 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
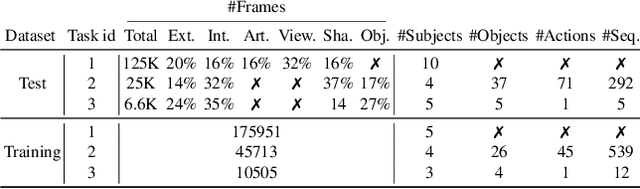
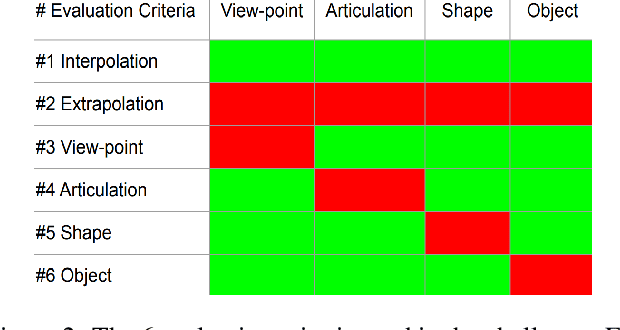
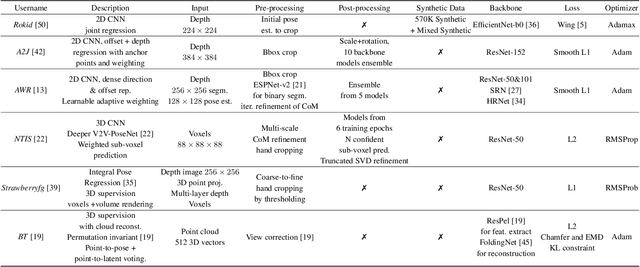
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.
Moulding Humans: Non-parametric 3D Human Shape Estimation from Single Images
Aug 01, 2019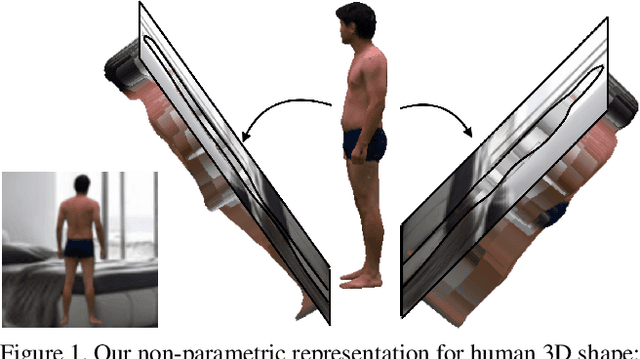

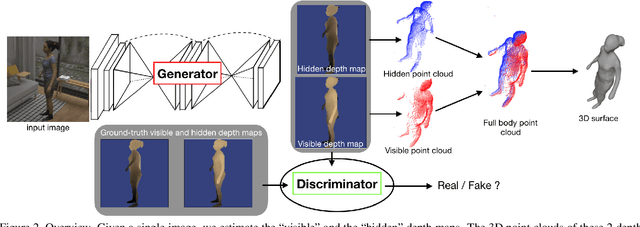
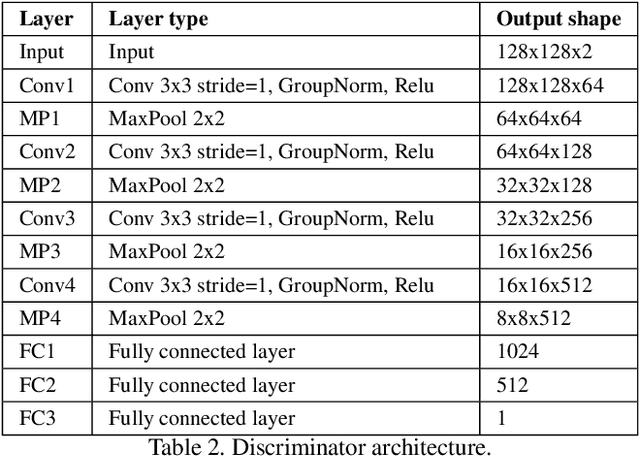
In this paper, we tackle the problem of 3D human shape estimation from single RGB images. While the recent progress in convolutional neural networks has allowed impressive results for 3D human pose estimation, estimating the full 3D shape of a person is still an open issue. Model-based approaches can output precise meshes of naked under-cloth human bodies but fail to estimate details and un-modelled elements such as hair or clothing. On the other hand, non-parametric volumetric approaches can potentially estimate complete shapes but, in practice, they are limited by the resolution of the output grid and cannot produce detailed estimates. In this work, we propose a non-parametric approach that employs a double depth map to represent the 3D shape of a person: a visible depth map and a "hidden" depth map are estimated and combined, to reconstruct the human 3D shape as done with a "mould". This representation through 2D depth maps allows a higher resolution output with a much lower dimension than voxel-based volumetric representations. Additionally, our fully derivable depth-based model allows us to efficiently incorporate a discriminator in an adversarial fashion to improve the accuracy and "humanness" of the 3D output. We train and quantitatively validate our approach on SURREAL and on 3D-HUMANS, a new photorealistic dataset made of semi-synthetic in-house videos annotated with 3D ground truth surfaces.
LCR-Net++: Multi-person 2D and 3D Pose Detection in Natural Images
Oct 13, 2018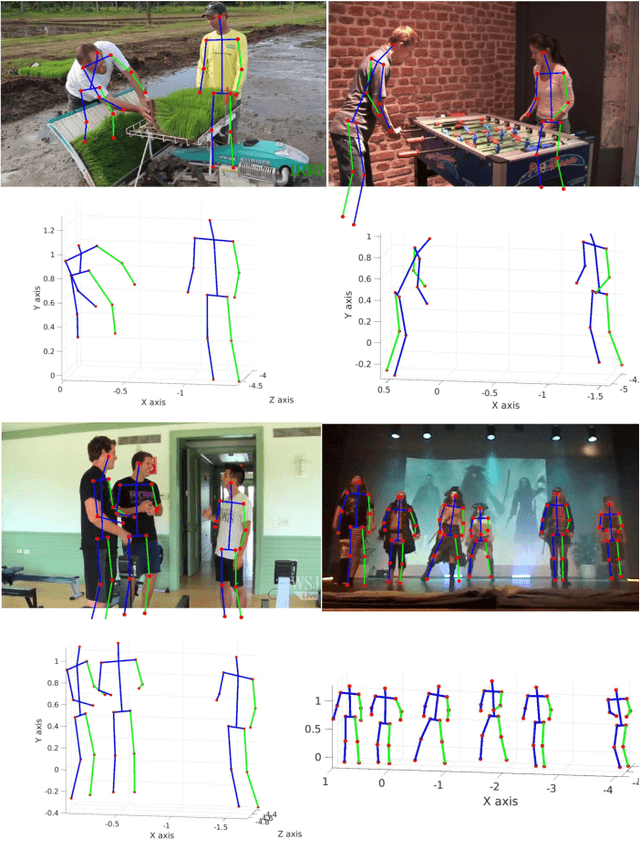
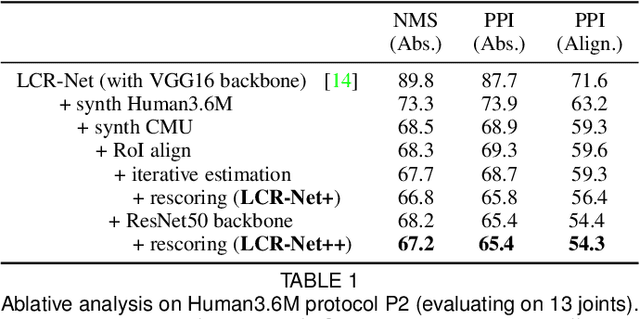
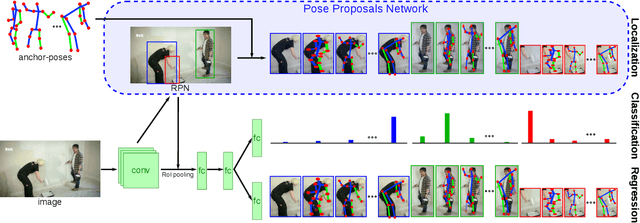
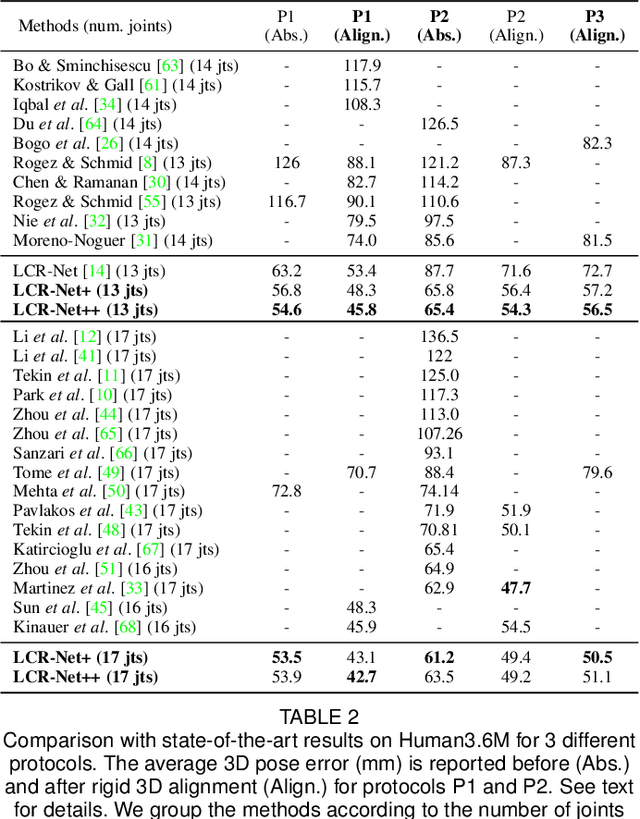
We propose an end-to-end architecture for joint 2D and 3D human pose estimation in natural images. Key to our approach is the generation and scoring of a number of pose proposals per image, which allows us to predict 2D and 3D poses of multiple people simultaneously. Hence, our approach does not require an approximate localization of the humans for initialization. Our Localization-Classification-Regression architecture, named LCR-Net, contains 3 main components: 1) the pose proposal generator that suggests candidate poses at different locations in the image; 2) a classifier that scores the different pose proposals; and 3) a regressor that refines pose proposals both in 2D and 3D. All three stages share the convolutional feature layers and are trained jointly. The final pose estimation is obtained by integrating over neighboring pose hypotheses, which is shown to improve over a standard non maximum suppression algorithm. Our method recovers full-body 2D and 3D poses, hallucinating plausible body parts when the persons are partially occluded or truncated by the image boundary. Our approach significantly outperforms the state of the art in 3D pose estimation on Human3.6M, a controlled environment. Moreover, it shows promising results on real images for both single and multi-person subsets of the MPII 2D pose benchmark and demonstrates satisfying 3D pose results even for multi-person images.
The Open World of Micro-Videos
Apr 01, 2016
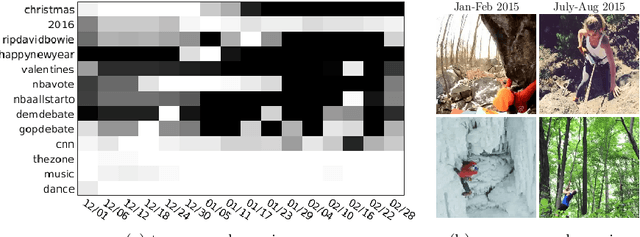
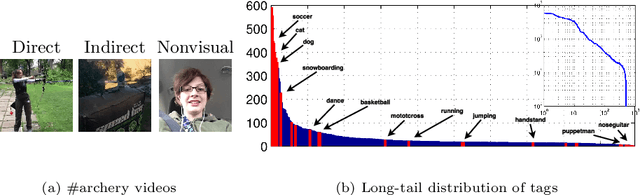
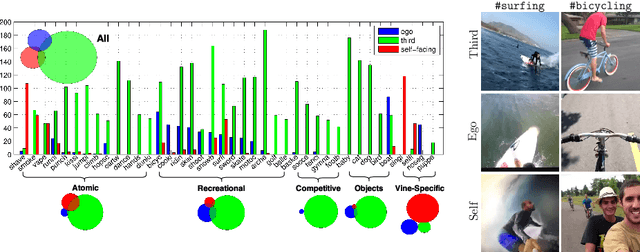
Micro-videos are six-second videos popular on social media networks with several unique properties. Firstly, because of the authoring process, they contain significantly more diversity and narrative structure than existing collections of video "snippets". Secondly, because they are often captured by hand-held mobile cameras, they contain specialized viewpoints including third-person, egocentric, and self-facing views seldom seen in traditional produced video. Thirdly, due to to their continuous production and publication on social networks, aggregate micro-video content contains interesting open-world dynamics that reflects the temporal evolution of tag topics. These aspects make micro-videos an appealing well of visual data for developing large-scale models for video understanding. We analyze a novel dataset of micro-videos labeled with 58 thousand tags. To analyze this data, we introduce viewpoint-specific and temporally-evolving models for video understanding, defined over state-of-the-art motion and deep visual features. We conclude that our dataset opens up new research opportunities for large-scale video analysis, novel viewpoints, and open-world dynamics.
Depth-based hand pose estimation: methods, data, and challenges
May 06, 2015
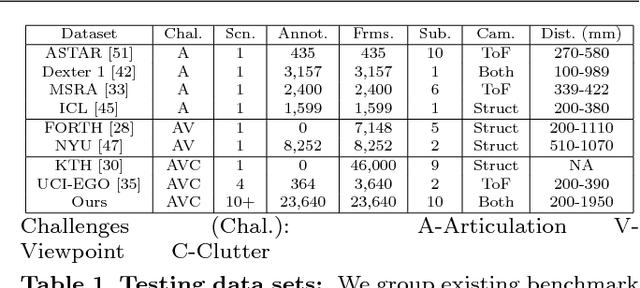


Hand pose estimation has matured rapidly in recent years. The introduction of commodity depth sensors and a multitude of practical applications have spurred new advances. We provide an extensive analysis of the state-of-the-art, focusing on hand pose estimation from a single depth frame. To do so, we have implemented a considerable number of systems, and will release all software and evaluation code. We summarize important conclusions here: (1) Pose estimation appears roughly solved for scenes with isolated hands. However, methods still struggle to analyze cluttered scenes where hands may be interacting with nearby objects and surfaces. To spur further progress we introduce a challenging new dataset with diverse, cluttered scenes. (2) Many methods evaluate themselves with disparate criteria, making comparisons difficult. We define a consistent evaluation criteria, rigorously motivated by human experiments. (3) We introduce a simple nearest-neighbor baseline that outperforms most existing systems. This implies that most systems do not generalize beyond their training sets. This also reinforces the under-appreciated point that training data is as important as the model itself. We conclude with directions for future progress.
3D Hand Pose Detection in Egocentric RGB-D Images
Nov 29, 2014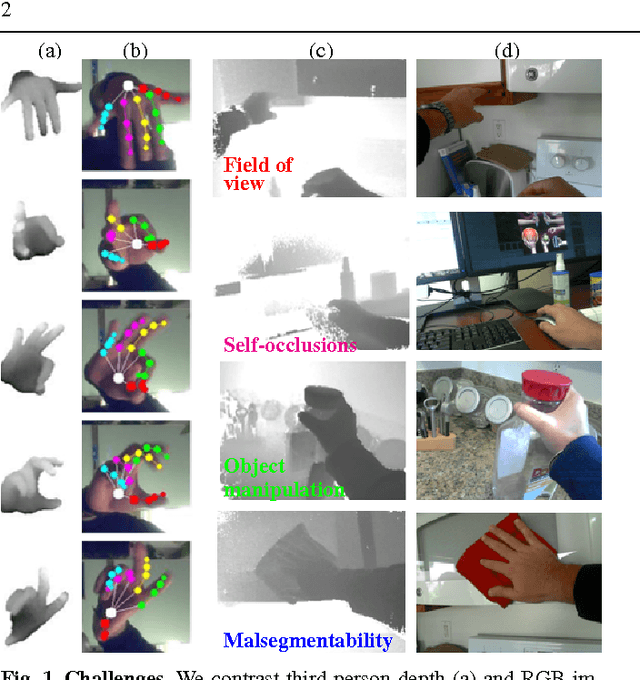
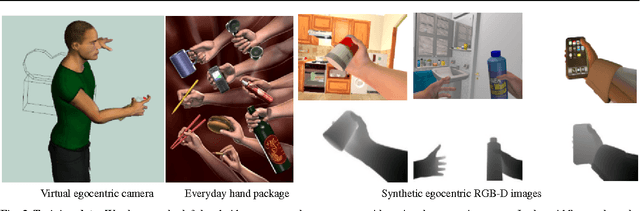
We focus on the task of everyday hand pose estimation from egocentric viewpoints. For this task, we show that depth sensors are particularly informative for extracting near-field interactions of the camera wearer with his/her environment. Despite the recent advances in full-body pose estimation using Kinect-like sensors, reliable monocular hand pose estimation in RGB-D images is still an unsolved problem. The problem is considerably exacerbated when analyzing hands performing daily activities from a first-person viewpoint, due to severe occlusions arising from object manipulations and a limited field-of-view. Our system addresses these difficulties by exploiting strong priors over viewpoint and pose in a discriminative tracking-by-detection framework. Our priors are operationalized through a photorealistic synthetic model of egocentric scenes, which is used to generate training data for learning depth-based pose classifiers. We evaluate our approach on an annotated dataset of real egocentric object manipulation scenes and compare to both commercial and academic approaches. Our method provides state-of-the-art performance for both hand detection and pose estimation in egocentric RGB-D images.
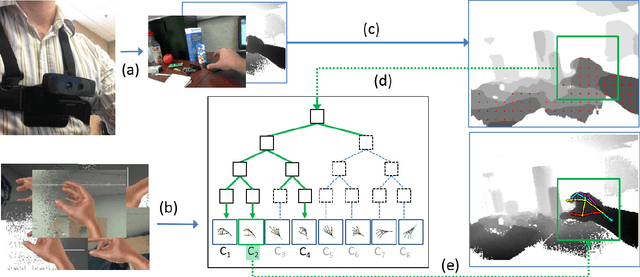
Egocentric Pose Recognition in Four Lines of Code
Nov 29, 2014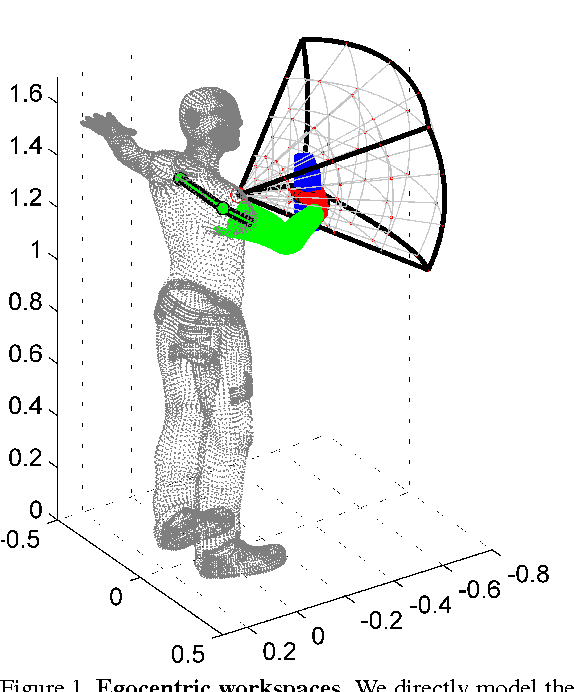
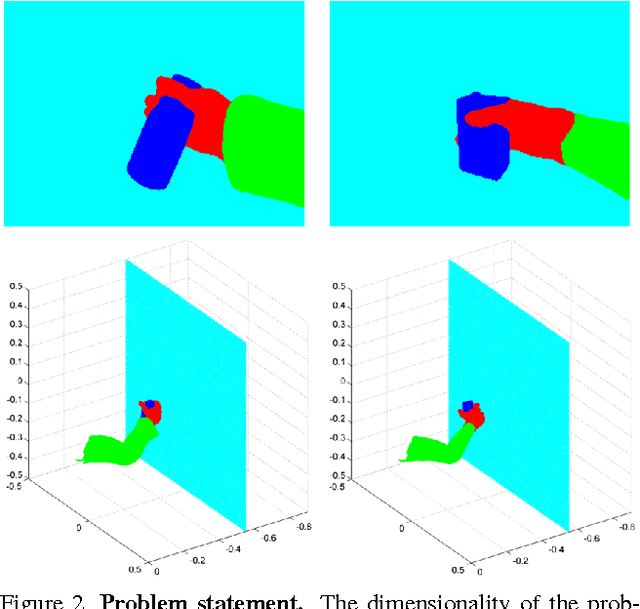

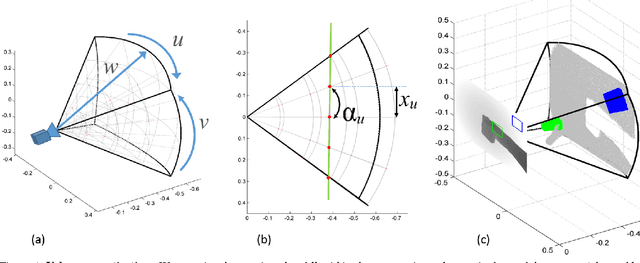
We tackle the problem of estimating the 3D pose of an individual's upper limbs (arms+hands) from a chest mounted depth-camera. Importantly, we consider pose estimation during everyday interactions with objects. Past work shows that strong pose+viewpoint priors and depth-based features are crucial for robust performance. In egocentric views, hands and arms are observable within a well defined volume in front of the camera. We call this volume an egocentric workspace. A notable property is that hand appearance correlates with workspace location. To exploit this correlation, we classify arm+hand configurations in a global egocentric coordinate frame, rather than a local scanning window. This greatly simplify the architecture and improves performance. We propose an efficient pipeline which 1) generates synthetic workspace exemplars for training using a virtual chest-mounted camera whose intrinsic parameters match our physical camera, 2) computes perspective-aware depth features on this entire volume and 3) recognizes discrete arm+hand pose classes through a sparse multi-class SVM. Our method provides state-of-the-art hand pose recognition performance from egocentric RGB-D images in real-time.