 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC-Bayes Bounds for Meta-learning with Data-Dependent Prior
Feb 07, 2021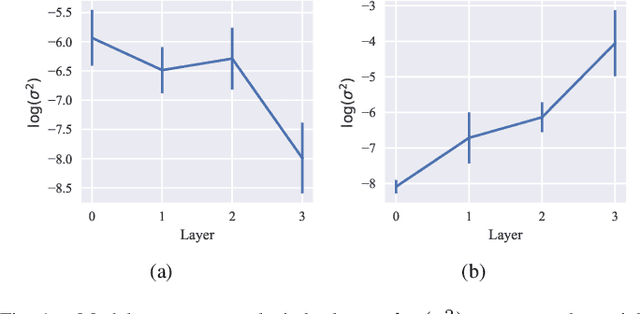
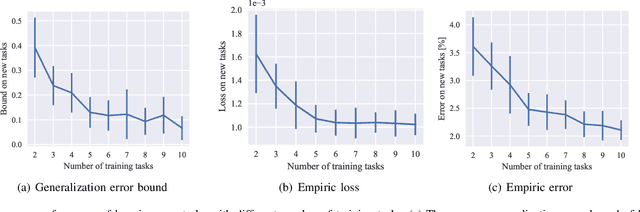
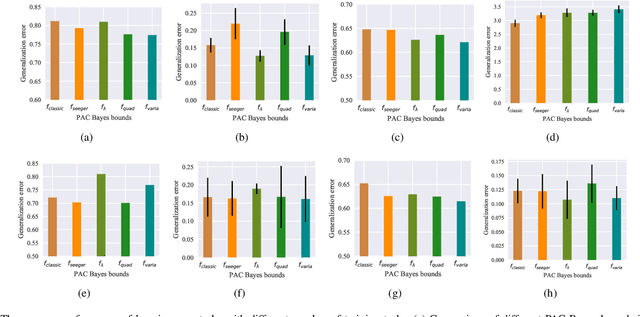
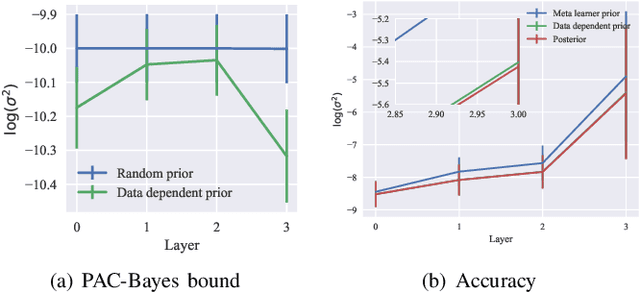
By leveraging experience from previous tasks, meta-learning algorithms can achieve effective fast adaptation ability when encountering new tasks. However it is unclear how the generalization property applies to new tasks. Probably approximately correct (PAC) Bayes bound theory provides a theoretical framework to analyze the generalization performance for meta-learning. We derive three novel generalisation error bounds for meta-learning based on PAC-Bayes relative entropy bound. Furthermore, using the empirical risk minimization (ERM) method, a PAC-Bayes bound for meta-learning with data-dependent prior is developed. Experiments illustrate that the proposed three PAC-Bayes bounds for meta-learning guarantee a competitive generalization performance guarantee, and the extended PAC-Bayes bound with data-dependent prior can achieve rapid convergence ability.
How does the Combined Risk Affect the Performance of Unsupervised Domain Adaptation Approaches?
Dec 30, 2020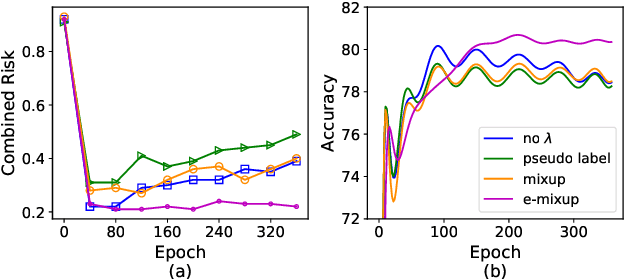
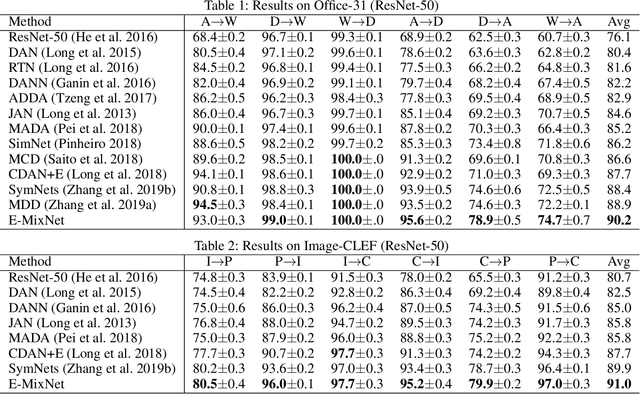
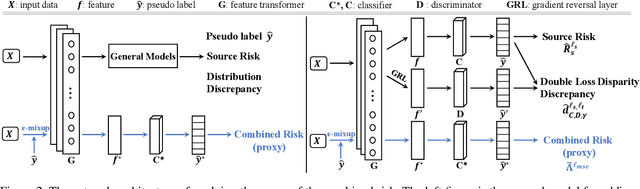
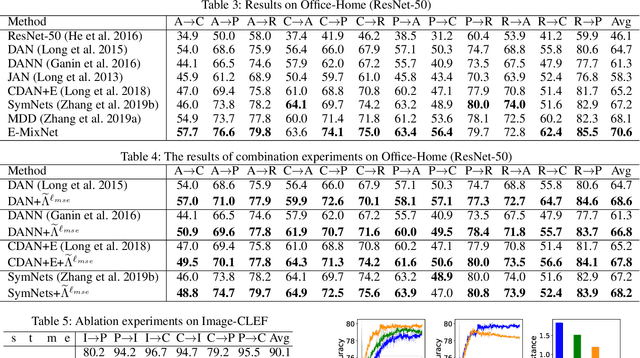
Unsupervised domain adaptation (UDA) aims to train a target classifier with labeled samples from the source domain and unlabeled samples from the target domain. Classical UDA learning bounds show that target risk is upper bounded by three terms: source risk, distribution discrepancy, and combined risk. Based on the assumption that the combined risk is a small fixed value, methods based on this bound train a target classifier by only minimizing estimators of the source risk and the distribution discrepancy. However, the combined risk may increase when minimizing both estimators, which makes the target risk uncontrollable. Hence the target classifier cannot achieve ideal performance if we fail to control the combined risk. To control the combined risk, the key challenge takes root in the unavailability of the labeled samples in the target domain. To address this key challenge, we propose a method named E-MixNet. E-MixNet employs enhanced mixup, a generic vicinal distribution, on the labeled source samples and pseudo-labeled target samples to calculate a proxy of the combined risk. Experiments show that the proxy can effectively curb the increase of the combined risk when minimizing the source risk and distribution discrepancy. Furthermore, we show that if the proxy of the combined risk is added into loss functions of four representative UDA methods, their performance is also improved.
Concept Drift Detection: Dealing with MissingValues via Fuzzy Distance Estimations
Aug 09, 2020In data streams, the data distribution of arriving observations at different time points may change - a phenomenon called concept drift. While detecting concept drift is a relatively mature area of study, solutions to the uncertainty introduced by observations with missing values have only been studied in isolation. No one has yet explored whether or how these solutions might impact drift detection performance. We, however, believe that data imputation methods may actually increase uncertainty in the data rather than reducing it. We also conjecture that imputation can introduce bias into the process of estimating distribution changes during drift detection, which can make it more difficult to train a learning model. Our idea is to focus on estimating the distance between observations rather than estimating the missing values, and to define membership functions that allocate observations to histogram bins according to the estimation errors. Our solution comprises a novel masked distance learning (MDL) algorithm to reduce the cumulative errors caused by iteratively estimating each missing value in an observation and a fuzzy-weighted frequency (FWF) method for identifying discrepancies in the data distribution. The concept drift detection algorithm proposed in this paper is a singular and unified algorithm that can handle missing values, but not an imputation algorithm combined with a concept drift detection algorithm. Experiments on both synthetic and real-world data sets demonstrate the advantages of this method and show its robustness in detecting drift in data with missing values. These findings reveal that missing values exert a profound impact on concept drift detection, but using fuzzy set theory to model observations can produce more reliable results than imputation.
Learning from a Complementary-label Source Domain: Theory and Algorithms
Aug 04, 2020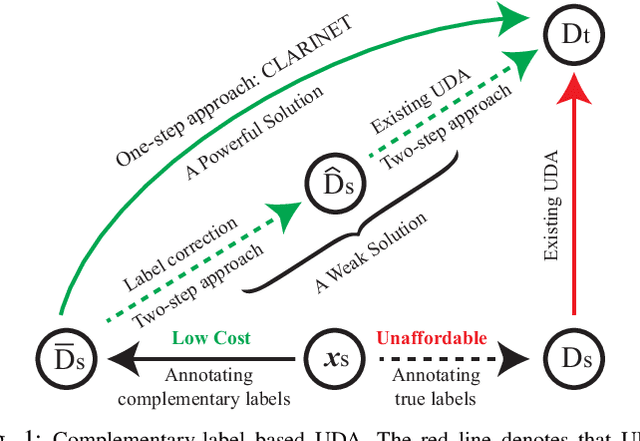

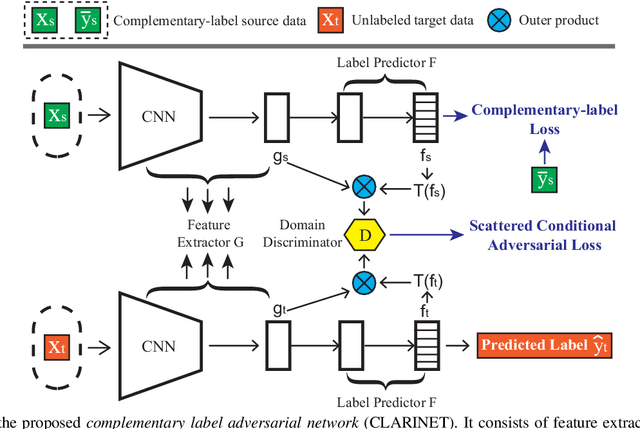
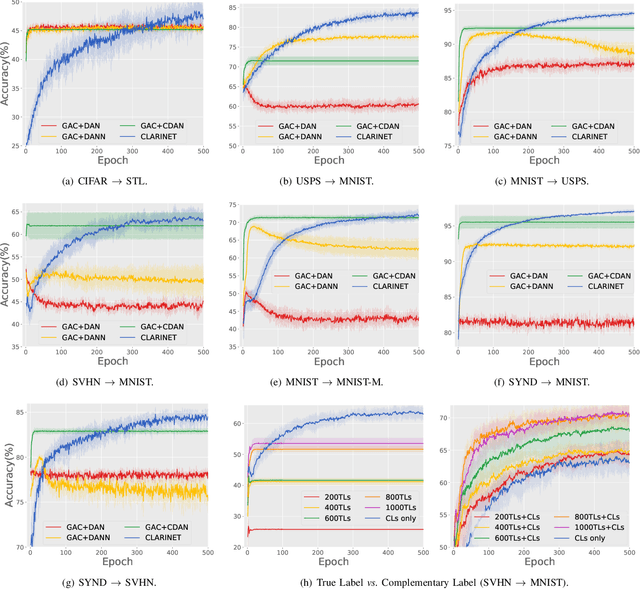
In unsupervised domain adaptation (UDA), a classifier for the target domain is trained with massive true-label data from the source domain and unlabeled data from the target domain. However, collecting fully-true-label data in the source domain is high-cost and sometimes impossible. Compared to the true labels, a complementary label specifies a class that a pattern does not belong to, hence collecting complementary labels would be less laborious than collecting true labels. Thus, in this paper, we propose a novel setting that the source domain is composed of complementary-label data, and a theoretical bound for it is first proved. We consider two cases of this setting, one is that the source domain only contains complementary-label data (completely complementary unsupervised domain adaptation, CC-UDA), and the other is that the source domain has plenty of complementary-label data and a small amount of true-label data (partly complementary unsupervised domain adaptation, PC-UDA). To this end, a complementary label adversarial network} (CLARINET) is proposed to solve CC-UDA and PC-UDA problems. CLARINET maintains two deep networks simultaneously, where one focuses on classifying complementary-label source data and the other takes care of source-to-target distributional adaptation. Experiments show that CLARINET significantly outperforms a series of competent baselines on handwritten-digits-recognition and objects-recognition tasks.
Clarinet: A One-step Approach Towards Budget-friendly Unsupervised Domain Adaptation
Jul 29, 2020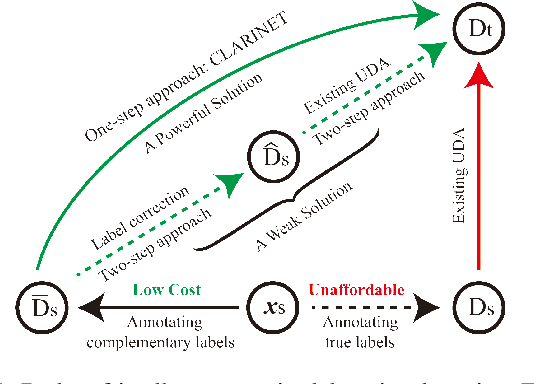
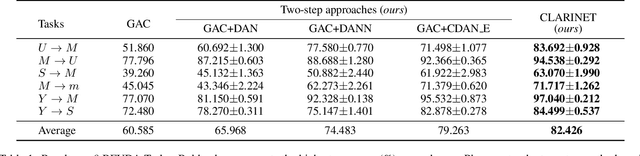
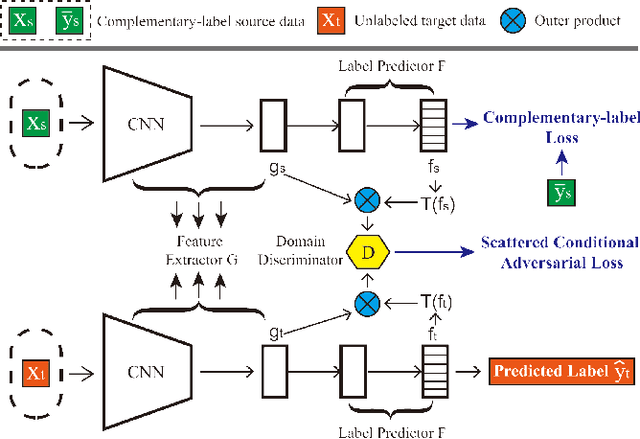

In unsupervised domain adaptation (UDA), classifiers for the target domain are trained with massive true-label data from the source domain and unlabeled data from the target domain. However, it may be difficult to collect fully-true-label data in a source domain given a limited budget. To mitigate this problem, we consider a novel problem setting where the classifier for the target domain has to be trained with complementary-label data from the source domain and unlabeled data from the target domain named budget-friendly UDA (BFUDA). The key benefit is that it is much less costly to collect complementary-label source data (required by BFUDA) than collecting the true-label source data (required by ordinary UDA). To this end, the complementary label adversarial network (CLARINET) is proposed to solve the BFUDA problem. CLARINET maintains two deep networks simultaneously, where one focuses on classifying complementary-label source data and the other takes care of the source-to-target distributional adaptation. Experiments show that CLARINET significantly outperforms a series of competent baselines.
Bridging the Theoretical Bound and Deep Algorithms for Open Set Domain Adaptation
Jun 23, 2020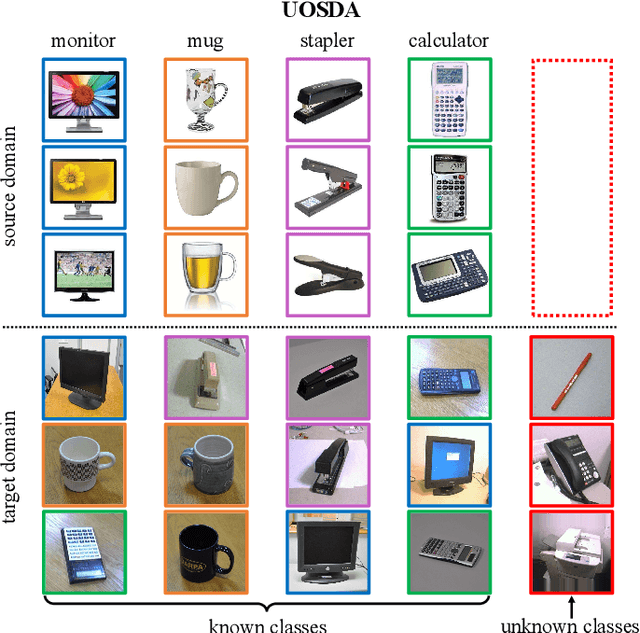
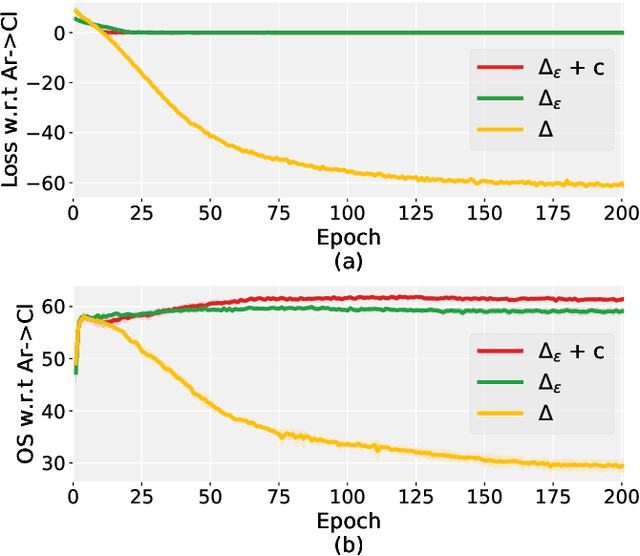
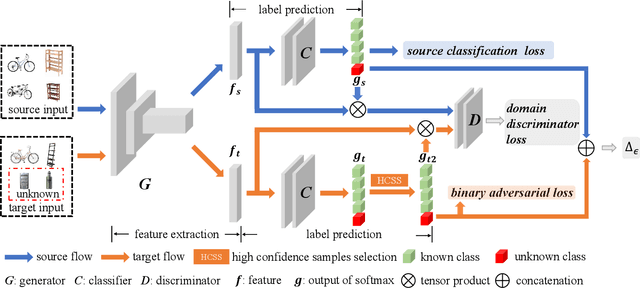
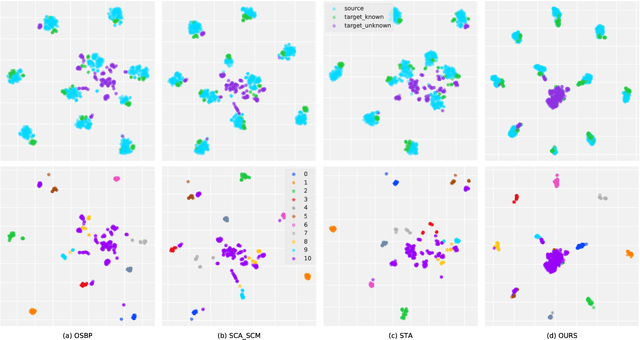
In the unsupervised open set domain adaptation (UOSDA), the target domain contains unknown classes that are not observed in the source domain. Researchers in this area aim to train a classifier to accurately: 1) recognize unknown target data (data with unknown classes) and, 2) classify other target data. To achieve this aim, a previous study has proven an upper bound of the target-domain risk, and the open set difference, as an important term in the upper bound, is used to measure the risk on unknown target data. By minimizing the upper bound, a shallow classifier can be trained to achieve the aim. However, if the classifier is very flexible (e.g., deep neural networks (DNNs)), the open set difference will converge to a negative value when minimizing the upper bound, which causes an issue where most target data are recognized as unknown data. To address this issue, we propose a new upper bound of target-domain risk for UOSDA, which includes four terms: source-domain risk, $\epsilon$-open set difference ($\Delta_\epsilon$), a distributional discrepancy between domains, and a constant. Compared to the open set difference, $\Delta_\epsilon$ is more robust against the issue when it is being minimized, and thus we are able to use very flexible classifiers (i.e., DNNs). Then, we propose a new principle-guided deep UOSDA method that trains DNNs via minimizing the new upper bound. Specifically, source-domain risk and $\Delta_\epsilon$ are minimized by gradient descent, and the distributional discrepancy is minimized via a novel open-set conditional adversarial training strategy. Finally, compared to existing shallow and deep UOSDA methods, our method shows the state-of-the-art performance on several benchmark datasets, including digit recognition (MNIST, SVHN, USPS), object recognition (Office-31, Office-Home), and face recognition (PIE).
Diverse Instances-Weighting Ensemble based on Region Drift Disagreement for Concept Drift Adaptation
Apr 13, 2020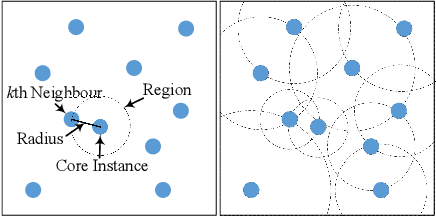

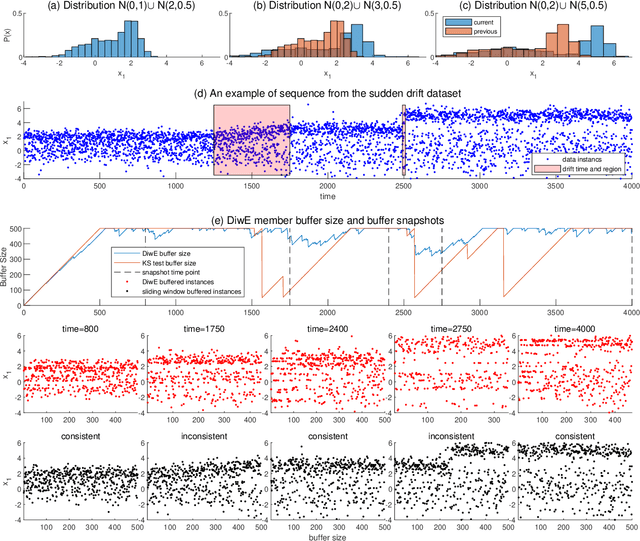
Concept drift refers to changes in the distribution of underlying data and is an inherent property of evolving data streams. Ensemble learning, with dynamic classifiers, has proved to be an efficient method of handling concept drift. However, the best way to create and maintain ensemble diversity with evolving streams is still a challenging problem. In contrast to estimating diversity via inputs, outputs, or classifier parameters, we propose a diversity measurement based on whether the ensemble members agree on the probability of a regional distribution change. In our method, estimations over regional distribution changes are used as instance weights. Constructing different region sets through different schemes will lead to different drift estimation results, thereby creating diversity. The classifiers that disagree the most are selected to maximize diversity. Accordingly, an instance-based ensemble learning algorithm, called the diverse instance weighting ensemble (DiwE), is developed to address concept drift for data stream classification problems. Evaluations of various synthetic and real-world data stream benchmarks show the effectiveness and advantages of the proposed algorithm.
Learning under Concept Drift: A Review
Apr 13, 2020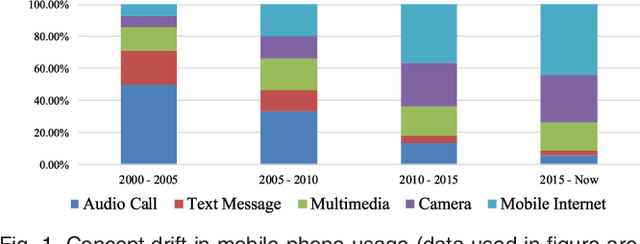
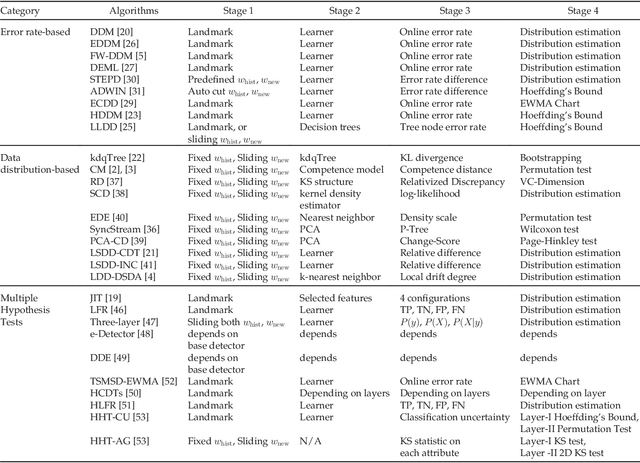
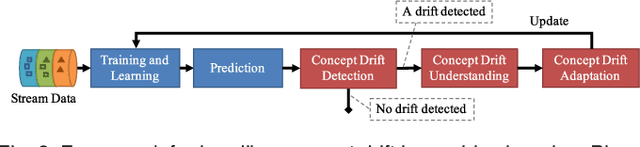
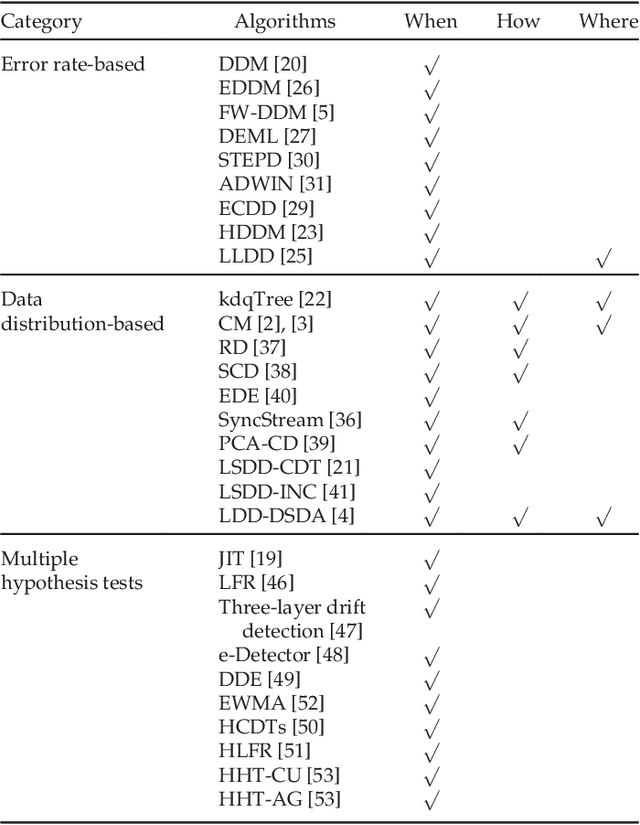
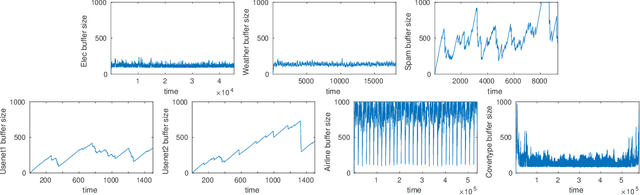
Concept drift describes unforeseeable changes in the underlying distribution of streaming data over time. Concept drift research involves the development of methodologies and techniques for drift detection, understanding and adaptation. Data analysis has revealed that machine learning in a concept drift environment will result in poor learning results if the drift is not addressed. To help researchers identify which research topics are significant and how to apply related techniques in data analysis tasks, it is necessary that a high quality, instructive review of current research developments and trends in the concept drift field is conducted. In addition, due to the rapid development of concept drift in recent years, the methodologies of learning under concept drift have become noticeably systematic, unveiling a framework which has not been mentioned in literature. This paper reviews over 130 high quality publications in concept drift related research areas, analyzes up-to-date developments in methodologies and techniques, and establishes a framework of learning under concept drift including three main components: concept drift detection, concept drift understanding, and concept drift adaptation. This paper lists and discusses 10 popular synthetic datasets and 14 publicly available benchmark datasets used for evaluating the performance of learning algorithms aiming at handling concept drift. Also, concept drift related research directions are covered and discussed. By providing state-of-the-art knowledge, this survey will directly support researchers in their understanding of research developments in the field of learning under concept drift.
Learning Deep Kernels for Non-Parametric Two-Sample Tests
Feb 21, 2020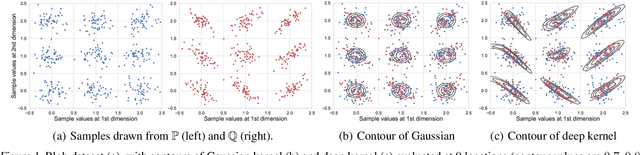
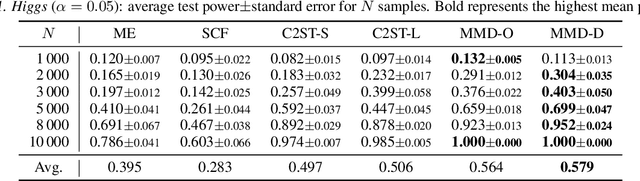
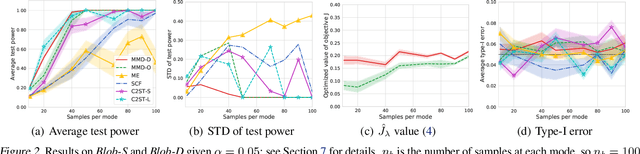
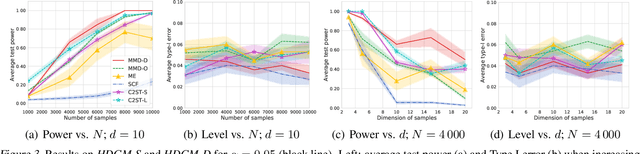
We propose a class of kernel-based two-sample tests, which aim to determine whether two sets of samples are drawn from the same distribution. Our tests are constructed from kernels parameterized by deep neural nets, trained to maximize test power. These tests adapt to variations in distribution smoothness and shape over space, and are especially suited to high dimensions and complex data. By contrast, the simpler kernels used in prior kernel testing work are spatially homogeneous, and adaptive only in lengthscale. We explain how this scheme includes popular classifier-based two-sample tests as a special case, but improves on them in general. We provide the first proof of consistency for the proposed adaptation method, which applies both to kernels on deep features and to simpler radial basis kernels or multiple kernel learning. In experiments, we establish the superior performance of our deep kernels in hypothesis testing on benchmark and real-world data. The code of our deep-kernel-based two sample tests is available at https://github.com/fengliu90/DK-for-TST.
Cross-domain Network Representations
Aug 01, 2019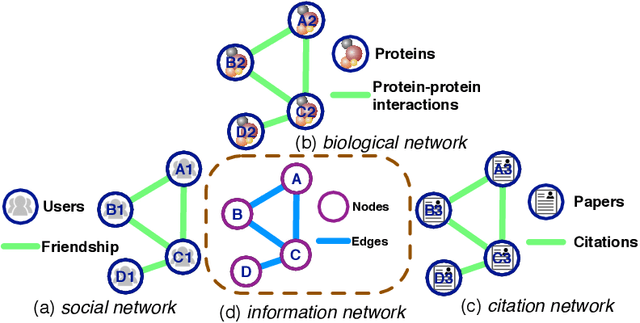
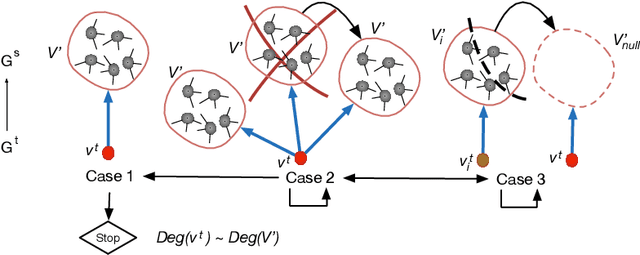

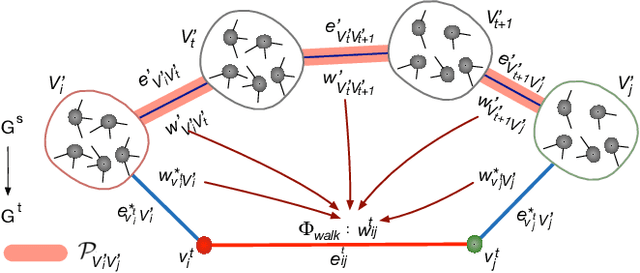
The purpose of network representation is to learn a set of latent features by obtaining community information from network structures to provide knowledge for machine learning tasks. Recent research has driven significant progress in network representation by employing random walks as the network sampling strategy. Nevertheless, existing approaches rely on domain-specifically rich community structures and fail in the network that lack topological information in its own domain. In this paper, we propose a novel algorithm for cross-domain network representation, named as CDNR. By generating the random walks from a structural rich domain and transferring the knowledge on the random walks across domains, it enables a network representation for the structural scarce domain as well. To be specific, CDNR is realized by a cross-domain two-layer node-scale balance algorithm and a cross-domain two-layer knowledge transfer algorithm in the framework of cross-domain two-layer random walk learning. Experiments on various real-world datasets demonstrate the effectiveness of CDNR for universal networks in an unsupervised way.