 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKamera: Unified Position-Invariant Multimodal KV Cache for Training-Free Reuse
Jun 22, 2026Multimodal agents repeatedly re-examine the same video frames, UI screenshots, and rendered artifacts as their context window slides and reasoning iterates, yet every look-back re-encodes from scratch, because prefix caches serve reuse only at a fixed leading position. We show this recompute is avoidable, and identify exactly what naive KV reuse loses: the cross-chunk conditioning a chunk absorbs from its neighbours. This loss is asymmetric. The direct readout of a cached chunk is recovered exactly and for free by the standard state-merge. What remains is a diffuse, low-rank residue concentrated in deep layers, invisible to single-hop retrieval but precisely what multi-hop reasoning binds on. Blind reuse therefore leaves single-hop recall intact while halving multi-hop accuracy; this is the failure mode prior position-independent caches, designed for single-context or single-image reuse, do not address. We repair it with a small, training-free low-rank conditioning patch stored alongside each position-free chunk. Reuse reduces to one operator across MLA, GQA, and MHA: exact RoPE re-rotation to any target position, plus the patch that restores cross-chunk binding. This makes three window operations cheap: reorder (one patch serves every ordering of a cached set), sliding-window survival (surviving chunks relocate via rotation only, zero re-encode), and recall (an evicted chunk is rehydrated by its patch, never re-encoded). A rank-m patch recovers full task accuracy on cross-chunk-binding benchmarks, MM-NIAH across two attention families and two-page doc-QA, at a fraction of the KV footprint, and reconstructs re-prefill KV to within bf16 rounding in a production SGLang kernel across six backbones. The conditioning signal is strongest in redundant vision and video streams, making our solution most impactful where multimodal agents spend their recompute budget.
Move the Query, Not the Cache: Characterizing Cross-Instance Latent Attention Redistribution Across GPU Fabrics
May 31, 2026Frontier LLMs increasingly decide what a query attends to with a sparse-attention indexer that picks a few KV-cache blocks per query: attention's unit is now a small, reusable chunk. Agentic workloads hammer it: many sub-agents query one large codebase, reusing the same blocks. When that corpus outgrows one GPU it is partitioned across instances, so a query and the blocks it selects often sit on different GPUs: answering it means attention across instances. The reflex of prior cross-instance KV systems is to move the cache: pull the selected blocks to the requester. Multi-head Latent Attention inverts the arithmetic, compressing each token's key and value into one narrow vector, so a routed query row is only ~1 KB, smaller than the chunk it attends; routing the query is then often cheaper than moving the cache. Which primitive wins, over which fabric and request shape, is uncharted, least of all on device-initiated RDMA that makes per-request cross-node transfers cheap. We characterize cross-instance MLA attention on a real multi-node H100 cluster, distilling two reusable artifacts: a topology-aware cost model (probe / transfer / compute / return / merge) and a closed-form route/fetch/local predicate, whose constants we measure on real IBGDA, where the model tracks batched round-trips to within ~7%. At decode it routes the query, trading the cost of moving the cache (a ~3 ms re-adaptation splice for a contiguous chunk, or a scattered gather under selection) for a tens-of-microsecond round trip, and picks the fabric by probe latency, not peak bandwidth. We instantiate the cost model and predicate for MLA, but neither is MLA-specific: they apply wherever compression or sparse selection shrinks attention to small chunks (DeepSeek-V3.2, V4, and GLM-5.1 today). Extending them to a new architecture requires measuring just two coefficients: the routed payload and fetch's move-the-cache cost.
Diagnosing Overhead in Dispatch Operations: Cross-architecture Observatory
May 20, 2026AlltoAll dispatch is the dominant bottleneck of MoE expert parallelism, and the interconnect community has responded with four families of mitigations: predictive sample placement, adaptive expert relayout, hierarchical collectives, and EP-aware topology. All four rest on two assumptions about the workload. The first is that routing imbalance is correctable by the system layer. The second is that the mock-token benchmarks evaluating them faithfully represent production routing. We introduce DODOCO to test both assumptions. We instrument five MoE checkpoints spanning five sequence-mixer designs (DeepSeek-V2-Lite MLA, DeepSeek-MoE-16B MHA, Qwen3-30B GQA, Nemotron-30B Mamba-2, Qwen3.5-35B GDN) under a 5 by 6 grid of data conditions plus a matched EP scan from 4 to 32 ranks on H100s; both assumptions fail. Scaling EP changes the per-expert max/mean token ratio by at most 5% within every architecture's measurable range: the straggler is intrinsic to the routing decision the model makes, not to how its experts land on ranks. Mock tokens overestimate routing Gini by up to a factor of 2.35 and fabricate a batch-size scaling trend that vanishes the moment real text replaces random IDs. A third pattern, unexpected, emerges from the same matrix: the five architectures cleave into two stable bands. MHA and Mamba-2 (data-resilient) drop to Gini 0.105 and 0.150 on wikitext. MLA and GDN (persistently concentrated) stay above 0.24 on every real-text condition and reach 0.29 to 0.38 on mock. GQA is the intermediate case. These bands, not the EP degree or the mock-data profile, are the right workload input to AlltoAll-aware interconnect and dispatch design.
The Illusion of Power Capping in LLM Decode: A Phase-Aware Energy Characterisation Across Attention Architectures
May 12, 2026Power capping is the standard GPU energy lever in LLM serving, and it appears to work: throughput drops, power readings fall, and energy budgets are met. We show the appearance is illusory for the phase that dominates production serving: autoregressive decode. Across four attention paradigms -- GQA, MLA, Gated DeltaNet, and Mamba2 -- on NVIDIA H200, decode draws only 137--300\,W on a 700\,W GPU; no cap ever triggers, because memory-bound decode saturates HBM bandwidth rather than compute and leaves power headroom untouched. Firmware-initiated clock throttling compounds the illusion: these deviations can corrupt any throughput measurement that attributes them to the cap. SM clock locking dissolves both confounds. By targeting the lever that is actually on the critical path, clock locking Pareto-dominates power capping universally, recovering up to 32\% of decode energy at minimal throughput loss. We identify three architecture-dependent DVFS behavioural classes and characterise a common energy pattern across novel attention replacements: a heavy prefill cost recouped by efficient decode, eventually halving total request energy relative to GQA at production batch sizes.
Safety and accuracy follow different scaling laws in clinical large language models
May 05, 2026Clinical LLMs are often scaled by increasing model size, context length, retrieval complexity, or inference-time compute, with the implicit expectation that higher accuracy implies safer behavior. This assumption is incomplete in medicine, where a few confident, high-risk, or evidence-contradicting errors can matter more than average benchmark performance. We introduce SaFE-Scale, a framework for measuring how clinical LLM safety changes across model scale, evidence quality, retrieval strategy, context exposure, and inference-time compute. To instantiate this framework, we introduce RadSaFE-200, a Radiology Safety-Focused Evaluation benchmark of 200 multiple-choice questions with clinician-defined clean evidence, conflict evidence, and option-level labels for high-risk error, unsafe answer, and evidence contradiction. We evaluated 34 locally deployed LLMs across six deployment conditions: closed-book prompting (zero-shot), clean evidence, conflict evidence, standard RAG, agentic RAG, and max-context prompting. Clean evidence produced the strongest improvement, increasing mean accuracy from 73.5% to 94.1%, while reducing high-risk error from 12.0% to 2.6%, contradiction from 12.7% to 2.3%, and dangerous overconfidence from 8.0% to 1.6%. Standard RAG and agentic RAG did not reproduce this safety profile: agentic RAG improved accuracy over standard RAG and reduced contradiction, but high-risk error and dangerous overconfidence remained elevated. Max-context prompting increased latency without closing the safety gap, and additional inference-time compute produced only limited gains. Worst-case analysis showed that clinically consequential errors concentrated in a small subset of questions. Clinical LLM safety is therefore not a passive consequence of scaling, but a deployment property shaped by evidence quality, retrieval design, context construction, and collective failure behavior.
SteuerLLM: Local specialized large language model for German tax law analysis
Feb 11, 2026Large language models (LLMs) demonstrate strong general reasoning and language understanding, yet their performance degrades in domains governed by strict formal rules, precise terminology, and legally binding structure. Tax law exemplifies these challenges, as correct answers require exact statutory citation, structured legal argumentation, and numerical accuracy under rigid grading schemes. We algorithmically generate SteuerEx, the first open benchmark derived from authentic German university tax law examinations. SteuerEx comprises 115 expert-validated examination questions spanning six core tax law domains and multiple academic levels, and employs a statement-level, partial-credit evaluation framework that closely mirrors real examination practice. We further present SteuerLLM, a domain-adapted LLM for German tax law trained on a large-scale synthetic dataset generated from authentic examination material using a controlled retrieval-augmented pipeline. SteuerLLM (28B parameters) consistently outperforms general-purpose instruction-tuned models of comparable size and, in several cases, substantially larger systems, demonstrating that domain-specific data and architectural adaptation are more decisive than parameter scale for performance on realistic legal reasoning tasks. All benchmark data, training datasets, model weights, and evaluation code are released openly to support reproducible research in domain-specific legal artificial intelligence. A web-based demo of SteuerLLM is available at https://steuerllm.i5.ai.fau.de.
Agentic large language models improve retrieval-based radiology question answering
Aug 01, 2025



Clinical decision-making in radiology increasingly benefits from artificial intelligence (AI), particularly through large language models (LLMs). However, traditional retrieval-augmented generation (RAG) systems for radiology question answering (QA) typically rely on single-step retrieval, limiting their ability to handle complex clinical reasoning tasks. Here we propose an agentic RAG framework enabling LLMs to autonomously decompose radiology questions, iteratively retrieve targeted clinical evidence from Radiopaedia, and dynamically synthesize evidence-based responses. We evaluated 24 LLMs spanning diverse architectures, parameter scales (0.5B to >670B), and training paradigms (general-purpose, reasoning-optimized, clinically fine-tuned), using 104 expert-curated radiology questions from previously established RSNA-RadioQA and ExtendedQA datasets. Agentic retrieval significantly improved mean diagnostic accuracy over zero-shot prompting (73% vs. 64%; P<0.001) and conventional online RAG (73% vs. 68%; P<0.001). The greatest gains occurred in mid-sized models (e.g., Mistral Large improved from 72% to 81%) and small-scale models (e.g., Qwen 2.5-7B improved from 55% to 71%), while very large models (>200B parameters) demonstrated minimal changes (<2% improvement). Additionally, agentic retrieval reduced hallucinations (mean 9.4%) and retrieved clinically relevant context in 46% of cases, substantially aiding factual grounding. Even clinically fine-tuned models exhibited meaningful improvements (e.g., MedGemma-27B improved from 71% to 81%), indicating complementary roles of retrieval and fine-tuning. These results highlight the potential of agentic frameworks to enhance factuality and diagnostic accuracy in radiology QA, particularly among mid-sized LLMs, warranting future studies to validate their clinical utility.
Exploring Techniques for the Analysis of Spontaneous Asynchronicity in MPI-Parallel Applications
May 27, 2022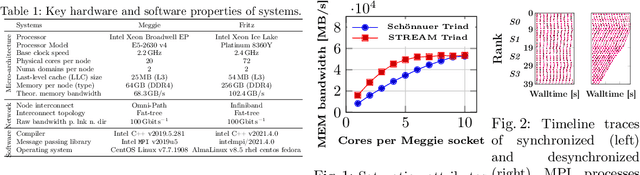
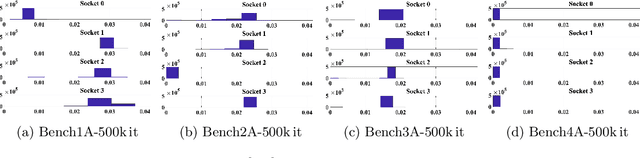
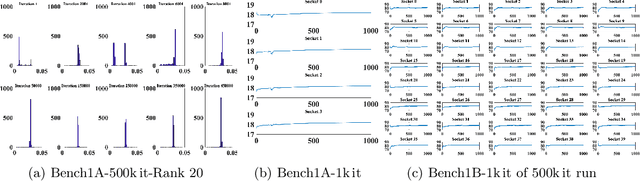
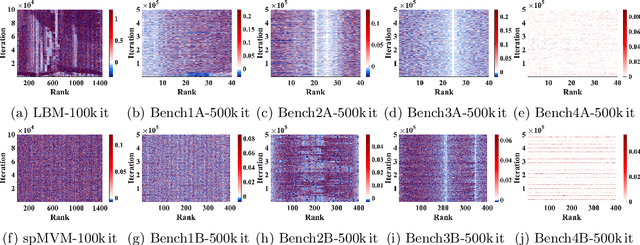
This paper studies the utility of using data analytics and machine learning techniques for identifying, classifying, and characterizing the dynamics of large-scale parallel (MPI) programs. To this end, we run microbenchmarks and realistic proxy applications with the regular compute-communicate structure on two different supercomputing platforms and choose the per-process performance and MPI time per time step as relevant observables. Using principal component analysis, clustering techniques, correlation functions, and a new "phase space plot," we show how desynchronization patterns (or lack thereof) can be readily identified from a data set that is much smaller than a full MPI trace. Our methods also lead the way towards a more general classification of parallel program dynamics.
$K$-way $p$-spectral clustering on Grassmann manifolds
Aug 30, 2020
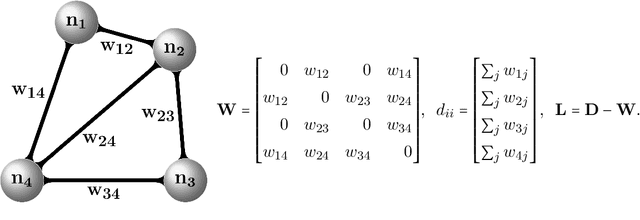
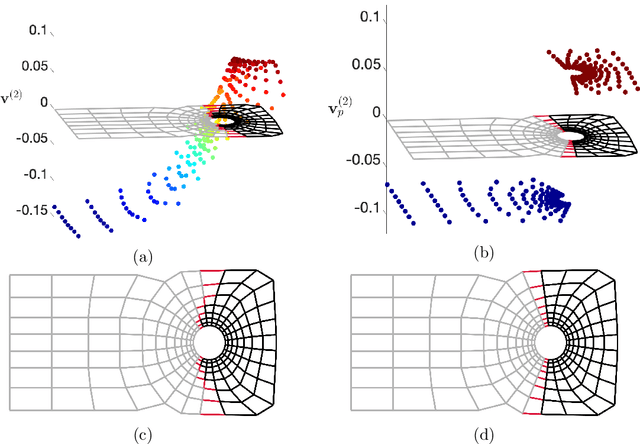
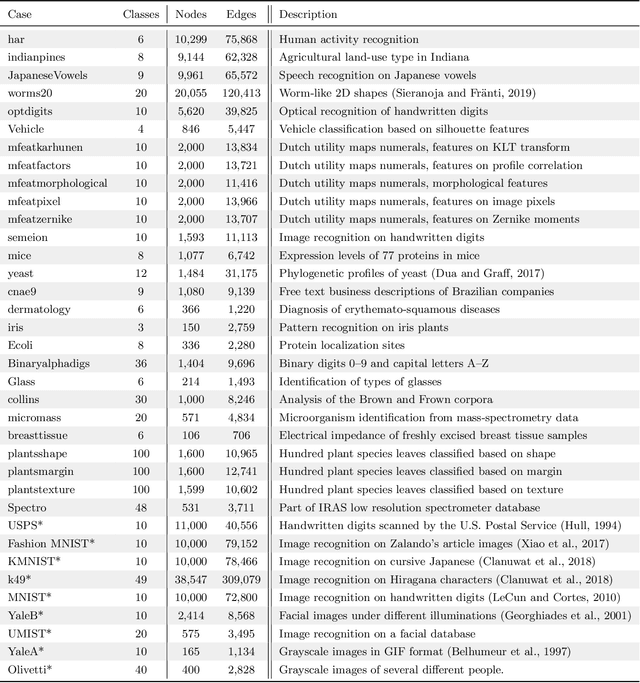
Spectral methods have gained a lot of recent attention due to the simplicity of their implementation and their solid mathematical background. We revisit spectral graph clustering, and reformulate in the $p$-norm the continuous problem of minimizing the graph Laplacian Rayleigh quotient. The value of $p \in (1,2]$ is reduced, promoting sparser solution vectors that correspond to optimal clusters as $p$ approaches one. The computation of multiple $p$-eigenvectors of the graph $p$-Laplacian, a nonlinear generalization of the standard graph Laplacian, is achieved by the minimization of our objective function on the Grassmann manifold, hence ensuring the enforcement of the orthogonality constraint between them. Our approach attempts to bridge the fields of graph clustering and nonlinear numerical optimization, and employs a robust algorithm to obtain clusters of high quality. The benefits of the suggested method are demonstrated in a plethora of artificial and real-world graphs. Our results are compared against standard spectral clustering methods and the current state-of-the-art algorithm for clustering using the graph $p$-Laplacian variant.
Performance Engineering for a Medical Imaging Application on the Intel Xeon Phi Accelerator
Dec 17, 2013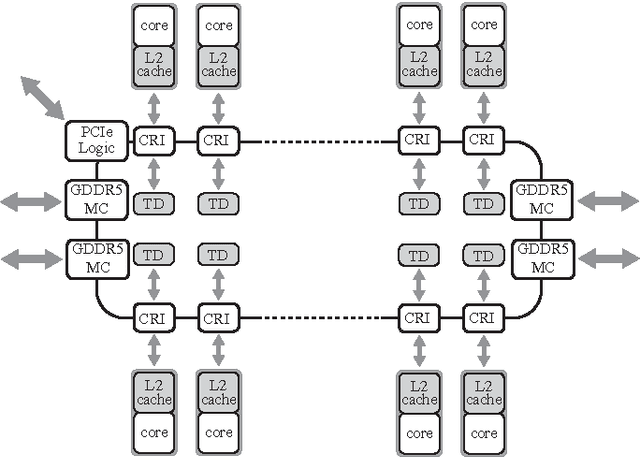
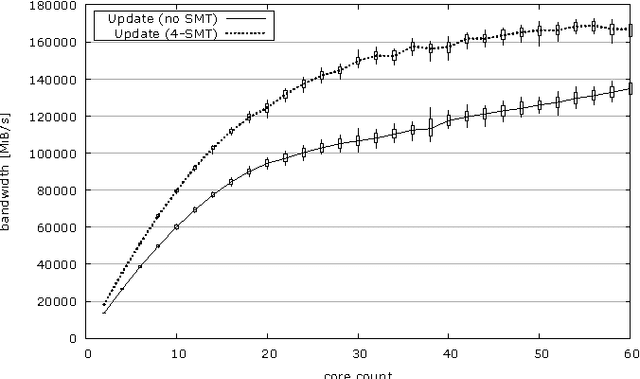
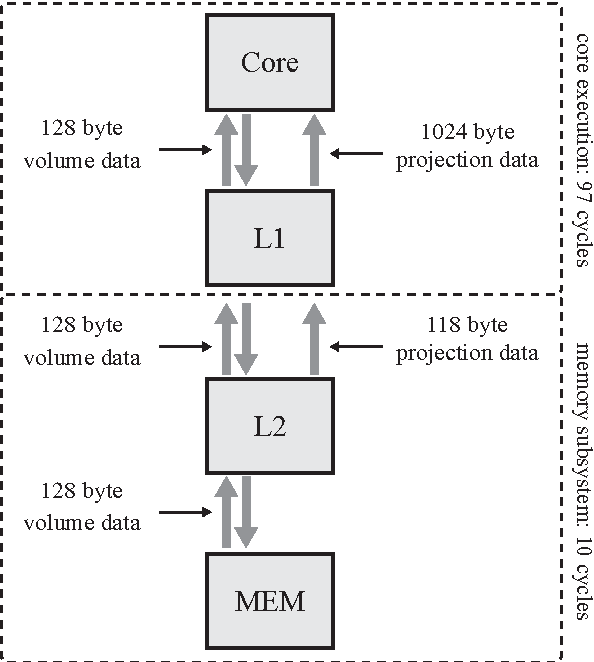
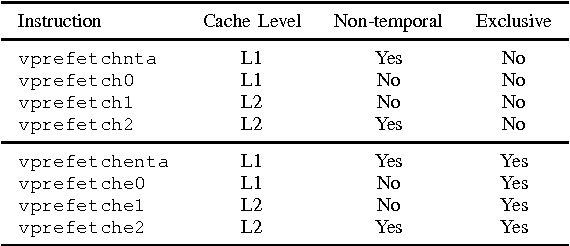
We examine the Xeon Phi, which is based on Intel's Many Integrated Cores architecture, for its suitability to run the FDK algorithm--the most commonly used algorithm to perform the 3D image reconstruction in cone-beam computed tomography. We study the challenges of efficiently parallelizing the application and means to enable sensible data sharing between threads despite the lack of a shared last level cache. Apart from parallelization, SIMD vectorization is critical for good performance on the Xeon Phi; we perform various micro-benchmarks to investigate the platform's new set of vector instructions and put a special emphasis on the newly introduced vector gather capability. We refine a previous performance model for the application and adapt it for the Xeon Phi to validate the performance of our optimized hand-written assembly implementation, as well as the performance of several different auto-vectorization approaches.