 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Segmentation by Inpainting Error Maximization
Dec 14, 2020
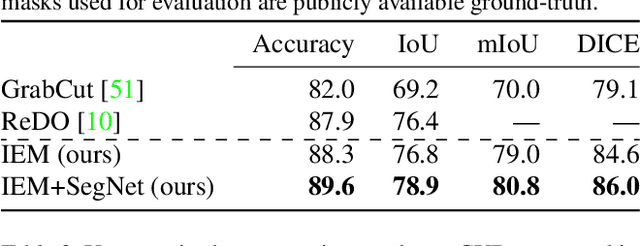
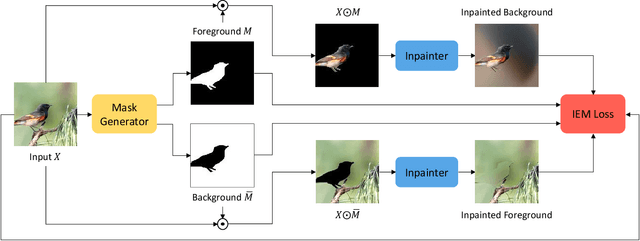
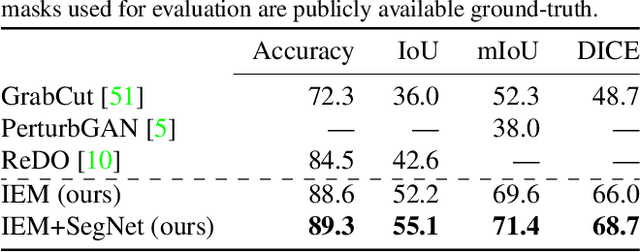
We study image segmentation from an information-theoretic perspective, proposing a novel adversarial method that performs unsupervised segmentation by partitioning images into maximally independent sets. More specifically, we group image pixels into foreground and background, with the goal of minimizing predictability of one set from the other. An easily computed loss drives a greedy search process to maximize inpainting error over these partitions. Our method does not involve training deep networks, is computationally cheap, class-agnostic, and even applicable in isolation to a single unlabeled image. Experiments demonstrate that it achieves a new state-of-the-art in unsupervised segmentation quality, while being substantially faster and more general than competing approaches.
Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-motion
Aug 15, 2020
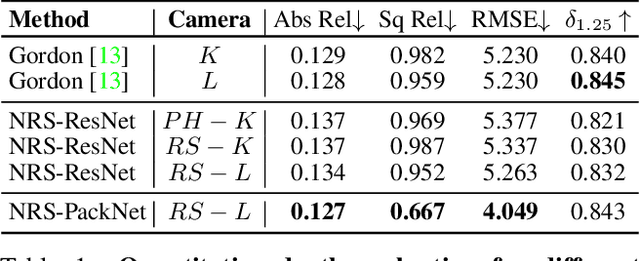
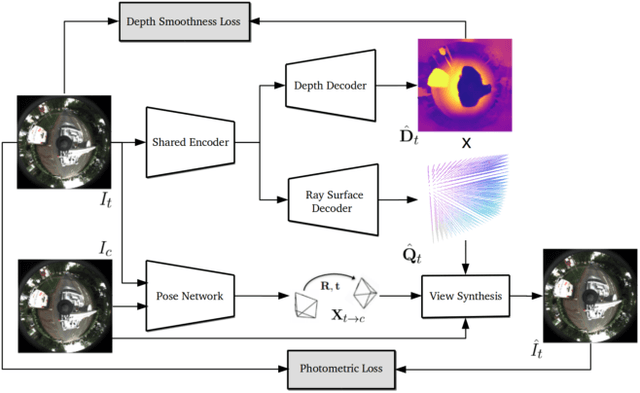

Self-supervised learning has emerged as a powerful tool for depth and ego-motion estimation, leading to state-of-the-art results on benchmark datasets. However, one significant limitation shared by current methods is the assumption of a known parametric camera model -- usually the standard pinhole geometry -- leading to failure when applied to imaging systems that deviate significantly from this assumption (e.g., catadioptric cameras or underwater imaging). In this work, we show that self-supervision can be used to learn accurate depth and ego-motion estimation without prior knowledge of the camera model. Inspired by the geometric model of Grossberg and Nayar, we introduce Neural Ray Surfaces (NRS), convolutional networks that represent pixel-wise projection rays, approximating a wide range of cameras. NRS are fully differentiable and can be learned end-to-end from unlabeled raw videos. We demonstrate the use of NRS for self-supervised learning of visual odometry and depth estimation from raw videos obtained using a wide variety of camera systems, including pinhole, fisheye, and catadioptric.
Controlling Length in Image Captioning
May 29, 2020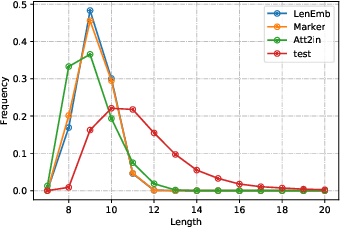

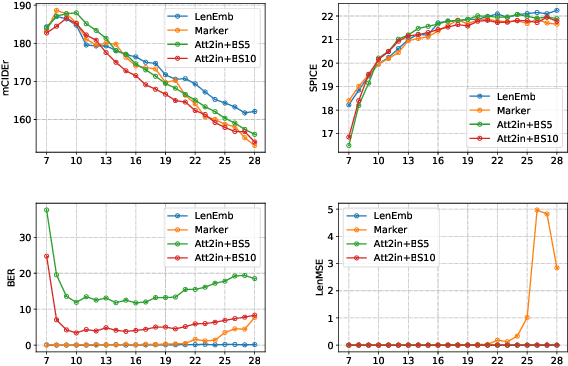

We develop and evaluate captioning models that allow control of caption length. Our models can leverage this control to generate captions of different style and descriptiveness.
Detection and Description of Change in Visual Streams
Apr 09, 2020

This paper presents a framework for the analysis of changes in visual streams: ordered sequences of images, possibly separated by significant time gaps. We propose a new approach to incorporating unlabeled data into training to generate natural language descriptions of change. We also develop a framework for estimating the time of change in visual stream. We use learned representations for change evidence and consistency of perceived change, and combine these in a regularized graph cut based change detector. Experimental evaluation on visual stream datasets, which we release as part of our contribution, shows that representation learning driven by natural language descriptions significantly improves change detection accuracy, compared to methods that do not rely on language.
Pixel Consensus Voting for Panoptic Segmentation
Apr 04, 2020The core of our approach, Pixel Consensus Voting, is a framework for instance segmentation based on the Generalized Hough transform. Pixels cast discretized, probabilistic votes for the likely regions that contain instance centroids. At the detected peaks that emerge in the voting heatmap, backprojection is applied to collect pixels and produce instance masks. Unlike a sliding window detector that densely enumerates object proposals, our method detects instances as a result of the consensus among pixel-wise votes. We implement vote aggregation and backprojection using native operators of a convolutional neural network. The discretization of centroid voting reduces the training of instance segmentation to pixel labeling, analogous and complementary to FCN-style semantic segmentation, leading to an efficient and unified architecture that jointly models things and stuff. We demonstrate the effectiveness of our pipeline on COCO and Cityscapes Panoptic Segmentation and obtain competitive results. Code will be open-sourced.
Space-Time-Aware Multi-Resolution Video Enhancement
Mar 30, 2020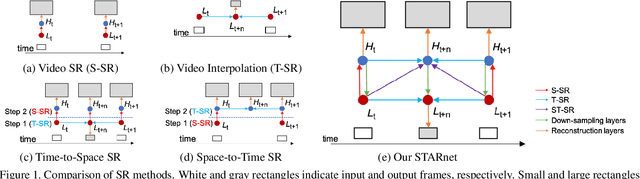
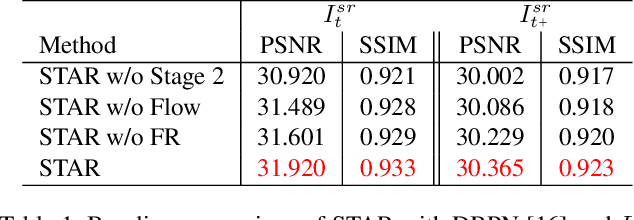

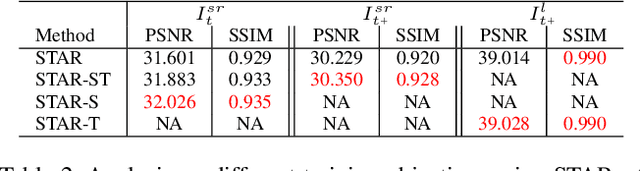
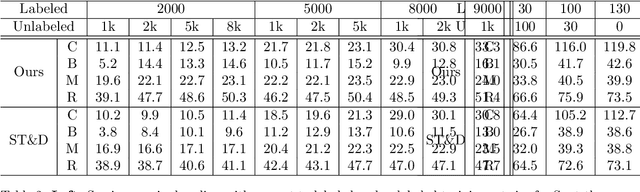
We consider the problem of space-time super-resolution (ST-SR): increasing spatial resolution of video frames and simultaneously interpolating frames to increase the frame rate. Modern approaches handle these axes one at a time. In contrast, our proposed model called STARnet super-resolves jointly in space and time. This allows us to leverage mutually informative relationships between time and space: higher resolution can provide more detailed information about motion, and higher frame-rate can provide better pixel alignment. The components of our model that generate latent low- and high-resolution representations during ST-SR can be used to finetune a specialized mechanism for just spatial or just temporal super-resolution. Experimental results demonstrate that STARnet improves the performances of space-time, spatial, and temporal video super-resolution by substantial margins on publicly available datasets.
Fingerspelling recognition in the wild with iterative visual attention
Aug 28, 2019

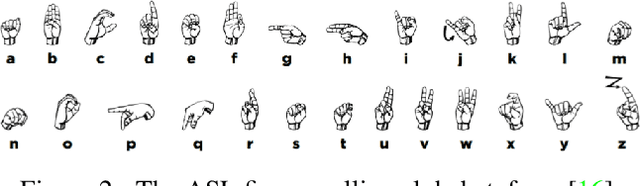
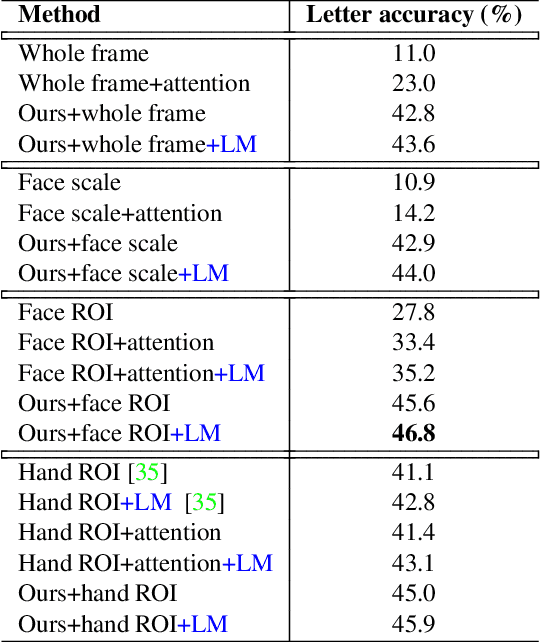
Sign language recognition is a challenging gesture sequence recognition problem, characterized by quick and highly coarticulated motion. In this paper we focus on recognition of fingerspelling sequences in American Sign Language (ASL) videos collected in the wild, mainly from YouTube and Deaf social media. Most previous work on sign language recognition has focused on controlled settings where the data is recorded in a studio environment and the number of signers is limited. Our work aims to address the challenges of real-life data, reducing the need for detection or segmentation modules commonly used in this domain. We propose an end-to-end model based on an iterative attention mechanism, without explicit hand detection or segmentation. Our approach dynamically focuses on increasingly high-resolution regions of interest. It outperforms prior work by a large margin. We also introduce a newly collected data set of crowdsourced annotations of fingerspelling in the wild, and show that performance can be further improved with this additional data set.
Style Transfer by Relaxed Optimal Transport and Self-Similarity
Apr 29, 2019
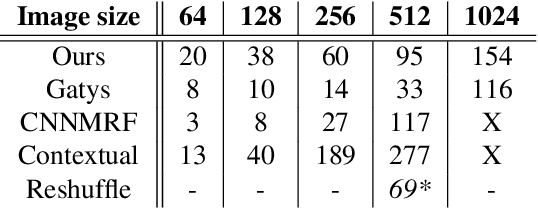


Style transfer algorithms strive to render the content of one image using the style of another. We propose Style Transfer by Relaxed Optimal Transport and Self-Similarity (STROTSS), a new optimization-based style transfer algorithm. We extend our method to allow user-specified point-to-point or region-to-region control over visual similarity between the style image and the output. Such guidance can be used to either achieve a particular visual effect or correct errors made by unconstrained style transfer. In order to quantitatively compare our method to prior work, we conduct a large-scale user study designed to assess the style-content tradeoff across settings in style transfer algorithms. Our results indicate that for any desired level of content preservation, our method provides higher quality stylization than prior work. Code is available at https://github.com/nkolkin13/STROTSS
Deep Back-Projection Networks for Single Image Super-resolution
Apr 04, 2019
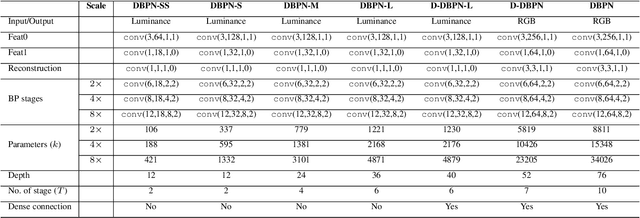
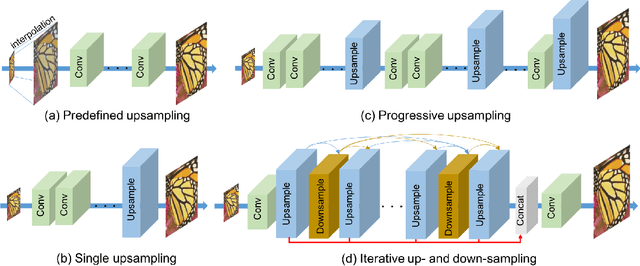
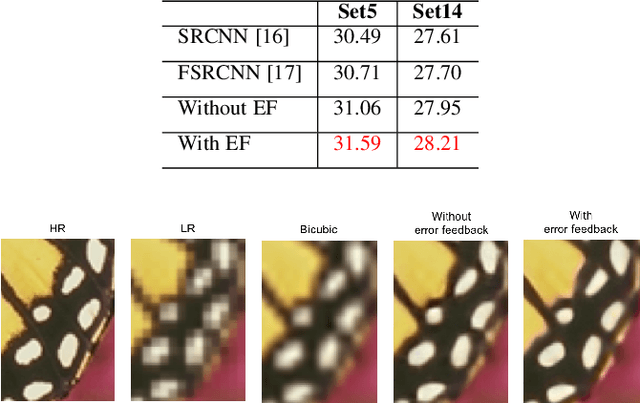
Previous feed-forward architectures of recently proposed deep super-resolution networks learn the features of low-resolution inputs and the non-linear mapping from those to a high-resolution output. However, this approach does not fully address the mutual dependencies of low- and high-resolution images. We propose Deep Back-Projection Networks (DBPN), the winner of two image super-resolution challenges (NTIRE2018 and PIRM2018), that exploit iterative up- and down-sampling layers. These layers are formed as a unit providing an error feedback mechanism for projection errors. We construct mutually-connected up- and down-sampling units each of which represents different types of image degradation and high-resolution components. We also show that extending this idea to several variants applying the latest deep network trends, such as recurrent network, dense connection, and residual learning, to improve the performance. The experimental results yield superior results and in particular establishing new state-of-the-art results across multiple data sets, especially for large scaling factors such as 8x.
Recurrent Back-Projection Network for Video Super-Resolution
Mar 25, 2019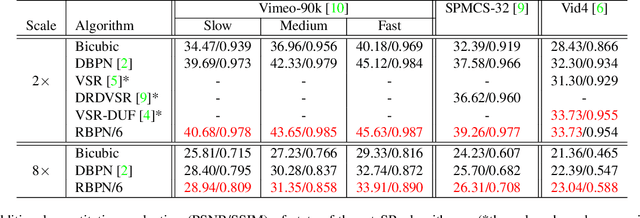



We proposed a novel architecture for the problem of video super-resolution. We integrate spatial and temporal contexts from continuous video frames using a recurrent encoder-decoder module, that fuses multi-frame information with the more traditional, single frame super-resolution path for the target frame. In contrast to most prior work where frames are pooled together by stacking or warping, our model, the Recurrent Back-Projection Network (RBPN) treats each context frame as a separate source of information. These sources are combined in an iterative refinement framework inspired by the idea of back-projection in multiple-image super-resolution. This is aided by explicitly representing estimated inter-frame motion with respect to the target, rather than explicitly aligning frames. We propose a new video super-resolution benchmark, allowing evaluation at a larger scale and considering videos in different motion regimes. Experimental results demonstrate that our RBPN is superior to existing methods on several datasets.