 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeBERTScore: Evaluating Code Generation with Pretrained Models of Code
Feb 10, 2023
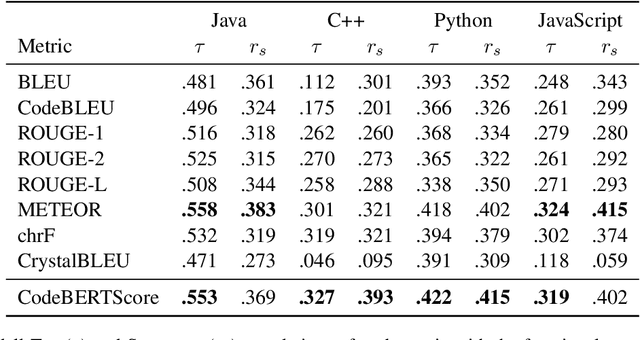
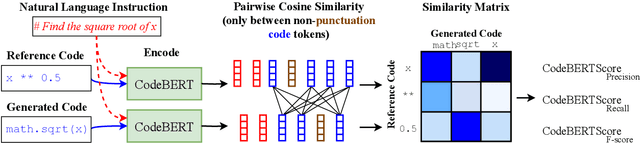
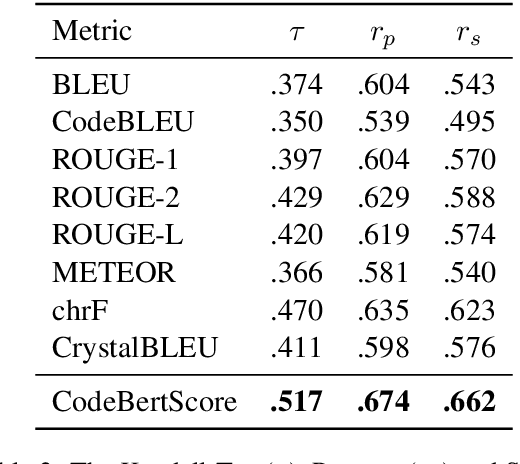
Since the rise of neural models of code that can generate long expressions and statements rather than a single next-token, one of the major problems has been reliably evaluating their generated output. In this paper, we propose CodeBERTScore: an automatic evaluation metric for code generation, which builds on BERTScore (Zhang et al., 2020). Instead of measuring exact token matching as BLEU, CodeBERTScore computes a soft similarity score between each token in the generated code and in the reference code, using the contextual encodings of large pretrained models. Further, instead of encoding only the generated tokens as in BERTScore, CodeBERTScore also encodes the programmatic context surrounding the generated code. We perform an extensive evaluation of CodeBERTScore across four programming languages. We find that CodeBERTScore achieves a higher correlation with human preference and with functional correctness than all existing metrics. That is, generated code that receives a higher score by CodeBERTScore is more likely to be preferred by humans, as well as to function correctly when executed. Finally, while CodeBERTScore can be used with a multilingual CodeBERT as its base model, we release five language-specific pretrained models to use with our publicly available code at https://github.com/neulab/code-bert-score . Our language-specific models have been downloaded more than 25,000 times from the Huggingface Hub.
Why do Nearest Neighbor Language Models Work?
Jan 17, 2023



Language models (LMs) compute the probability of a text by sequentially computing a representation of an already-seen context and using this representation to predict the next word. Currently, most LMs calculate these representations through a neural network consuming the immediate previous context. However recently, retrieval-augmented LMs have shown to improve over standard neural LMs, by accessing information retrieved from a large datastore, in addition to their standard, parametric, next-word prediction. In this paper, we set out to understand why retrieval-augmented language models, and specifically why k-nearest neighbor language models (kNN-LMs) perform better than standard parametric LMs, even when the k-nearest neighbor component retrieves examples from the same training set that the LM was originally trained on. To this end, we perform a careful analysis of the various dimensions over which kNN-LM diverges from standard LMs, and investigate these dimensions one by one. Empirically, we identify three main reasons why kNN-LM performs better than standard LMs: using a different input representation for predicting the next tokens, approximate kNN search, and the importance of softmax temperature for the kNN distribution. Further, we incorporate these insights into the model architecture or the training procedure of the standard parametric LM, improving its results without the need for an explicit retrieval component. The code is available at https://github.com/frankxu2004/knnlm-why.
Beyond Contrastive Learning: A Variational Generative Model for Multilingual Retrieval
Dec 21, 2022Contrastive learning has been successfully used for retrieval of semantically aligned sentences, but it often requires large batch sizes or careful engineering to work well. In this paper, we instead propose a generative model for learning multilingual text embeddings which can be used to retrieve or score sentence pairs. Our model operates on parallel data in $N$ languages and, through an approximation we introduce, efficiently encourages source separation in this multilingual setting, separating semantic information that is shared between translations from stylistic or language-specific variation. We show careful large-scale comparisons between contrastive and generation-based approaches for learning multilingual text embeddings, a comparison that has not been done to the best of our knowledge despite the popularity of these approaches. We evaluate this method on a suite of tasks including semantic similarity, bitext mining, and cross-lingual question retrieval -- the last of which we introduce in this paper. Overall, our Variational Multilingual Source-Separation Transformer (VMSST) model outperforms both a strong contrastive and generative baseline on these tasks.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
Execution-Based Evaluation for Open-Domain Code Generation
Dec 20, 2022



To extend the scope of coding queries to more realistic settings, we propose ODEX, the first open-domain execution-based natural language (NL) to code generation dataset. ODEX has 945 NL-Code pairs spanning 79 diverse libraries, along with 1,707 human-written test cases for execution. Our NL-Code pairs are harvested from StackOverflow forums to encourage natural and practical coding queries, which are then carefully rephrased to ensure intent clarity and prevent potential data memorization. Moreover, ODEX supports four natural languages as intents, in English, Spanish, Japanese, and Russian. ODEX unveils intriguing behavioral differences between top-performing Code LMs: Codex performs better on open-domain queries, yet CodeGen captures a better balance between open- and closed-domain. ODEX corroborates the merits of execution-based evaluation over metrics without execution but also unveils their complementary effects. Powerful models such as CodeGen-6B only achieve an 11.96 pass rate at top-1 prediction, suggesting plenty of headroom for improvement. We release ODEX to facilitate research into open-domain problems for the code generation community.
Searching for Effective Multilingual Fine-Tuning Methods: A Case Study in Summarization
Dec 12, 2022



Recently, a large number of tuning strategies have been proposed to adapt pre-trained language models to downstream tasks. In this paper, we perform an extensive empirical evaluation of various tuning strategies for multilingual learning, particularly in the context of text summarization. Specifically, we explore the relative advantages of three families of multilingual tuning strategies (a total of five models) and empirically evaluate them for summarization over 45 languages. Experimentally, we not only established a new state-of-the-art on the XL-Sum dataset but also derive a series of observations that hopefully can provide hints for future research on the design of multilingual tuning strategies.
T5Score: Discriminative Fine-tuning of Generative Evaluation Metrics
Dec 12, 2022Modern embedding-based metrics for evaluation of generated text generally fall into one of two paradigms: discriminative metrics that are trained to directly predict which outputs are of higher quality according to supervised human annotations, and generative metrics that are trained to evaluate text based on the probabilities of a generative model. Both have their advantages; discriminative metrics are able to directly optimize for the problem of distinguishing between good and bad outputs, while generative metrics can be trained using abundant raw text. In this paper, we present a framework that combines the best of both worlds, using both supervised and unsupervised signals from whatever data we have available. We operationalize this idea by training T5Score, a metric that uses these training signals with mT5 as the backbone. We perform an extensive empirical comparison with other existing metrics on 5 datasets, 19 languages and 280 systems, demonstrating the utility of our method. Experimental results show that: T5Score achieves the best performance on all datasets against existing top-scoring metrics at the segment level. We release our code and models at https://github.com/qinyiwei/T5Score.
Retrieval as Attention: End-to-end Learning of Retrieval and Reading within a Single Transformer
Dec 05, 2022



Systems for knowledge-intensive tasks such as open-domain question answering (QA) usually consist of two stages: efficient retrieval of relevant documents from a large corpus and detailed reading of the selected documents to generate answers. Retrievers and readers are usually modeled separately, which necessitates a cumbersome implementation and is hard to train and adapt in an end-to-end fashion. In this paper, we revisit this design and eschew the separate architecture and training in favor of a single Transformer that performs Retrieval as Attention (ReAtt), and end-to-end training solely based on supervision from the end QA task. We demonstrate for the first time that a single model trained end-to-end can achieve both competitive retrieval and QA performance, matching or slightly outperforming state-of-the-art separately trained retrievers and readers. Moreover, end-to-end adaptation significantly boosts its performance on out-of-domain datasets in both supervised and unsupervised settings, making our model a simple and adaptable solution for knowledge-intensive tasks. Code and models are available at https://github.com/jzbjyb/ReAtt.
PAL: Program-aided Language Models
Nov 18, 2022



Large language models (LLMs) have recently demonstrated an impressive ability to perform arithmetic and symbolic reasoning tasks when provided with a few examples at test time (few-shot prompting). Much of this success can be attributed to prompting methods for reasoning, such as chain-of-thought, that employ LLMs for both understanding the problem description by decomposing it into steps, as well as solving each step of the problem. While LLMs seem to be adept at this sort of step-by-step decomposition, LLMs often make logical and arithmetic mistakes in the solution part, even when the problem is correctly decomposed. We present Program-Aided Language models (PaL): a new method that uses the LLM to understand natural language problems and generate programs as the intermediate reasoning steps, but offloads the solution step to a programmatic runtime such as a Python interpreter. With PaL, decomposing the natural language problem into runnable steps remains the only learning task for the LLM, while solving is delegated to the interpreter. We experiment with 12 reasoning tasks from BIG-Bench Hard and other benchmarks, including mathematical reasoning, symbolic reasoning, and algorithmic problems. In all these natural language reasoning tasks, generating code using an LLM and reasoning using a Python interpreter leads to more accurate results than much larger models, and we set new state-of-the-art results in all 12 benchmarks. For example, PaL using Codex achieves state-of-the-art few-shot accuracy on the GSM benchmark of math word problems when the model is allowed only a single decoding, surpassing PaLM-540B with chain-of-thought prompting by an absolute 8% .In three reasoning tasks from the BIG-Bench Hard benchmark, PaL outperforms CoT by 11%. On GSM-hard, a more challenging version of GSM that we create, PaL outperforms chain-of-thought by an absolute 40%.
English Contrastive Learning Can Learn Universal Cross-lingual Sentence Embeddings
Nov 11, 2022Universal cross-lingual sentence embeddings map semantically similar cross-lingual sentences into a shared embedding space. Aligning cross-lingual sentence embeddings usually requires supervised cross-lingual parallel sentences. In this work, we propose mSimCSE, which extends SimCSE to multilingual settings and reveal that contrastive learning on English data can surprisingly learn high-quality universal cross-lingual sentence embeddings without any parallel data. In unsupervised and weakly supervised settings, mSimCSE significantly improves previous sentence embedding methods on cross-lingual retrieval and multilingual STS tasks. The performance of unsupervised mSimCSE is comparable to fully supervised methods in retrieving low-resource languages and multilingual STS. The performance can be further enhanced when cross-lingual NLI data is available. Our code is publicly available at https://github.com/yaushian/mSimCSE.