 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Smoothing of All Shapes and Sizes
Mar 04, 2020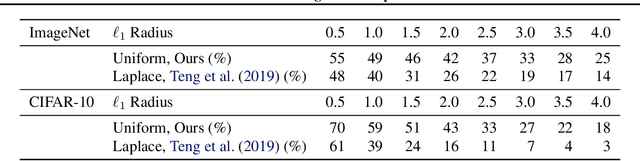

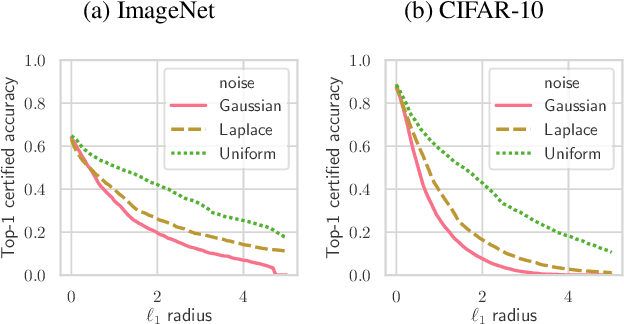
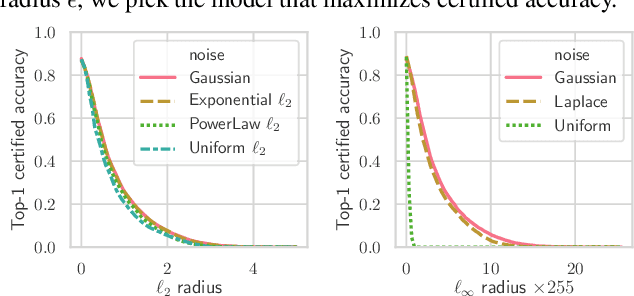
Randomized smoothing is a recently proposed defense against adversarial attacks that has achieved state-of-the-art provable robustness against $\ell_2$ perturbations. Soon after, a number of works devised new randomized smoothing schemes for other metrics, such as $\ell_1$ or $\ell_\infty$; however, for each geometry, substantial effort was needed to derive new robustness guarantees. This begs the question: can we find a general theory for randomized smoothing? In this work we propose a novel framework for devising and analyzing randomized smoothing schemes, and validate its effectiveness in practice. Our theoretical contributions are as follows: (1) We show that for an appropriate notion of "optimal", the optimal smoothing distributions for any "nice" norm have level sets given by the *Wulff Crystal* of that norm. (2) We propose two novel and complementary methods for deriving provably robust radii for any smoothing distribution. Finally, (3) we show fundamental limits to current randomized smoothing techniques via the theory of *Banach space cotypes*. By combining (1) and (2), we significantly improve the state-of-the-art certified accuracy in $\ell_1$ on standard datasets. On the other hand, using (3), we show that, without more information than label statistics under random input perturbations, randomized smoothing cannot achieve nontrivial certified accuracy against perturbations of $\ell_p$-norm $\Omega(\min(1, d^{\frac{1}{p}-\frac{1}{2}}))$, when the input dimension $d$ is large. We provide code in github.com/tonyduan/rs4a.
Missingness as Stability: Understanding the Structure of Missingness in Longitudinal EHR data and its Impact on Reinforcement Learning in Healthcare
Nov 16, 2019

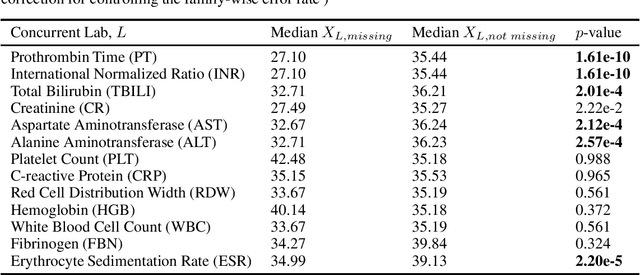
There is an emerging trend in the reinforcement learning for healthcare literature. In order to prepare longitudinal, irregularly sampled, clinical datasets for reinforcement learning algorithms, many researchers will resample the time series data to short, regular intervals and use last-observation-carried-forward (LOCF) imputation to fill in these gaps. Typically, they will not maintain any explicit information about which values were imputed. In this work, we (1) call attention to this practice and discuss its potential implications; (2) propose an alternative representation of the patient state that addresses some of these issues; and (3) demonstrate in a novel but representative clinical dataset that our alternative representation yields consistently better results for achieving optimal control, as measured by off-policy policy evaluation, compared to representations that do not incorporate missingness information.
Graph Embedding VAE: A Permutation Invariant Model of Graph Structure
Oct 17, 2019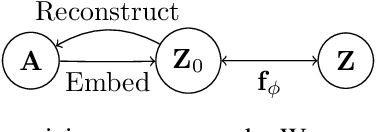
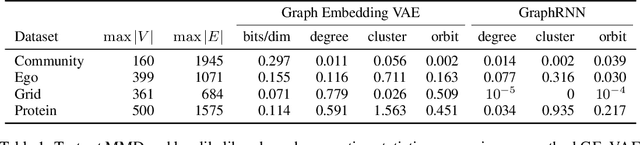
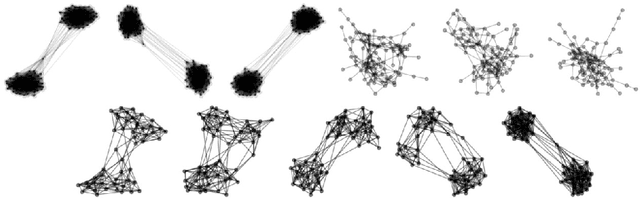
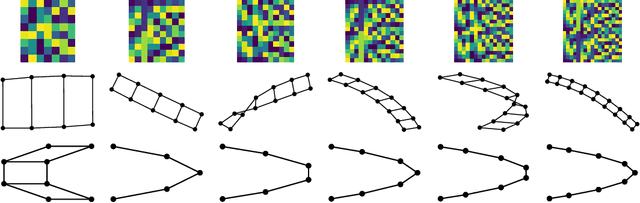
Generative models of graph structure have applications in biology and social sciences. The state of the art is GraphRNN, which decomposes the graph generation process into a series of sequential steps. While effective for modest sizes, it loses its permutation invariance for larger graphs. Instead, we present a permutation invariant latent-variable generative model relying on graph embeddings to encode structure. Using tools from the random graph literature, our model is highly scalable to large graphs with likelihood evaluation and generation in $O(|V | + |E|)$.
NGBoost: Natural Gradient Boosting for Probabilistic Prediction
Oct 09, 2019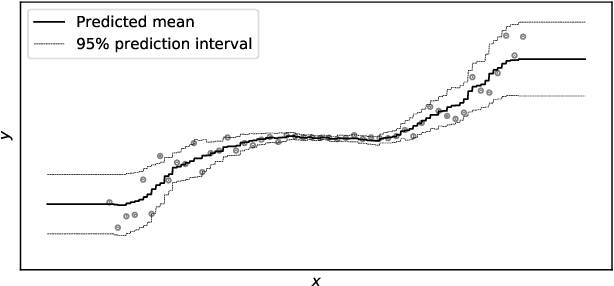
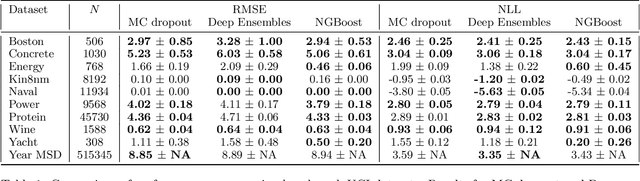

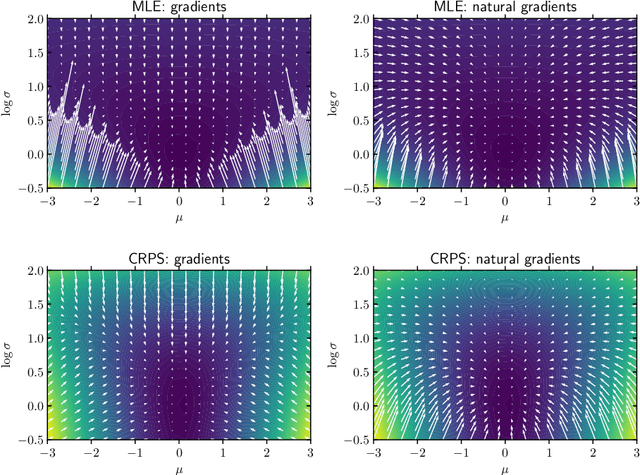
We present Natural Gradient Boosting (NGBoost), an algorithm which brings probabilistic prediction capability to gradient boosting in a generic way. Predictive uncertainty estimation is crucial in many applications such as healthcare and weather forecasting. Probabilistic prediction, which is the approach where the model outputs a full probability distribution over the entire outcome space, is a natural way to quantify those uncertainties. Gradient Boosting Machines have been widely successful in prediction tasks on structured input data, but a simple boosting solution for probabilistic prediction of real valued outputs is yet to be made. NGBoost is a gradient boosting approach which uses the \emph{Natural Gradient} to address technical challenges that makes generic probabilistic prediction hard with existing gradient boosting methods. Our approach is modular with respect to the choice of base learner, probability distribution, and scoring rule. We show empirically on several regression datasets that NGBoost provides competitive predictive performance of both uncertainty estimates and traditional metrics.
Counterfactual Reasoning for Fair Clinical Risk Prediction
Jul 14, 2019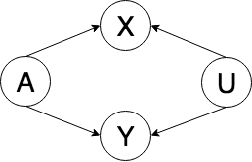
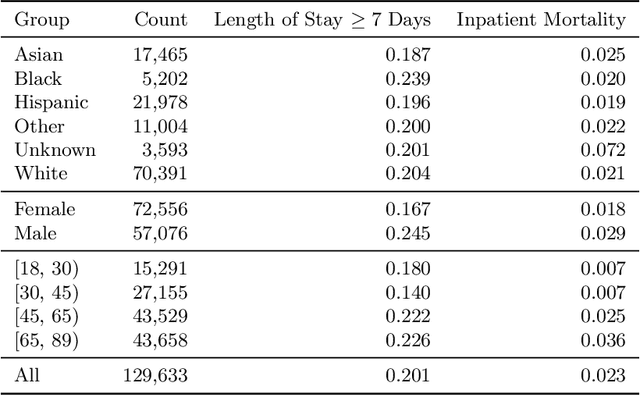
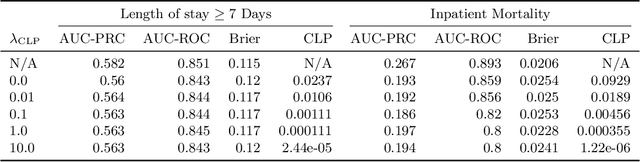
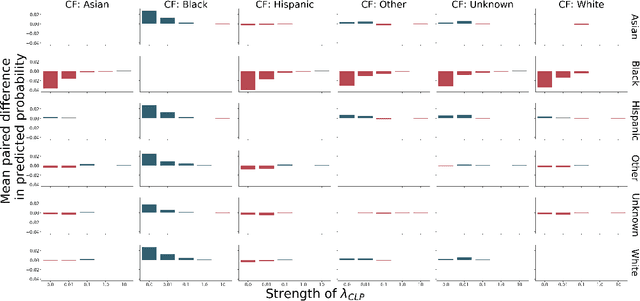
The use of machine learning systems to support decision making in healthcare raises questions as to what extent these systems may introduce or exacerbate disparities in care for historically underrepresented and mistreated groups, due to biases implicitly embedded in observational data in electronic health records. To address this problem in the context of clinical risk prediction models, we develop an augmented counterfactual fairness criteria to extend the group fairness criteria of equalized odds to an individual level. We do so by requiring that the same prediction be made for a patient, and a counterfactual patient resulting from changing a sensitive attribute, if the factual and counterfactual outcomes do not differ. We investigate the extent to which the augmented counterfactual fairness criteria may be applied to develop fair models for prolonged inpatient length of stay and mortality with observational electronic health records data. As the fairness criteria is ill-defined without knowledge of the data generating process, we use a variational autoencoder to perform counterfactual inference in the context of an assumed causal graph. While our technique provides a means to trade off maintenance of fairness with reduction in predictive performance in the context of a learned generative model, further work is needed to assess the generality of this approach.
Countdown Regression: Sharp and Calibrated Survival Predictions
Jun 21, 2018
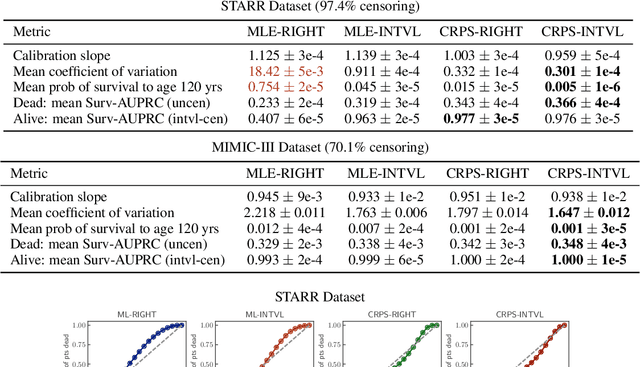
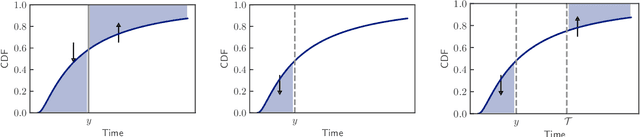
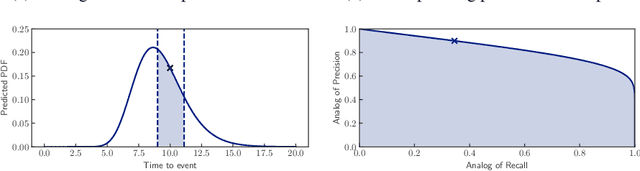
Personalized probabilistic forecasts of time to event (such as mortality) can be crucial in decision making, especially in the clinical setting. Inspired by ideas from the meteorology literature, we approach this problem through the paradigm of maximizing sharpness of prediction distributions, subject to calibration. In regression problems, it has been shown that optimizing the continuous ranked probability score (CRPS) instead of maximum likelihood leads to sharper prediction distributions while maintaining calibration. We introduce the Survival-CRPS, a generalization of the CRPS to the time to event setting, and present right-censored and interval-censored variants. To holistically evaluate the quality of predicted distributions over time to event, we present the Survival-AUPRC evaluation metric, an analog to area under the precision-recall curve. We apply these ideas by building a recurrent neural network for mortality prediction, using an Electronic Health Record dataset covering millions of patients. We demonstrate significant benefits in models trained by the Survival-CRPS objective instead of maximum likelihood.
MURA: Large Dataset for Abnormality Detection in Musculoskeletal Radiographs
May 22, 2018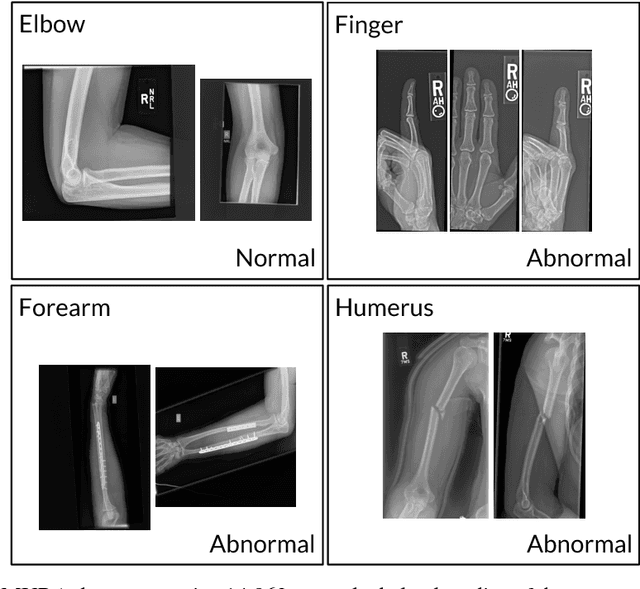
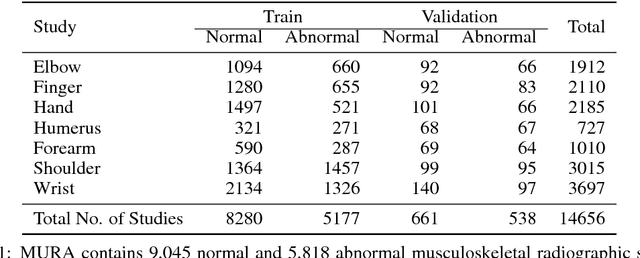

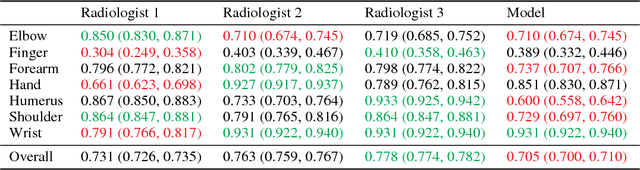
We introduce MURA, a large dataset of musculoskeletal radiographs containing 40,561 images from 14,863 studies, where each study is manually labeled by radiologists as either normal or abnormal. To evaluate models robustly and to get an estimate of radiologist performance, we collect additional labels from six board-certified Stanford radiologists on the test set, consisting of 207 musculoskeletal studies. On this test set, the majority vote of a group of three radiologists serves as gold standard. We train a 169-layer DenseNet baseline model to detect and localize abnormalities. Our model achieves an AUROC of 0.929, with an operating point of 0.815 sensitivity and 0.887 specificity. We compare our model and radiologists on the Cohen's kappa statistic, which expresses the agreement of our model and of each radiologist with the gold standard. Model performance is comparable to the best radiologist performance in detecting abnormalities on finger and wrist studies. However, model performance is lower than best radiologist performance in detecting abnormalities on elbow, forearm, hand, humerus, and shoulder studies. We believe that the task is a good challenge for future research. To encourage advances, we have made our dataset freely available at https://stanfordmlgroup.github.io/competitions/mura .
CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning
Dec 25, 2017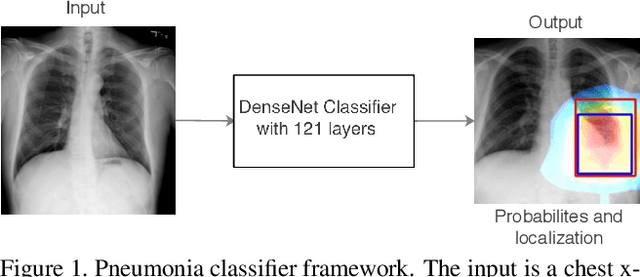

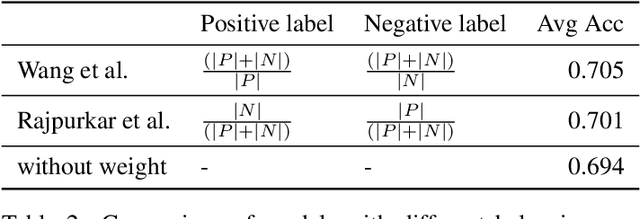
We develop an algorithm that can detect pneumonia from chest X-rays at a level exceeding practicing radiologists. Our algorithm, CheXNet, is a 121-layer convolutional neural network trained on ChestX-ray14, currently the largest publicly available chest X-ray dataset, containing over 100,000 frontal-view X-ray images with 14 diseases. Four practicing academic radiologists annotate a test set, on which we compare the performance of CheXNet to that of radiologists. We find that CheXNet exceeds average radiologist performance on the F1 metric. We extend CheXNet to detect all 14 diseases in ChestX-ray14 and achieve state of the art results on all 14 diseases.