 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks in Leipzig
Jun 04, 2026Between April 1 and May 15, 2026, a group of 49 mathematicians compiled a dataset of research-level mathematics questions with known answers. Most of the work was done during the 3-day workshop *Benchmarks in Leipzig* with 35 participants at the Max Planck Institute for Mathematics in the Sciences in Leipzig, Germany. We present the resulting collection of 100 questions. We evaluated these questions in three stages: a single attempt by five state-of-the-art LLMs, followed by a 20-runs-per-model evaluation with three of these models, and finally a 3-run attempt with two heavy-thinking models. After Stage 1, 41 questions remained completely unsolved; after Stage 2, this count dropped to 16; and we concluded Stage 3 with only 2 unsolved questions. This demonstrates that the mathematical reasoning capabilities of LLMs are becoming impressive.
TabPert: An Effective Platform for Tabular Perturbation
Aug 02, 2021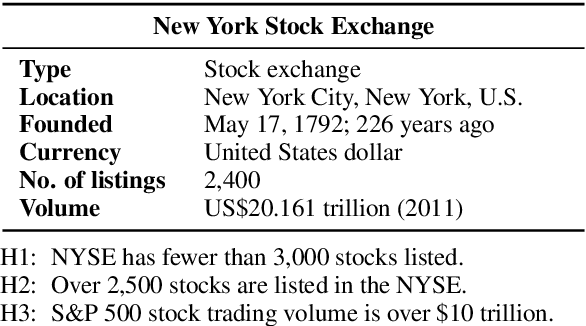
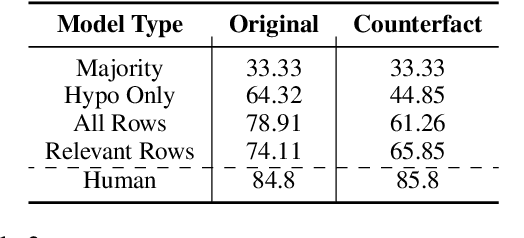
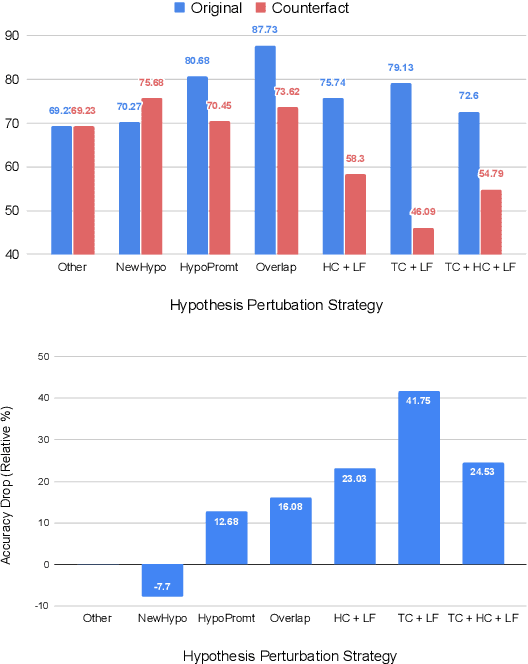
To truly grasp reasoning ability, a Natural Language Inference model should be evaluated on counterfactual data. TabPert facilitates this by assisting in the generation of such counterfactual data for assessing model tabular reasoning issues. TabPert allows a user to update a table, change its associated hypotheses, change their labels, and highlight rows that are important for hypothesis classification. TabPert also captures information about the techniques used to automatically produce the table, as well as the strategies employed to generate the challenging hypotheses. These counterfactual tables and hypotheses, as well as the metadata, can then be used to explore an existing model's shortcomings methodically and quantitatively.