 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Manipulate Amorphous Materials
Mar 03, 2021

We present a method of training character manipulation of amorphous materials such as those often used in cooking. Common examples of amorphous materials include granular materials (salt, uncooked rice), fluids (honey), and visco-plastic materials (sticky rice, softened butter). A typical task is to spread a given material out across a flat surface using a tool such as a scraper or knife. We use reinforcement learning to train our controllers to manipulate materials in various ways. The training is performed in a physics simulator that uses position-based dynamics of particles to simulate the materials to be manipulated. The neural network control policy is given observations of the material (e.g. a low-resolution density map), and the policy outputs actions such as rotating and translating the knife. We demonstrate policies that have been successfully trained to carry out the following tasks: spreading, gathering, and flipping. We produce a final animation by using inverse kinematics to guide a character's arm and hand to match the motion of the manipulation tool such as a knife or a frying pan.
Protective Policy Transfer
Dec 11, 2020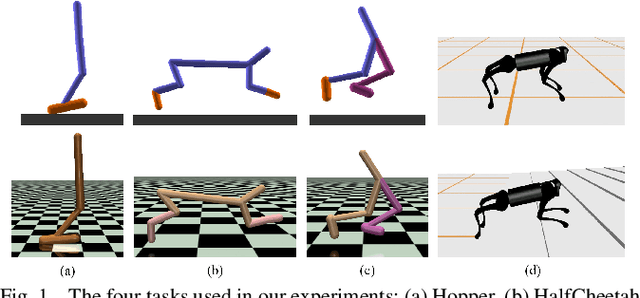
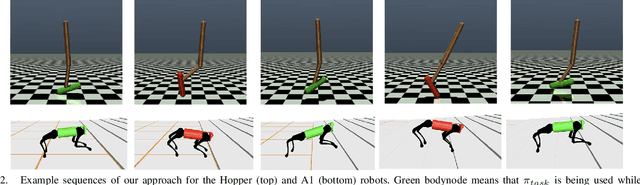

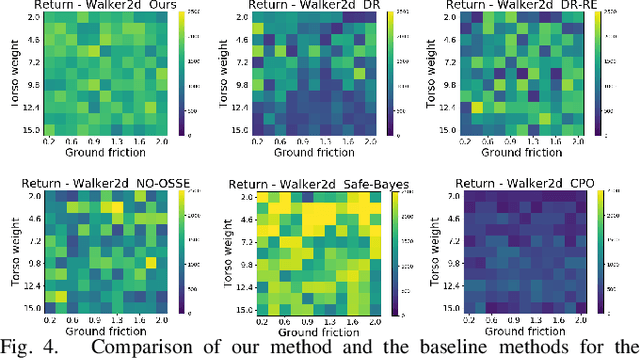
Being able to transfer existing skills to new situations is a key capability when training robots to operate in unpredictable real-world environments. A successful transfer algorithm should not only minimize the number of samples that the robot needs to collect in the new environment, but also prevent the robot from damaging itself or the surrounding environment during the transfer process. In this work, we introduce a policy transfer algorithm for adapting robot motor skills to novel scenarios while minimizing serious failures. Our algorithm trains two control policies in the training environment: a task policy that is optimized to complete the task of interest, and a protective policy that is dedicated to keep the robot from unsafe events (e.g. falling to the ground). To decide which policy to use during execution, we learn a safety estimator model in the training environment that estimates a continuous safety level of the robot. When used with a set of thresholds, the safety estimator becomes a classifier for switching between the protective policy and the task policy. We evaluate our approach on four simulated robot locomotion problems and a 2D navigation problem and show that our method can achieve successful transfer to notably different environments while taking the robot's safety into consideration.
Bodies at Rest: 3D Human Pose and Shape Estimation from a Pressure Image using Synthetic Data
Apr 02, 2020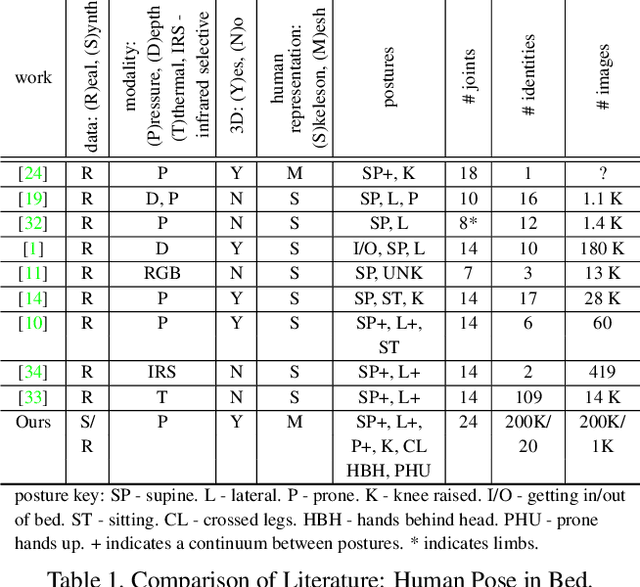

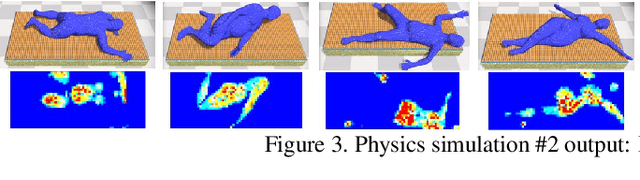
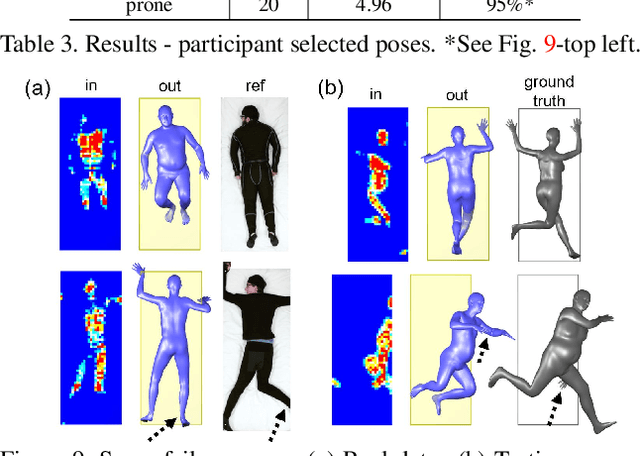
People spend a substantial part of their lives at rest in bed. 3D human pose and shape estimation for this activity would have numerous beneficial applications, yet line-of-sight perception is complicated by occlusion from bedding. Pressure sensing mats are a promising alternative, but training data is challenging to collect at scale. We describe a physics-based method that simulates human bodies at rest in a bed with a pressure sensing mat, and present PressurePose, a synthetic dataset with 206K pressure images with 3D human poses and shapes. We also present PressureNet, a deep learning model that estimates human pose and shape given a pressure image and gender. PressureNet incorporates a pressure map reconstruction (PMR) network that models pressure image generation to promote consistency between estimated 3D body models and pressure image input. In our evaluations, PressureNet performed well with real data from participants in diverse poses, even though it had only been trained with synthetic data. When we ablated the PMR network, performance dropped substantially.
Modeling Collaboration for Robot-assisted Dressing Tasks
Sep 14, 2019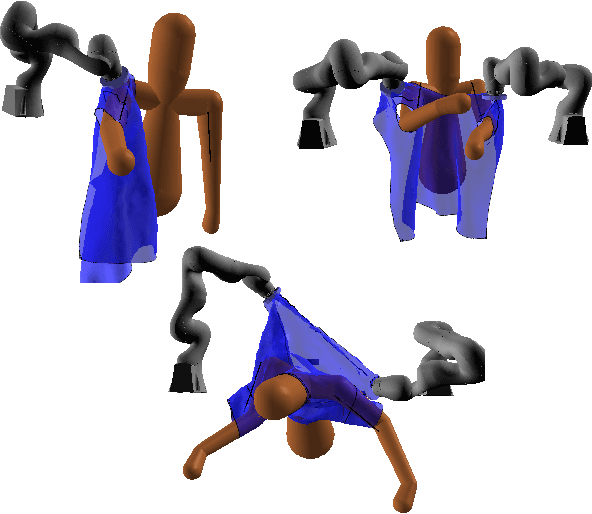
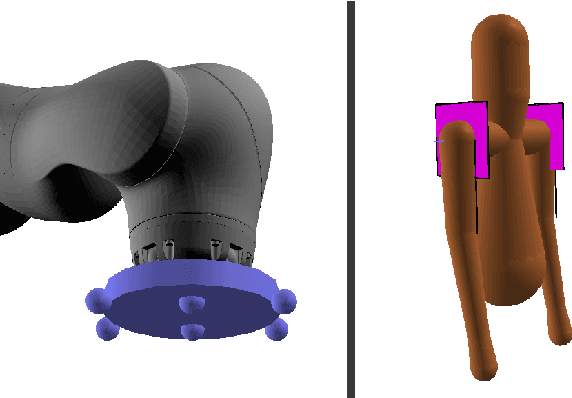
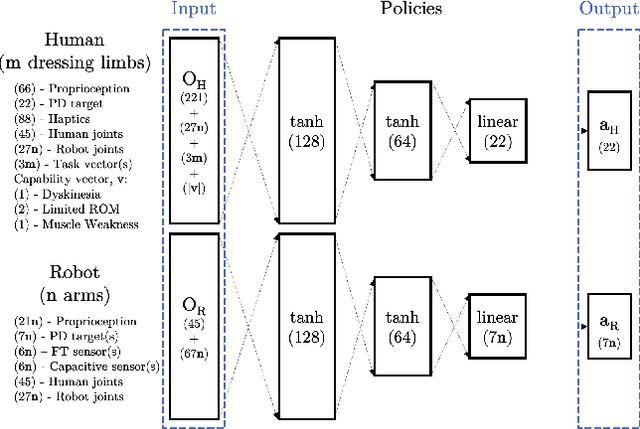
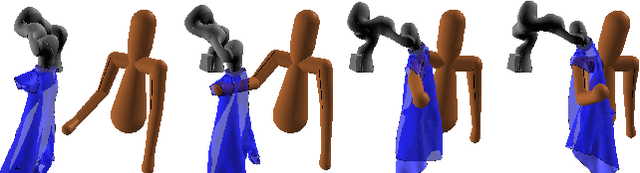
We investigated the application of haptic aware feedback control and deep reinforcement learning to robot assisted dressing in simulation. We did so by modeling both human and robot control policies as separate neural networks and training them both via TRPO. We show that co-optimization, training separate human and robot control policies simultaneously, can be a valid approach to finding successful strategies for human/robot cooperation on assisted dressing tasks. Typical tasks are putting on one or both sleeves of a hospital gown or pulling on a T-shirt. We also present a method for modeling human dressing behavior under variations in capability including: unilateral muscle weakness, Dyskinesia, and limited range of motion. Using this method and behavior model, we demonstrate discovery of successful strategies for a robot to assist humans with a variety of capability limitations.
Learning Novel Policies For Tasks
May 13, 2019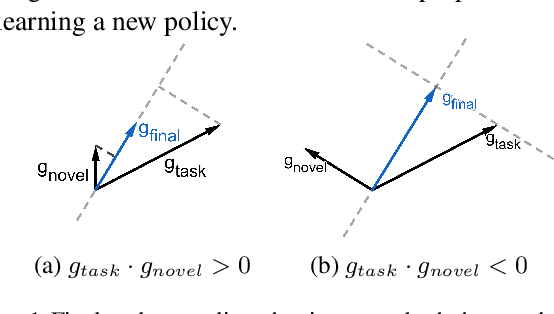

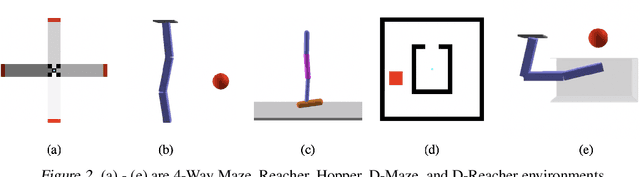
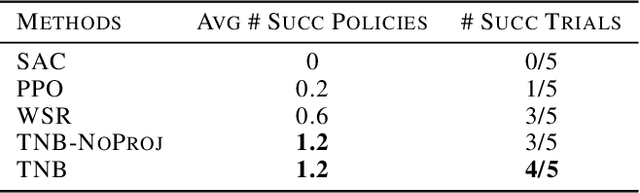
In this work, we present a reinforcement learning algorithm that can find a variety of policies (novel policies) for a task that is given by a task reward function. Our method does this by creating a second reward function that recognizes previously seen state sequences and rewards those by novelty, which is measured using autoencoders that have been trained on state sequences from previously discovered policies. We present a two-objective update technique for policy gradient algorithms in which each update of the policy is a compromise between improving the task reward and improving the novelty reward. Using this method, we end up with a collection of policies that solves a given task as well as carrying out action sequences that are distinct from one another. We demonstrate this method on maze navigation tasks, a reaching task for a simulated robot arm, and a locomotion task for a hopper. We also demonstrate the effectiveness of our approach on deceptive tasks in which policy gradient methods often get stuck.
Multidimensional Capacitive Sensing for Robot-Assisted Dressing and Bathing
Apr 03, 2019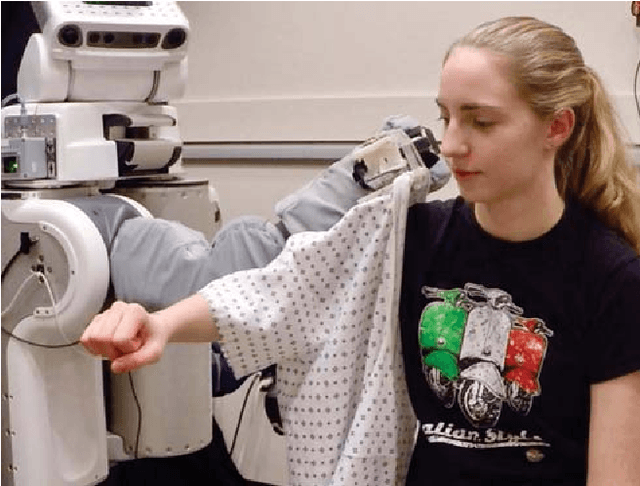
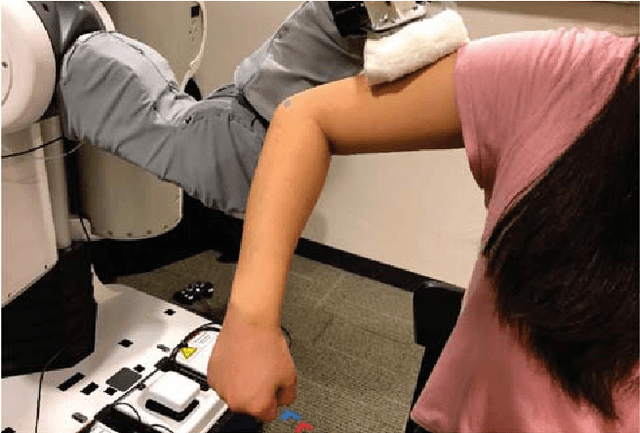

Robotic assistance presents an opportunity to benefit the lives of many adults with physical disabilities, yet accurately sensing the human body and tracking human motion remain difficult for robots. We present a multidimensional capacitive sensing technique capable of sensing the local pose of a human limb in real time. This sensing approach is unaffected by many visual occlusions that obscure sight of a person's body during robotic assistance, while also allowing a robot to sense the human body through some conductive materials, such as wet cloth. Given measurements from this capacitive sensor, we train a neural network model to estimate the relative vertical and lateral position to the closest point on a person's limb, as well as the pitch and yaw orientation between a robot's end effector and the central axis of the limb. We demonstrate that a PR2 robot can use this sensing approach to assist with two activities of daily living-dressing and bathing. Our robot pulled the sleeve of a hospital gown onto participants' right arms, while using capacitive sensing with feedback control to track human motion. When assisting with bathing, the robot used capacitive sensing with a soft wet washcloth to follow the contours of a participant's limbs and clean the surface of the body. Overall, we find that multidimensional capacitive sensing presents a promising approach for robots to sense and track the human body during assistive tasks that require physical human-robot interaction.
Sim-to-Real Transfer for Biped Locomotion
Mar 04, 2019
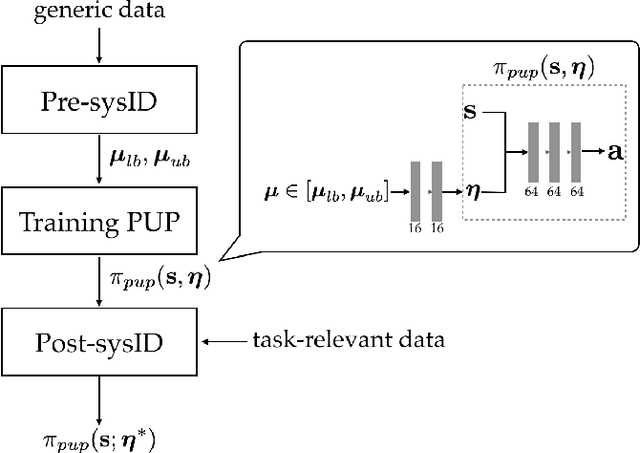

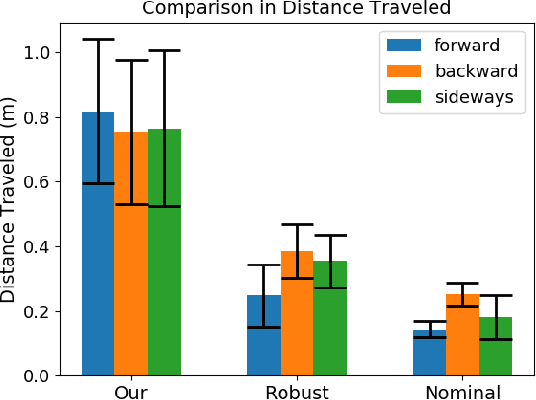
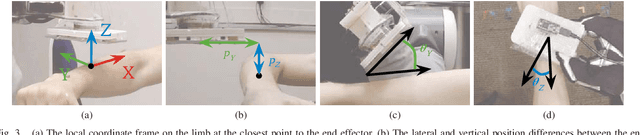
We present a new approach for transfer of dynamic robot control policies such as biped locomotion from simulation to real hardware. Key to our approach is to perform system identification of the model parameters {\mu} of the hardware (e.g. friction, center-of-mass) in two distinct stages, before policy learning (pre-sysID) and after policy learning (post-sysID). Pre-sysID begins by collecting trajectories from the physical hardware based on a set of generic motion sequences. Because the trajectories may not be related to the task of interest, presysID does not attempt to accurately identify the true value of {\mu}, but only to approximate the range of {\mu} to guide the policy learning. Next, a Projected Universal Policy (PUP) is created by simultaneously training a network that projects {\mu} to a low-dimensional latent variable {\eta} and a family of policies that are conditioned on {\eta}. The second round of system identification (post-sysID) is then carried out by deploying the PUP on the robot hardware using task-relevant trajectories. We use Bayesian Optimization to determine the values for {\eta} that optimizes the performance of PUP on the real hardware. We have used this approach to create three successful biped locomotion controllers (walk forward, walk backwards, walk sideways) on the Darwin OP2 robot.
Policy Transfer with Strategy Optimization
Dec 04, 2018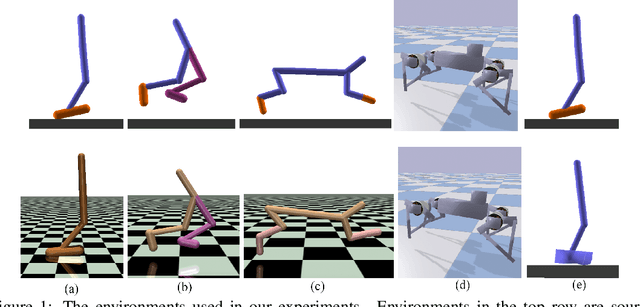

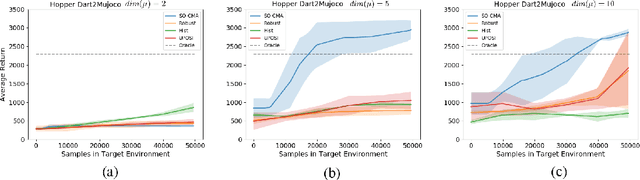
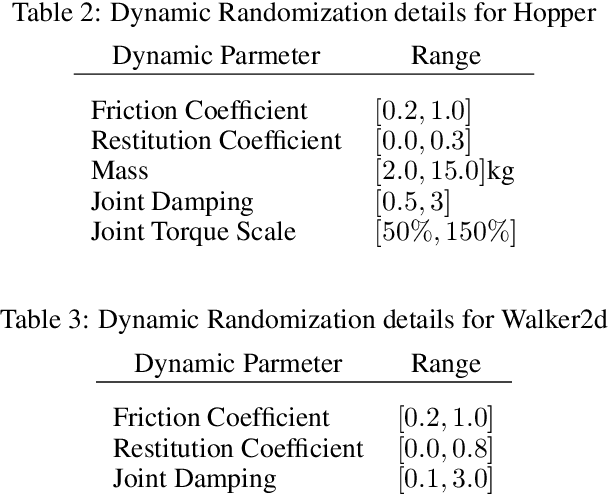
Computer simulation provides an automatic and safe way for training robotic control policies to achieve complex tasks such as locomotion. However, a policy trained in simulation usually does not transfer directly to the real hardware due to the differences between the two environments. Transfer learning using domain randomization is a promising approach, but it usually assumes that the target environment is close to the distribution of the training environments, thus relying heavily on accurate system identification. In this paper, we present a different approach that leverages domain randomization for transferring control policies to unknown environments. The key idea that, instead of learning a single policy in the simulation, we simultaneously learn a family of policies that exhibit different behaviors. When tested in the target environment, we directly search for the best policy in the family based on the task performance, without the need to identify the dynamic parameters. We evaluate our method on five simulated robotic control problems with different discrepancies in the training and testing environment and demonstrate that our method can overcome larger modeling errors compared to training a robust policy or an adaptive policy.
Learning Symmetric and Low-energy Locomotion
May 12, 2018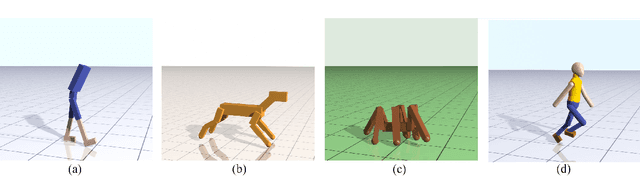
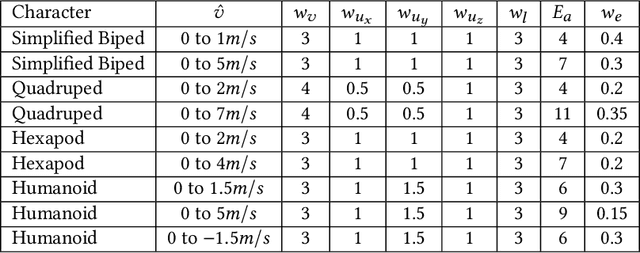
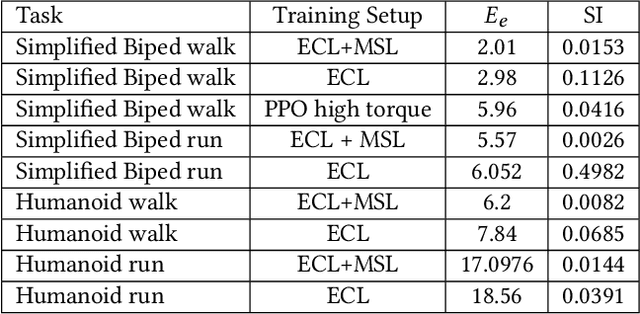
Learning locomotion skills is a challenging problem. To generate realistic and smooth locomotion, existing methods use motion capture, finite state machines or morphology-specific knowledge to guide the motion generation algorithms. Deep reinforcement learning (DRL) is a promising approach for the automatic creation of locomotion control. Indeed, a standard benchmark for DRL is to automatically create a running controller for a biped character from a simple reward function. Although several different DRL algorithms can successfully create a running controller, the resulting motions usually look nothing like a real runner. This paper takes a minimalist learning approach to the locomotion problem, without the use of motion examples, finite state machines, or morphology-specific knowledge. We introduce two modifications to the DRL approach that, when used together, produce locomotion behaviors that are symmetric, low-energy, and much closer to that of a real person. First, we introduce a new term to the loss function (not the reward function) that encourages symmetric actions. Second, we introduce a new curriculum learning method that provides modulated physical assistance to help the character with left/right balance and forward movement. The algorithm automatically computes appropriate assistance to the character and gradually relaxes this assistance, so that eventually the character learns to move entirely without help. Because our method does not make use of motion capture data, it can be applied to a variety of character morphologies. We demonstrate locomotion controllers for the lower half of a biped, a full humanoid, a quadruped, and a hexapod. Our results show that learned policies are able to produce symmetric, low-energy gaits. In addition, speed-appropriate gait patterns emerge without any guidance from motion examples or contact planning.
* Accepted to SIGGRAPH 2018. Supplementary video: https://www.youtube.com/watch?v=zkH90rU-uew&feature=youtu.be
Multi-task Learning with Gradient Guided Policy Specialization
Mar 02, 2018

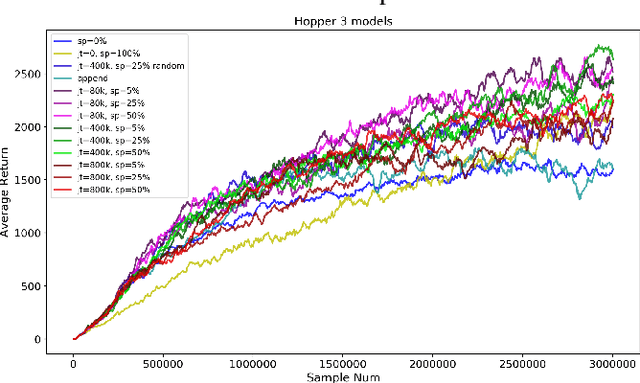
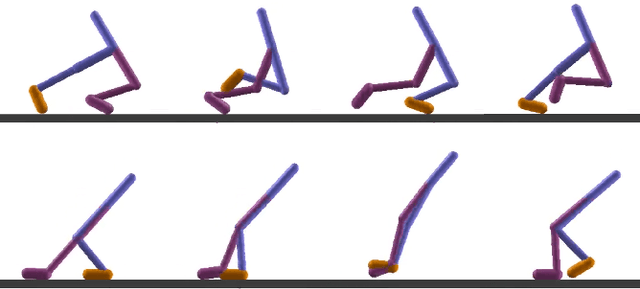
We present a method for efficient learning of control policies for multiple related robotic motor skills. Our approach consists of two stages, joint training and specialization training. During the joint training stage, a neural network policy is trained with minimal information to disambiguate the motor skills. This forces the policy to learn a common representation of the different tasks. Then, during the specialization training stage we selectively split the weights of the policy based on a per-weight metric that measures the disagreement among the multiple tasks. By splitting part of the control policy, it can be further trained to specialize to each task. To update the control policy during learning, we use Trust Region Policy Optimization with Generalized Advantage Function (TRPOGAE). We propose a modification to the gradient update stage of TRPO to better accommodate multi-task learning scenarios. We evaluate our approach on three continuous motor skill learning problems in simulation: 1) a locomotion task where three single legged robots with considerable difference in shape and size are trained to hop forward, 2) a manipulation task where three robot manipulators with different sizes and joint types are trained to reach different locations in 3D space, and 3) locomotion of a two-legged robot, whose range of motion of one leg is constrained in different ways. We compare our training method to three baselines. The first baseline uses only joint training for the policy, the second trains independent policies for each task, and the last randomly selects weights to split. We show that our approach learns more efficiently than each of the baseline methods.