 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeeipy: An Open-Source Python Package for Multi-modal Data Integration using Heterogeneous Ensembles
Jan 17, 2024
In this paper, we introduce eipy--an open-source Python package for developing effective, multi-modal heterogeneous ensembles for classification. eipy simultaneously provides both a rigorous, and user-friendly framework for comparing and selecting the best-performing multi-modal data integration and predictive modeling methods by systematically evaluating their performance using nested cross-validation. The package is designed to leverage scikit-learn-like estimators as components to build multi-modal predictive models. An up-to-date user guide, including API reference and tutorials, for eipy is maintained at https://eipy.readthedocs.io . The main repository for this project can be found on GitHub at https://github.com/GauravPandeyLab/eipy .
Sharable Clothoid-based Continuous Motion Planning for Connected Automated Vehicles
Dec 18, 2023



A continuous motion planning method for connected automated vehicles is considered for generating feasible trajectories in real-time using three consecutive clothoids. The proposed method reduces path planning to a small set of nonlinear algebraic equations such that the generated path can be efficiently checked for feasibility and collision. After path planning, velocity planning is executed while maintaining a parallel simple structure. Key strengths of this framework include its interpretability, shareability, and ability to specify boundary conditions. Its interpretability and shareability stem from the succinct representation of the resulting local motion plan using a handful of physically meaningful parameters. Vehicles may share these parameters via V2X communication so that the recipients can precisely reconstruct the planned trajectory of the senders and respond accordingly. The proposed local planner guarantees the satisfaction of boundary conditions, thus ensuring seamless integration with a wide array of higher-level global motion planners. The tunable nature of the method enables tailoring the local plans to specific maneuvers like turns at intersections, lane changes, and U-turns.
RGB-X Object Detection via Scene-Specific Fusion Modules
Oct 30, 2023



Multimodal deep sensor fusion has the potential to enable autonomous vehicles to visually understand their surrounding environments in all weather conditions. However, existing deep sensor fusion methods usually employ convoluted architectures with intermingled multimodal features, requiring large coregistered multimodal datasets for training. In this work, we present an efficient and modular RGB-X fusion network that can leverage and fuse pretrained single-modal models via scene-specific fusion modules, thereby enabling joint input-adaptive network architectures to be created using small, coregistered multimodal datasets. Our experiments demonstrate the superiority of our method compared to existing works on RGB-thermal and RGB-gated datasets, performing fusion using only a small amount of additional parameters. Our code is available at https://github.com/dsriaditya999/RGBXFusion.
Stereo Visual Odometry with Deep Learning-Based Point and Line Feature Matching using an Attention Graph Neural Network
Aug 02, 2023



Robust feature matching forms the backbone for most Visual Simultaneous Localization and Mapping (vSLAM), visual odometry, 3D reconstruction, and Structure from Motion (SfM) algorithms. However, recovering feature matches from texture-poor scenes is a major challenge and still remains an open area of research. In this paper, we present a Stereo Visual Odometry (StereoVO) technique based on point and line features which uses a novel feature-matching mechanism based on an Attention Graph Neural Network that is designed to perform well even under adverse weather conditions such as fog, haze, rain, and snow, and dynamic lighting conditions such as nighttime illumination and glare scenarios. We perform experiments on multiple real and synthetic datasets to validate the ability of our method to perform StereoVO under low visibility weather and lighting conditions through robust point and line matches. The results demonstrate that our method achieves more line feature matches than state-of-the-art line matching algorithms, which when complemented with point feature matches perform consistently well in adverse weather and dynamic lighting conditions.
Look Both Ways: Bidirectional Visual Sensing for Automatic Multi-Camera Registration
Aug 15, 2022



This work describes the automatic registration of a large network (approximately 40) of fixed, ceiling-mounted environment cameras spread over a large area (approximately 800 squared meters) using a mobile calibration robot equipped with a single upward-facing fisheye camera and a backlit ArUco marker for easy detection. The fisheye camera is used to do visual odometry (VO), and the ArUco marker facilitates easy detection of the calibration robot in the environment cameras. In addition, the fisheye camera is also able to detect the environment cameras. This two-way, bidirectional detection constrains the pose of the environment cameras to solve an optimization problem. Such an approach can be used to automatically register a large-scale multi-camera system used for surveillance, automated parking, or robotic applications. This VO based multicamera registration method is extensively validated using real-world experiments, and also compared against a similar approach which uses an LiDAR - an expensive, heavier and power hungry sensor.
Real-time Full-stack Traffic Scene Perception for Autonomous Driving with Roadside Cameras
Jun 20, 2022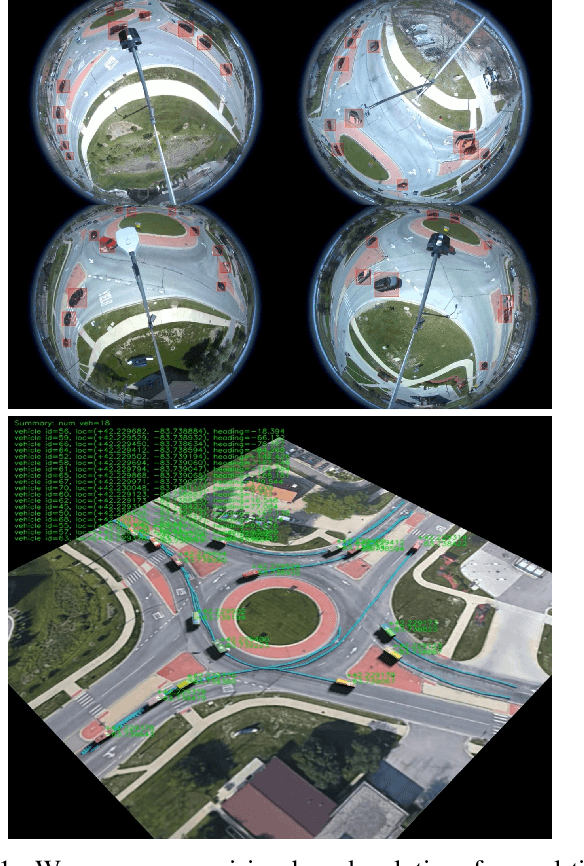
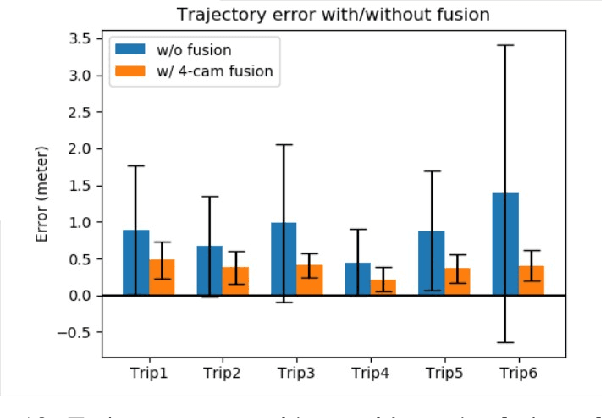
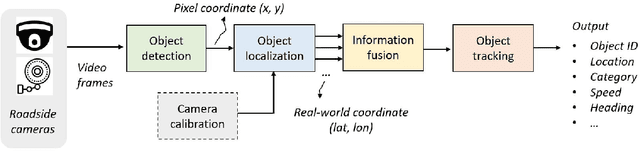
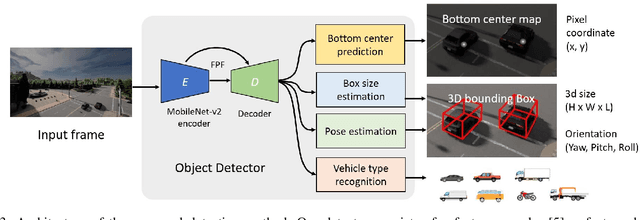
We propose a novel and pragmatic framework for traffic scene perception with roadside cameras. The proposed framework covers a full-stack of roadside perception pipeline for infrastructure-assisted autonomous driving, including object detection, object localization, object tracking, and multi-camera information fusion. Unlike previous vision-based perception frameworks rely upon depth offset or 3D annotation at training, we adopt a modular decoupling design and introduce a landmark-based 3D localization method, where the detection and localization can be well decoupled so that the model can be easily trained based on only 2D annotations. The proposed framework applies to either optical or thermal cameras with pinhole or fish-eye lenses. Our framework is deployed at a two-lane roundabout located at Ellsworth Rd. and State St., Ann Arbor, MI, USA, providing 7x24 real-time traffic flow monitoring and high-precision vehicle trajectory extraction. The whole system runs efficiently on a low-power edge computing device with all-component end-to-end delay of less than 20ms.
Gaining Insights into Unrecognized User Utterances in Task-Oriented Dialog Systems
Apr 11, 2022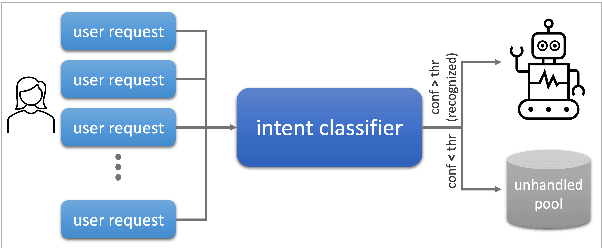

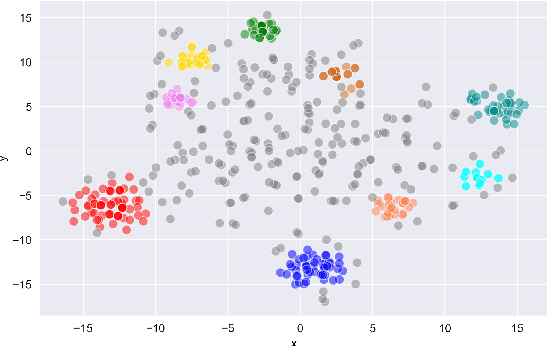
The rapidly growing market demand for dialogue agents capable of goal-oriented behavior has caused many tech-industry leaders to invest considerable efforts into task-oriented dialog systems. The performance and success of these systems is highly dependent on the accuracy of their intent identification -- the process of deducing the goal or meaning of the user's request and mapping it to one of the known intents for further processing. Gaining insights into unrecognized utterances -- user requests the systems fails to attribute to a known intent -- is therefore a key process in continuous improvement of goal-oriented dialog systems. We present an end-to-end pipeline for processing unrecognized user utterances, including a specifically-tailored clustering algorithm, a novel approach to cluster representative extraction, and cluster naming. We evaluated the proposed clustering algorithm and compared its performance to out-of-the-box SOTA solutions, demonstrating its benefits in the analysis of unrecognized user requests.
Mix-and-Match: Scalable Dialog Response Retrieval using Gaussian Mixture Embeddings
Apr 06, 2022
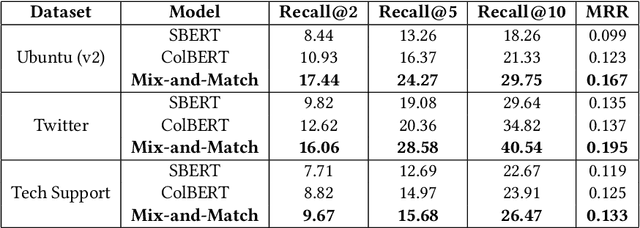
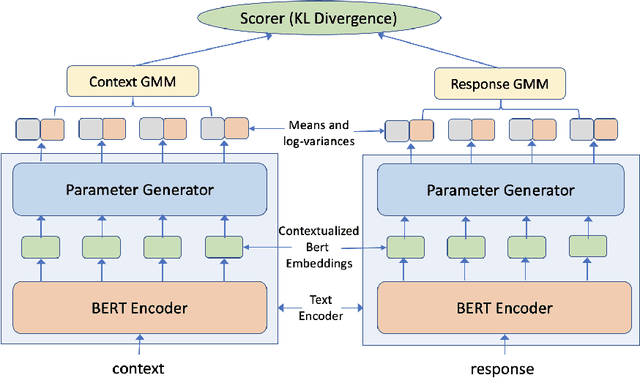
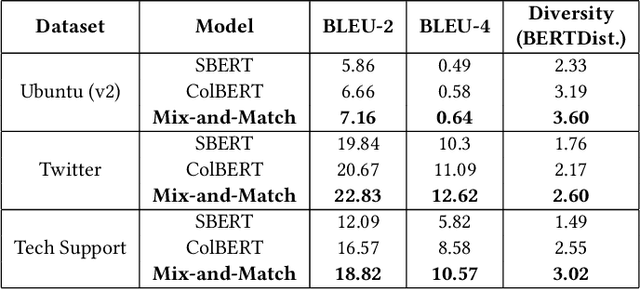
Embedding-based approaches for dialog response retrieval embed the context-response pairs as points in the embedding space. These approaches are scalable, but fail to account for the complex, many-to-many relationships that exist between context-response pairs. On the other end of the spectrum, there are approaches that feed the context-response pairs jointly through multiple layers of neural networks. These approaches can model the complex relationships between context-response pairs, but fail to scale when the set of responses is moderately large (>100). In this paper, we combine the best of both worlds by proposing a scalable model that can learn complex relationships between context-response pairs. Specifically, the model maps the contexts as well as responses to probability distributions over the embedding space. We train the models by optimizing the Kullback-Leibler divergence between the distributions induced by context-response pairs in the training data. We show that the resultant model achieves better performance as compared to other embedding-based approaches on publicly available conversation data.
Variational Learning for Unsupervised Knowledge Grounded Dialogs
Dec 06, 2021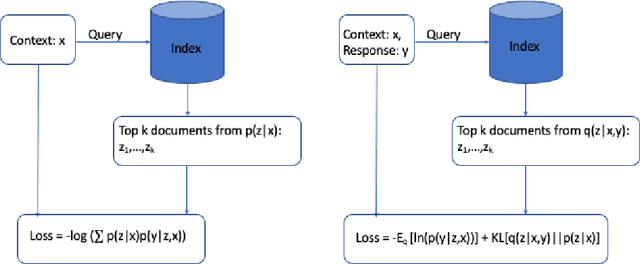
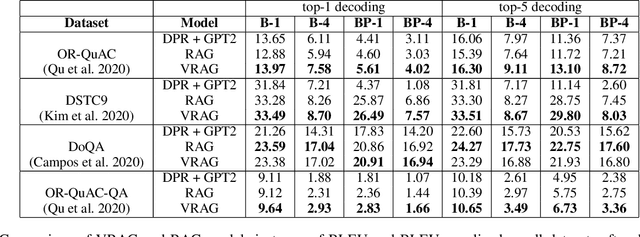
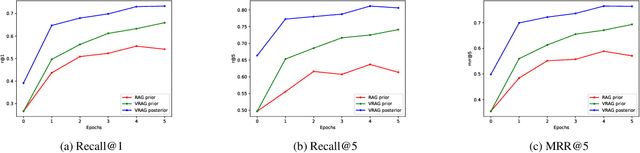
Recent methods for knowledge grounded dialogs generate responses by incorporating information from an external textual document. These methods do not require the exact document to be known during training and rely on the use of a retrieval system to fetch relevant documents from a large index. The documents used to generate the responses are modeled as latent variables whose prior probabilities need to be estimated. Models such as RAG , marginalize the document probabilities over the documents retrieved from the index to define the log likelihood loss function which is optimized end-to-end. In this paper, we develop a variational approach to the above technique wherein, we instead maximize the Evidence Lower bound (ELBO). Using a collection of three publicly available open-conversation datasets, we demonstrate how the posterior distribution, that has information from the ground-truth response, allows for a better approximation of the objective function during training. To overcome the challenges associated with sampling over a large knowledge collection, we develop an efficient approach to approximate the ELBO. To the best of our knowledge we are the first to apply variational training for open-scale unsupervised knowledge grounded dialog systems.
Localization of a Smart Infrastructure Fisheye Camera in a Prior Map for Autonomous Vehicles
Sep 28, 2021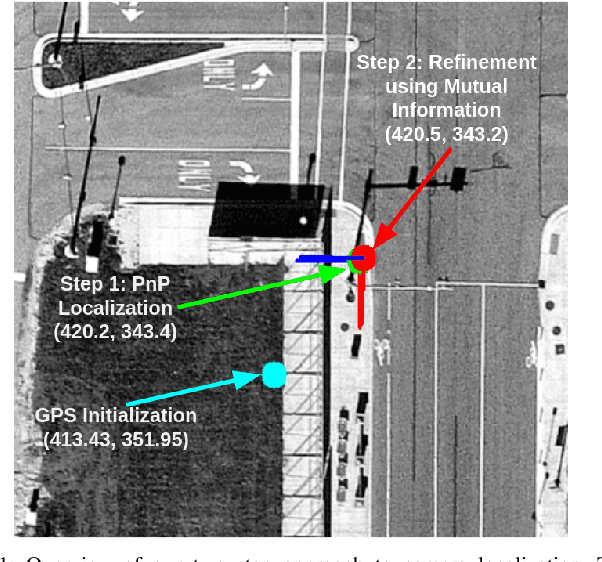


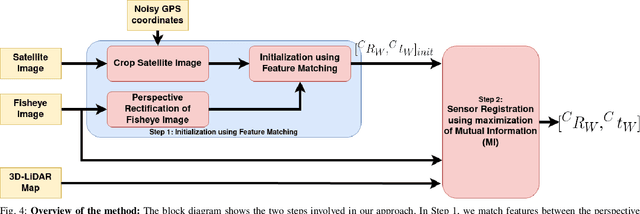
This work presents a technique for localization of a smart infrastructure node, consisting of a fisheye camera, in a prior map. These cameras can detect objects that are outside the line of sight of the autonomous vehicles (AV) and send that information to AVs using V2X technology. However, in order for this information to be of any use to the AV, the detected objects should be provided in the reference frame of the prior map that the AV uses for its own navigation. Therefore, it is important to know the accurate pose of the infrastructure camera with respect to the prior map. Here we propose to solve this localization problem in two steps, \textit{(i)} we perform feature matching between perspective projection of fisheye image and bird's eye view (BEV) satellite imagery from the prior map to estimate an initial camera pose, \textit{(ii)} we refine the initialization by maximizing the Mutual Information (MI) between intensity of pixel values of fisheye image and reflectivity of 3D LiDAR points in the map data. We validate our method on simulated data and also present results with real world data.