 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel-based Reconstruction of Graph Signals
May 23, 2016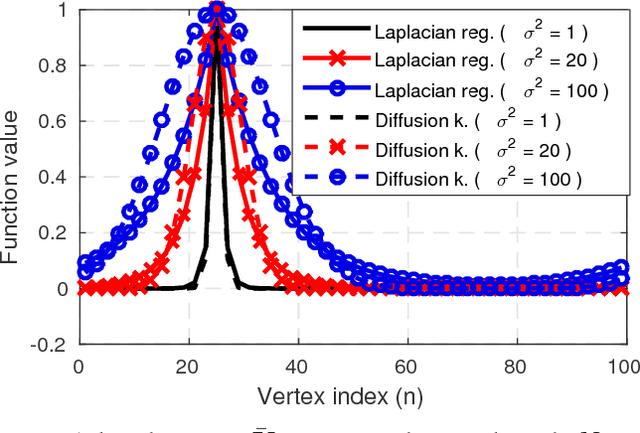
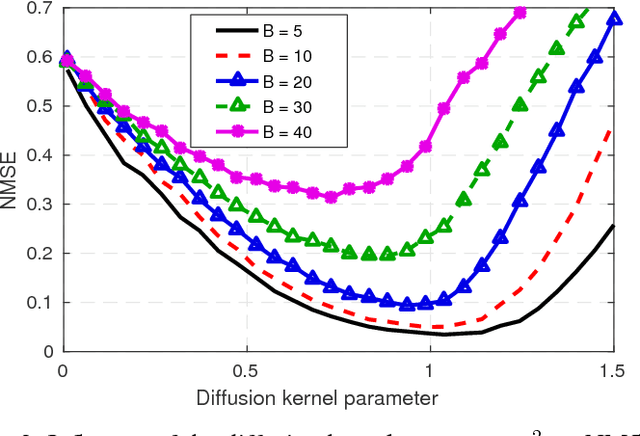
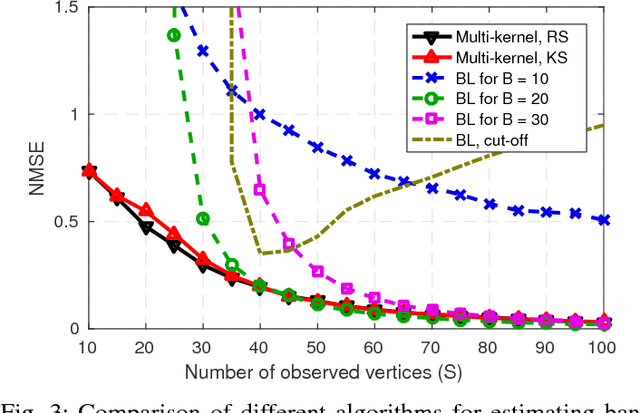
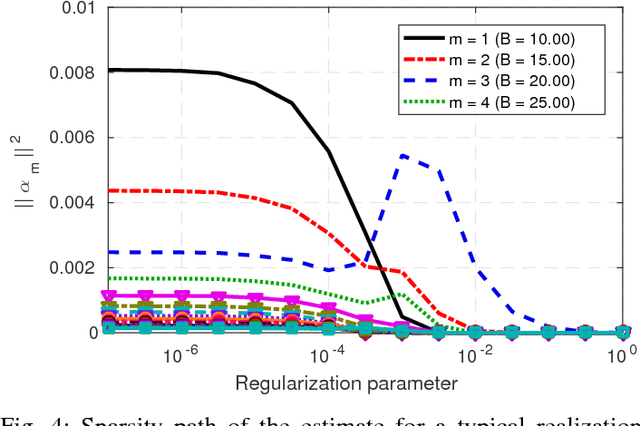
A number of applications in engineering, social sciences, physics, and biology involve inference over networks. In this context, graph signals are widely encountered as descriptors of vertex attributes or features in graph-structured data. Estimating such signals in all vertices given noisy observations of their values on a subset of vertices has been extensively analyzed in the literature of signal processing on graphs (SPoG). This paper advocates kernel regression as a framework generalizing popular SPoG modeling and reconstruction and expanding their capabilities. Formulating signal reconstruction as a regression task on reproducing kernel Hilbert spaces of graph signals permeates benefits from statistical learning, offers fresh insights, and allows for estimators to leverage richer forms of prior information than existing alternatives. A number of SPoG notions such as bandlimitedness, graph filters, and the graph Fourier transform are naturally accommodated in the kernel framework. Additionally, this paper capitalizes on the so-called representer theorem to devise simpler versions of existing Thikhonov regularized estimators, and offers a novel probabilistic interpretation of kernel methods on graphs based on graphical models. Motivated by the challenges of selecting the bandwidth parameter in SPoG estimators or the kernel map in kernel-based methods, the present paper further proposes two multi-kernel approaches with complementary strengths. Whereas the first enables estimation of the unknown bandwidth of bandlimited signals, the second allows for efficient graph filter selection. Numerical tests with synthetic as well as real data demonstrate the merits of the proposed methods relative to state-of-the-art alternatives.
Kernel-Based Structural Equation Models for Topology Identification of Directed Networks
May 10, 2016

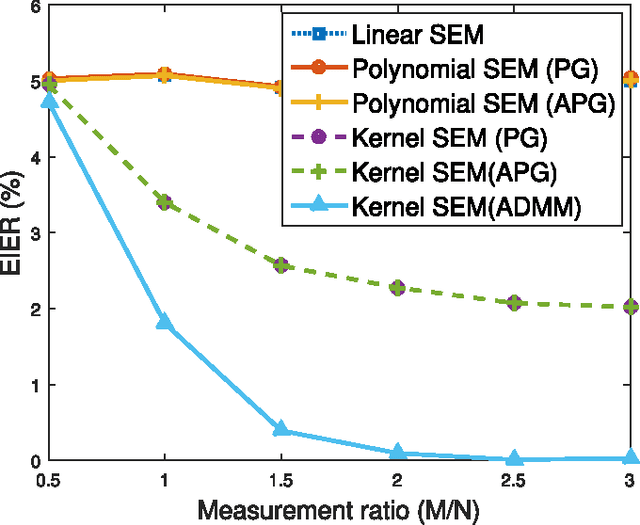
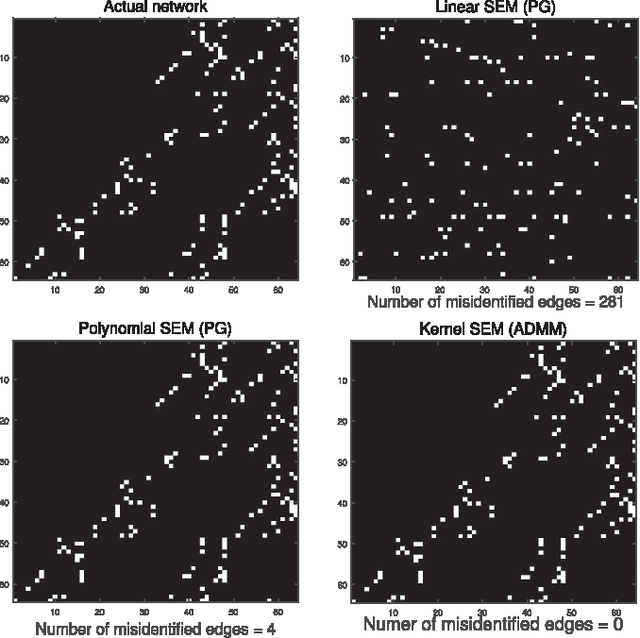
Structural equation models (SEMs) have been widely adopted for inference of causal interactions in complex networks. Recent examples include unveiling topologies of hidden causal networks over which processes such as spreading diseases, or rumors propagate. The appeal of SEMs in these settings stems from their simplicity and tractability, since they typically assume linear dependencies among observable variables. Acknowledging the limitations inherent to adopting linear models, the present paper advocates nonlinear SEMs, which account for (possible) nonlinear dependencies among network nodes. The advocated approach leverages kernels as a powerful encompassing framework for nonlinear modeling, and an efficient estimator with affordable tradeoffs is put forth. Interestingly, pursuit of the novel kernel-based approach yields a convex regularized estimator that promotes edge sparsity, and is amenable to proximal-splitting optimization methods. To this end, solvers with complementary merits are developed by leveraging the alternating direction method of multipliers, and proximal gradient iterations. Experiments conducted on simulated data demonstrate that the novel approach outperforms linear SEMs with respect to edge detection errors. Furthermore, tests on a real gene expression dataset unveil interesting new edges that were not revealed by linear SEMs, which could shed more light on regulatory behavior of human genes.
Backhaul-Constrained Multi-Cell Cooperation Leveraging Sparsity and Spectral Clustering
Oct 14, 2015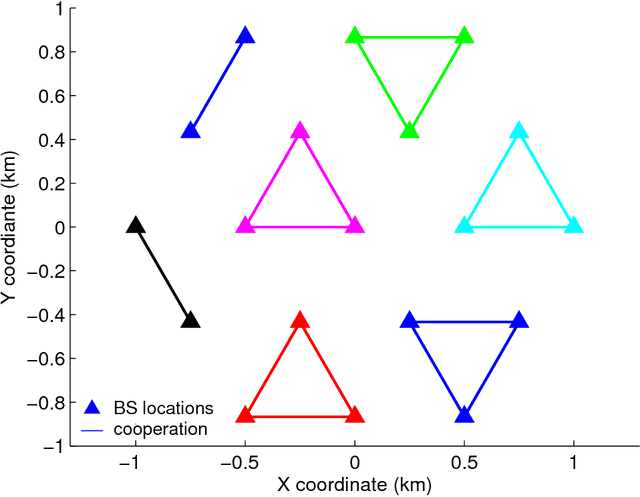
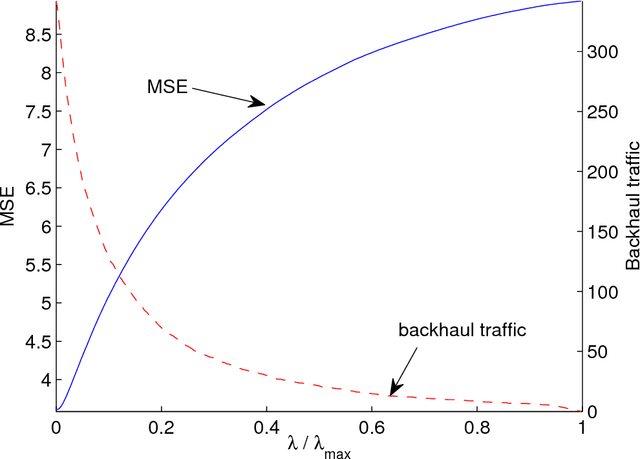
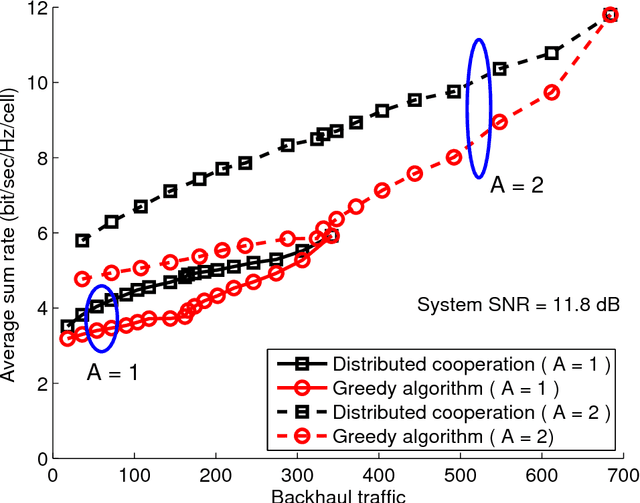
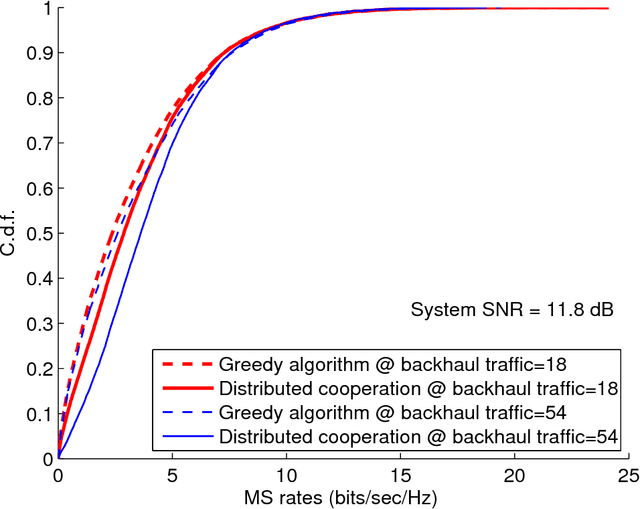
Multi-cell cooperative processing with limited backhaul traffic is studied for cellular uplinks. Aiming at reduced backhaul overhead, a sparsity-regularized multi-cell receive-filter design problem is formulated. Both unstructured distributed cooperation as well as clustered cooperation, in which base station groups are formed for tight cooperation, are considered. Dynamic clustered cooperation, where the sparse equalizer and the cooperation clusters are jointly determined, is solved via alternating minimization based on spectral clustering and group-sparse regression. Furthermore, decentralized implementations of both unstructured and clustered cooperation schemes are developed for scalability, robustness and computational efficiency. Extensive numerical tests verify the efficacy of the proposed methods.
Large-scale subspace clustering using sketching and validation
Oct 06, 2015



The nowadays massive amounts of generated and communicated data present major challenges in their processing. While capable of successfully classifying nonlinearly separable objects in various settings, subspace clustering (SC) methods incur prohibitively high computational complexity when processing large-scale data. Inspired by the random sampling and consensus (RANSAC) approach to robust regression, the present paper introduces a randomized scheme for SC, termed sketching and validation (SkeVa-)SC, tailored for large-scale data. At the heart of SkeVa-SC lies a randomized scheme for approximating the underlying probability density function of the observed data by kernel smoothing arguments. Sparsity in data representations is also exploited to reduce the computational burden of SC, while achieving high clustering accuracy. Performance analysis as well as extensive numerical tests on synthetic and real data corroborate the potential of SkeVa-SC and its competitive performance relative to state-of-the-art scalable SC approaches. Keywords: Subspace clustering, big data, kernel smoothing, randomization, sketching, validation, sparsity.
Online Censoring for Large-Scale Regressions with Application to Streaming Big Data
Jul 27, 2015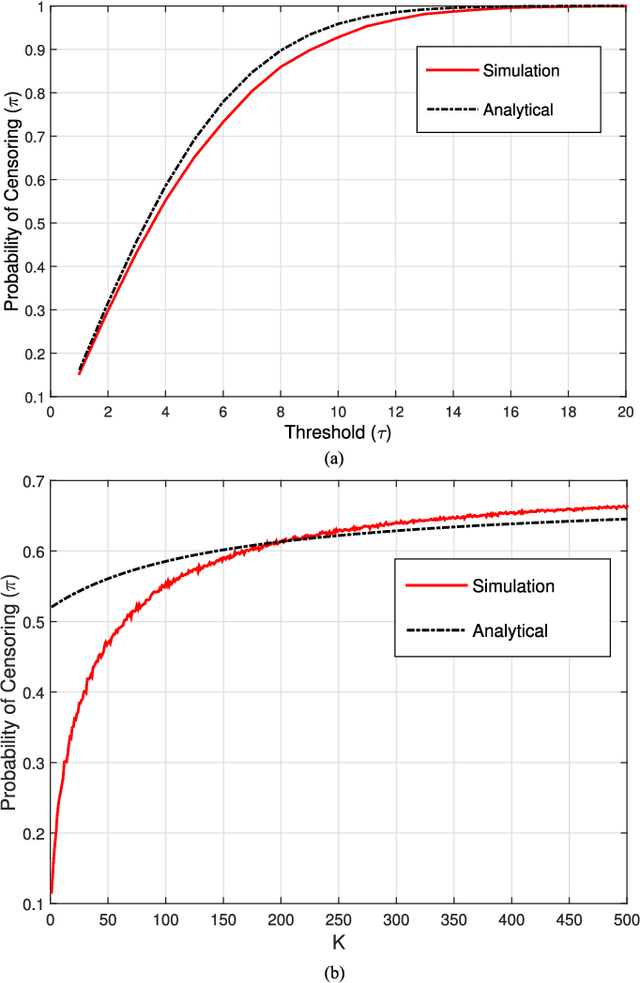
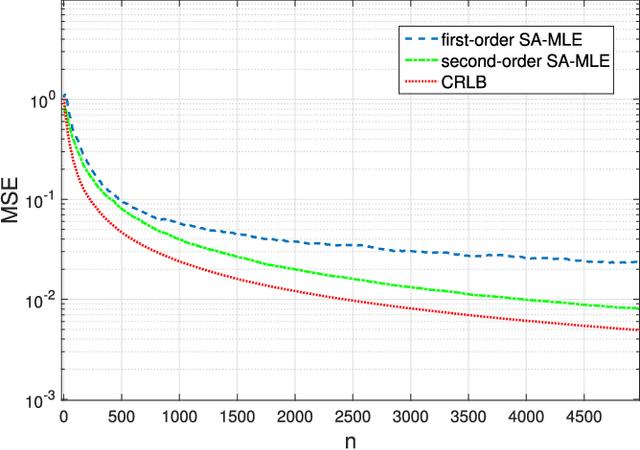
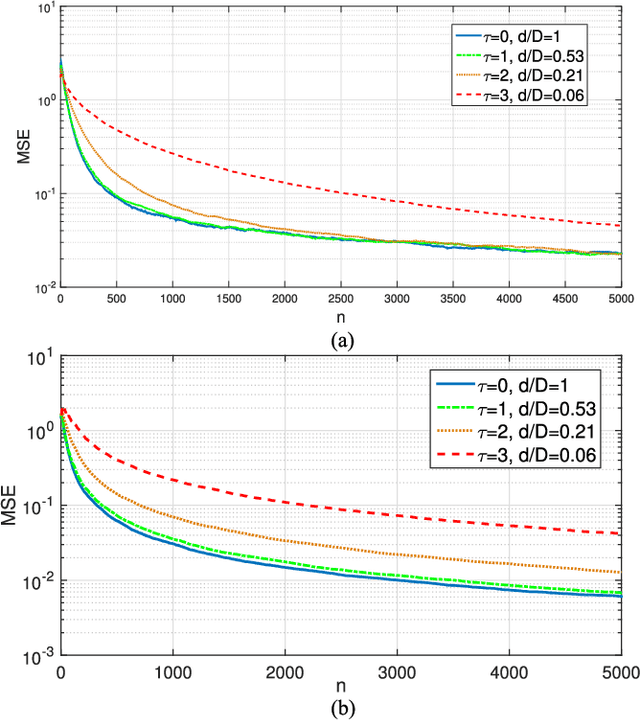
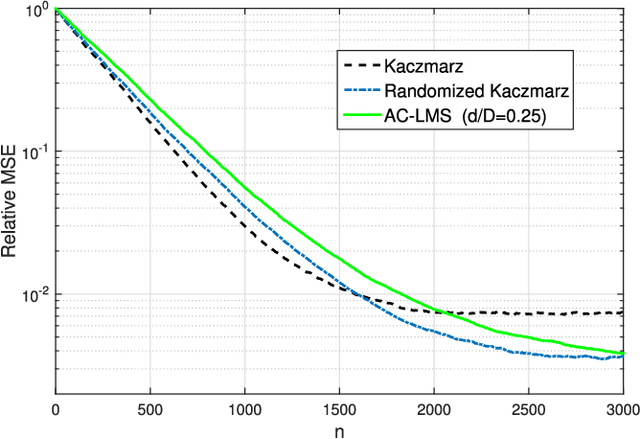
Linear regression is arguably the most prominent among statistical inference methods, popular both for its simplicity as well as its broad applicability. On par with data-intensive applications, the sheer size of linear regression problems creates an ever growing demand for quick and cost efficient solvers. Fortunately, a significant percentage of the data accrued can be omitted while maintaining a certain quality of statistical inference with an affordable computational budget. The present paper introduces means of identifying and omitting "less informative" observations in an online and data-adaptive fashion, built on principles of stochastic approximation and data censoring. First- and second-order stochastic approximation maximum likelihood-based algorithms for censored observations are developed for estimating the regression coefficients. Online algorithms are also put forth to reduce the overall complexity by adaptively performing censoring along with estimation. The novel algorithms entail simple closed-form updates, and have provable (non)asymptotic convergence guarantees. Furthermore, specific rules are investigated for tuning to desired censoring patterns and levels of dimensionality reduction. Simulated tests on real and synthetic datasets corroborate the efficacy of the proposed data-adaptive methods compared to data-agnostic random projection-based alternatives.
Joint community and anomaly tracking in dynamic networks
Jun 25, 2015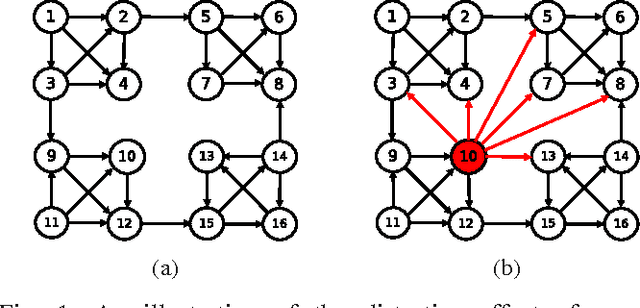
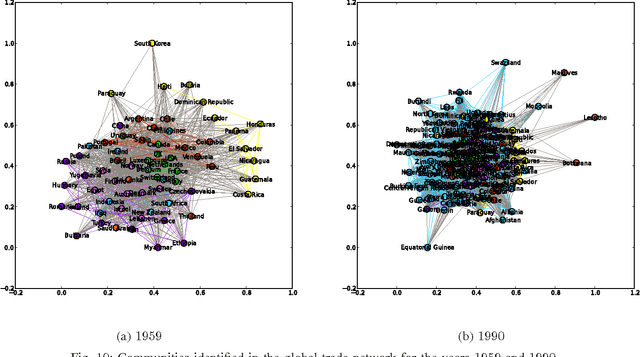
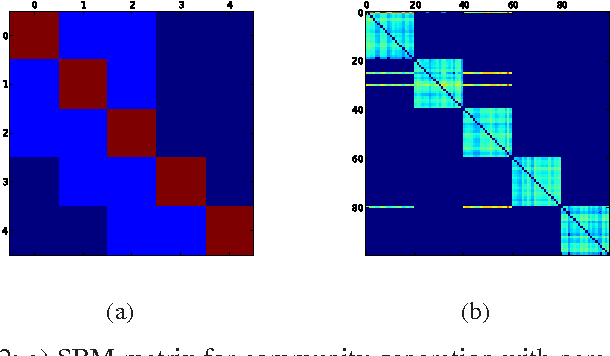
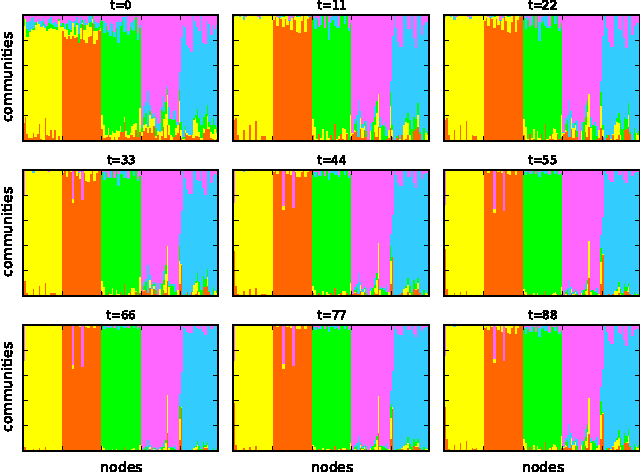
Most real-world networks exhibit community structure, a phenomenon characterized by existence of node clusters whose intra-edge connectivity is stronger than edge connectivities between nodes belonging to different clusters. In addition to facilitating a better understanding of network behavior, community detection finds many practical applications in diverse settings. Communities in online social networks are indicative of shared functional roles, or affiliation to a common socio-economic status, the knowledge of which is vital for targeted advertisement. In buyer-seller networks, community detection facilitates better product recommendations. Unfortunately, reliability of community assignments is hindered by anomalous user behavior often observed as unfair self-promotion, or "fake" highly-connected accounts created to promote fraud. The present paper advocates a novel approach for jointly tracking communities while detecting such anomalous nodes in time-varying networks. By postulating edge creation as the result of mutual community participation by node pairs, a dynamic factor model with anomalous memberships captured through a sparse outlier matrix is put forth. Efficient tracking algorithms suitable for both online and decentralized operation are developed. Experiments conducted on both synthetic and real network time series successfully unveil underlying communities and anomalous nodes.
Decentralized learning for wireless communications and networking
Mar 30, 2015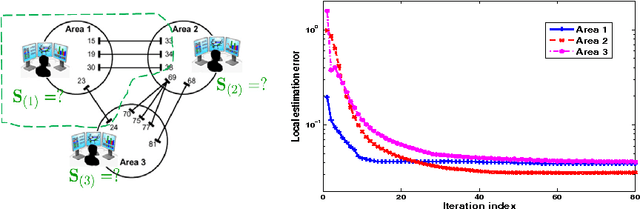
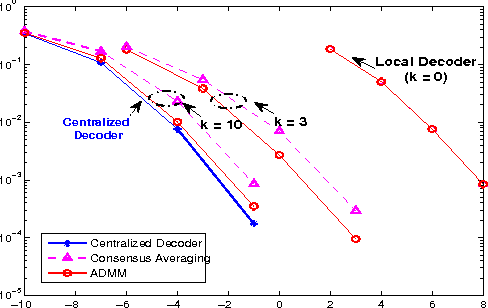
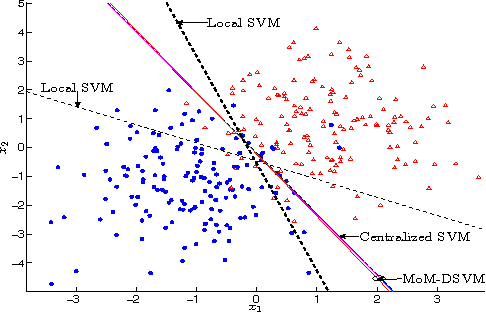
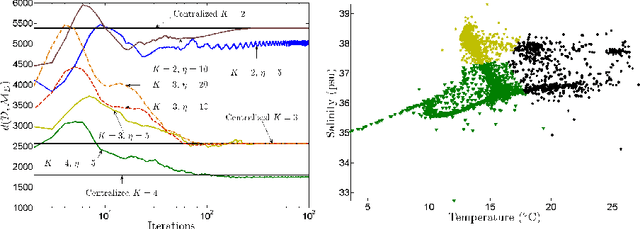
This chapter deals with decentralized learning algorithms for in-network processing of graph-valued data. A generic learning problem is formulated and recast into a separable form, which is iteratively minimized using the alternating-direction method of multipliers (ADMM) so as to gain the desired degree of parallelization. Without exchanging elements from the distributed training sets and keeping inter-node communications at affordable levels, the local (per-node) learners consent to the desired quantity inferred globally, meaning the one obtained if the entire training data set were centrally available. Impact of the decentralized learning framework to contemporary wireless communications and networking tasks is illustrated through case studies including target tracking using wireless sensor networks, unveiling Internet traffic anomalies, power system state estimation, as well as spectrum cartography for wireless cognitive radio networks.
Sketch and Validate for Big Data Clustering
Jan 22, 2015
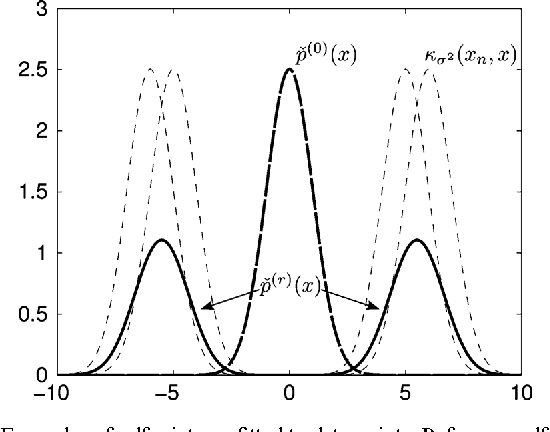


In response to the need for learning tools tuned to big data analytics, the present paper introduces a framework for efficient clustering of huge sets of (possibly high-dimensional) data. Building on random sampling and consensus (RANSAC) ideas pursued earlier in a different (computer vision) context for robust regression, a suite of novel dimensionality and set-reduction algorithms is developed. The advocated sketch-and-validate (SkeVa) family includes two algorithms that rely on K-means clustering per iteration on reduced number of dimensions and/or feature vectors: The first operates in a batch fashion, while the second sequential one offers computational efficiency and suitability with streaming modes of operation. For clustering even nonlinearly separable vectors, the SkeVa family offers also a member based on user-selected kernel functions. Further trading off performance for reduced complexity, a fourth member of the SkeVa family is based on a divergence criterion for selecting proper minimal subsets of feature variables and vectors, thus bypassing the need for K-means clustering per iteration. Extensive numerical tests on synthetic and real data sets highlight the potential of the proposed algorithms, and demonstrate their competitive performance relative to state-of-the-art random projection alternatives.
Online Energy Price Matrix Factorization for Power Grid Topology Tracking
Oct 22, 2014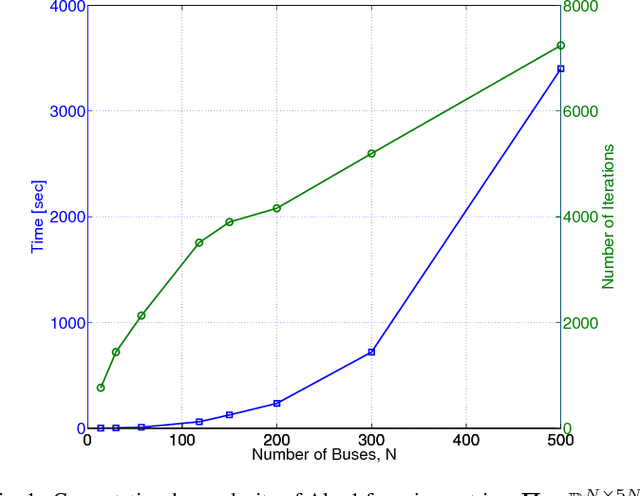
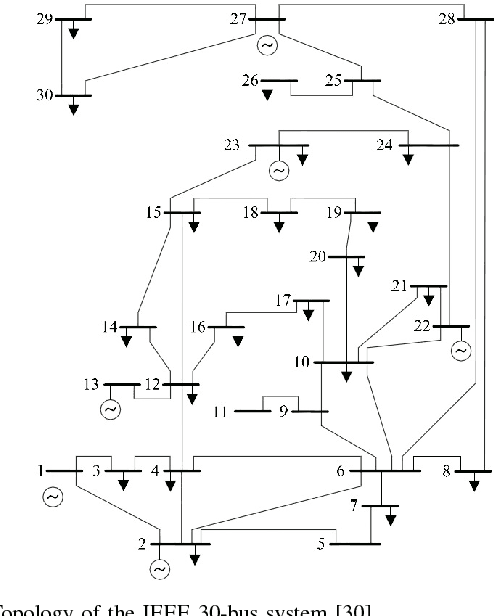
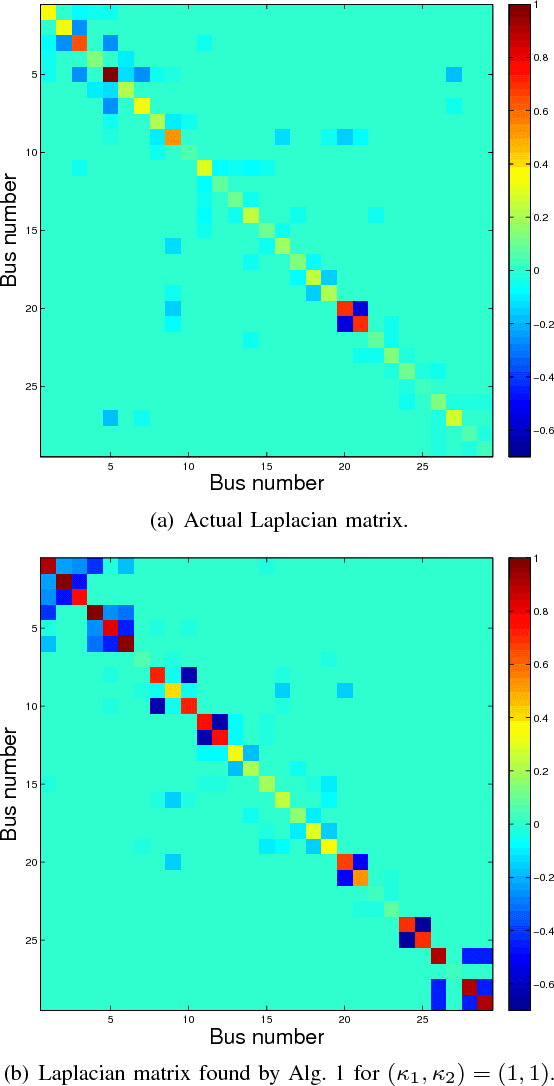
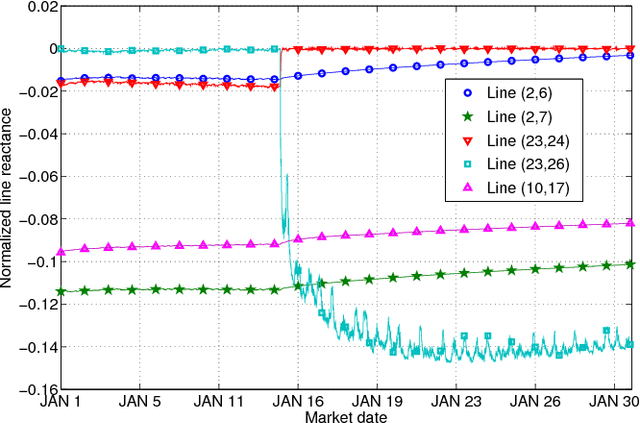
Grid security and open markets are two major smart grid goals. Transparency of market data facilitates a competitive and efficient energy environment, yet it may also reveal critical physical system information. Recovering the grid topology based solely on publicly available market data is explored here. Real-time energy prices are calculated as the Lagrange multipliers of network-constrained economic dispatch; that is, via a linear program (LP) typically solved every 5 minutes. Granted the grid Laplacian is a parameter of this LP, one could infer such a topology-revealing matrix upon observing successive LP dual outcomes. The matrix of spatio-temporal prices is first shown to factor as the product of the inverse Laplacian times a sparse matrix. Leveraging results from sparse matrix decompositions, topology recovery schemes with complementary strengths are subsequently formulated. Solvers scalable to high-dimensional and streaming market data are devised. Numerical validation using real load data on the IEEE 30-bus grid provide useful input for current and future market designs.
Subspace Learning and Imputation for Streaming Big Data Matrices and Tensors
Apr 17, 2014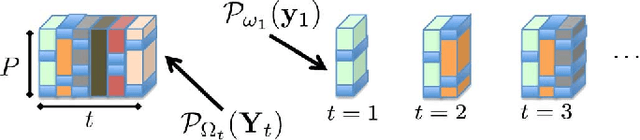
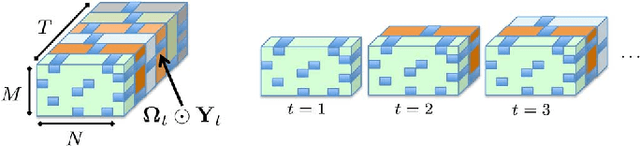
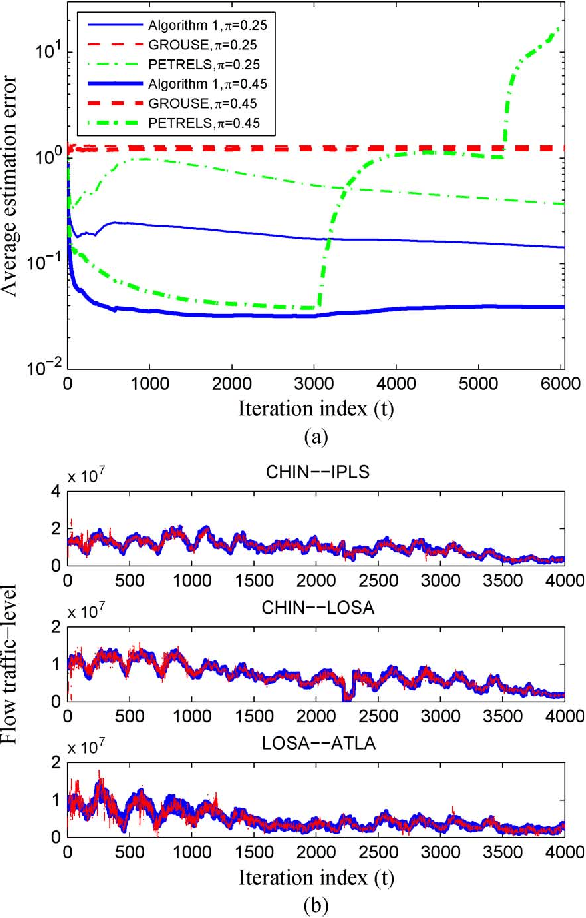
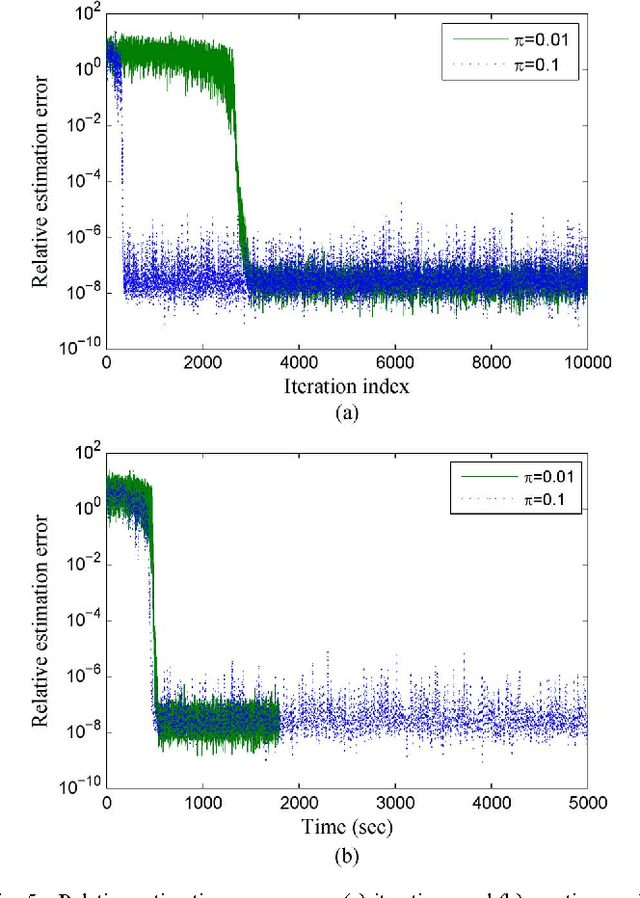
Extracting latent low-dimensional structure from high-dimensional data is of paramount importance in timely inference tasks encountered with `Big Data' analytics. However, increasingly noisy, heterogeneous, and incomplete datasets as well as the need for {\em real-time} processing of streaming data pose major challenges to this end. In this context, the present paper permeates benefits from rank minimization to scalable imputation of missing data, via tracking low-dimensional subspaces and unraveling latent (possibly multi-way) structure from \emph{incomplete streaming} data. For low-rank matrix data, a subspace estimator is proposed based on an exponentially-weighted least-squares criterion regularized with the nuclear norm. After recasting the non-separable nuclear norm into a form amenable to online optimization, real-time algorithms with complementary strengths are developed and their convergence is established under simplifying technical assumptions. In a stationary setting, the asymptotic estimates obtained offer the well-documented performance guarantees of the {\em batch} nuclear-norm regularized estimator. Under the same unifying framework, a novel online (adaptive) algorithm is developed to obtain multi-way decompositions of \emph{low-rank tensors} with missing entries, and perform imputation as a byproduct. Simulated tests with both synthetic as well as real Internet and cardiac magnetic resonance imagery (MRI) data confirm the efficacy of the proposed algorithms, and their superior performance relative to state-of-the-art alternatives.