 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DB: A Framework for Debugging Computer Vision Models
Jun 07, 2021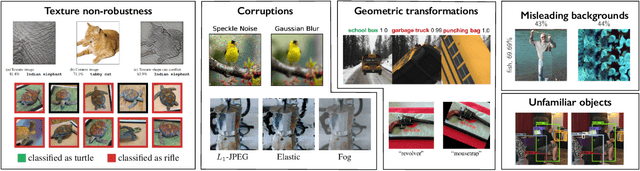
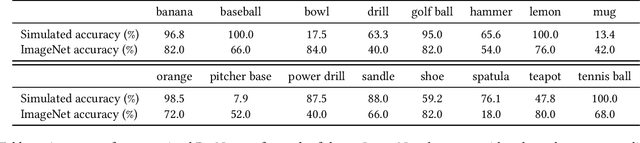

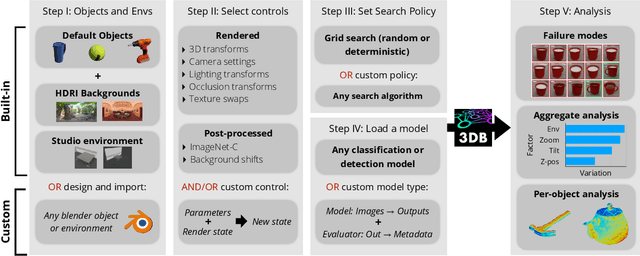
We introduce 3DB: an extendable, unified framework for testing and debugging vision models using photorealistic simulation. We demonstrate, through a wide range of use cases, that 3DB allows users to discover vulnerabilities in computer vision systems and gain insights into how models make decisions. 3DB captures and generalizes many robustness analyses from prior work, and enables one to study their interplay. Finally, we find that the insights generated by the system transfer to the physical world. We are releasing 3DB as a library (https://github.com/3db/3db) alongside a set of example analyses, guides, and documentation: https://3db.github.io/3db/ .
Tensor Programs IIb: Architectural Universality of Neural Tangent Kernel Training Dynamics
May 08, 2021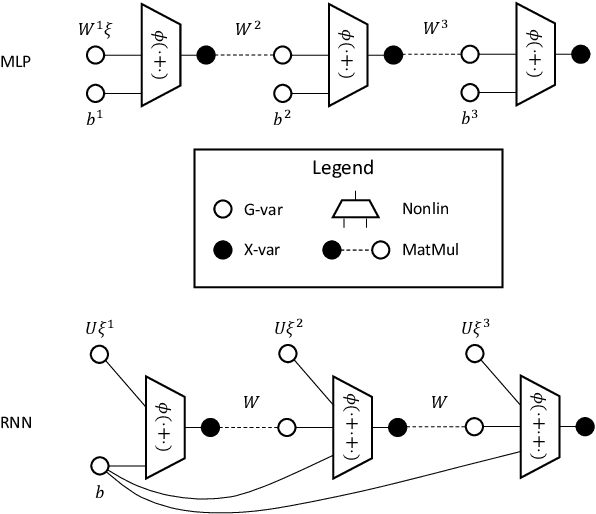
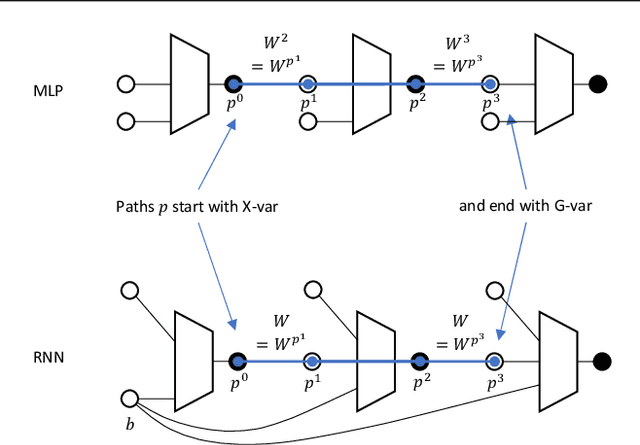
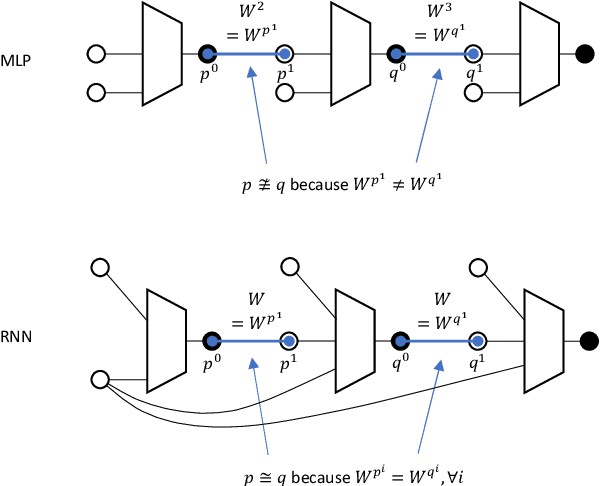
Yang (2020a) recently showed that the Neural Tangent Kernel (NTK) at initialization has an infinite-width limit for a large class of architectures including modern staples such as ResNet and Transformers. However, their analysis does not apply to training. Here, we show the same neural networks (in the so-called NTK parametrization) during training follow a kernel gradient descent dynamics in function space, where the kernel is the infinite-width NTK. This completes the proof of the *architectural universality* of NTK behavior. To achieve this result, we apply the Tensor Programs technique: Write the entire SGD dynamics inside a Tensor Program and analyze it via the Master Theorem. To facilitate this proof, we develop a graphical notation for Tensor Programs.
Feature Learning in Infinite-Width Neural Networks
Nov 30, 2020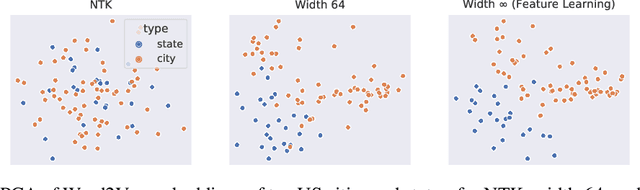


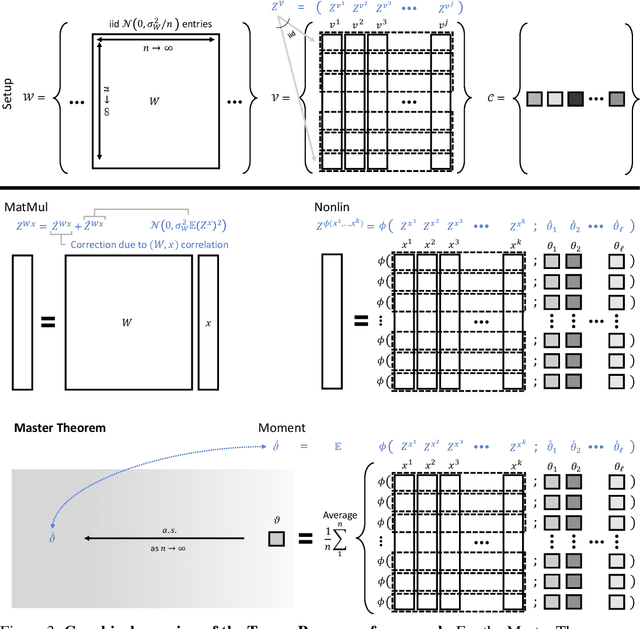
As its width tends to infinity, a deep neural network's behavior under gradient descent can become simplified and predictable (e.g. given by the Neural Tangent Kernel (NTK)), if it is parametrized appropriately (e.g. the NTK parametrization). However, we show that the standard and NTK parametrizations of a neural network do not admit infinite-width limits that can learn features, which is crucial for pretraining and transfer learning such as with BERT. We propose simple modifications to the standard parametrization to allow for feature learning in the limit. Using the *Tensor Programs* technique, we derive explicit formulas for such limits. On Word2Vec and few-shot learning on Omniglot via MAML, two canonical tasks that rely crucially on feature learning, we compute these limits exactly. We find that they outperform both NTK baselines and finite-width networks, with the latter approaching the infinite-width feature learning performance as width increases. More generally, we classify a natural space of neural network parametrizations that generalizes standard, NTK, and Mean Field parametrizations. We show 1) any parametrization in this space either admits feature learning or has an infinite-width training dynamics given by kernel gradient descent, but not both; 2) any such infinite-width limit can be computed using the Tensor Programs technique.
Tensor Programs III: Neural Matrix Laws
Sep 22, 2020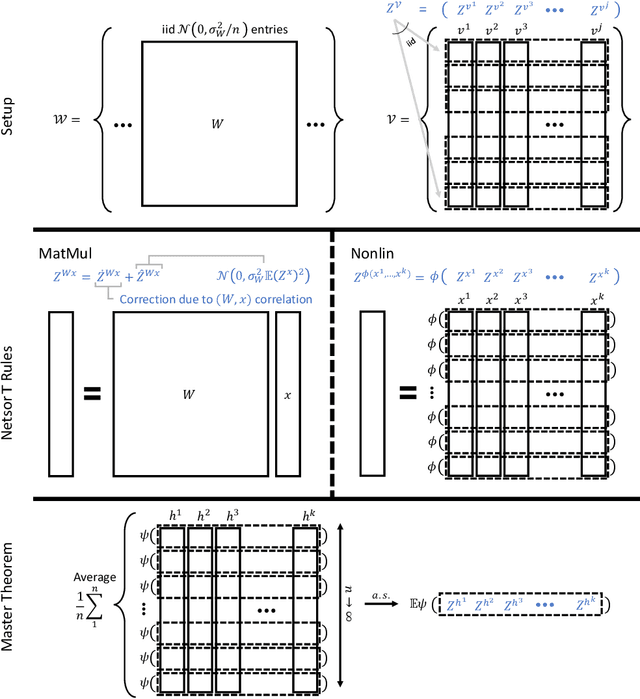
In a neural network (NN), \emph{weight matrices} linearly transform inputs into \emph{preactivations} that are then transformed nonlinearly into \emph{activations}. A typical NN interleaves multitudes of such linear and nonlinear transforms to express complex functions. Thus, the (pre-)activations depend on the weights in an intricate manner. We show that, surprisingly, (pre-)activations of a randomly initialized NN become \emph{independent} from the weights as the NN's widths tend to infinity, in the sense of \emph{asymptotic freeness} in random matrix theory. We call this the \emph{Free Independence Principle (FIP)}, which has these consequences: 1) It rigorously justifies the calculation of asymptotic Jacobian singular value distribution of an NN in Pennington et al. [36,37], essential for training ultra-deep NNs [48]. 2) It gives a new justification of \emph{gradient independence assumption} used for calculating the \emph{Neural Tangent Kernel} of a neural network. FIP and these results hold for any neural architecture. We show FIP by proving a Master Theorem for any Tensor Program, as introduced in Yang [50,51], generalizing the Master Theorems proved in those works. As warmup demonstrations of this new Master Theorem, we give new proofs of the semicircle and Marchenko-Pastur laws, which benchmarks our framework against these fundamental mathematical results.
Tensor Programs II: Neural Tangent Kernel for Any Architecture
Jun 28, 2020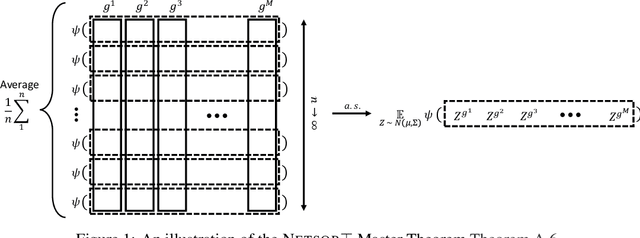
We prove that a randomly initialized neural network of *any architecture* has its Tangent Kernel (NTK) converge to a deterministic limit, as the network widths tend to infinity. We demonstrate how to calculate this limit. In prior literature, the heuristic study of neural network gradients often assumes every weight matrix used in forward propagation is independent from its transpose used in backpropagation (Schoenholz et al. 2017). This is known as the *gradient independence assumption (GIA)*. We identify a commonly satisfied condition, which we call *Simple GIA Check*, such that the NTK limit calculation based on GIA is correct. Conversely, when Simple GIA Check fails, we show GIA can result in wrong answers. Our material here presents the NTK results of Yang (2019a) in a friendly manner and showcases the *tensor programs* technique for understanding wide neural networks. We provide reference implementations of infinite-width NTKs of recurrent neural network, transformer, and batch normalization at https://github.com/thegregyang/NTK4A.
Improved Image Wasserstein Attacks and Defenses
Apr 26, 2020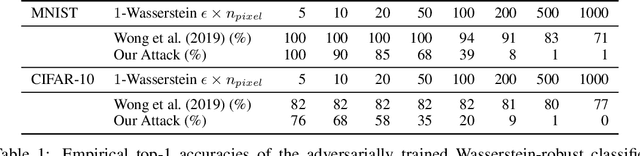
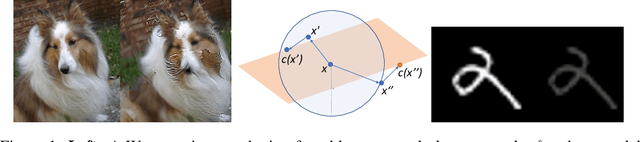

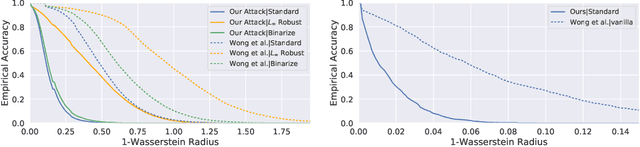
Robustness against image perturbations bounded by a $\ell_p$ ball have been well-studied in recent literature. Perturbations in the real-world, however, rarely exhibit the pixel independence that $\ell_p$ threat models assume. A recently proposed Wasserstein distance-bounded threat model is a promising alternative that limits the perturbation to pixel mass movements. We point out and rectify flaws in previous definition of the Wasserstein threat model and explore stronger attacks and defenses under our better-defined framework. Lastly, we discuss the inability of current Wasserstein-robust models in defending against perturbations seen in the real world. Our code and trained models are available at https://github.com/edwardjhu/improved_wasserstein .
Randomized Smoothing of All Shapes and Sizes
Mar 04, 2020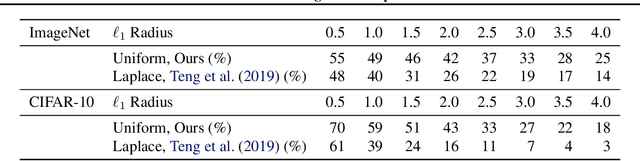

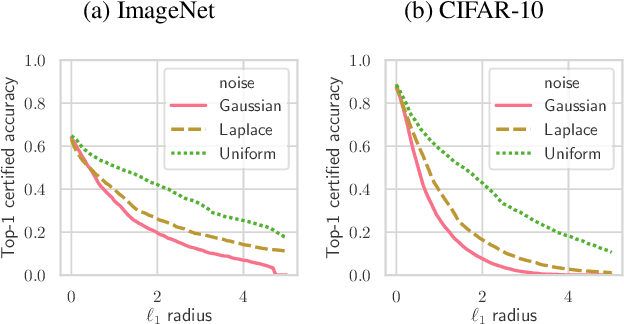
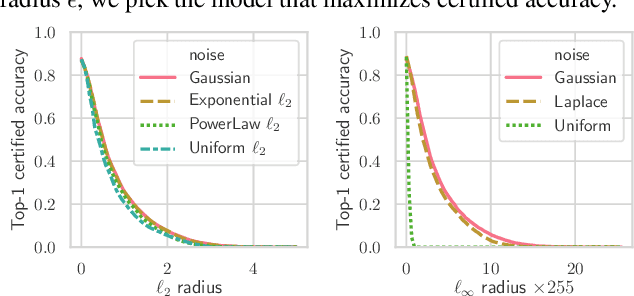
Randomized smoothing is a recently proposed defense against adversarial attacks that has achieved state-of-the-art provable robustness against $\ell_2$ perturbations. Soon after, a number of works devised new randomized smoothing schemes for other metrics, such as $\ell_1$ or $\ell_\infty$; however, for each geometry, substantial effort was needed to derive new robustness guarantees. This begs the question: can we find a general theory for randomized smoothing? In this work we propose a novel framework for devising and analyzing randomized smoothing schemes, and validate its effectiveness in practice. Our theoretical contributions are as follows: (1) We show that for an appropriate notion of "optimal", the optimal smoothing distributions for any "nice" norm have level sets given by the *Wulff Crystal* of that norm. (2) We propose two novel and complementary methods for deriving provably robust radii for any smoothing distribution. Finally, (3) we show fundamental limits to current randomized smoothing techniques via the theory of *Banach space cotypes*. By combining (1) and (2), we significantly improve the state-of-the-art certified accuracy in $\ell_1$ on standard datasets. On the other hand, using (3), we show that, without more information than label statistics under random input perturbations, randomized smoothing cannot achieve nontrivial certified accuracy against perturbations of $\ell_p$-norm $\Omega(\min(1, d^{\frac{1}{p}-\frac{1}{2}}))$, when the input dimension $d$ is large. We provide code in github.com/tonyduan/rs4a.
Black-box Smoothing: A Provable Defense for Pretrained Classifiers
Mar 04, 2020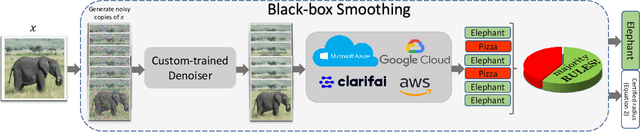


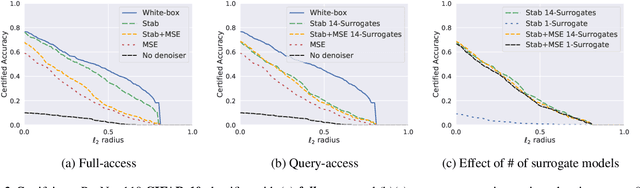
We present a method for provably defending any pretrained image classifier against $\ell_p$ adversarial attacks. By prepending a custom-trained denoiser to any off-the-shelf image classifier and using randomized smoothing, we effectively create a new classifier that is guaranteed to be $\ell_p$-robust to adversarial examples, without modifying the pretrained classifier. The approach applies both to the case where we have full access to the pretrained classifier as well as the case where we only have query access. We refer to this defense as black-box smoothing, and we demonstrate its effectiveness through extensive experimentation on ImageNet and CIFAR-10. Finally, we use our method to provably defend the Azure, Google, AWS, and ClarifAI image classification APIs. Our code replicating all the experiments in the paper can be found at https://github.com/microsoft/blackbox-smoothing .
Tensor Programs I: Wide Feedforward or Recurrent Neural Networks of Any Architecture are Gaussian Processes
Dec 07, 2019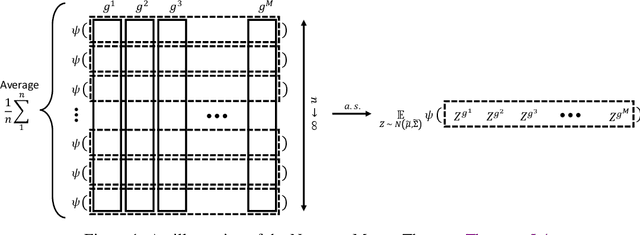
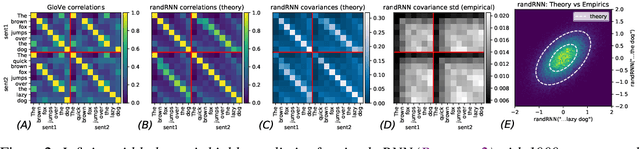
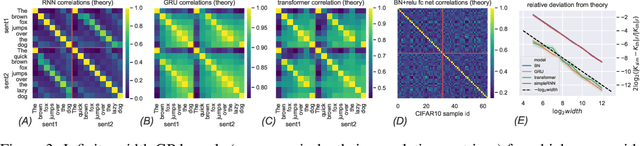
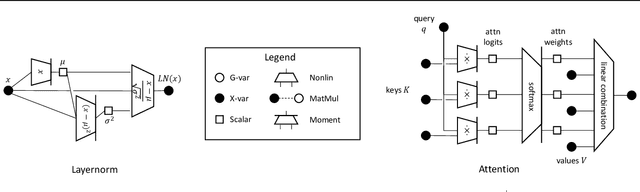
Wide neural networks with random weights and biases are Gaussian processes, as originally observed by Neal (1995) and more recently by Lee et al. (2018) and Matthews et al. (2018) for deep fully-connected networks, as well as by Novak et al. (2019) and Garriga-Alonso et al. (2019) for deep convolutional networks. We show that this Neural Network-Gaussian Process correspondence surprisingly extends to all modern feedforward or recurrent neural networks composed of multilayer perceptron, RNNs (e.g. LSTMs, GRUs), (nD or graph) convolution, pooling, skip connection, attention, batch normalization, and/or layer normalization. More generally, we introduce a language for expressing neural network computations, and our result encompasses all such expressible neural networks. This work serves as a tutorial on the *tensor programs* technique formulated in Yang (2019) and elucidates the Gaussian Process results obtained there. We provide open-source implementations of the Gaussian Process kernels of simple RNN, GRU, transformer, and batchnorm+ReLU network at github.com/thegregyang/GP4A.
Free resolutions of function classes via order complexes
Sep 05, 2019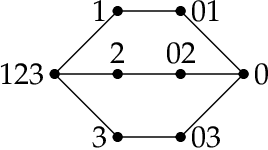
Function classes are collections of Boolean functions on a finite set, which are fundamental objects of study in theoretical computer science. We study algebraic properties of ideals associated to function classes previously defined by the third author. We consider the broad family of intersection-closed function classes, and describe cellular free resolutions of their ideals by order complexes of the associated posets. For function classes arising from matroids, polyhedral cell complexes, and more generally interval Cohen-Macaulay posets, we show that the multigraded Betti numbers are pure, and are given combinatorially by the M\"obius functions. We then apply our methods to derive bounds on the VC dimension of some important families of function classes in learning theory.