evolved and have become tools of choice for studying cardiovascular systems in-silico. While such tools are routinely used to simulate whole-body hemodynamics from physiological parameters, solving the corresponding inverse problem of mapping waveforms back to plausible physiological parameters remains both promising and challenging. Motivated by advances in simulation-based inference (SBI), we cast this inverse problem as statistical inference. In contrast to alternative approaches, SBI provides \textit{posterior distributions} for the parameters of interest, providing a \textit{multi-dimensional} representation of uncertainty for \textit{individual} measurements. We showcase this ability by performing an in-silico uncertainty analysis of five biomarkers of clinical interest comparing several measurement modalities. Beyond the corroboration of known facts, such as the feasibility of estimating heart rate, our study highlights the potential of estimating new biomarkers from standard-of-care measurements. SBI reveals practically relevant findings that cannot be captured by standard sensitivity analyses, such as the existence of sub-populations for which parameter estimation exhibits distinct uncertainty regimes. Finally, we study the gap between in-vivo and in-silico with the MIMIC-III waveform database and critically discuss how cardiovascular simulations can inform real-world data analysis.
Robust Hybrid Learning With Expert Augmentation
Feb 09, 2022



Hybrid modelling reduces the misspecification of expert models by combining them with machine learning (ML) components learned from data. Like for many ML algorithms, hybrid model performance guarantees are limited to the training distribution. Leveraging the insight that the expert model is usually valid even outside the training domain, we overcome this limitation by introducing a hybrid data augmentation strategy termed \textit{expert augmentation}. Based on a probabilistic formalization of hybrid modelling, we show why expert augmentation improves generalization. Finally, we validate the practical benefits of augmented hybrid models on a set of controlled experiments, modelling dynamical systems described by ordinary and partial differential equations.
Minimax Demographic Group Fairness in Federated Learning
Jan 25, 2022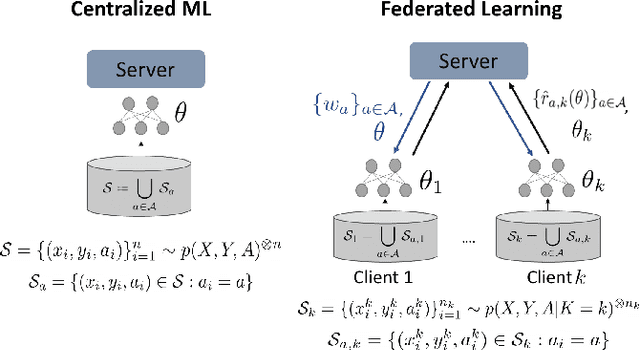
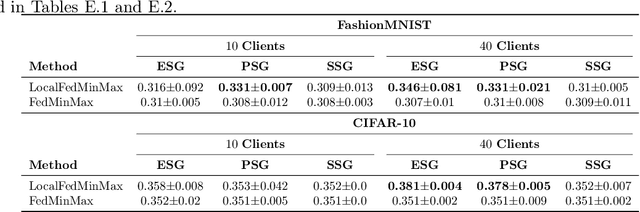
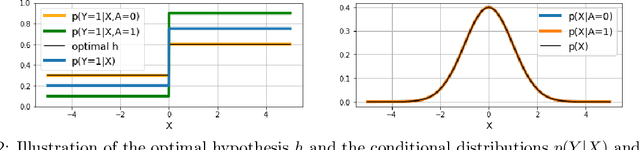
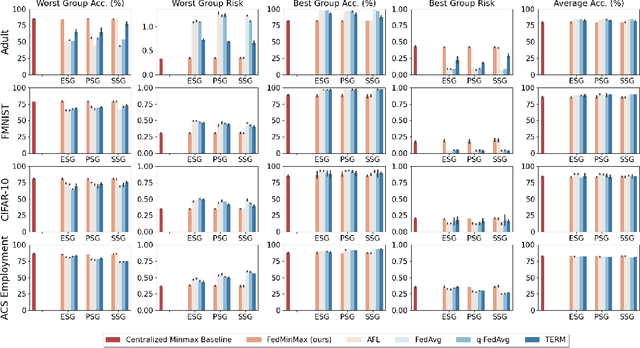
Federated learning is an increasingly popular paradigm that enables a large number of entities to collaboratively learn better models. In this work, we study minimax group fairness in federated learning scenarios where different participating entities may only have access to a subset of the population groups during the training phase. We formally analyze how our proposed group fairness objective differs from existing federated learning fairness criteria that impose similar performance across participants instead of demographic groups. We provide an optimization algorithm -- FedMinMax -- for solving the proposed problem that provably enjoys the performance guarantees of centralized learning algorithms. We experimentally compare the proposed approach against other state-of-the-art methods in terms of group fairness in various federated learning setups, showing that our approach exhibits competitive or superior performance.
Distributionally Robust Group Backwards Compatibility
Dec 20, 2021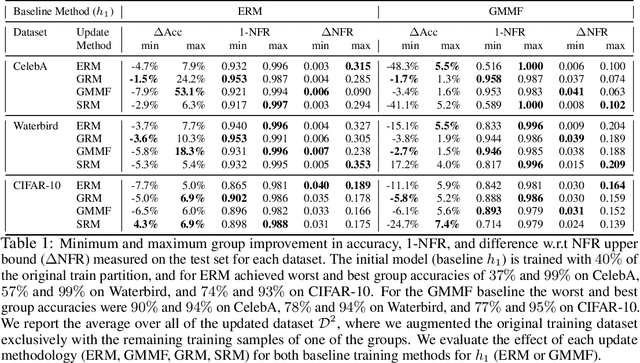
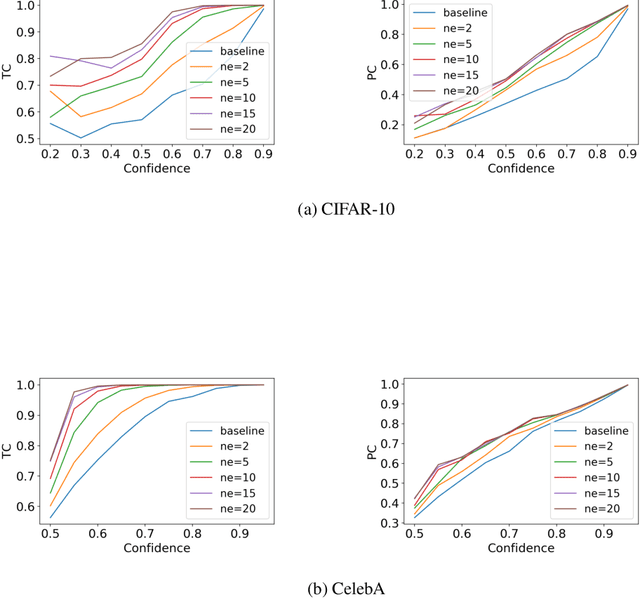
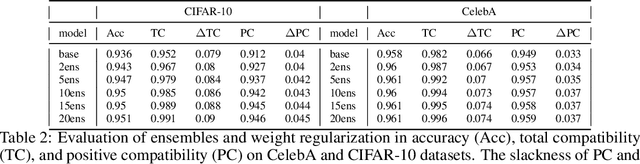

Machine learning models are updated as new data is acquired or new architectures are developed. These updates usually increase model performance, but may introduce backward compatibility errors, where individual users or groups of users see their performance on the updated model adversely affected. This problem can also be present when training datasets do not accurately reflect overall population demographics, with some groups having overall lower participation in the data collection process, posing a significant fairness concern. We analyze how ideas from distributional robustness and minimax fairness can aid backward compatibility in this scenario, and propose two methods to directly address this issue. Our theoretical analysis is backed by experimental results on CIFAR-10, CelebA, and Waterbirds, three standard image classification datasets. Code available at github.com/natalialmg/GroupBC
Federating for Learning Group Fair Models
Oct 07, 2021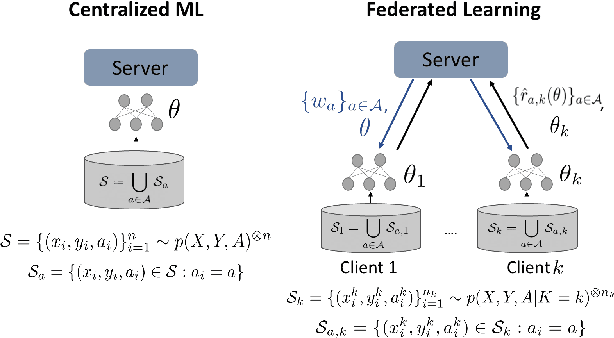
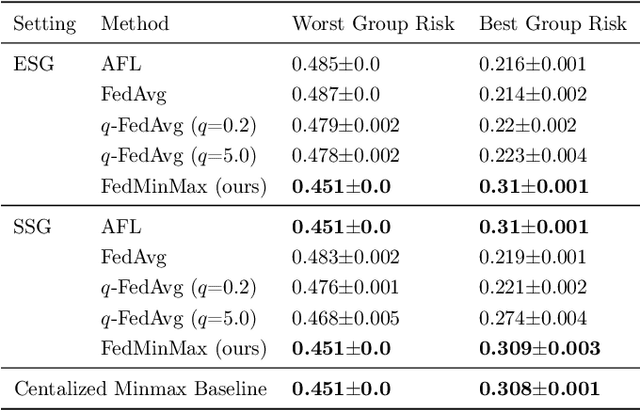
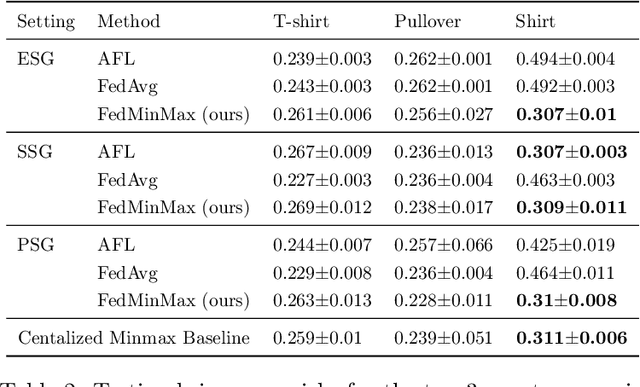
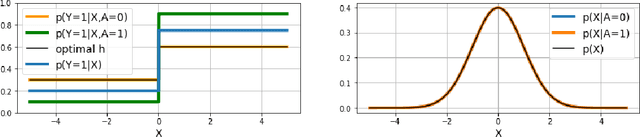
Federated learning is an increasingly popular paradigm that enables a large number of entities to collaboratively learn better models. In this work, we study minmax group fairness in paradigms where different participating entities may only have access to a subset of the population groups during the training phase. We formally analyze how this fairness objective differs from existing federated learning fairness criteria that impose similar performance across participants instead of demographic groups. We provide an optimization algorithm -- FedMinMax -- for solving the proposed problem that provably enjoys the performance guarantees of centralized learning algorithms. We experimentally compare the proposed approach against other methods in terms of group fairness in various federated learning setups.
GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions
Apr 30, 2021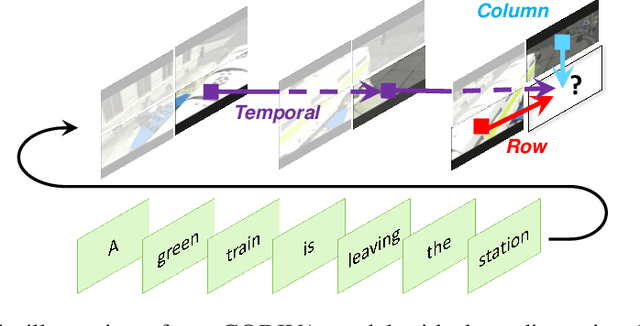
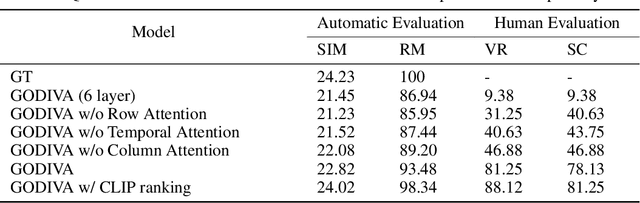
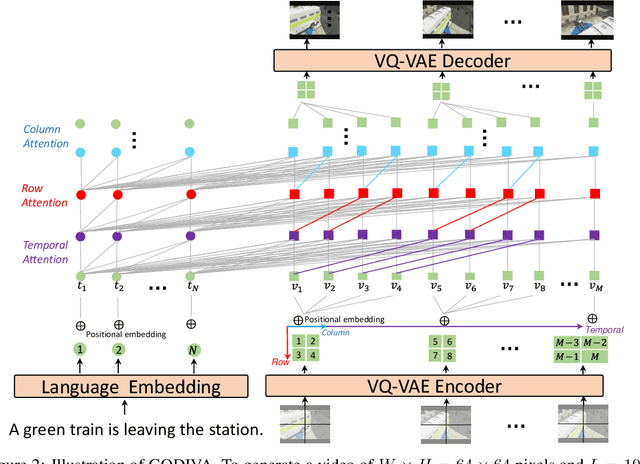

Generating videos from text is a challenging task due to its high computational requirements for training and infinite possible answers for evaluation. Existing works typically experiment on simple or small datasets, where the generalization ability is quite limited. In this work, we propose GODIVA, an open-domain text-to-video pretrained model that can generate videos from text in an auto-regressive manner using a three-dimensional sparse attention mechanism. We pretrain our model on Howto100M, a large-scale text-video dataset that contains more than 136 million text-video pairs. Experiments show that GODIVA not only can be fine-tuned on downstream video generation tasks, but also has a good zero-shot capability on unseen texts. We also propose a new metric called Relative Matching (RM) to automatically evaluate the video generation quality. Several challenges are listed and discussed as future work.
Cirrus: A Long-range Bi-pattern LiDAR Dataset
Dec 05, 2020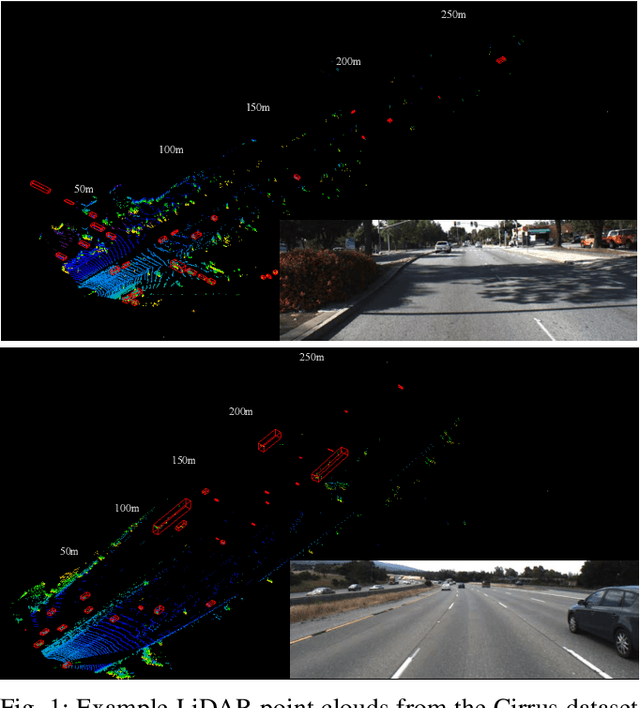
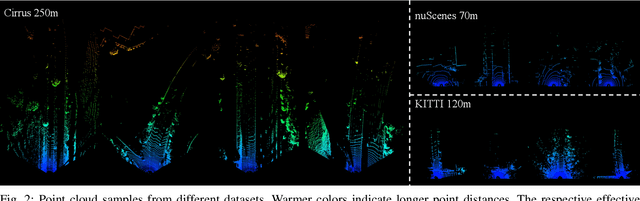
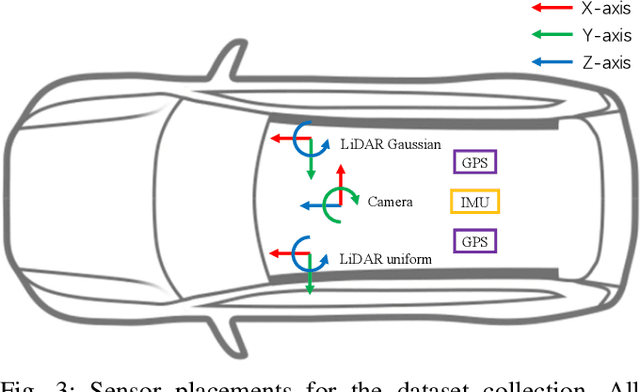
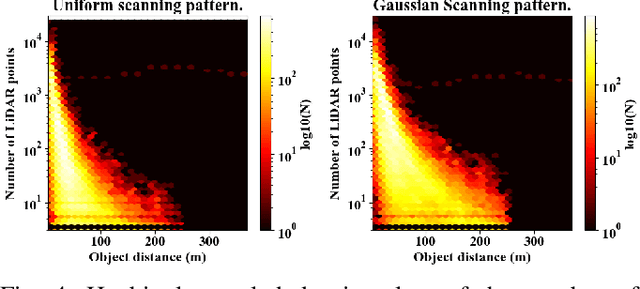
In this paper, we introduce Cirrus, a new long-range bi-pattern LiDAR public dataset for autonomous driving tasks such as 3D object detection, critical to highway driving and timely decision making. Our platform is equipped with a high-resolution video camera and a pair of LiDAR sensors with a 250-meter effective range, which is significantly longer than existing public datasets. We record paired point clouds simultaneously using both Gaussian and uniform scanning patterns. Point density varies significantly across such a long range, and different scanning patterns further diversify object representation in LiDAR. In Cirrus, eight categories of objects are exhaustively annotated in the LiDAR point clouds for the entire effective range. To illustrate the kind of studies supported by this new dataset, we introduce LiDAR model adaptation across different ranges, scanning patterns, and sensor devices. Promising results show the great potential of this new dataset to the robotics and computer vision communities.
Using Text to Teach Image Retrieval
Nov 19, 2020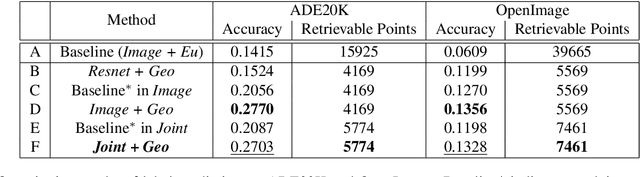
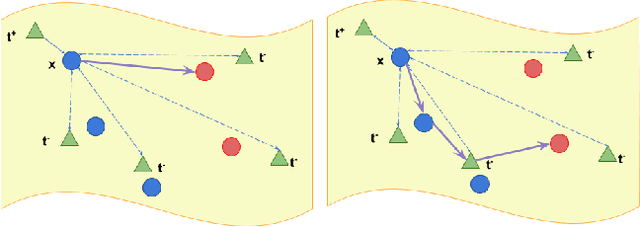
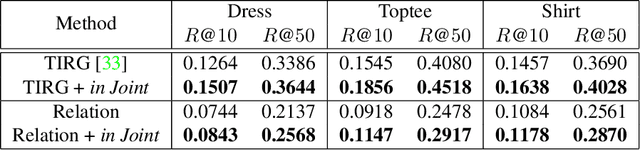

Image retrieval relies heavily on the quality of the data modeling and the distance measurement in the feature space. Building on the concept of image manifold, we first propose to represent the feature space of images, learned via neural networks, as a graph. Neighborhoods in the feature space are now defined by the geodesic distance between images, represented as graph vertices or manifold samples. When limited images are available, this manifold is sparsely sampled, making the geodesic computation and the corresponding retrieval harder. To address this, we augment the manifold samples with geometrically aligned text, thereby using a plethora of sentences to teach us about images. In addition to extensive results on standard datasets illustrating the power of text to help in image retrieval, a new public dataset based on CLEVR is introduced to quantify the semantic similarity between visual data and text data. The experimental results show that the joint embedding manifold is a robust representation, allowing it to be a better basis to perform image retrieval given only an image and a textual instruction on the desired modifications over the image