Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Acceleration and Feature Learning in Infinitely Wide Neural Networks with Bottlenecks
Paper and Code
Jul 02, 2021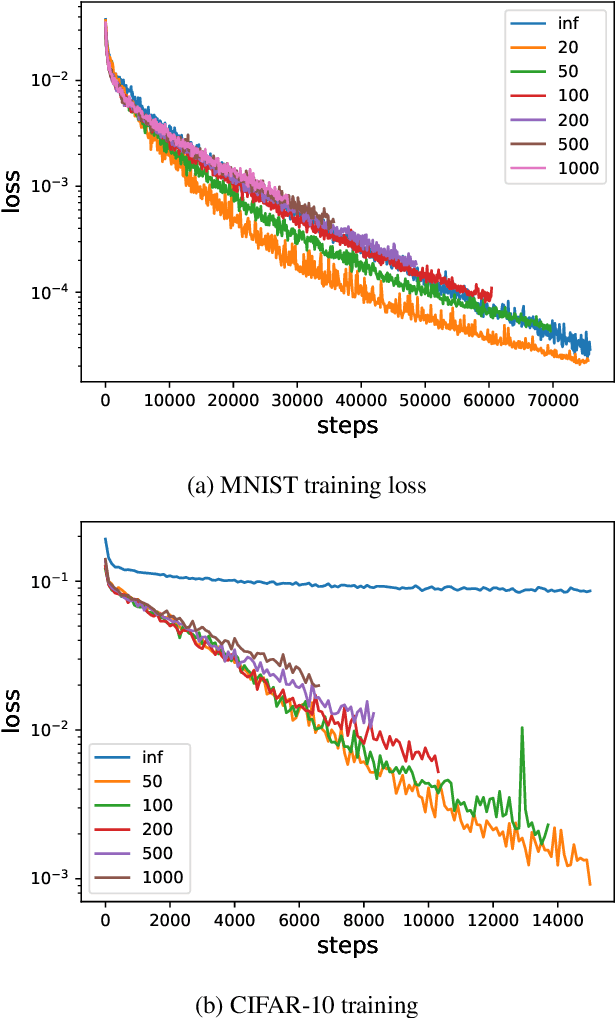
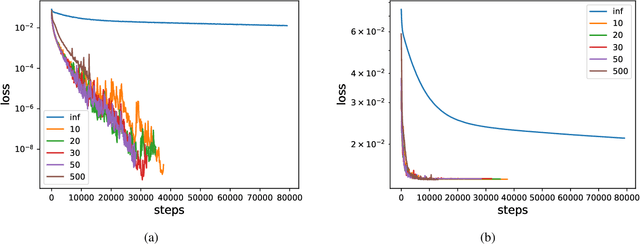
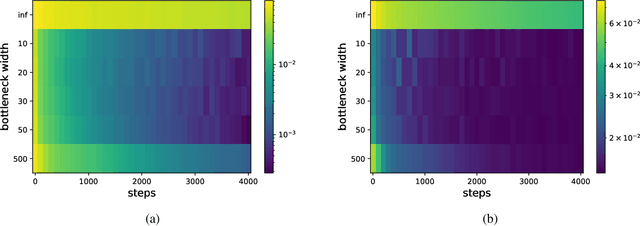
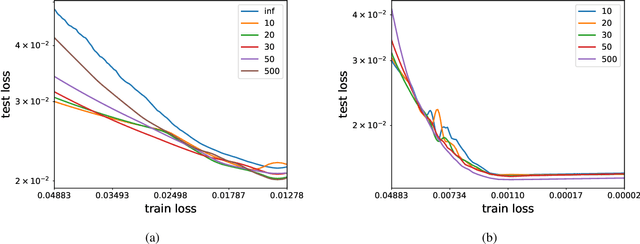
We analyze the learning dynamics of infinitely wide neural networks with a finite sized bottle-neck. Unlike the neural tangent kernel limit, a bottleneck in an otherwise infinite width network al-lows data dependent feature learning in its bottle-neck representation. We empirically show that a single bottleneck in infinite networks dramatically accelerates training when compared to purely in-finite networks, with an improved overall performance. We discuss the acceleration phenomena by drawing similarities to infinitely wide deep linear models, where the acceleration effect of a bottleneck can be understood theoretically.
View paper on