 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Knowledge Identification and Fusion for Language Model Continual Learning
Feb 22, 2025Continual learning (CL) is crucial for deploying large language models (LLMs) in dynamic real-world environments without costly retraining. While recent model ensemble and model merging methods guided by parameter importance have gained popularity, they often struggle to balance knowledge transfer and forgetting, mainly due to the reliance on static importance estimates during sequential training. In this paper, we present Recurrent-KIF, a novel CL framework for Recurrent Knowledge Identification and Fusion, which enables dynamic estimation of parameter importance distributions to enhance knowledge transfer. Inspired by human continual learning, Recurrent-KIF employs an inner loop that rapidly adapts to new tasks while identifying important parameters, coupled with an outer loop that globally manages the fusion of new and historical knowledge through redundant knowledge pruning and key knowledge merging. These inner-outer loops iteratively perform multiple rounds of fusion, allowing Recurrent-KIF to leverage intermediate training information and adaptively adjust fusion strategies based on evolving importance distributions. Extensive experiments on two CL benchmarks with various model sizes (from 770M to 13B) demonstrate that Recurrent-KIF effectively mitigates catastrophic forgetting and enhances knowledge transfer.
Understanding Layer Significance in LLM Alignment
Oct 23, 2024



Aligning large language models (LLMs) through fine-tuning is essential for tailoring them to specific applications. Therefore, understanding what LLMs learn during the alignment process is crucial. Recent studies suggest that alignment primarily adjusts a model's presentation style rather than its foundational knowledge, indicating that only certain components of the model are significantly impacted. To delve deeper into LLM alignment, we propose to identify which layers within LLMs are most critical to the alignment process, thereby uncovering how alignment influences model behavior at a granular level. We propose a novel approach to identify the important layers for LLM alignment (ILA). It involves learning a binary mask for each incremental weight matrix in the LoRA algorithm, indicating the significance of each layer. ILA consistently identifies important layers across various alignment datasets, with nearly 90% overlap even with substantial dataset differences, highlighting fundamental patterns in LLM alignment. Experimental results indicate that freezing non-essential layers improves overall model performance, while selectively tuning the most critical layers significantly enhances fine-tuning efficiency with minimal performance loss.
TaSL: Continual Dialog State Tracking via Task Skill Localization and Consolidation
Aug 19, 2024A practical dialogue system requires the capacity for ongoing skill acquisition and adaptability to new tasks while preserving prior knowledge. However, current methods for Continual Dialogue State Tracking (DST), a crucial function of dialogue systems, struggle with the catastrophic forgetting issue and knowledge transfer between tasks. We present TaSL, a novel framework for task skill localization and consolidation that enables effective knowledge transfer without relying on memory replay. TaSL uses a novel group-wise technique to pinpoint task-specific and task-shared areas. Additionally, a fine-grained skill consolidation strategy protects task-specific knowledge from being forgotten while updating shared knowledge for bi-directional knowledge transfer. As a result, TaSL strikes a balance between preserving previous knowledge and excelling at new tasks. Comprehensive experiments on various backbones highlight the significant performance improvements of TaSL over existing state-of-the-art methods. The source code is provided for reproducibility.
Making Multimodal Generation Easier: When Diffusion Models Meet LLMs
Oct 13, 2023We present EasyGen, an efficient model designed to enhance multimodal understanding and generation by harnessing the capabilities of diffusion models and large language models (LLMs). Unlike existing multimodal models that predominately depend on encoders like CLIP or ImageBind and need ample amounts of training data to bridge the gap between modalities, EasyGen is built upon a bidirectional conditional diffusion model named BiDiffuser, which promotes more efficient interactions between modalities. EasyGen handles image-to-text generation by integrating BiDiffuser and an LLM via a simple projection layer. Unlike most existing multimodal models that are limited to generating text responses, EasyGen can also facilitate text-to-image generation by leveraging the LLM to create textual descriptions, which can be interpreted by BiDiffuser to generate appropriate visual responses. Extensive quantitative and qualitative experiments demonstrate the effectiveness of EasyGen, whose training can be easily achieved in a lab setting. The source code is available at https://github.com/zxy556677/EasyGen.
Recon: Reducing Conflicting Gradients from the Root for Multi-Task Learning
Feb 22, 2023



A fundamental challenge for multi-task learning is that different tasks may conflict with each other when they are solved jointly, and a cause of this phenomenon is conflicting gradients during optimization. Recent works attempt to mitigate the influence of conflicting gradients by directly altering the gradients based on some criteria. However, our empirical study shows that ``gradient surgery'' cannot effectively reduce the occurrence of conflicting gradients. In this paper, we take a different approach to reduce conflicting gradients from the root. In essence, we investigate the task gradients w.r.t. each shared network layer, select the layers with high conflict scores, and turn them to task-specific layers. Our experiments show that such a simple approach can greatly reduce the occurrence of conflicting gradients in the remaining shared layers and achieve better performance, with only a slight increase in model parameters in many cases. Our approach can be easily applied to improve various state-of-the-art methods including gradient manipulation methods and branched architecture search methods. Given a network architecture (e.g., ResNet18), it only needs to search for the conflict layers once, and the network can be modified to be used with different methods on the same or even different datasets to gain performance improvement. The source code is available at https://github.com/moukamisama/Recon.
A Closer Look at Blind Super-Resolution: Degradation Models, Baselines, and Performance Upper Bounds
May 10, 2022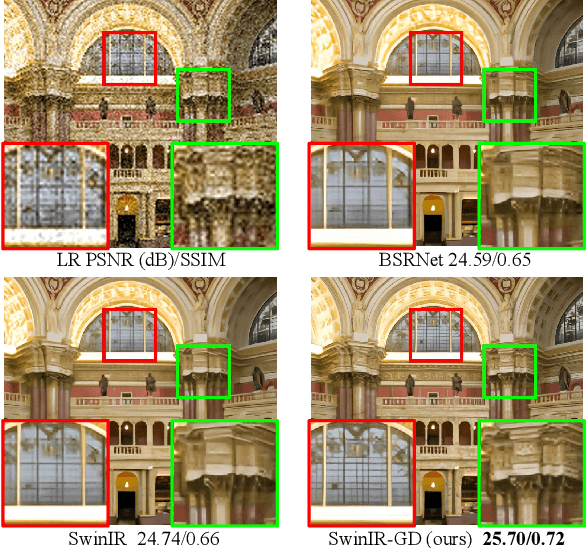

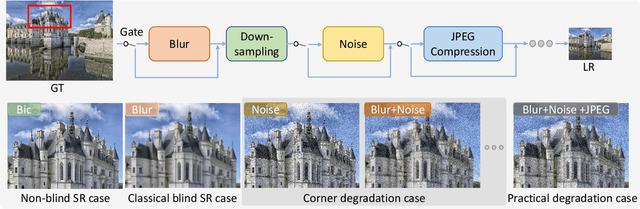
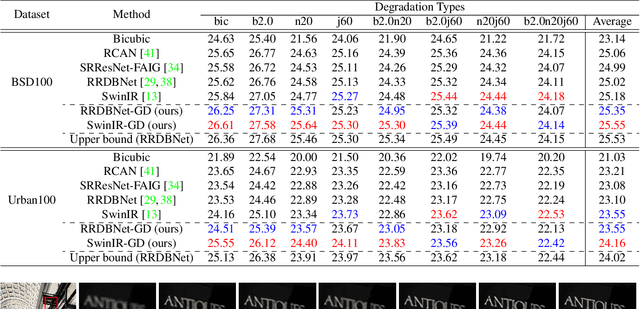
Degradation models play an important role in Blind super-resolution (SR). The classical degradation model, which mainly involves blur degradation, is too simple to simulate real-world scenarios. The recently proposed practical degradation model includes a full spectrum of degradation types, but only considers complex cases that use all degradation types in the degradation process, while ignoring many important corner cases that are common in the real world. To address this problem, we propose a unified gated degradation model to generate a broad set of degradation cases using a random gate controller. Based on the gated degradation model, we propose simple baseline networks that can effectively handle non-blind, classical, practical degradation cases as well as many other corner cases. To fairly evaluate the performance of our baseline networks against state-of-the-art methods and understand their limits, we introduce the performance upper bound of an SR network for every degradation type. Our empirical analysis shows that with the unified gated degradation model, the proposed baselines can achieve much better performance than existing methods in quantitative and qualitative results, which are close to the performance upper bounds.
Overcoming Catastrophic Forgetting in Incremental Few-Shot Learning by Finding Flat Minima
Nov 04, 2021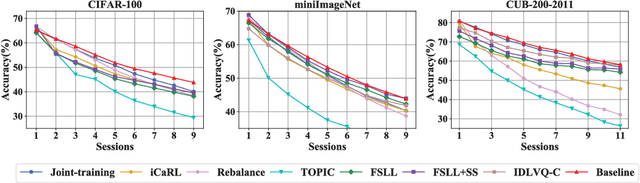
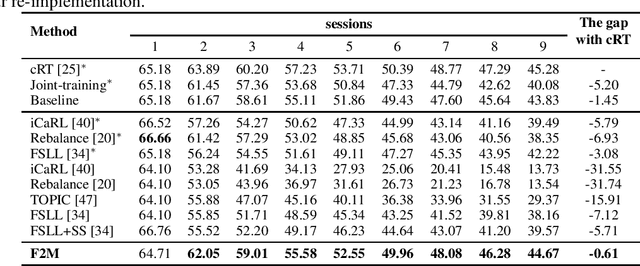
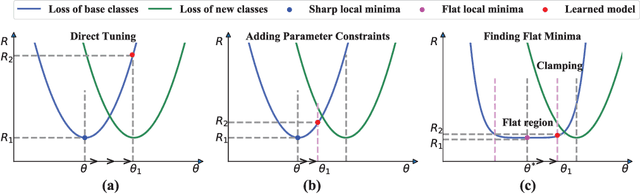
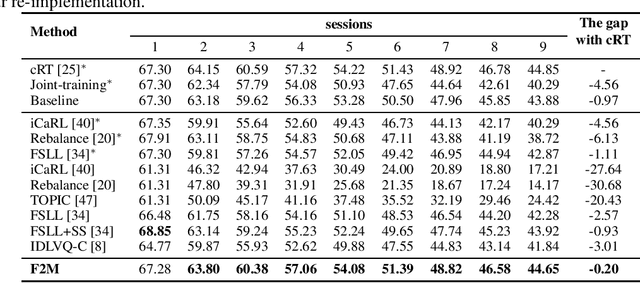
This paper considers incremental few-shot learning, which requires a model to continually recognize new categories with only a few examples provided. Our study shows that existing methods severely suffer from catastrophic forgetting, a well-known problem in incremental learning, which is aggravated due to data scarcity and imbalance in the few-shot setting. Our analysis further suggests that to prevent catastrophic forgetting, actions need to be taken in the primitive stage -- the training of base classes instead of later few-shot learning sessions. Therefore, we propose to search for flat local minima of the base training objective function and then fine-tune the model parameters within the flat region on new tasks. In this way, the model can efficiently learn new classes while preserving the old ones. Comprehensive experimental results demonstrate that our approach outperforms all prior state-of-the-art methods and is very close to the approximate upper bound. The source code is available at https://github.com/moukamisama/F2M.
Effectiveness of Pre-training for Few-shot Intent Classification
Sep 13, 2021
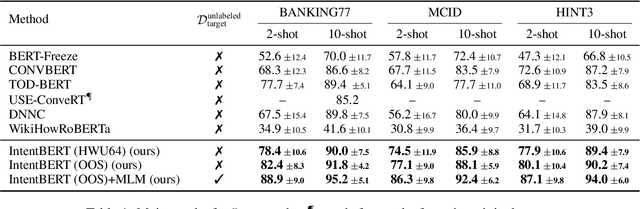
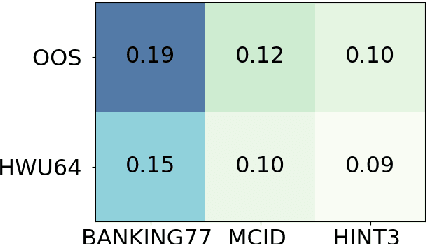
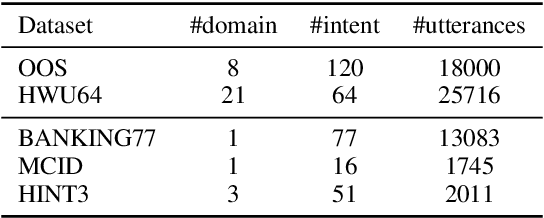
This paper investigates the effectiveness of pre-training for few-shot intent classification. While existing paradigms commonly further pre-train language models such as BERT on a vast amount of unlabeled corpus, we find it highly effective and efficient to simply fine-tune BERT with a small set of labeled utterances from public datasets. Specifically, fine-tuning BERT with roughly 1,000 labeled data yields a pre-trained model -- IntentBERT, which can easily surpass the performance of existing pre-trained models for few-shot intent classification on novel domains with very different semantics. The high effectiveness of IntentBERT confirms the feasibility and practicality of few-shot intent detection, and its high generalization ability across different domains suggests that intent classification tasks may share a similar underlying structure, which can be efficiently learned from a small set of labeled data. The source code can be found at https://github.com/hdzhang-code/IntentBERT.