 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Power Capping in LLM Decode: A Phase-Aware Energy Characterisation Across Attention Architectures
May 12, 2026Power capping is the standard GPU energy lever in LLM serving, and it appears to work: throughput drops, power readings fall, and energy budgets are met. We show the appearance is illusory for the phase that dominates production serving: autoregressive decode. Across four attention paradigms -- GQA, MLA, Gated DeltaNet, and Mamba2 -- on NVIDIA H200, decode draws only 137--300\,W on a 700\,W GPU; no cap ever triggers, because memory-bound decode saturates HBM bandwidth rather than compute and leaves power headroom untouched. Firmware-initiated clock throttling compounds the illusion: these deviations can corrupt any throughput measurement that attributes them to the cap. SM clock locking dissolves both confounds. By targeting the lever that is actually on the critical path, clock locking Pareto-dominates power capping universally, recovering up to 32\% of decode energy at minimal throughput loss. We identify three architecture-dependent DVFS behavioural classes and characterise a common energy pattern across novel attention replacements: a heavy prefill cost recouped by efficient decode, eventually halving total request energy relative to GQA at production batch sizes.
Exploring Techniques for the Analysis of Spontaneous Asynchronicity in MPI-Parallel Applications
May 27, 2022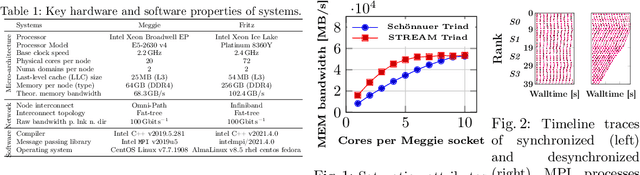
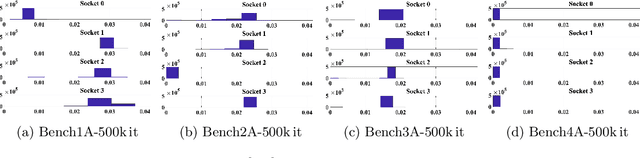
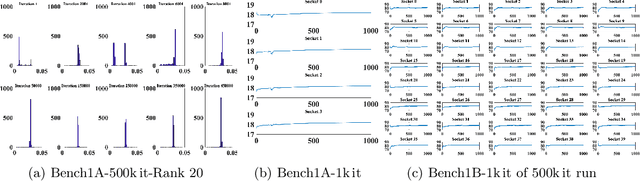
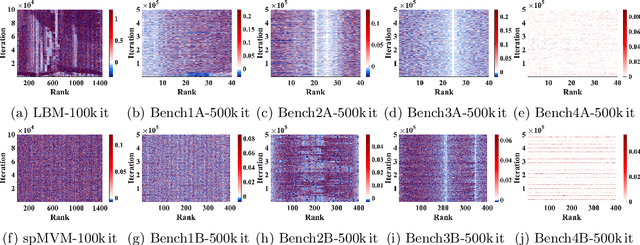
This paper studies the utility of using data analytics and machine learning techniques for identifying, classifying, and characterizing the dynamics of large-scale parallel (MPI) programs. To this end, we run microbenchmarks and realistic proxy applications with the regular compute-communicate structure on two different supercomputing platforms and choose the per-process performance and MPI time per time step as relevant observables. Using principal component analysis, clustering techniques, correlation functions, and a new "phase space plot," we show how desynchronization patterns (or lack thereof) can be readily identified from a data set that is much smaller than a full MPI trace. Our methods also lead the way towards a more general classification of parallel program dynamics.