 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Face Segmentation, Face Swapping, and Face Perception
Apr 22, 2017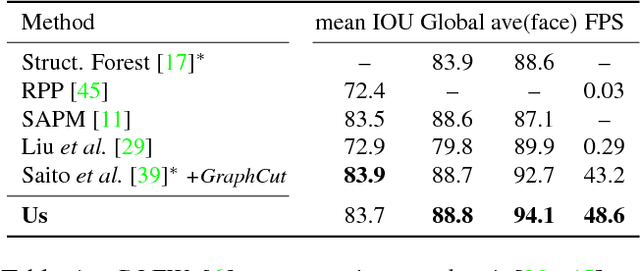

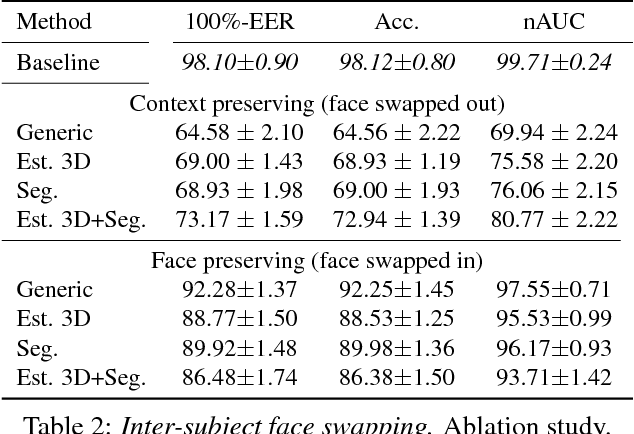
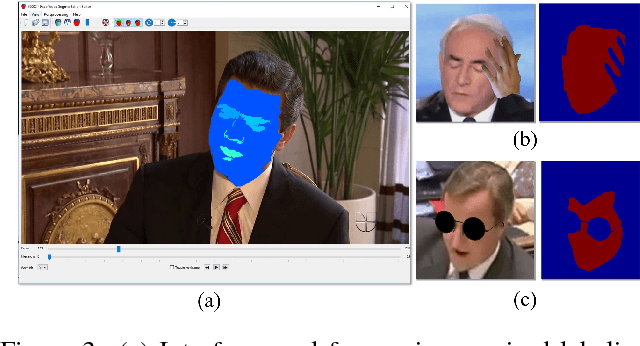
We show that even when face images are unconstrained and arbitrarily paired, face swapping between them is actually quite simple. To this end, we make the following contributions. (a) Instead of tailoring systems for face segmentation, as others previously proposed, we show that a standard fully convolutional network (FCN) can achieve remarkably fast and accurate segmentations, provided that it is trained on a rich enough example set. For this purpose, we describe novel data collection and generation routines which provide challenging segmented face examples. (b) We use our segmentations to enable robust face swapping under unprecedented conditions. (c) Unlike previous work, our swapping is robust enough to allow for extensive quantitative tests. To this end, we use the Labeled Faces in the Wild (LFW) benchmark and measure the effect of intra- and inter-subject face swapping on recognition. We show that our intra-subject swapped faces remain as recognizable as their sources, testifying to the effectiveness of our method. In line with well known perceptual studies, we show that better face swapping produces less recognizable inter-subject results. This is the first time this effect was quantitatively demonstrated for machine vision systems.
Deep 3D Face Identification
Mar 30, 2017
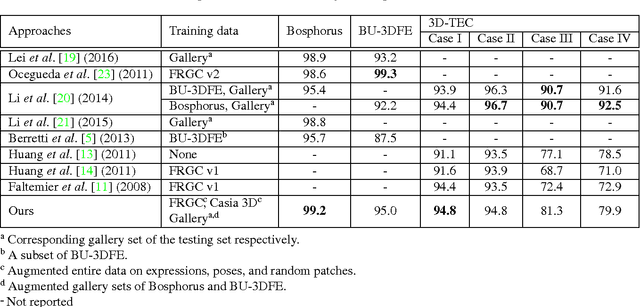
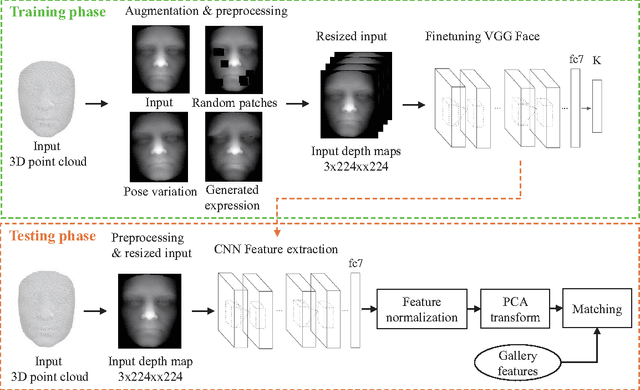
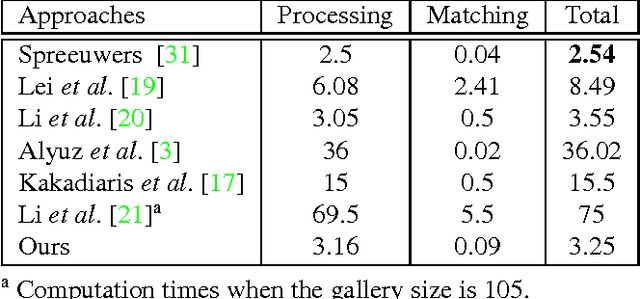
We propose a novel 3D face recognition algorithm using a deep convolutional neural network (DCNN) and a 3D augmentation technique. The performance of 2D face recognition algorithms has significantly increased by leveraging the representational power of deep neural networks and the use of large-scale labeled training data. As opposed to 2D face recognition, training discriminative deep features for 3D face recognition is very difficult due to the lack of large-scale 3D face datasets. In this paper, we show that transfer learning from a CNN trained on 2D face images can effectively work for 3D face recognition by fine-tuning the CNN with a relatively small number of 3D facial scans. We also propose a 3D face augmentation technique which synthesizes a number of different facial expressions from a single 3D face scan. Our proposed method shows excellent recognition results on Bosphorus, BU-3DFE, and 3D-TEC datasets, without using hand-crafted features. The 3D identification using our deep features also scales well for large databases.
Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network
Dec 15, 2016
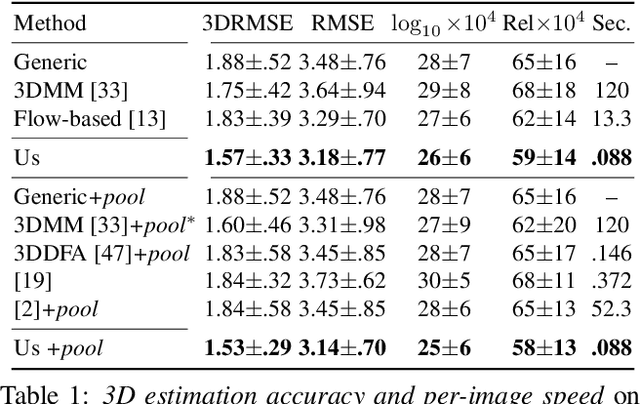
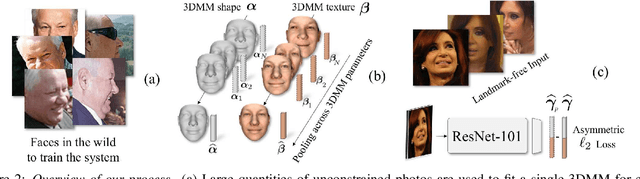
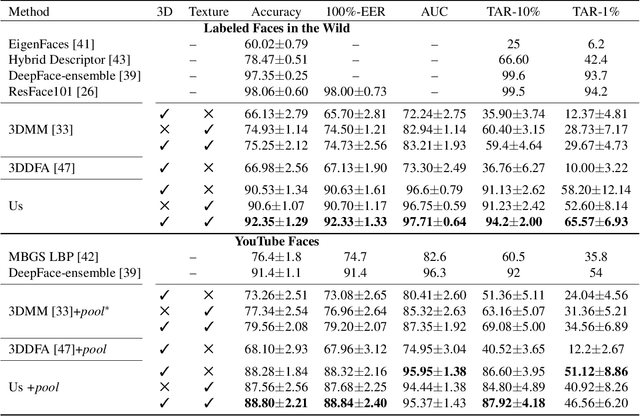
The 3D shapes of faces are well known to be discriminative. Yet despite this, they are rarely used for face recognition and always under controlled viewing conditions. We claim that this is a symptom of a serious but often overlooked problem with existing methods for single view 3D face reconstruction: when applied "in the wild", their 3D estimates are either unstable and change for different photos of the same subject or they are over-regularized and generic. In response, we describe a robust method for regressing discriminative 3D morphable face models (3DMM). We use a convolutional neural network (CNN) to regress 3DMM shape and texture parameters directly from an input photo. We overcome the shortage of training data required for this purpose by offering a method for generating huge numbers of labeled examples. The 3D estimates produced by our CNN surpass state of the art accuracy on the MICC data set. Coupled with a 3D-3D face matching pipeline, we show the first competitive face recognition results on the LFW, YTF and IJB-A benchmarks using 3D face shapes as representations, rather than the opaque deep feature vectors used by other modern systems.
Graph-Based Manifold Frequency Analysis for Denoising
Nov 29, 2016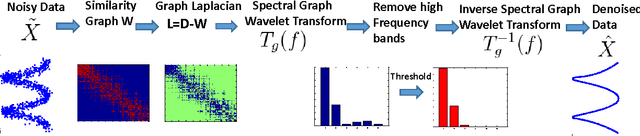


We propose a new framework for manifold denoising based on processing in the graph Fourier frequency domain, derived from the spectral decomposition of the discrete graph Laplacian. Our approach uses the Spectral Graph Wavelet transform in order to per- form non-iterative denoising directly in the graph frequency domain, an approach inspired by conventional wavelet-based signal denoising methods. We theoretically justify our approach, based on the fact that for smooth manifolds the coordinate information energy is localized in the low spectral graph wavelet sub-bands, while the noise affects all frequency bands in a similar way. Experimental results show that our proposed manifold frequency denoising (MFD) approach significantly outperforms the state of the art denoising meth- ods, and is robust to a wide range of parameter selections, e.g., the choice of k nearest neighbor connectivity of the graph.
Pooling Faces: Template based Face Recognition with Pooled Face Images
Jul 06, 2016

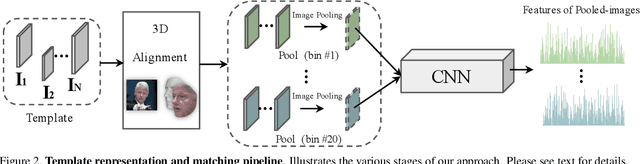
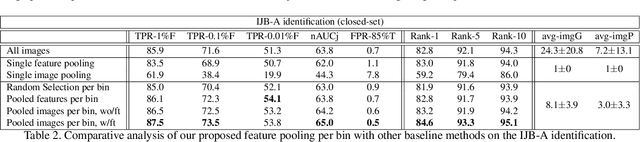
We propose a novel approach to template based face recognition. Our dual goal is to both increase recognition accuracy and reduce the computational and storage costs of template matching. To do this, we leverage on an approach which was proven effective in many other domains, but, to our knowledge, never fully explored for face images: average pooling of face photos. We show how (and why!) the space of a template's images can be partitioned and then pooled based on image quality and head pose and the effect this has on accuracy and template size. We perform extensive tests on the IJB-A and Janus CS2 template based face identification and verification benchmarks. These show that not only does our approach outperform published state of the art despite requiring far fewer cross template comparisons, but also, surprisingly, that image pooling performs on par with deep feature pooling.
Capturing Dynamic Textured Surfaces of Moving Targets
Apr 11, 2016

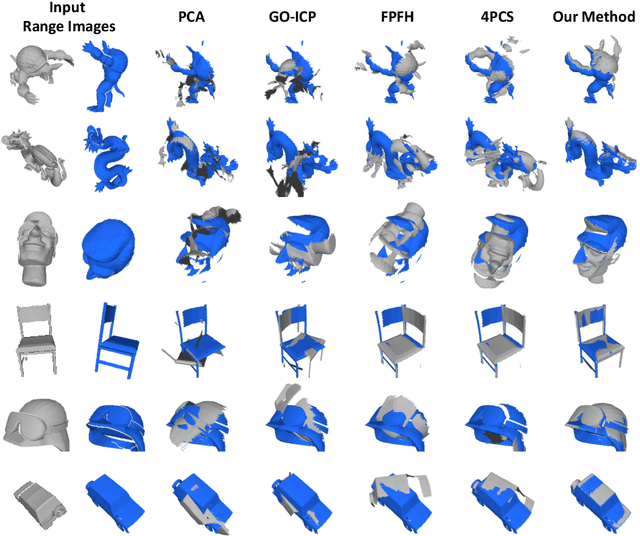
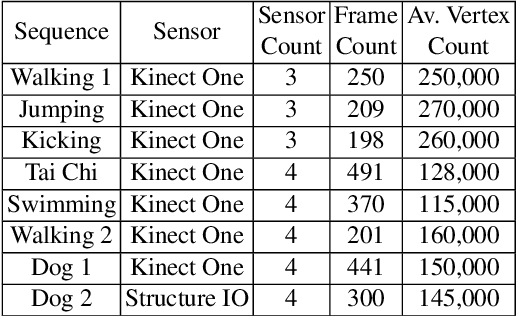
We present an end-to-end system for reconstructing complete watertight and textured models of moving subjects such as clothed humans and animals, using only three or four handheld sensors. The heart of our framework is a new pairwise registration algorithm that minimizes, using a particle swarm strategy, an alignment error metric based on mutual visibility and occlusion. We show that this algorithm reliably registers partial scans with as little as 15% overlap without requiring any initial correspondences, and outperforms alternative global registration algorithms. This registration algorithm allows us to reconstruct moving subjects from free-viewpoint video produced by consumer-grade sensors, without extensive sensor calibration, constrained capture volume, expensive arrays of cameras, or templates of the subject geometry.
Do We Really Need to Collect Millions of Faces for Effective Face Recognition?
Apr 11, 2016
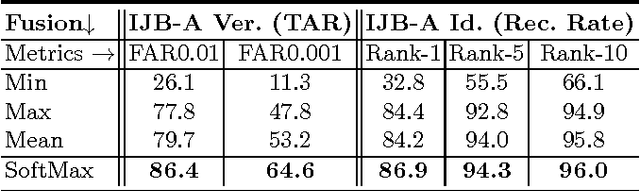

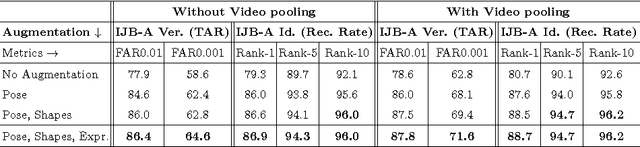
Face recognition capabilities have recently made extraordinary leaps. Though this progress is at least partially due to ballooning training set sizes -- huge numbers of face images downloaded and labeled for identity -- it is not clear if the formidable task of collecting so many images is truly necessary. We propose a far more accessible means of increasing training data sizes for face recognition systems. Rather than manually harvesting and labeling more faces, we simply synthesize them. We describe novel methods of enriching an existing dataset with important facial appearance variations by manipulating the faces it contains. We further apply this synthesis approach when matching query images represented using a standard convolutional neural network. The effect of training and testing with synthesized images is extensively tested on the LFW and IJB-A (verification and identification) benchmarks and Janus CS2. The performances obtained by our approach match state of the art results reported by systems trained on millions of downloaded images.
Exploring Local Context for Multi-target Tracking in Wide Area Aerial Surveillance
Mar 28, 2016
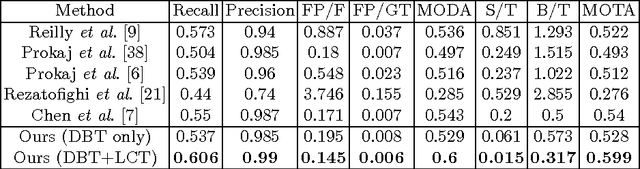
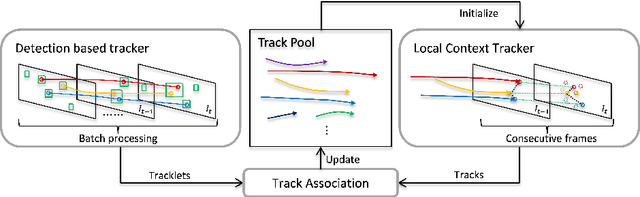
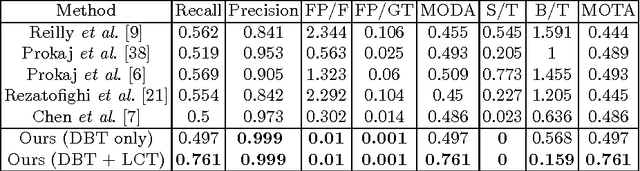
Tracking many vehicles in wide coverage aerial imagery is crucial for understanding events in a large field of view. Most approaches aim to associate detections from frame differencing into tracks. However, slow or stopped vehicles result in long-term missing detections and further cause tracking discontinuities. Relying merely on appearance clue to recover missing detections is difficult as targets are extremely small and in grayscale. In this paper, we address the limitations of detection association methods by coupling it with a local context tracker (LCT), which does not rely on motion detections. On one hand, our LCT learns neighboring spatial relation and tracks each target in consecutive frames using graph optimization. It takes the advantage of context constraints to avoid drifting to nearby targets. We generate hypotheses from sparse and dense flow efficiently to keep solutions tractable. On the other hand, we use detection association strategy to extract short tracks in batch processing. We explicitly handle merged detections by generating additional hypotheses from them. Our evaluation on wide area aerial imagery sequences shows significant improvement over state-of-the-art methods.
Face Recognition Using Deep Multi-Pose Representations
Mar 23, 2016
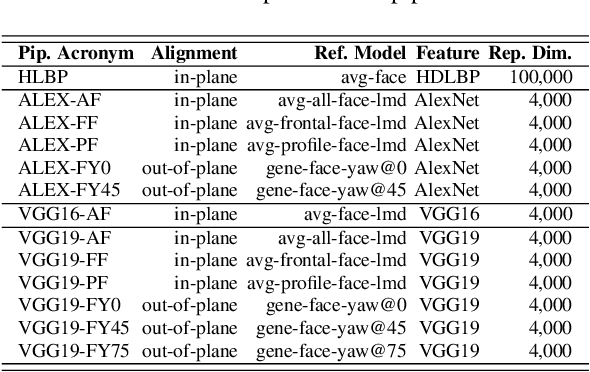
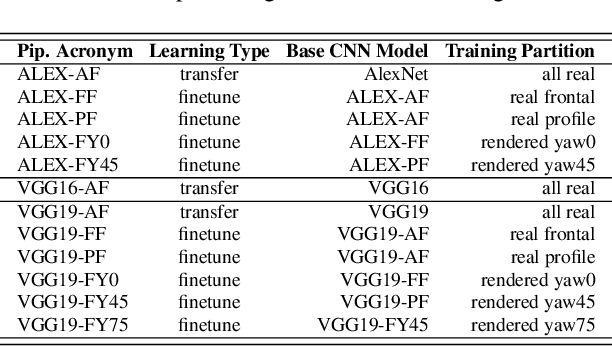
We introduce our method and system for face recognition using multiple pose-aware deep learning models. In our representation, a face image is processed by several pose-specific deep convolutional neural network (CNN) models to generate multiple pose-specific features. 3D rendering is used to generate multiple face poses from the input image. Sensitivity of the recognition system to pose variations is reduced since we use an ensemble of pose-specific CNN features. The paper presents extensive experimental results on the effect of landmark detection, CNN layer selection and pose model selection on the performance of the recognition pipeline. Our novel representation achieves better results than the state-of-the-art on IARPA's CS2 and NIST's IJB-A in both verification and identification (i.e. search) tasks.
Facial Landmark Detection with Tweaked Convolutional Neural Networks
Mar 21, 2016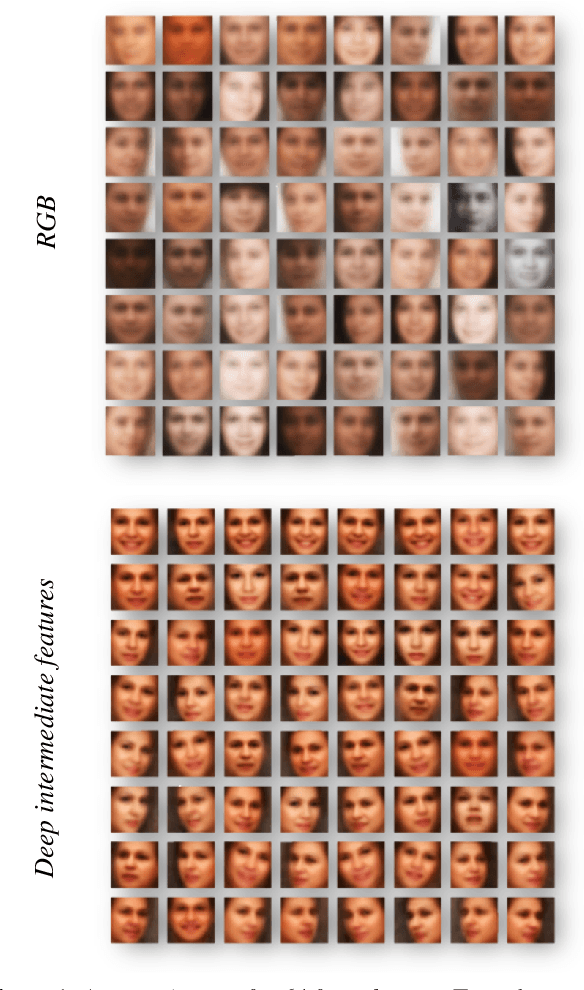


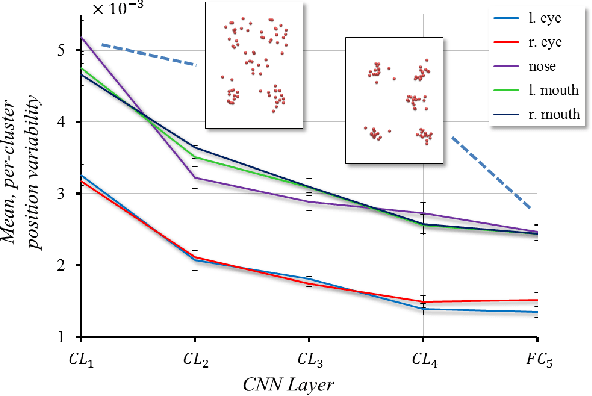
We present a novel convolutional neural network (CNN) design for facial landmark coordinate regression. We examine the intermediate features of a standard CNN trained for landmark detection and show that features extracted from later, more specialized layers capture rough landmark locations. This provides a natural means of applying differential treatment midway through the network, tweaking processing based on facial alignment. The resulting Tweaked CNN model (TCNN) harnesses the robustness of CNNs for landmark detection, in an appearance-sensitive manner without training multi-part or multi-scale models. Our results on standard face landmark detection and face verification benchmarks show TCNN to surpasses previously published performances by wide margins.