 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Transformer Based Crowd Counting
Sep 04, 2021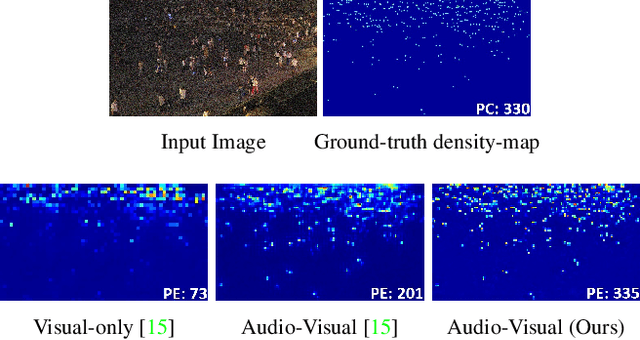
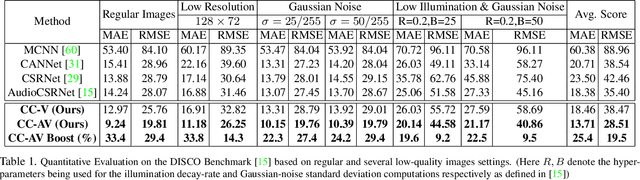
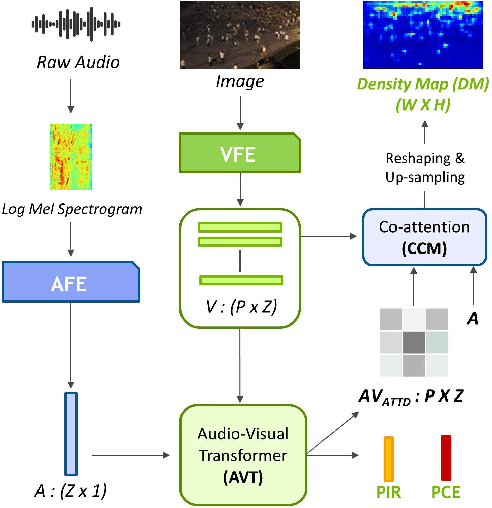
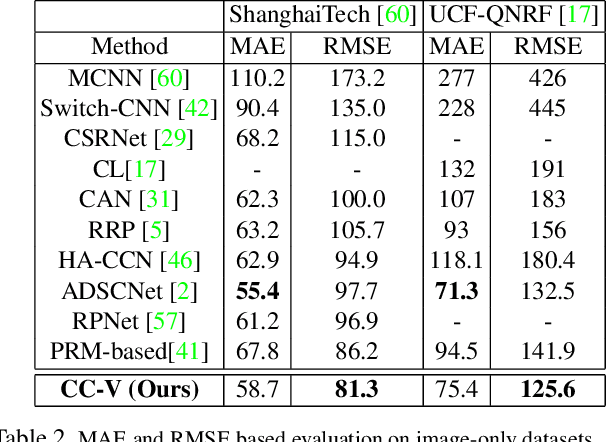
Crowd estimation is a very challenging problem. The most recent study tries to exploit auditory information to aid the visual models, however, the performance is limited due to the lack of an effective approach for feature extraction and integration. The paper proposes a new audiovisual multi-task network to address the critical challenges in crowd counting by effectively utilizing both visual and audio inputs for better modalities association and productive feature extraction. The proposed network introduces the notion of auxiliary and explicit image patch-importance ranking (PIR) and patch-wise crowd estimate (PCE) information to produce a third (run-time) modality. These modalities (audio, visual, run-time) undergo a transformer-inspired cross-modality co-attention mechanism to finally output the crowd estimate. To acquire rich visual features, we propose a multi-branch structure with transformer-style fusion in-between. Extensive experimental evaluations show that the proposed scheme outperforms the state-of-the-art networks under all evaluation settings with up to 33.8% improvement. We also analyze and compare the vision-only variant of our network and empirically demonstrate its superiority over previous approaches.
DRB-GAN: A Dynamic ResBlock Generative Adversarial Network for Artistic Style Transfer
Aug 19, 2021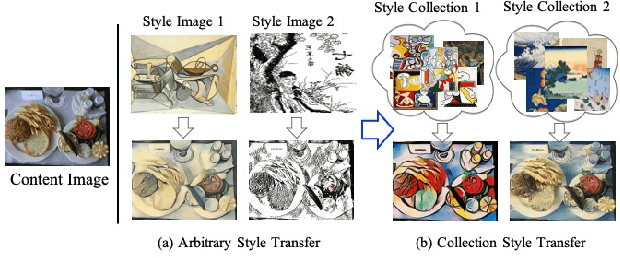
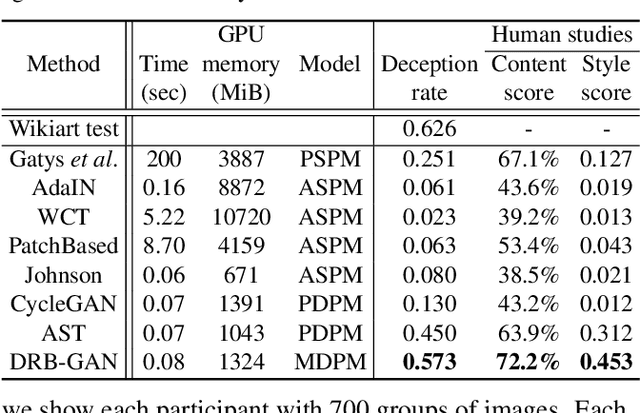
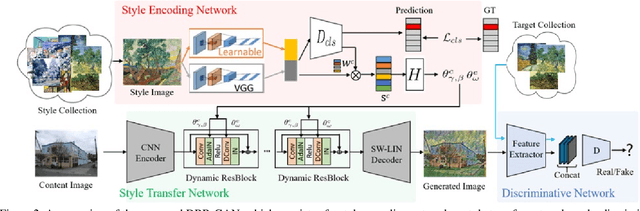

The paper proposes a Dynamic ResBlock Generative Adversarial Network (DRB-GAN) for artistic style transfer. The style code is modeled as the shared parameters for Dynamic ResBlocks connecting both the style encoding network and the style transfer network. In the style encoding network, a style class-aware attention mechanism is used to attend the style feature representation for generating the style codes. In the style transfer network, multiple Dynamic ResBlocks are designed to integrate the style code and the extracted CNN semantic feature and then feed into the spatial window Layer-Instance Normalization (SW-LIN) decoder, which enables high-quality synthetic images with artistic style transfer. Moreover, the style collection conditional discriminator is designed to equip our DRB-GAN model with abilities for both arbitrary style transfer and collection style transfer during the training stage. No matter for arbitrary style transfer or collection style transfer, extensive experiments strongly demonstrate that our proposed DRB-GAN outperforms state-of-the-art methods and exhibits its superior performance in terms of visual quality and efficiency. Our source code is available at \color{magenta}{\url{https://github.com/xuwenju123/DRB-GAN}}.
Multiple Classifiers Based Maximum Classifier Discrepancy for Unsupervised Domain Adaptation
Aug 02, 2021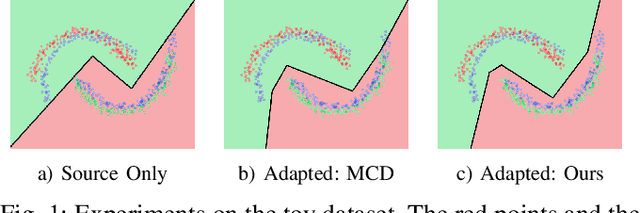
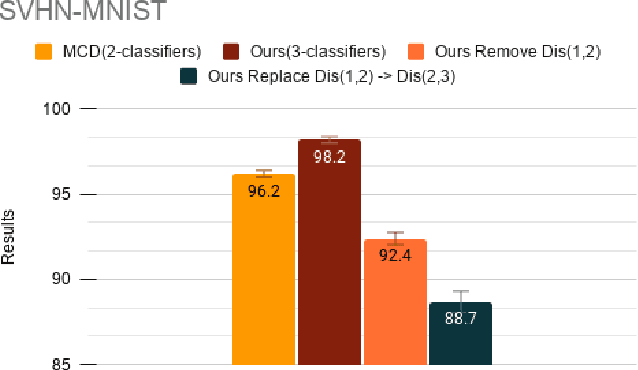
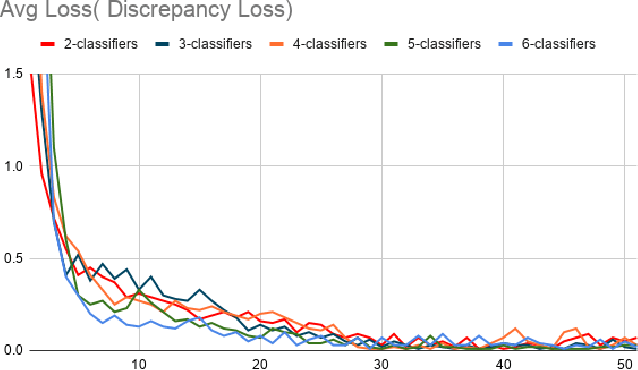
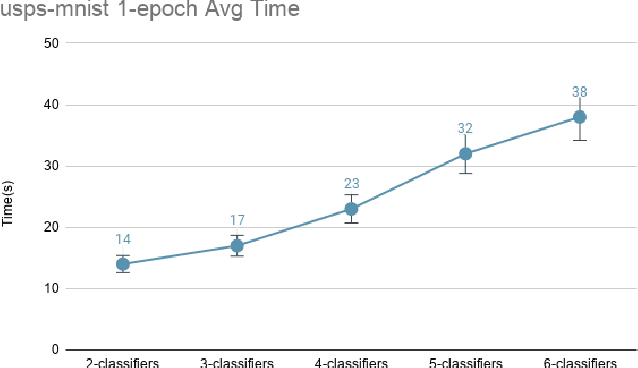
Adversarial training based on the maximum classifier discrepancy between the two classifier structures has achieved great success in unsupervised domain adaptation tasks for image classification. The approach adopts the structure of two classifiers, though simple and intuitive, the learned classification boundary may not well represent the data property in the new domain. In this paper, we propose to extend the structure to multiple classifiers to further boost its performance. To this end, we propose a very straightforward approach to adding more classifiers. We employ the principle that the classifiers are different from each other to construct a discrepancy loss function for multiple classifiers. Through the loss function construction method, we make it possible to add any number of classifiers to the original framework. The proposed approach is validated through extensive experimental evaluations. We demonstrate that, on average, adopting the structure of three classifiers normally yields the best performance as a trade-off between the accuracy and efficiency. With minimum extra computational costs, the proposed approach can significantly improve the original algorithm.
Momentum Accelerates the Convergence of Stochastic AUPRC Maximization
Jul 02, 2021
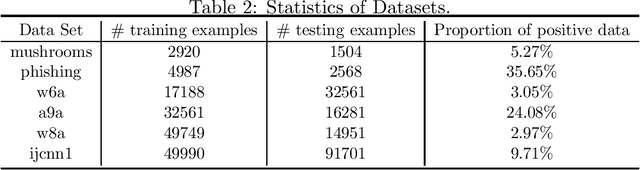
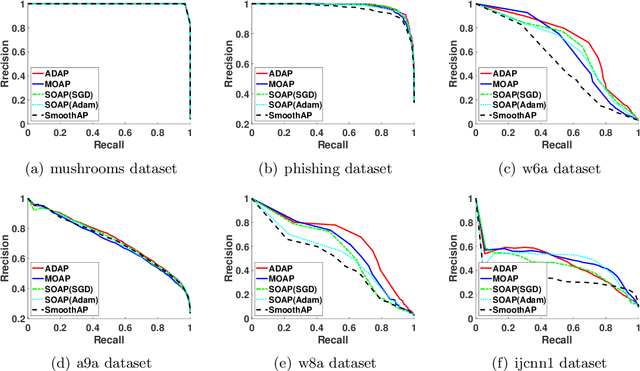
In this paper, we study stochastic optimization of areas under precision-recall curves (AUPRC), which is widely used for combating imbalanced classification tasks. Although a few methods have been proposed for maximizing AUPRC, stochastic optimization of AUPRC with convergence guarantee remains an undeveloped territory. A recent work [42] has proposed a promising approach towards AUPRC based on maximizing a surrogate loss for the average precision, and proved an $O(1/\epsilon^5)$ complexity for finding an $\epsilon$-stationary solution of the non-convex objective. In this paper, we further improve the stochastic optimization of AURPC by (i) developing novel stochastic momentum methods with a better iteration complexity of $O(1/\epsilon^4)$ for finding an $\epsilon$-stationary solution; and (ii) designing a novel family of stochastic adaptive methods with the same iteration complexity of $O(1/\epsilon^4)$, which enjoy faster convergence in practice. To this end, we propose two innovative techniques that are critical for improving the convergence: (i) the biased estimators for tracking individual ranking scores are updated in a randomized coordinate-wise manner; and (ii) a momentum update is used on top of the stochastic gradient estimator for tracking the gradient of the objective. Extensive experiments on various data sets demonstrate the effectiveness of the proposed algorithms. Of independent interest, the proposed stochastic momentum and adaptive algorithms are also applicable to a class of two-level stochastic dependent compositional optimization problems.
A Fine-Grained Visual Attention Approach for Fingerspelling Recognition in the Wild
May 17, 2021
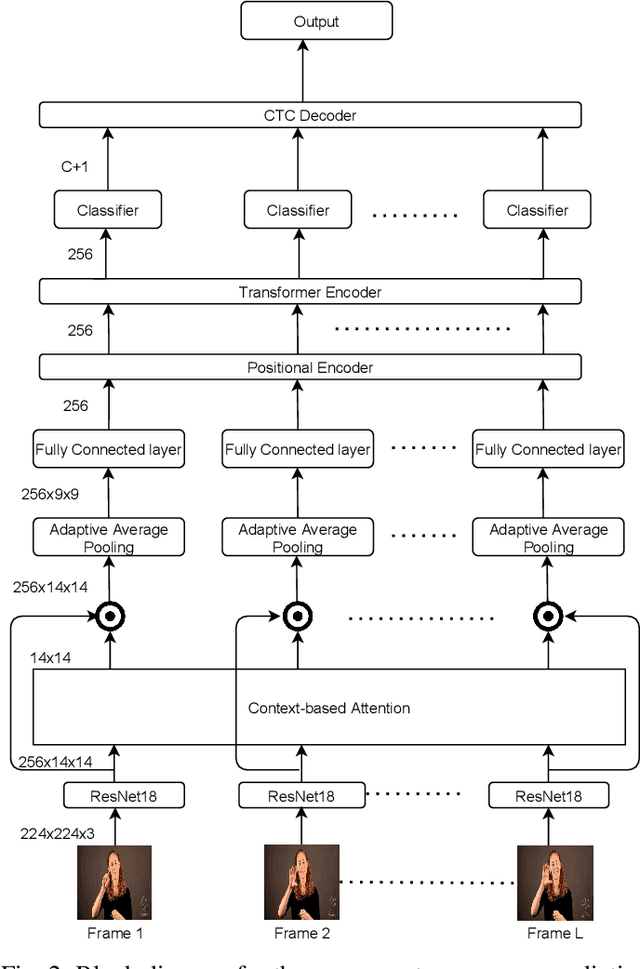
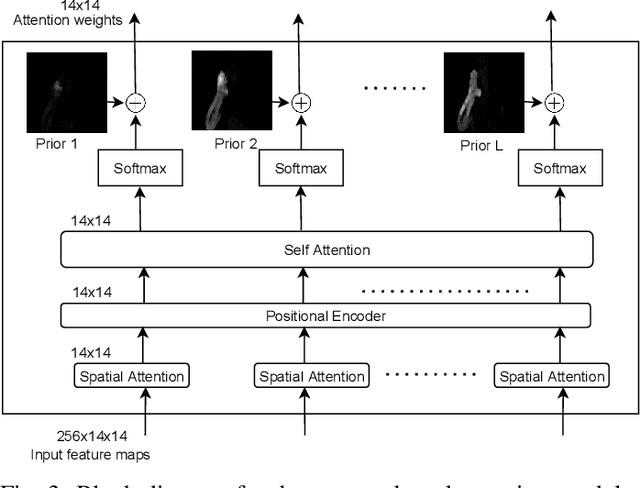
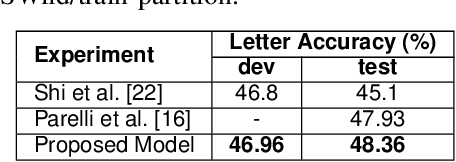
Fingerspelling in sign language has been the means of communicating technical terms and proper nouns when they do not have dedicated sign language gestures. Automatic recognition of fingerspelling can help resolve communication barriers when interacting with deaf people. The main challenges prevalent in fingerspelling recognition are the ambiguity in the gestures and strong articulation of the hands. The automatic recognition model should address high inter-class visual similarity and high intra-class variation in the gestures. Most of the existing research in fingerspelling recognition has focused on the dataset collected in a controlled environment. The recent collection of a large-scale annotated fingerspelling dataset in the wild, from social media and online platforms, captures the challenges in a real-world scenario. In this work, we propose a fine-grained visual attention mechanism using the Transformer model for the sequence-to-sequence prediction task in the wild dataset. The fine-grained attention is achieved by utilizing the change in motion of the video frames (optical flow) in sequential context-based attention along with a Transformer encoder model. The unsegmented continuous video dataset is jointly trained by balancing the Connectionist Temporal Classification (CTC) loss and the maximum-entropy loss. The proposed approach can capture better fine-grained attention in a single iteration. Experiment evaluations show that it outperforms the state-of-the-art approaches.
A Simple yet Universal Strategy for Online Convex Optimization
May 14, 2021Recently, several universal methods have been proposed for online convex optimization, and attain minimax rates for multiple types of convex functions simultaneously. However, they need to design and optimize one surrogate loss for each type of functions, which makes it difficult to exploit the structure of the problem and utilize the vast amount of existing algorithms. In this paper, we propose a simple strategy for universal online convex optimization, which avoids these limitations. The key idea is to construct a set of experts to process the original online functions, and deploy a meta-algorithm over the \emph{linearized} losses to aggregate predictions from experts. Specifically, we choose Adapt-ML-Prod to track the best expert, because it has a second-order bound and can be used to leverage strong convexity and exponential concavity. In this way, we can plug in off-the-shelf online solvers as black-box experts to deliver problem-dependent regret bounds. Furthermore, our strategy inherits the theoretical guarantee of any expert designed for strongly convex functions and exponentially concave functions, up to a double logarithmic factor. For general convex functions, it maintains the minimax optimality and also achieves a small-loss bound.
Few-Shot Learning by Integrating Spatial and Frequency Representation
May 11, 2021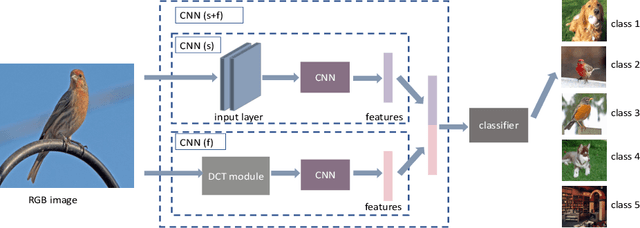
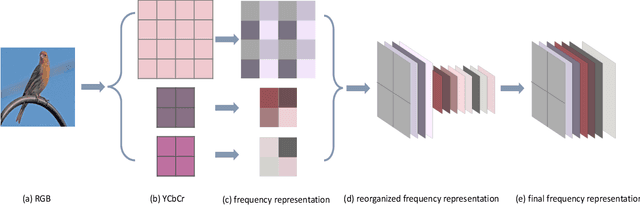
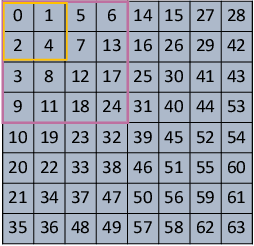
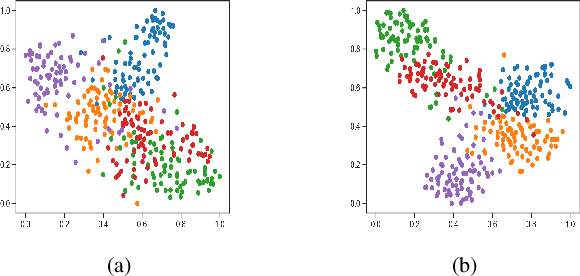
Human beings can recognize new objects with only a few labeled examples, however, few-shot learning remains a challenging problem for machine learning systems. Most previous algorithms in few-shot learning only utilize spatial information of the images. In this paper, we propose to integrate the frequency information into the learning model to boost the discrimination ability of the system. We employ Discrete Cosine Transformation (DCT) to generate the frequency representation, then, integrate the features from both the spatial domain and frequency domain for classification. The proposed strategy and its effectiveness are validated with different backbones, datasets, and algorithms. Extensive experiments demonstrate that the frequency information is complementary to the spatial representations in few-shot classification. The classification accuracy is boosted significantly by integrating features from both the spatial and frequency domains in different few-shot learning tasks.
Enhanced U-Net: A Feature Enhancement Network for Polyp Segmentation
May 03, 2021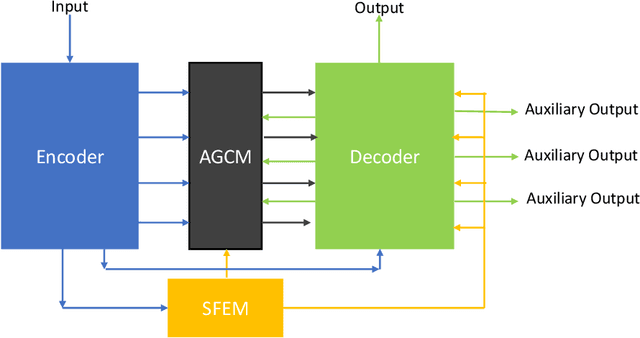
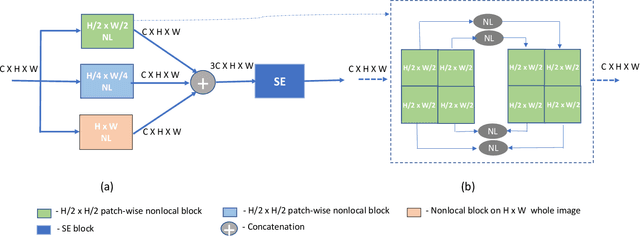
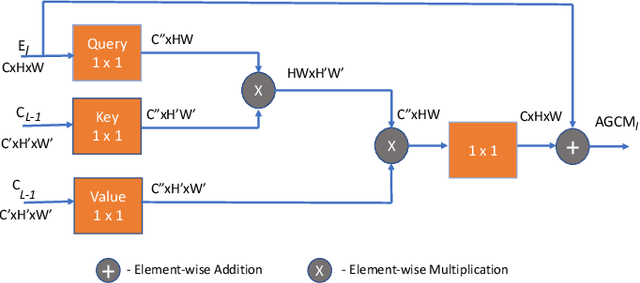
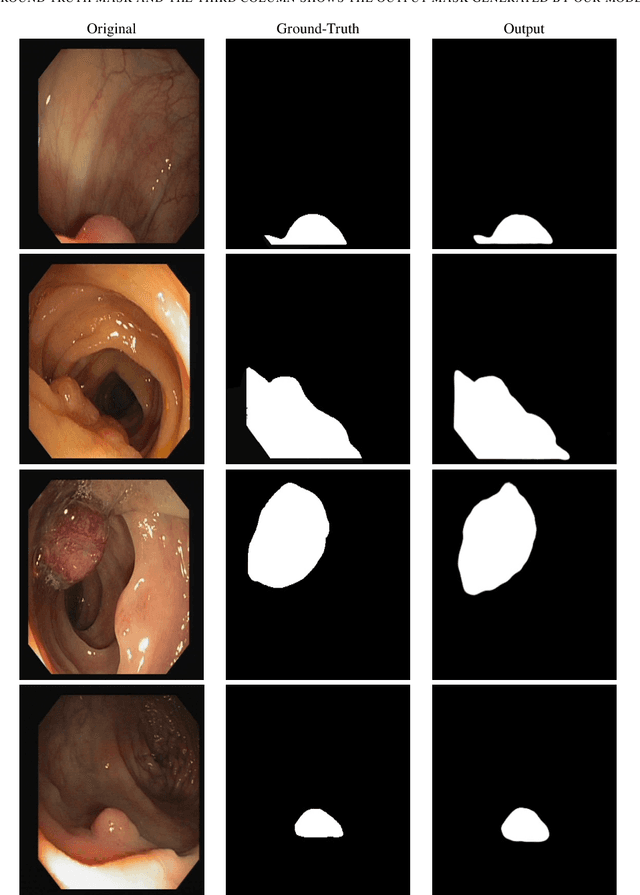
Colonoscopy is a procedure to detect colorectal polyps which are the primary cause for developing colorectal cancer. However, polyp segmentation is a challenging task due to the diverse shape, size, color, and texture of polyps, shuttle difference between polyp and its background, as well as low contrast of the colonoscopic images. To address these challenges, we propose a feature enhancement network for accurate polyp segmentation in colonoscopy images. Specifically, the proposed network enhances the semantic information using the novel Semantic Feature Enhance Module (SFEM). Furthermore, instead of directly adding encoder features to the respective decoder layer, we introduce an Adaptive Global Context Module (AGCM), which focuses only on the encoder's significant and hard fine-grained features. The integration of these two modules improves the quality of features layer by layer, which in turn enhances the final feature representation. The proposed approach is evaluated on five colonoscopy datasets and demonstrates superior performance compared to other state-of-the-art models.
SGNet: A Super-class Guided Network for Image Classification and Object Detection
Apr 26, 2021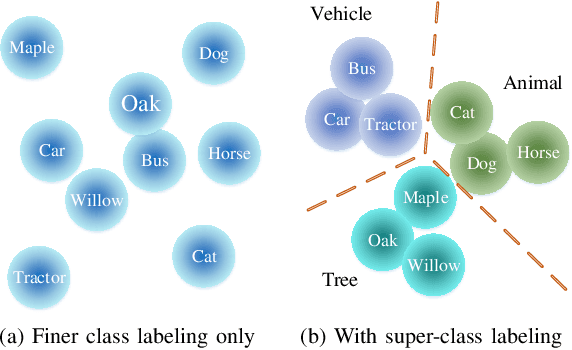
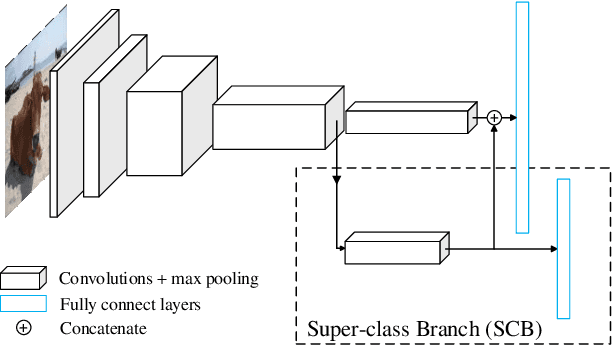
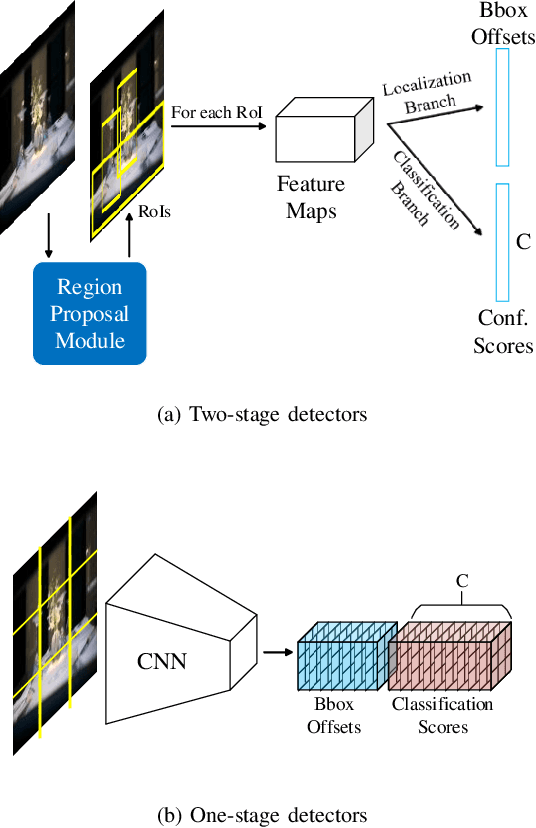
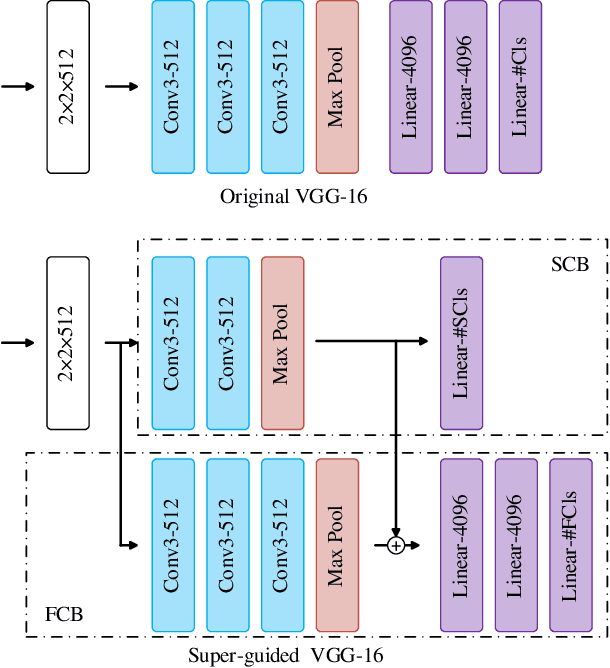
Most classification models treat different object classes in parallel and the misclassifications between any two classes are treated equally. In contrast, human beings can exploit high-level information in making a prediction of an unknown object. Inspired by this observation, the paper proposes a super-class guided network (SGNet) to integrate the high-level semantic information into the network so as to increase its performance in inference. SGNet takes two-level class annotations that contain both super-class and finer class labels. The super-classes are higher-level semantic categories that consist of a certain amount of finer classes. A super-class branch (SCB), trained on super-class labels, is introduced to guide finer class prediction. At the inference time, we adopt two different strategies: Two-step inference (TSI) and direct inference (DI). TSI first predicts the super-class and then makes predictions of the corresponding finer class. On the other hand, DI directly generates predictions from the finer class branch (FCB). Extensive experiments have been performed on CIFAR-100 and MS COCO datasets. The experimental results validate the proposed approach and demonstrate its superior performance on image classification and object detection.
Parallel Scale-wise Attention Network for Effective Scene Text Recognition
Apr 25, 2021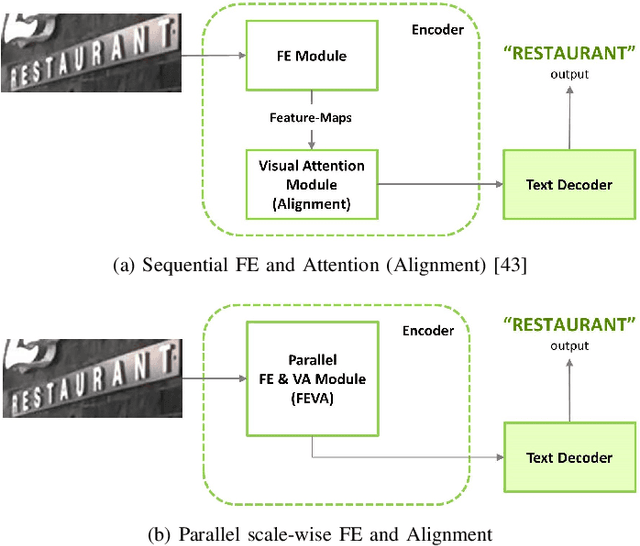
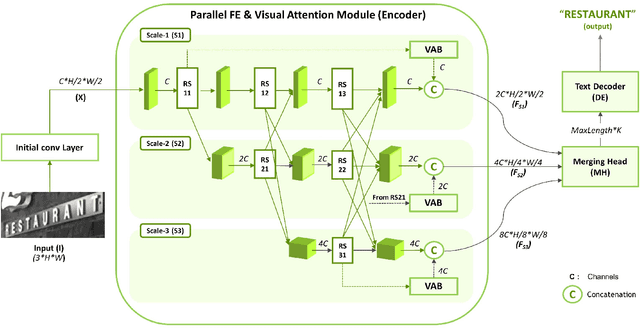
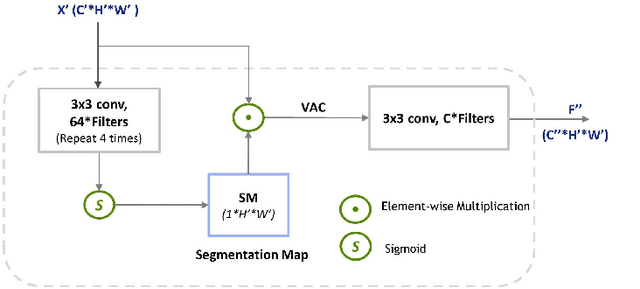
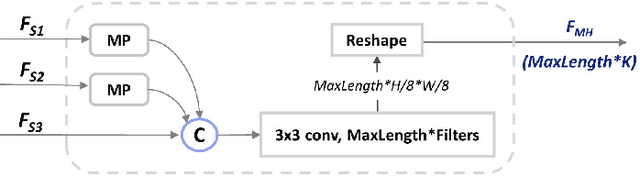
The paper proposes a new text recognition network for scene-text images. Many state-of-the-art methods employ the attention mechanism either in the text encoder or decoder for the text alignment. Although the encoder-based attention yields promising results, these schemes inherit noticeable limitations. They perform the feature extraction (FE) and visual attention (VA) sequentially, which bounds the attention mechanism to rely only on the FE final single-scale output. Moreover, the utilization of the attention process is limited by only applying it directly to the single scale feature-maps. To address these issues, we propose a new multi-scale and encoder-based attention network for text recognition that performs the multi-scale FE and VA in parallel. The multi-scale channels also undergo regular fusion with each other to develop the coordinated knowledge together. Quantitative evaluation and robustness analysis on the standard benchmarks demonstrate that the proposed network outperforms the state-of-the-art in most cases.