 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Linear Bandits with Adversarial Agents: Near-Optimal Regret Bounds
Jun 06, 2022
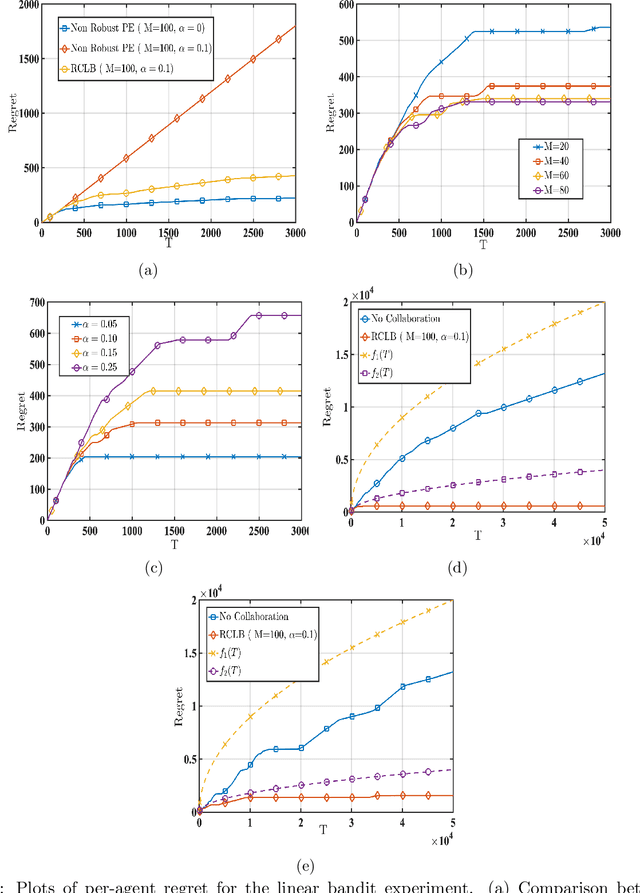
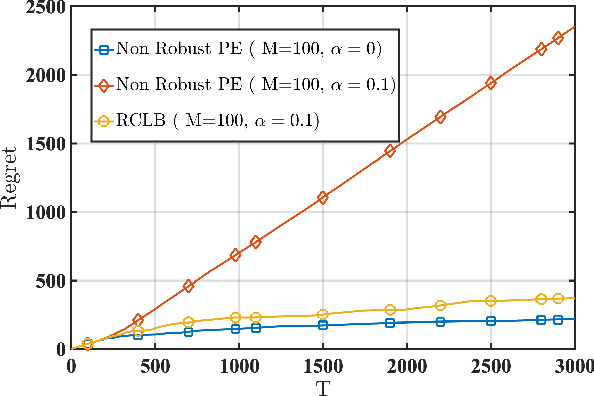
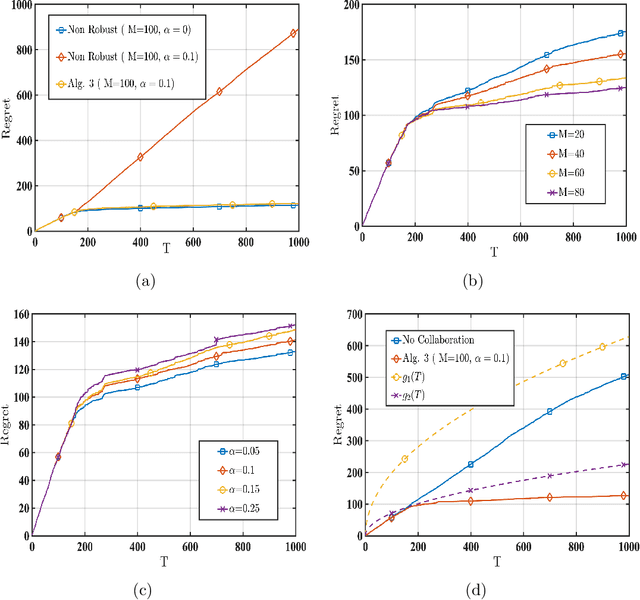
We consider a linear stochastic bandit problem involving $M$ agents that can collaborate via a central server to minimize regret. A fraction $\alpha$ of these agents are adversarial and can act arbitrarily, leading to the following tension: while collaboration can potentially reduce regret, it can also disrupt the process of learning due to adversaries. In this work, we provide a fundamental understanding of this tension by designing new algorithms that balance the exploration-exploitation trade-off via carefully constructed robust confidence intervals. We also complement our algorithms with tight analyses. First, we develop a robust collaborative phased elimination algorithm that achieves $\tilde{O}\left(\alpha+ 1/\sqrt{M}\right) \sqrt{dT}$ regret for each good agent; here, $d$ is the model-dimension and $T$ is the horizon. For small $\alpha$, our result thus reveals a clear benefit of collaboration despite adversaries. Using an information-theoretic argument, we then prove a matching lower bound, thereby providing the first set of tight, near-optimal regret bounds for collaborative linear bandits with adversaries. Furthermore, by leveraging recent advances in high-dimensional robust statistics, we significantly extend our algorithmic ideas and results to (i) the generalized linear bandit model that allows for non-linear observation maps; and (ii) the contextual bandit setting that allows for time-varying feature vectors.
Learning to Control Linear Systems can be Hard
May 27, 2022
In this paper, we study the statistical difficulty of learning to control linear systems. We focus on two standard benchmarks, the sample complexity of stabilization, and the regret of the online learning of the Linear Quadratic Regulator (LQR). Prior results state that the statistical difficulty for both benchmarks scales polynomially with the system state dimension up to system-theoretic quantities. However, this does not reveal the whole picture. By utilizing minimax lower bounds for both benchmarks, we prove that there exist non-trivial classes of systems for which learning complexity scales dramatically, i.e. exponentially, with the system dimension. This situation arises in the case of underactuated systems, i.e. systems with fewer inputs than states. Such systems are structurally difficult to control and their system theoretic quantities can scale exponentially with the system dimension dominating learning complexity. Under some additional structural assumptions (bounding systems away from uncontrollability), we provide qualitatively matching upper bounds. We prove that learning complexity can be at most exponential with the controllability index of the system, that is the degree of underactuation.
Reactive Informative Planning for Mobile Manipulation Tasks under Sensing and Environmental Uncertainty
May 12, 2022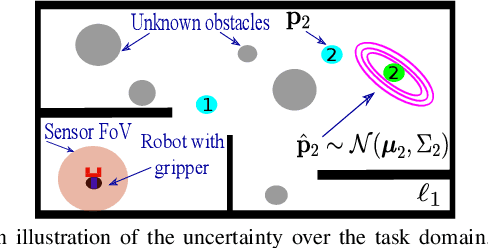
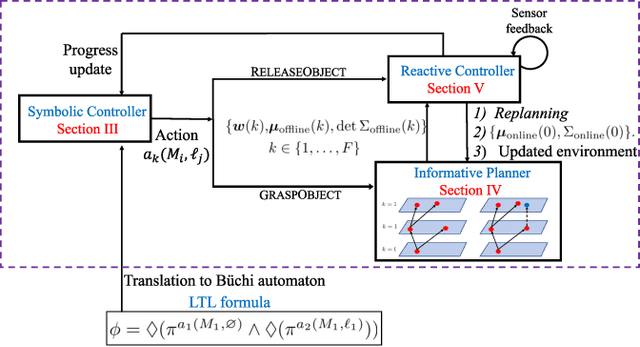
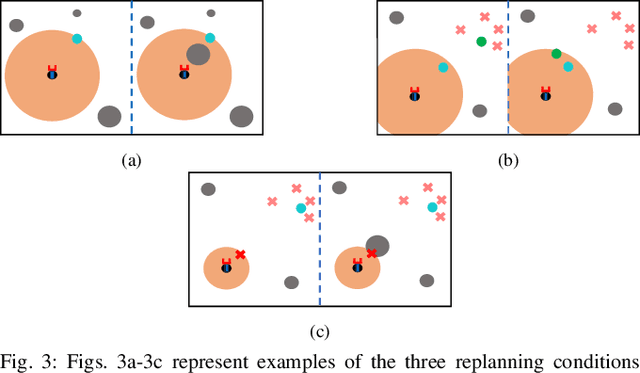
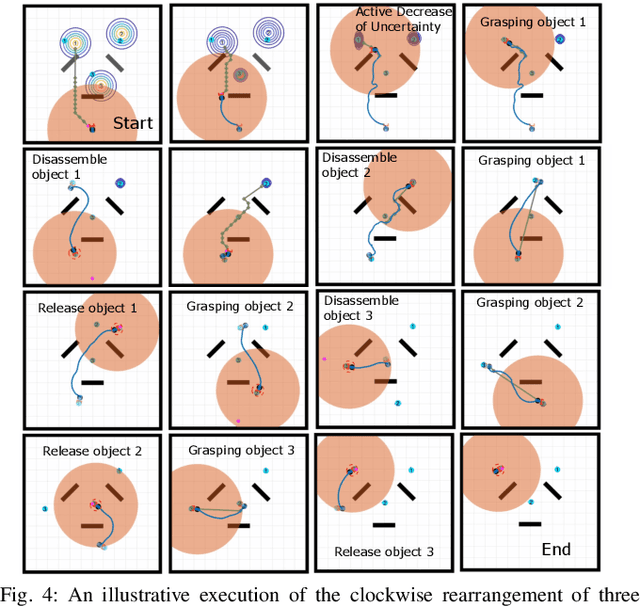
In this paper we address mobile manipulation planning problems in the presence of sensing and environmental uncertainty. In particular, we consider mobile sensing manipulators operating in environments with unknown geometry and uncertain movable objects, while being responsible for accomplishing tasks requiring grasping and releasing objects in a logical fashion. Existing algorithms either do not scale well or neglect sensing and/or environmental uncertainty. To face these challenges, we propose a hybrid control architecture, where a symbolic controller generates high-level manipulation commands (e.g., grasp an object) based on environmental feedback, an informative planner designs paths to actively decrease the uncertainty of objects of interest, and a continuous reactive controller tracks the sparse waypoints comprising the informative paths while avoiding a priori unknown obstacles. The overall architecture can handle environmental and sensing uncertainty online, as the robot explores its workspace. Using numerical simulations, we show that the proposed architecture can handle tasks of increased complexity while responding to unanticipated adverse configurations.
Distributed Statistical Min-Max Learning in the Presence of Byzantine Agents
Apr 07, 2022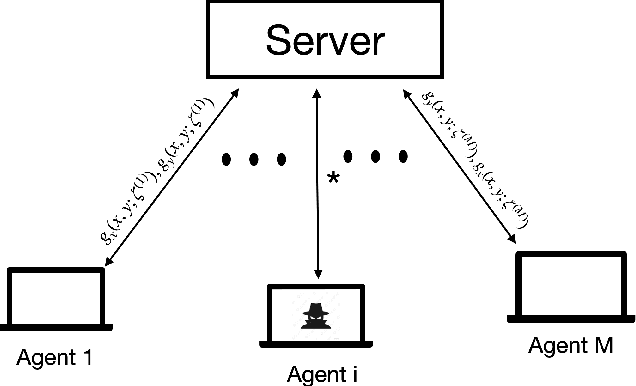
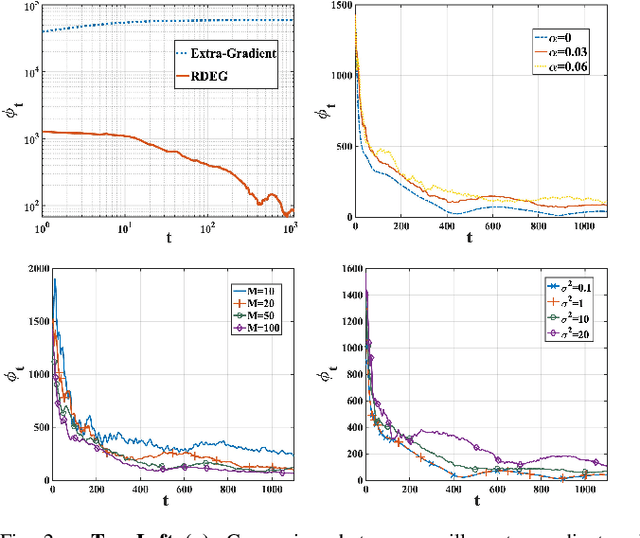
Recent years have witnessed a growing interest in the topic of min-max optimization, owing to its relevance in the context of generative adversarial networks (GANs), robust control and optimization, and reinforcement learning. Motivated by this line of work, we consider a multi-agent min-max learning problem, and focus on the emerging challenge of contending with worst-case Byzantine adversarial agents in such a setup. By drawing on recent results from robust statistics, we design a robust distributed variant of the extra-gradient algorithm - a popular algorithmic approach for min-max optimization. Our main contribution is to provide a crisp analysis of the proposed robust extra-gradient algorithm for smooth convex-concave and smooth strongly convex-strongly concave functions. Specifically, we establish statistical rates of convergence to approximate saddle points. Our rates are near-optimal, and reveal both the effect of adversarial corruption and the benefit of collaboration among the non-faulty agents. Notably, this is the first paper to provide formal theoretical guarantees for large-scale distributed min-max learning in the presence of adversarial agents.
Adaptive Stochastic MPC under Unknown Noise Distribution
Apr 03, 2022

In this paper, we address the stochastic MPC (SMPC) problem for linear systems, subject to chance state constraints and hard input constraints, under unknown noise distribution. First, we reformulate the chance state constraints as deterministic constraints depending only on explicit noise statistics. Based on these reformulated constraints, we design a distributionally robust and robustly stable benchmark SMPC algorithm for the ideal setting of known noise statistics. Then, we employ this benchmark controller to derive a novel robustly stable adaptive SMPC scheme that learns the necessary noise statistics online, while guaranteeing time-uniform satisfaction of the unknown reformulated state constraints with high probability. The latter is achieved through the use of confidence intervals which rely on the empirical noise statistics and are valid uniformly over time. Moreover, control performance is improved over time as more noise samples are gathered and better estimates of the noise statistics are obtained, given the online adaptation of the estimated reformulated constraints. Additionally, in tracking problems with multiple successive targets our approach leads to an online-enlarged domain of attraction compared to robust tube-based MPC. A numerical simulation of a DC-DC converter is used to demonstrate the effectiveness of the developed methodology.
Chordal Sparsity for Lipschitz Constant Estimation of Deep Neural Networks
Apr 02, 2022
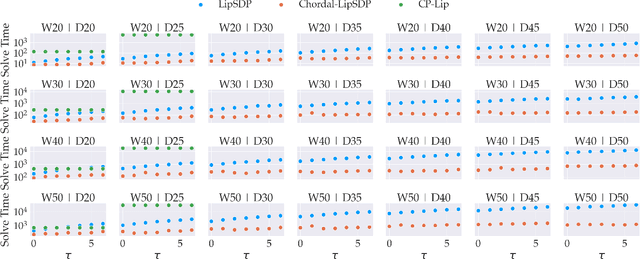
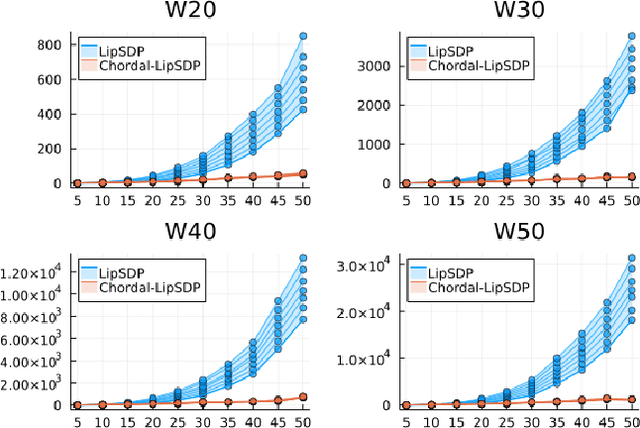
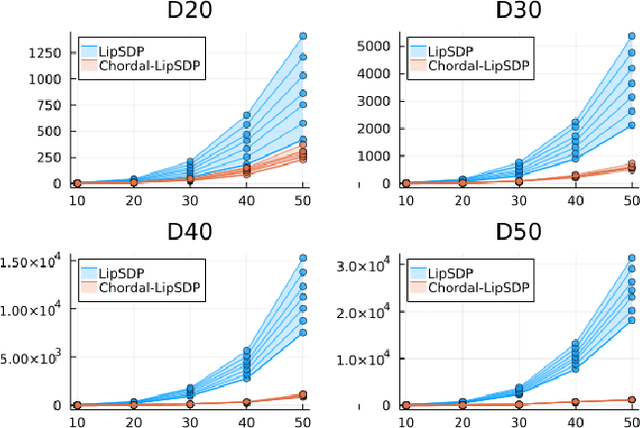
Lipschitz constants of neural networks allow for guarantees of robustness in image classification, safety in controller design, and generalizability beyond the training data. As calculating Lipschitz constants is NP-hard, techniques for estimating Lipschitz constants must navigate the trade-off between scalability and accuracy. In this work, we significantly push the scalability frontier of a semidefinite programming technique known as LipSDP while achieving zero accuracy loss. We first show that LipSDP has chordal sparsity, which allows us to derive a chordally sparse formulation that we call Chordal-LipSDP. The key benefit is that the main computational bottleneck of LipSDP, a large semidefinite constraint, is now decomposed into an equivalent collection of smaller ones: allowing Chordal-LipSDP to outperform LipSDP particularly as the network depth grows. Moreover, our formulation uses a tunable sparsity parameter that enables one to gain tighter estimates without incurring a significant computational cost. We illustrate the scalability of our approach through extensive numerical experiments.
Do Deep Networks Transfer Invariances Across Classes?
Mar 18, 2022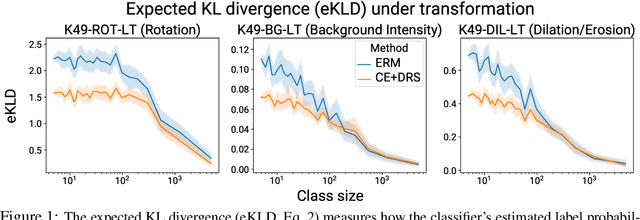
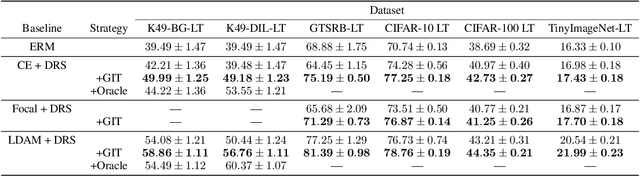
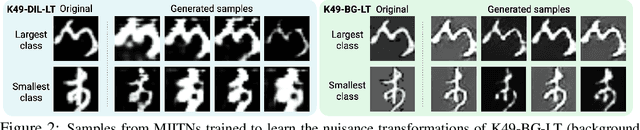
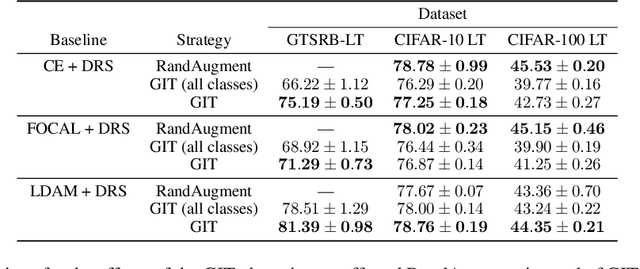
To generalize well, classifiers must learn to be invariant to nuisance transformations that do not alter an input's class. Many problems have "class-agnostic" nuisance transformations that apply similarly to all classes, such as lighting and background changes for image classification. Neural networks can learn these invariances given sufficient data, but many real-world datasets are heavily class imbalanced and contain only a few examples for most of the classes. We therefore pose the question: how well do neural networks transfer class-agnostic invariances learned from the large classes to the small ones? Through careful experimentation, we observe that invariance to class-agnostic transformations is still heavily dependent on class size, with the networks being much less invariant on smaller classes. This result holds even when using data balancing techniques, and suggests poor invariance transfer across classes. Our results provide one explanation for why classifiers generalize poorly on unbalanced and long-tailed distributions. Based on this analysis, we show how a generative approach for learning the nuisance transformations can help transfer invariances across classes and improve performance on a set of imbalanced image classification benchmarks. Source code for our experiments is available at https://github.com/AllanYangZhou/generative-invariance-transfer.
Linear Stochastic Bandits over a Bit-Constrained Channel
Mar 02, 2022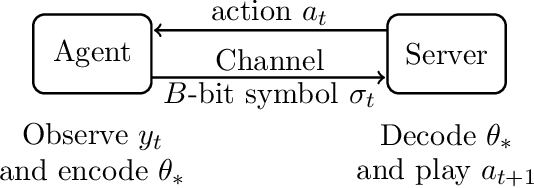
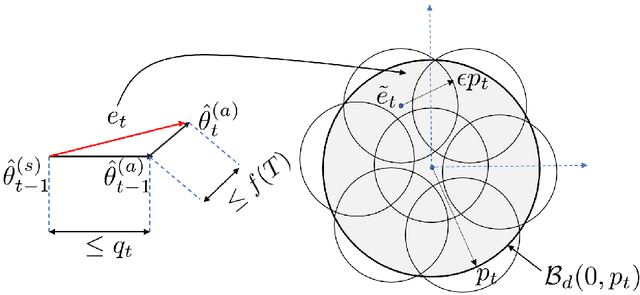
One of the primary challenges in large-scale distributed learning stems from stringent communication constraints. While several recent works address this challenge for static optimization problems, sequential decision-making under uncertainty has remained much less explored in this regard. Motivated by this gap, we introduce a new linear stochastic bandit formulation over a bit-constrained channel. Specifically, in our setup, an agent interacting with an environment transmits encoded estimates of an unknown model parameter to a server over a communication channel of finite capacity. The goal of the server is to take actions based on these estimates to minimize cumulative regret. To this end, we develop a novel and general algorithmic framework that hinges on two main components: (i) an adaptive encoding mechanism that exploits statistical concentration bounds, and (ii) a decision-making principle based on confidence sets that account for encoding errors. As our main result, we prove that when the unknown model is $d$-dimensional, a channel capacity of $O(d)$ bits suffices to achieve order-optimal regret. To demonstrate the generality of our approach, we then show that the same result continues to hold for non-linear observation models satisfying standard regularity conditions. Finally, we establish that for the simpler unstructured multi-armed bandit problem, $1$ bit channel-capacity is sufficient for achieving optimal regret bounds. Overall, our work takes a significant first step towards paving the way for statistical decision-making over finite-capacity channels.
Probabilistically Robust Learning: Balancing Average- and Worst-case Performance
Feb 02, 2022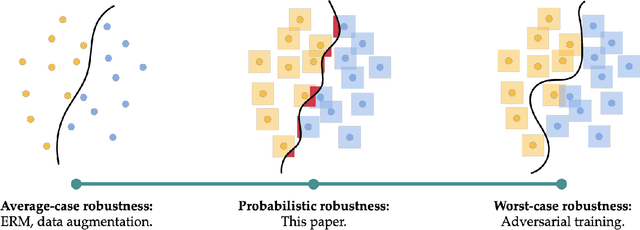
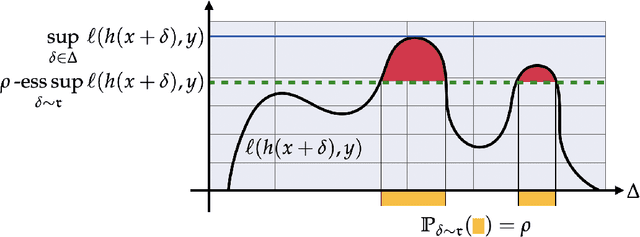
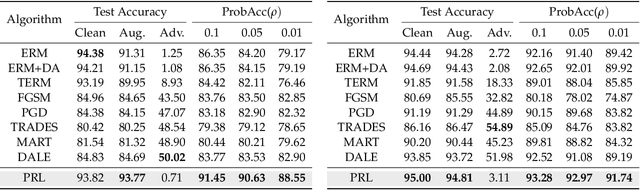
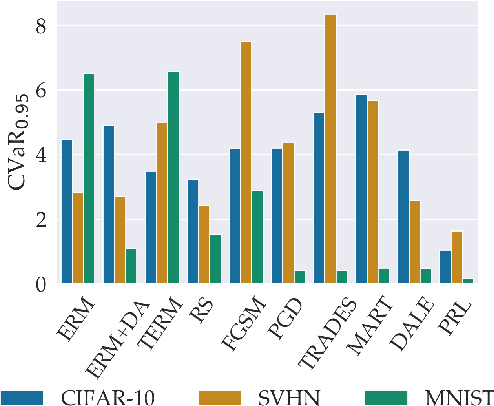
Many of the successes of machine learning are based on minimizing an averaged loss function. However, it is well-known that this paradigm suffers from robustness issues that hinder its applicability in safety-critical domains. These issues are often addressed by training against worst-case perturbations of data, a technique known as adversarial training. Although empirically effective, adversarial training can be overly conservative, leading to unfavorable trade-offs between nominal performance and robustness. To this end, in this paper we propose a framework called probabilistic robustness that bridges the gap between the accurate, yet brittle average case and the robust, yet conservative worst case by enforcing robustness to most rather than to all perturbations. From a theoretical point of view, this framework overcomes the trade-offs between the performance and the sample-complexity of worst-case and average-case learning. From a practical point of view, we propose a novel algorithm based on risk-aware optimization that effectively balances average- and worst-case performance at a considerably lower computational cost relative to adversarial training. Our results on MNIST, CIFAR-10, and SVHN illustrate the advantages of this framework on the spectrum from average- to worst-case robustness.
Learning Operators with Coupled Attention
Jan 04, 2022



Supervised operator learning is an emerging machine learning paradigm with applications to modeling the evolution of spatio-temporal dynamical systems and approximating general black-box relationships between functional data. We propose a novel operator learning method, LOCA (Learning Operators with Coupled Attention), motivated from the recent success of the attention mechanism. In our architecture, the input functions are mapped to a finite set of features which are then averaged with attention weights that depend on the output query locations. By coupling these attention weights together with an integral transform, LOCA is able to explicitly learn correlations in the target output functions, enabling us to approximate nonlinear operators even when the number of output function in the training set measurements is very small. Our formulation is accompanied by rigorous approximation theoretic guarantees on the universal expressiveness of the proposed model. Empirically, we evaluate the performance of LOCA on several operator learning scenarios involving systems governed by ordinary and partial differential equations, as well as a black-box climate prediction problem. Through these scenarios we demonstrate state of the art accuracy, robustness with respect to noisy input data, and a consistently small spread of errors over testing data sets, even for out-of-distribution prediction tasks.