 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Online Prediction Approach Based on Incremental Support Vector Machine for Dynamic Multiobjective Optimization
Feb 24, 2021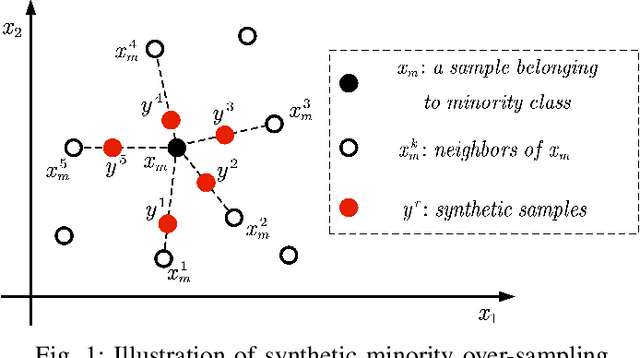

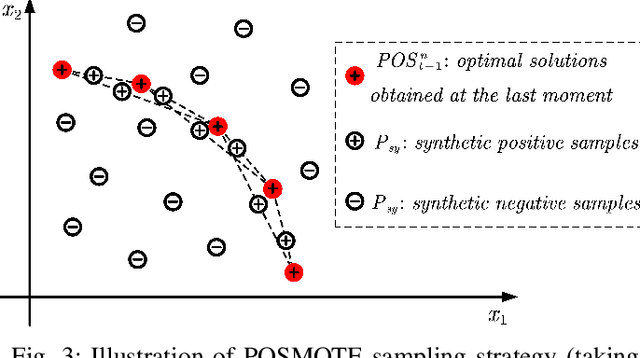
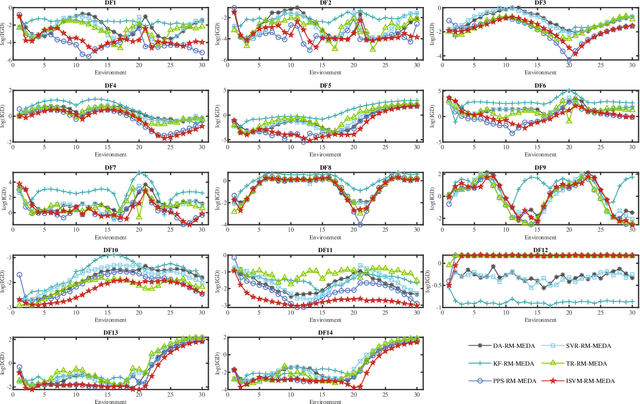
Real-world multiobjective optimization problems usually involve conflicting objectives that change over time, which requires the optimization algorithms to quickly track the Pareto optimal front (POF) when the environment changes. In recent years, evolutionary algorithms based on prediction models have been considered promising. However, most existing approaches only make predictions based on the linear correlation between a finite number of optimal solutions in two or three previous environments. These incomplete information extraction strategies may lead to low prediction accuracy in some instances. In this paper, a novel prediction algorithm based on incremental support vector machine (ISVM) is proposed, called ISVM-DMOEA. We treat the solving of dynamic multiobjective optimization problems (DMOPs) as an online learning process, using the continuously obtained optimal solution to update an incremental support vector machine without discarding the solution information at earlier time. ISVM is then used to filter random solutions and generate an initial population for the next moment. To overcome the obstacle of insufficient training samples, a synthetic minority oversampling strategy is implemented before the training of ISVM. The advantage of this approach is that the nonlinear correlation between solutions can be explored online by ISVM, and the information contained in all historical optimal solutions can be exploited to a greater extent. The experimental results and comparison with chosen state-of-the-art algorithms demonstrate that the proposed algorithm can effectively tackle dynamic multiobjective optimization problems.
System Design and Analysis for Energy-Efficient Passive UAV Radar Imaging System using Illuminators of Opportunity
Oct 01, 2020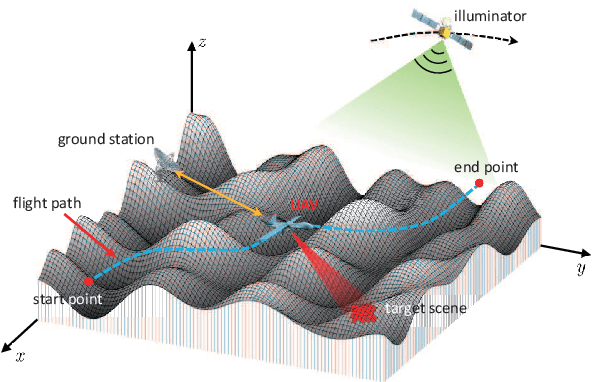
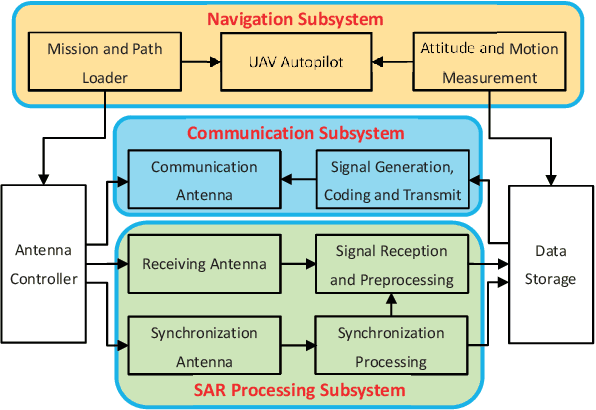
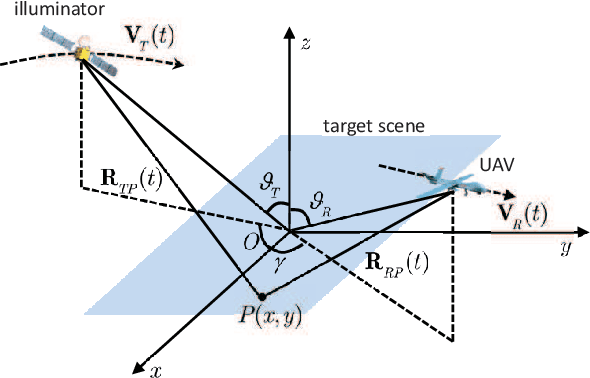
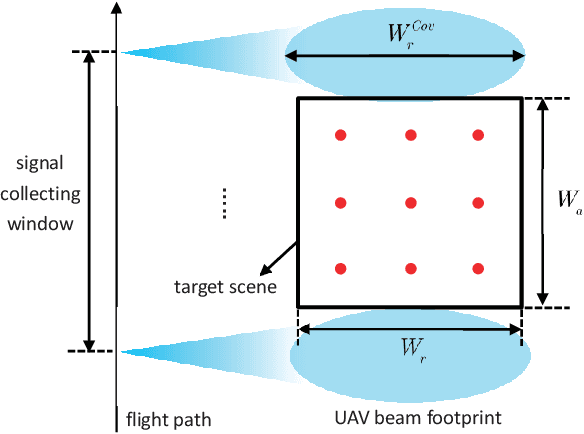
Unmanned ariel vehicle (UAV) can provide superior flexibility and cost-efficiency for modern radar imaging systems, which is an ideal platform for advanced remote sensing applications using synthetic aperture radar (SAR) technology. In this paper, an energy-efficient passive UAV radar imaging system using illuminators of opportunity is first proposed and investigated. Equipped with a SAR receiver, the UAV platform passively reuses the backscattered signal of the target scene from an external illuminator, such as SAR satellite, GNSS or ground-based stationary commercial illuminators, and achieves bi-static SAR imaging and data communication. The system can provide instant accessibility to the radar image of the interested targets with enhanced platform concealment, which is an essential tool for stealth observation and scene monitoring. The mission concept and system block diagram are first presented with justifications on the advantages of the system. Then, the prospective imaging performance and system feasibility are analyzed for the typical illuminators based on signal and spatial resolution model. With different illuminators, the proposed system can achieve distinct imaging performance, which offers more alternatives for various mission requirements. A set of mission performance evaluators is established to quantitatively assess the capability of the system in a comprehensive manner, including UAV navigation, passive SAR imaging and communication. Finally, the validity of the proposed performance evaluators are verified by numerical simulations.
When Autonomous Systems Meet Accuracy and Transferability through AI: A Survey
Apr 30, 2020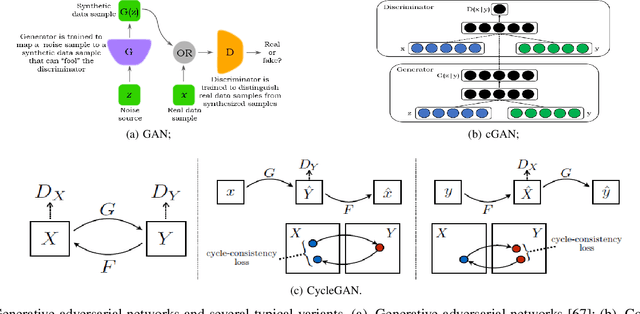
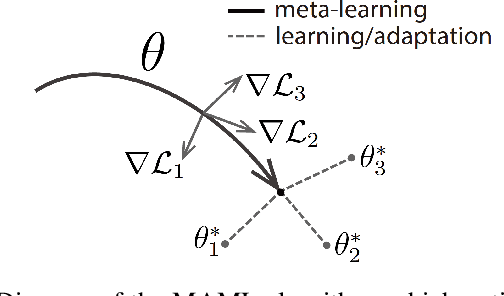


With widespread applications of artificial intelligence (AI), the capabilities of the perception, understanding, decision-making and control for autonomous systems have improved significantly in the past years. When autonomous systems consider the performance of accuracy and transferability, several AI methods, like adversarial learning, reinforcement learning (RL) and meta-learning, show their powerful performance. Here, we review the learning-based approaches in autonomous systems from the perspectives of accuracy and transferability. Accuracy means that a well-trained model shows good results during the testing phase, in which the testing set shares a same task or a data distribution with the training set. Transferability means that when a well-trained model is transferred to other testing domains, the accuracy is still good. Firstly, we introduce some basic concepts of transfer learning and then present some preliminaries of adversarial learning, RL and meta-learning. Secondly, we focus on reviewing the accuracy or transferability or both of them to show the advantages of adversarial learning, like generative adversarial networks (GANs), in typical computer vision tasks in autonomous systems, including image style transfer, image superresolution, image deblurring/dehazing/rain removal, semantic segmentation, depth estimation, pedestrian detection and person re-identification (re-ID). Then, we further review the performance of RL and meta-learning from the aspects of accuracy or transferability or both of them in autonomous systems, involving pedestrian tracking, robot navigation and robotic manipulation. Finally, we discuss several challenges and future topics for using adversarial learning, RL and meta-learning in autonomous systems.
Masked GANs for Unsupervised Depth and Pose Prediction with Scale Consistency
Apr 09, 2020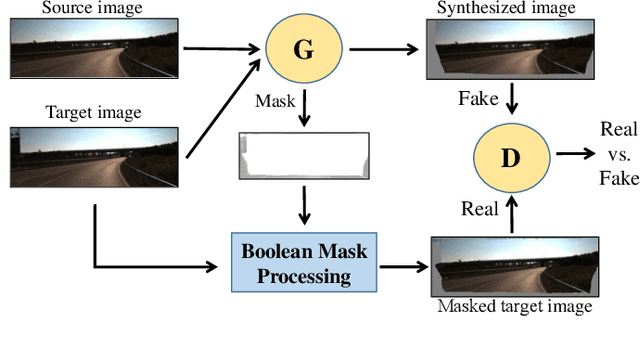

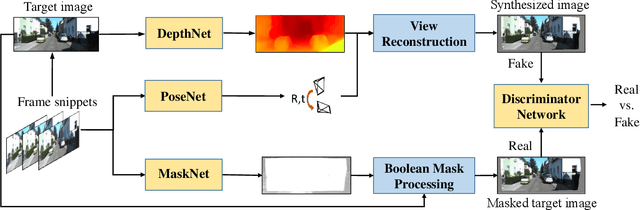

Previous works have shown that adversarial learning can be used for unsupervised monocular depth and visual odometry (VO) estimation. However, the performance of pose and depth networks is limited by occlusions and visual field changes. Because of the incomplete correspondence of visual information between frames caused by motion, target images cannot be synthesized completely from source images via view reconstruction and bilinear interpolation. The reconstruction loss based on the difference between synthesized and real target images will be affected by the incomplete reconstruction. Besides, the data distribution of unreconstructed regions will be learned and help the discriminator distinguish between real and fake images, thereby causing the case that the generator may fail to compete with the discriminator. Therefore, a MaskNet is designed in this paper to predict these regions and reduce their impacts on the reconstruction loss and adversarial loss. The impact of unreconstructed regions on discriminator is tackled by proposing a boolean mask scheme, as shown in Fig. 1. Furthermore, we consider the scale consistency of our pose network by utilizing a new scale-consistency loss, therefore our pose network is capable of providing the full camera trajectory over the long monocular sequence. Extensive experiments on KITTI dataset show that each component proposed in this paper contributes to the performance, and both of our depth and trajectory prediction achieve competitive performance.
Pruning Deep Neural Networks Architectures with Evolution Strategy
Dec 24, 2019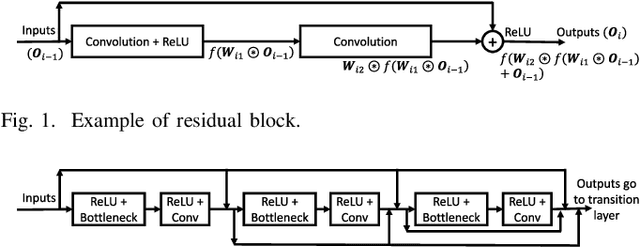

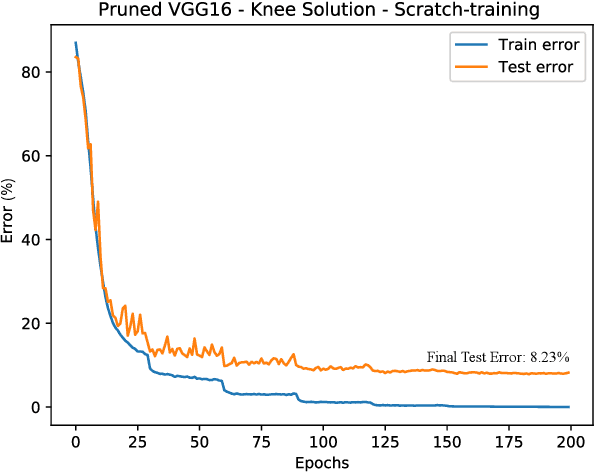
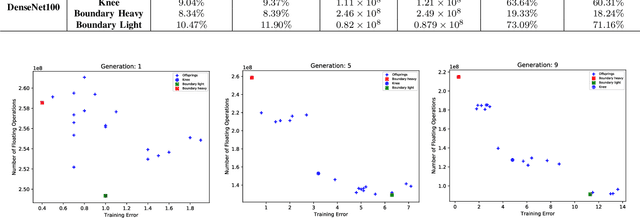
Currently, Deep Neural Networks (DNNs) are used to solve all kinds of problems in the field of machine learning and artificial intelligence due to their learning and adaptation capabilities. However, most of the successful DNN models have a high computational complexity, which makes them difficult to deploy on mobile or embedded platforms. This has prompted many researchers to develop algorithms and approaches to help reduce the computational complexity of such models. One of them is called filter pruning where convolution filters are eliminated to reduce the number of parameters and, consequently, the computational complexity of the given model. In the present work, we propose a novel algorithm to perform filter pruning by using Multi-Objective Evolution Strategy (ES) algorithm, called DeepPruningES. Our approach avoids the need for using any knowledge during the pruning procedure and helps decision makers by returning three pruned DNN models with different trade-offs between performance and computational complexity. We show that DeepPruningES can significantly reduce a model's computational complexity by testing it on three DNN architectures: Convolutional Neural Networks, Residual Neural Networks, and Densely Connected Neural Networks.
Automatically Designing CNN Architectures Using Genetic Algorithm for Image Classification
Aug 11, 2018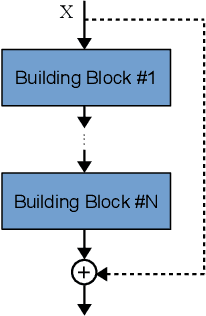
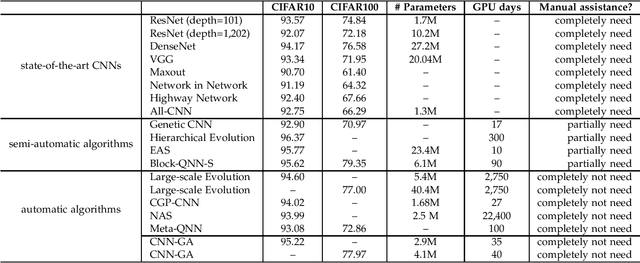

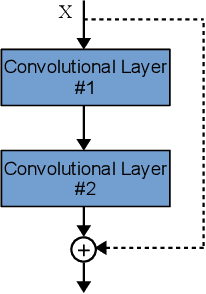
Convolutional Neural Networks (CNNs) have gained a remarkable success on many real-world problems in recent years. However, the performance of CNNs is highly relied on their architectures. For some state-of-the-art CNNs, their architectures are hand-crafted with expertise in both CNNs and the investigated problems. To this end, it is difficult for researchers, who have no extended expertise in CNNs, to explore CNNs for their own problems of interest. In this paper, we propose an automatic architecture design method for CNNs by using genetic algorithms, which is capable of discovering a promising architecture of a CNN on handling image classification tasks. The proposed algorithm does not need any pre-processing before it works, nor any post-processing on the discovered CNN, which means it is completely automatic. The proposed algorithm is validated on widely used benchmark datasets, by comparing to the state-of-the-art peer competitors covering eight manually designed CNNs, four semi-automatically designed CNNs and additional four automatically designed CNNs. The experimental results indicate that the proposed algorithm achieves the best classification accuracy consistently among manually and automatically designed CNNs. Furthermore, the proposed algorithm also shows the competitive classification accuracy to the semi-automatic peer competitors, while reducing 10 times of the parameters. In addition, on the average the proposed algorithm takes only one percentage of computational resource compared to that of all the other architecture discovering algorithms.
IGD Indicator-based Evolutionary Algorithm for Many-objective Optimization Problems
Feb 24, 2018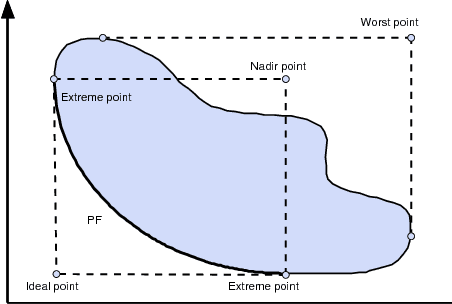
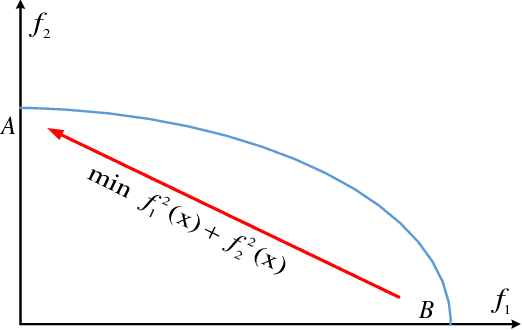
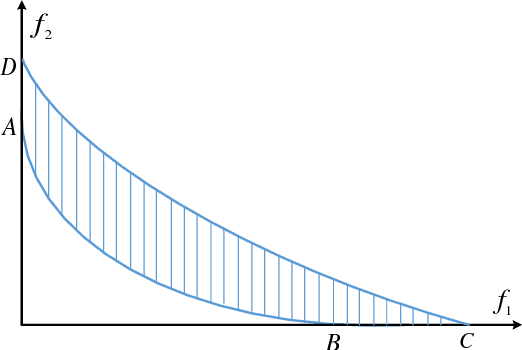
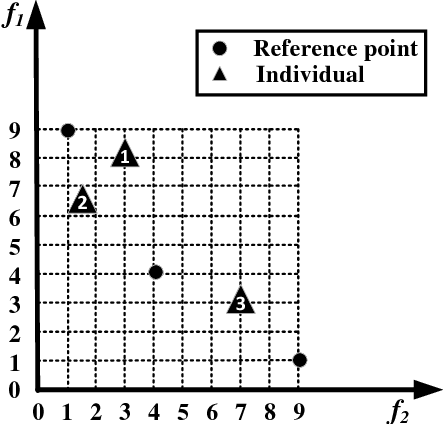
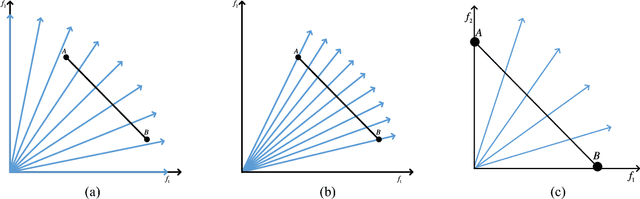
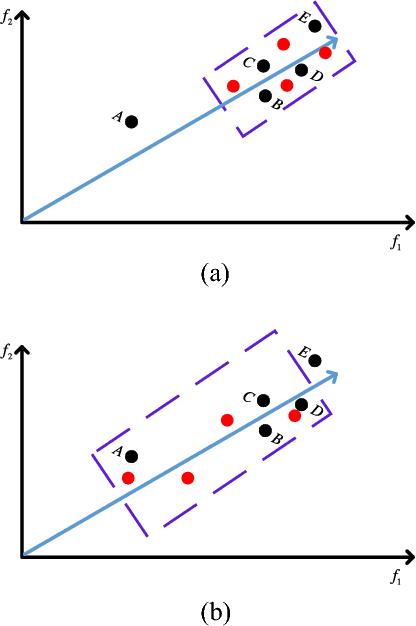
Inverted Generational Distance (IGD) has been widely considered as a reliable performance indicator to concurrently quantify the convergence and diversity of multi- and many-objective evolutionary algorithms. In this paper, an IGD indicator-based evolutionary algorithm for solving many-objective optimization problems (MaOPs) has been proposed. Specifically, the IGD indicator is employed in each generation to select the solutions with favorable convergence and diversity. In addition, a computationally efficient dominance comparison method is designed to assign the rank values of solutions along with three newly proposed proximity distance assignments. Based on these two designs, the solutions are selected from a global view by linear assignment mechanism to concern the convergence and diversity simultaneously. In order to facilitate the accuracy of the sampled reference points for the calculation of IGD indicator, we also propose an efficient decomposition-based nadir point estimation method for constructing the Utopian Pareto front which is regarded as the best approximate Pareto front for real-world MaOPs at the early stage of the evolution. To evaluate the performance, a series of experiments is performed on the proposed algorithm against a group of selected state-of-the-art many-objective optimization algorithms over optimization problems with $8$-, $15$-, and $20$-objective. Experimental results measured by the chosen performance metrics indicate that the proposed algorithm is very competitive in addressing MaOPs.
Improved Regularity Model-based EDA for Many-objective Optimization
Feb 24, 2018
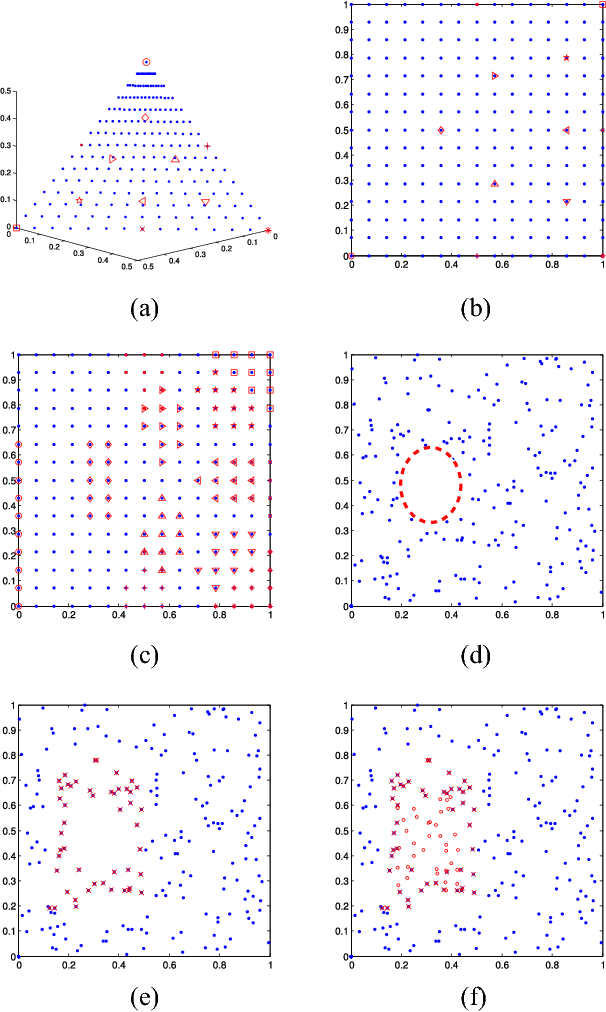
The performance of multi-objective evolutionary algorithms deteriorates appreciably in solving many-objective optimization problems which encompass more than three objectives. One of the known rationales is the loss of selection pressure which leads to the selected parents not generating promising offspring towards Pareto-optimal front with diversity. Estimation of distribution algorithms sample new solutions with a probabilistic model built from the statistics extracting over the existing solutions so as to mitigate the adverse impact of genetic operators. In this paper, an improved regularity-based estimation of distribution algorithm is proposed to effectively tackle unconstrained many-objective optimization problems. In the proposed algorithm, \emph{diversity repairing mechanism} is utilized to mend the areas where need non-dominated solutions with a closer proximity to the Pareto-optimal front. Then \emph{favorable solutions} are generated by the model built from the regularity of the solutions surrounding a group of representatives. These two steps collectively enhance the selection pressure which gives rise to the superior convergence of the proposed algorithm. In addition, dimension reduction technique is employed in the decision space to speed up the estimation search of the proposed algorithm. Finally, by assigning the Pareto-optimal solutions to the uniformly distributed reference vectors, a set of solutions with excellent diversity and convergence is obtained. To measure the performance, NSGA-III, GrEA, MOEA/D, HypE, MBN-EDA, and RM-MEDA are selected to perform comparison experiments over DTLZ and DTLZ$^-$ test suites with $3$-, $5$-, $8$-, $10$-, and $15$-objective. Experimental results quantified by the selected performance metrics reveal that the proposed algorithm shows considerable competitiveness in addressing unconstrained many-objective optimization problems.
Evolving Unsupervised Deep Neural Networks for Learning Meaningful Representations
Feb 24, 2018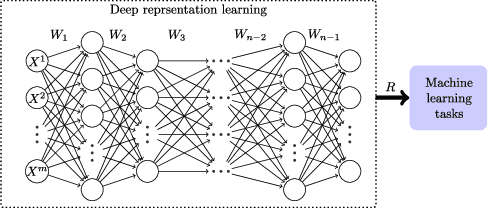
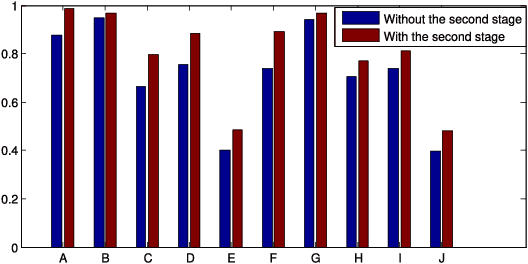

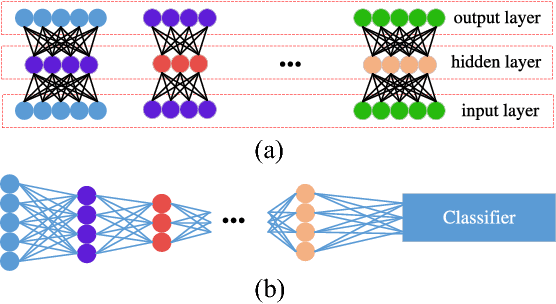
Deep Learning (DL) aims at learning the \emph{meaningful representations}. A meaningful representation refers to the one that gives rise to significant performance improvement of associated Machine Learning (ML) tasks by replacing the raw data as the input. However, optimal architecture design and model parameter estimation in DL algorithms are widely considered to be intractable. Evolutionary algorithms are much preferable for complex and non-convex problems due to its inherent characteristics of gradient-free and insensitivity to local optimum. In this paper, we propose a computationally economical algorithm for evolving \emph{unsupervised deep neural networks} to efficiently learn \emph{meaningful representations}, which is very suitable in the current Big Data era where sufficient labeled data for training is often expensive to acquire. In the proposed algorithm, finding an appropriate architecture and the initialized parameter values for a ML task at hand is modeled by one computational efficient gene encoding approach, which is employed to effectively model the task with a large number of parameters. In addition, a local search strategy is incorporated to facilitate the exploitation search for further improving the performance. Furthermore, a small proportion labeled data is utilized during evolution search to guarantee the learnt representations to be meaningful. The performance of the proposed algorithm has been thoroughly investigated over classification tasks. Specifically, error classification rate on MNIST with $1.15\%$ is reached by the proposed algorithm consistently, which is a very promising result against state-of-the-art unsupervised DL algorithms.
Transfer Learning based Dynamic Multiobjective Optimization Algorithms
Nov 18, 2017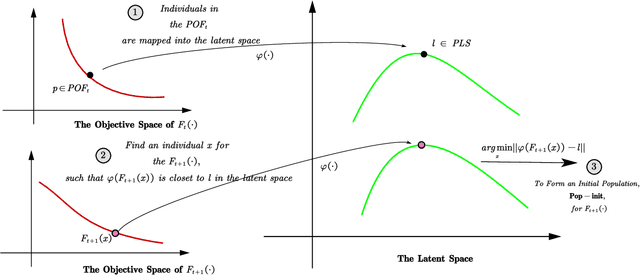
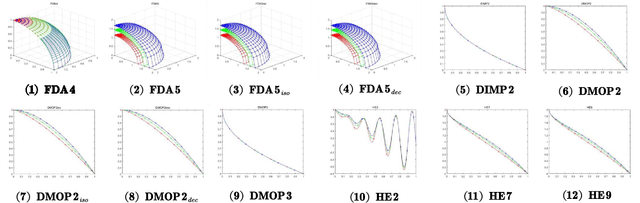
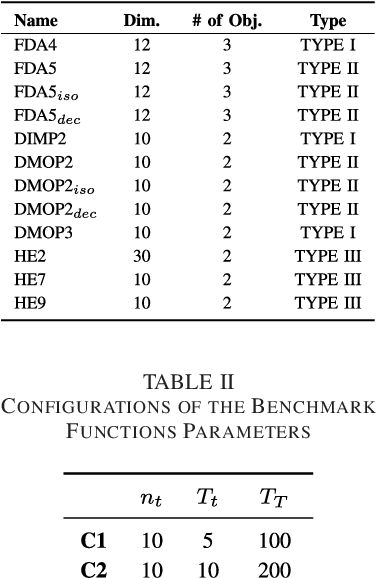
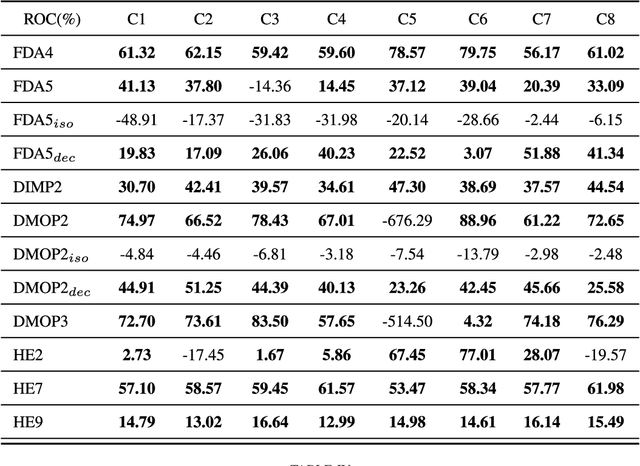
One of the major distinguishing features of the dynamic multiobjective optimization problems (DMOPs) is the optimization objectives will change over time, thus tracking the varying Pareto-optimal front becomes a challenge. One of the promising solutions is reusing the "experiences" to construct a prediction model via statistical machine learning approaches. However most of the existing methods ignore the non-independent and identically distributed nature of data used to construct the prediction model. In this paper, we propose an algorithmic framework, called Tr-DMOEA, which integrates transfer learning and population-based evolutionary algorithm for solving the DMOPs. This approach takes the transfer learning method as a tool to help reuse the past experience for speeding up the evolutionary process, and at the same time, any population based multiobjective algorithms can benefit from this integration without any extensive modifications. To verify this, we incorporate the proposed approach into the development of three well-known algorithms, nondominated sorting genetic algorithm II (NSGA-II), multiobjective particle swarm optimization (MOPSO), and the regularity model-based multiobjective estimation of distribution algorithm (RM-MEDA), and then employ twelve benchmark functions to test these algorithms as well as compare with some chosen state-of-the-art designs. The experimental results confirm the effectiveness of the proposed method through exploiting machine learning technology.