 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreg Shakhnarovich
Adapting CLIP For Phrase Localization Without Further Training
Apr 07, 2022

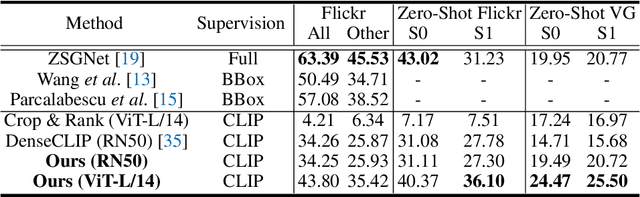
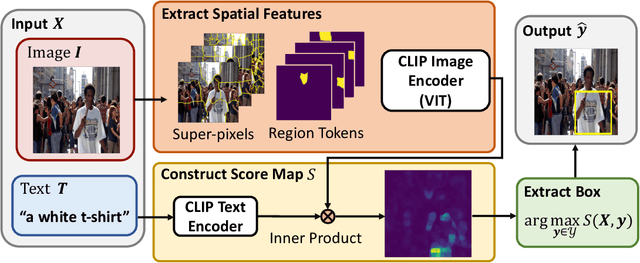
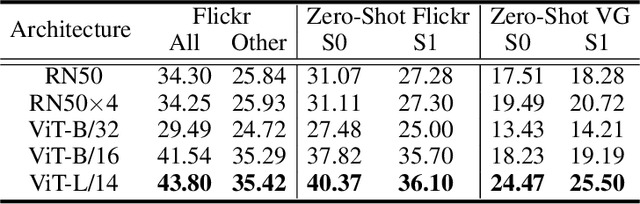
Supervised or weakly supervised methods for phrase localization (textual grounding) either rely on human annotations or some other supervised models, e.g., object detectors. Obtaining these annotations is labor-intensive and may be difficult to scale in practice. We propose to leverage recent advances in contrastive language-vision models, CLIP, pre-trained on image and caption pairs collected from the internet. In its original form, CLIP only outputs an image-level embedding without any spatial resolution. We adapt CLIP to generate high-resolution spatial feature maps. Importantly, we can extract feature maps from both ViT and ResNet CLIP model while maintaining the semantic properties of an image embedding. This provides a natural framework for phrase localization. Our method for phrase localization requires no human annotations or additional training. Extensive experiments show that our method outperforms existing no-training methods in zero-shot phrase localization, and in some cases, it even outperforms supervised methods. Code is available at https://github.com/pals-ttic/adapting-CLIP .
Searching for fingerspelled content in American Sign Language
Mar 24, 2022
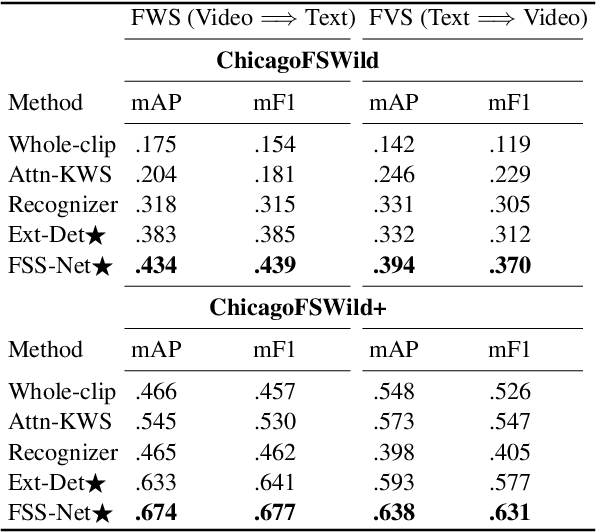
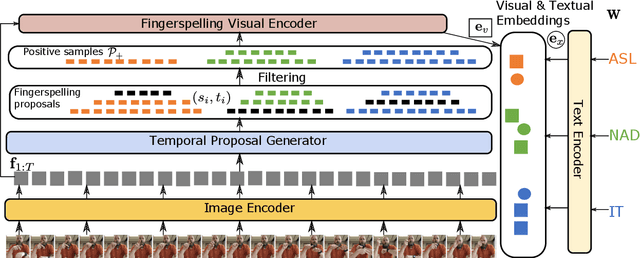
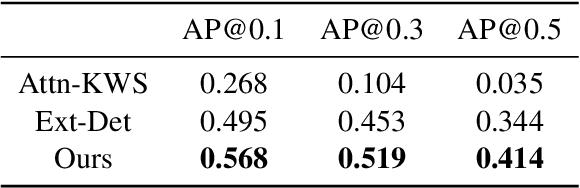
Natural language processing for sign language video - including tasks like recognition, translation, and search - is crucial for making artificial intelligence technologies accessible to deaf individuals, and is gaining research interest in recent years. In this paper, we address the problem of searching for fingerspelled key-words or key phrases in raw sign language videos. This is an important task since significant content in sign language is often conveyed via fingerspelling, and to our knowledge the task has not been studied before. We propose an end-to-end model for this task, FSS-Net, that jointly detects fingerspelling and matches it to a text sequence. Our experiments, done on a large public dataset of ASL fingerspelling in the wild, show the importance of fingerspelling detection as a component of a search and retrieval model. Our model significantly outperforms baseline methods adapted from prior work on related tasks
Neural Neighbor Style Transfer
Mar 24, 2022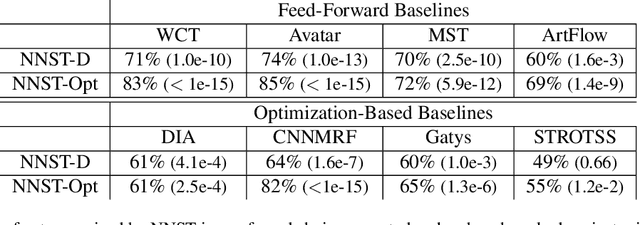
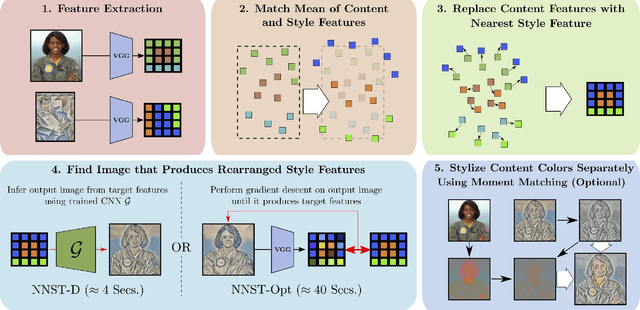


We propose Neural Neighbor Style Transfer (NNST), a pipeline that offers state-of-the-art quality, generalization, and competitive efficiency for artistic style transfer. Our approach is based on explicitly replacing neural features extracted from the content input (to be stylized) with those from a style exemplar, then synthesizing the final output based on these rearranged features. While the spirit of our approach is similar to prior work, we show that our design decisions dramatically improve the final visual quality.
Boosting Barely Robust Learners: A New Perspective on Adversarial Robustness
Feb 11, 2022We present an oracle-efficient algorithm for boosting the adversarial robustness of barely robust learners. Barely robust learning algorithms learn predictors that are adversarially robust only on a small fraction $\beta \ll 1$ of the data distribution. Our proposed notion of barely robust learning requires robustness with respect to a "larger" perturbation set; which we show is necessary for strongly robust learning, and that weaker relaxations are not sufficient for strongly robust learning. Our results reveal a qualitative and quantitative equivalence between two seemingly unrelated problems: strongly robust learning and barely robust learning.
Self-Supervised Camera Self-Calibration from Video
Dec 06, 2021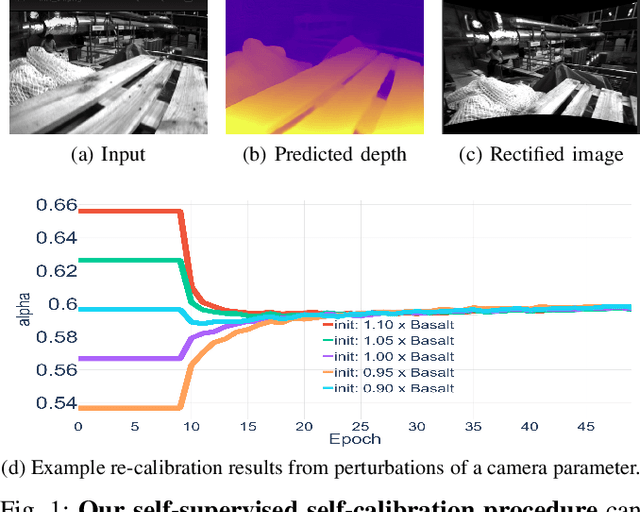
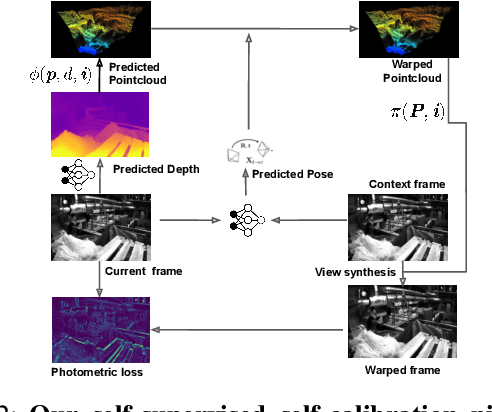
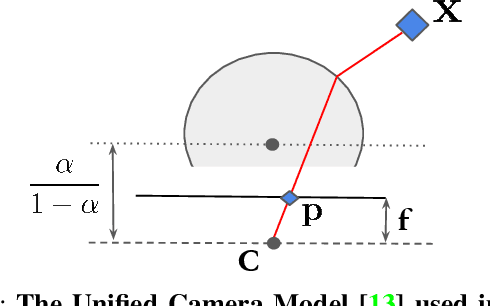

Camera calibration is integral to robotics and computer vision algorithms that seek to infer geometric properties of the scene from visual input streams. In practice, calibration is a laborious procedure requiring specialized data collection and careful tuning. This process must be repeated whenever the parameters of the camera change, which can be a frequent occurrence for mobile robots and autonomous vehicles. In contrast, self-supervised depth and ego-motion estimation approaches can bypass explicit calibration by inferring per-frame projection models that optimize a view synthesis objective. In this paper, we extend this approach to explicitly calibrate a wide range of cameras from raw videos in the wild. We propose a learning algorithm to regress per-sequence calibration parameters using an efficient family of general camera models. Our procedure achieves self-calibration results with sub-pixel reprojection error, outperforming other learning-based methods. We validate our approach on a wide variety of camera geometries, including perspective, fisheye, and catadioptric. Finally, we show that our approach leads to improvements in the downstream task of depth estimation, achieving state-of-the-art results on the EuRoC dataset with greater computational efficiency than contemporary methods.
Fingerspelling Detection in American Sign Language
Apr 03, 2021
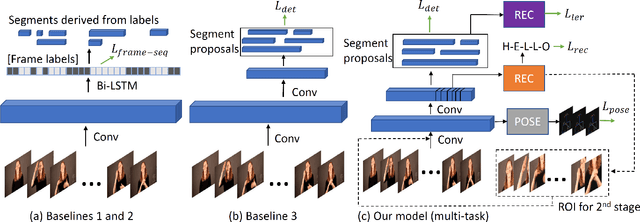
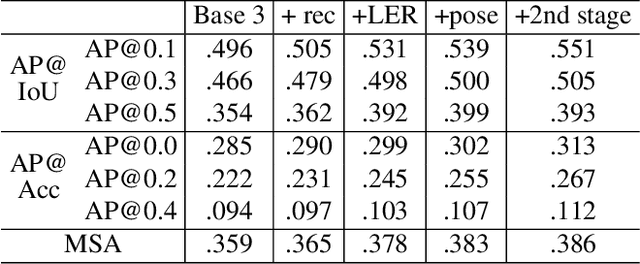
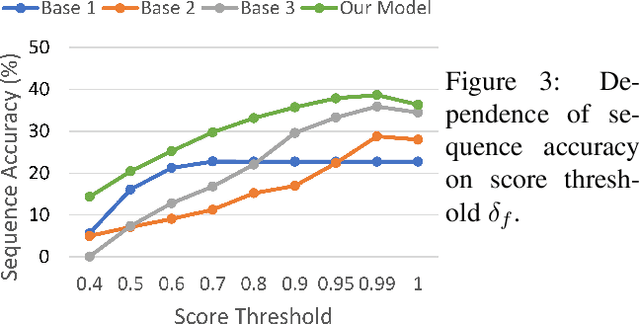
Fingerspelling, in which words are signed letter by letter, is an important component of American Sign Language. Most previous work on automatic fingerspelling recognition has assumed that the boundaries of fingerspelling regions in signing videos are known beforehand. In this paper, we consider the task of fingerspelling detection in raw, untrimmed sign language videos. This is an important step towards building real-world fingerspelling recognition systems. We propose a benchmark and a suite of evaluation metrics, some of which reflect the effect of detection on the downstream fingerspelling recognition task. In addition, we propose a new model that learns to detect fingerspelling via multi-task training, incorporating pose estimation and fingerspelling recognition (transcription) along with detection, and compare this model to several alternatives. The model outperforms all alternative approaches across all metrics, establishing a state of the art on the benchmark.
Full Surround Monodepth from Multiple Cameras
Mar 31, 2021
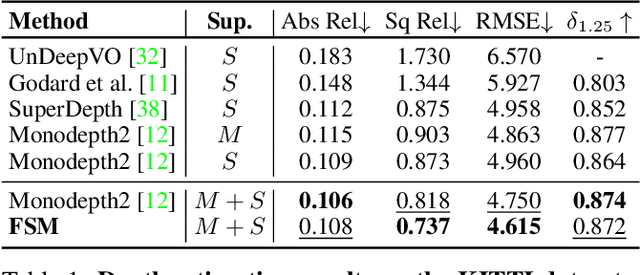
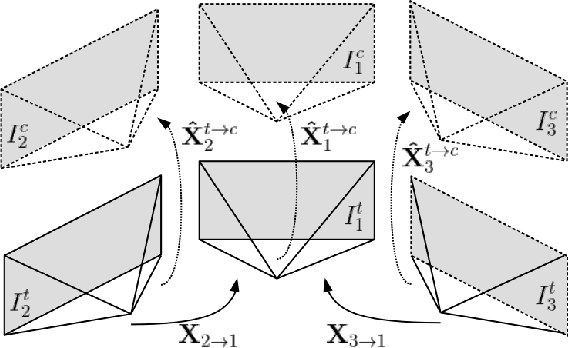
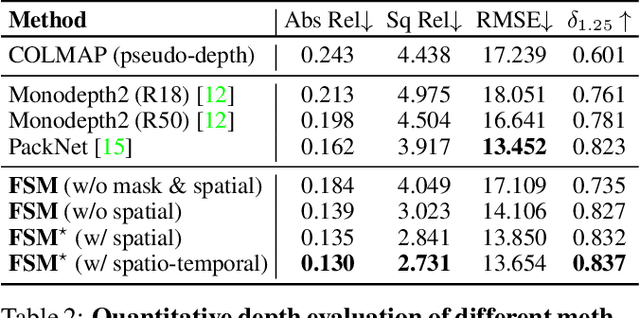
Self-supervised monocular depth and ego-motion estimation is a promising approach to replace or supplement expensive depth sensors such as LiDAR for robotics applications like autonomous driving. However, most research in this area focuses on a single monocular camera or stereo pairs that cover only a fraction of the scene around the vehicle. In this work, we extend monocular self-supervised depth and ego-motion estimation to large-baseline multi-camera rigs. Using generalized spatio-temporal contexts, pose consistency constraints, and carefully designed photometric loss masking, we learn a single network generating dense, consistent, and scale-aware point clouds that cover the same full surround 360 degree field of view as a typical LiDAR scanner. We also propose a new scale-consistent evaluation metric more suitable to multi-camera settings. Experiments on two challenging benchmarks illustrate the benefits of our approach over strong baselines.
Information-Theoretic Segmentation by Inpainting Error Maximization
Dec 14, 2020
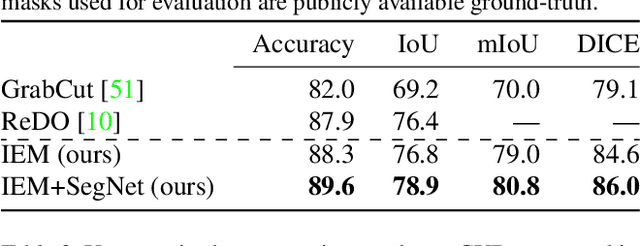
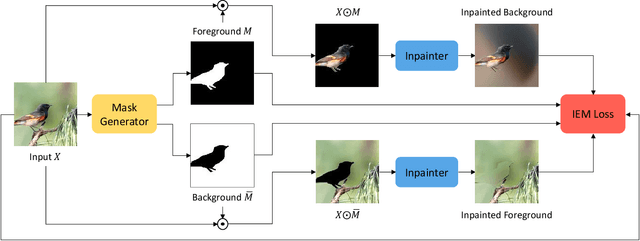
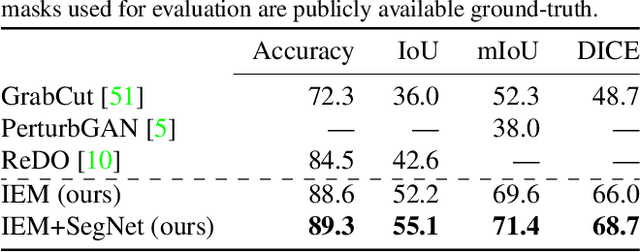
We study image segmentation from an information-theoretic perspective, proposing a novel adversarial method that performs unsupervised segmentation by partitioning images into maximally independent sets. More specifically, we group image pixels into foreground and background, with the goal of minimizing predictability of one set from the other. An easily computed loss drives a greedy search process to maximize inpainting error over these partitions. Our method does not involve training deep networks, is computationally cheap, class-agnostic, and even applicable in isolation to a single unlabeled image. Experiments demonstrate that it achieves a new state-of-the-art in unsupervised segmentation quality, while being substantially faster and more general than competing approaches.
Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-motion
Aug 15, 2020
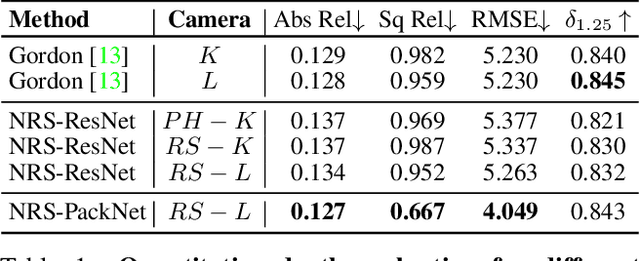
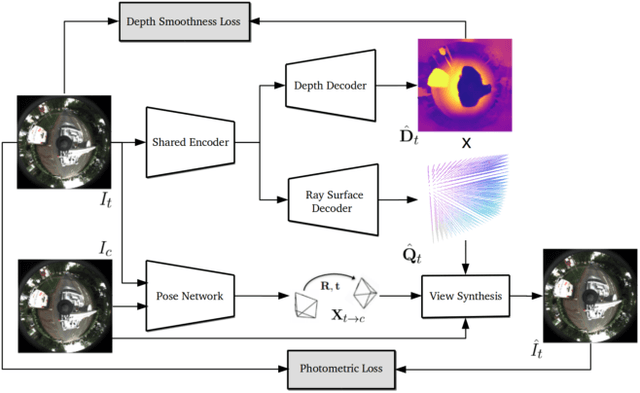

Self-supervised learning has emerged as a powerful tool for depth and ego-motion estimation, leading to state-of-the-art results on benchmark datasets. However, one significant limitation shared by current methods is the assumption of a known parametric camera model -- usually the standard pinhole geometry -- leading to failure when applied to imaging systems that deviate significantly from this assumption (e.g., catadioptric cameras or underwater imaging). In this work, we show that self-supervision can be used to learn accurate depth and ego-motion estimation without prior knowledge of the camera model. Inspired by the geometric model of Grossberg and Nayar, we introduce Neural Ray Surfaces (NRS), convolutional networks that represent pixel-wise projection rays, approximating a wide range of cameras. NRS are fully differentiable and can be learned end-to-end from unlabeled raw videos. We demonstrate the use of NRS for self-supervised learning of visual odometry and depth estimation from raw videos obtained using a wide variety of camera systems, including pinhole, fisheye, and catadioptric.
Controlling Length in Image Captioning
May 29, 2020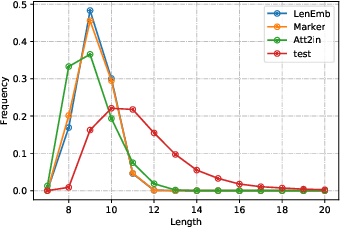

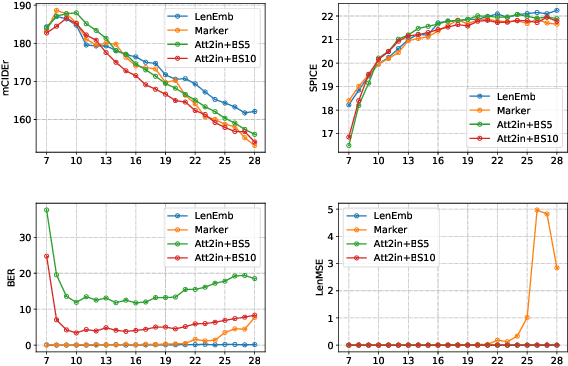

We develop and evaluate captioning models that allow control of caption length. Our models can leverage this control to generate captions of different style and descriptiveness.