 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Sample Selection Approach to Positive-Unlabeled Learning: Turning Unlabeled Data into Positive rather than Negative
Jan 29, 2019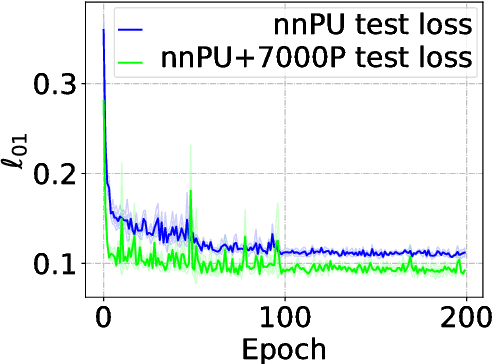

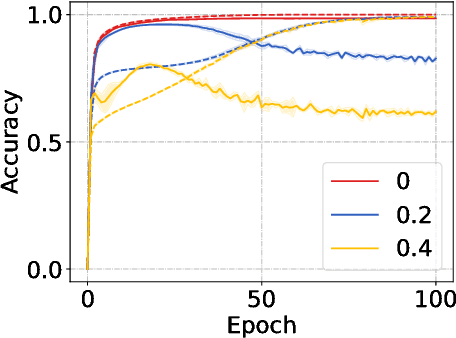
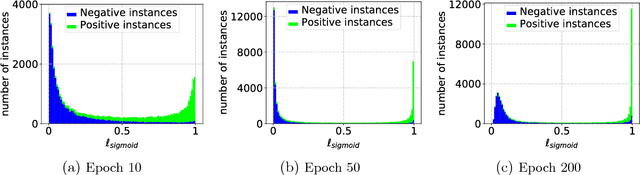
In the early history of positive-unlabeled (PU) learning, the sample selection approach, which heuristically selects negative (N) data from U data, was explored extensively. However, this approach was later dominated by the importance reweighting approach, which carefully treats all U data as N data. May there be a new sample selection method that can outperform the latest importance reweighting method in the deep learning age? This paper is devoted to answering this question affirmatively---we propose to label large-loss U data as P, based on the memorization properties of deep networks. Since P data selected in such a way are biased, we develop a novel learning objective that can handle such biased P data properly. Experiments confirm the superiority of the proposed method.
How does Disagreement Help Generalization against Label Corruption?
Jan 26, 2019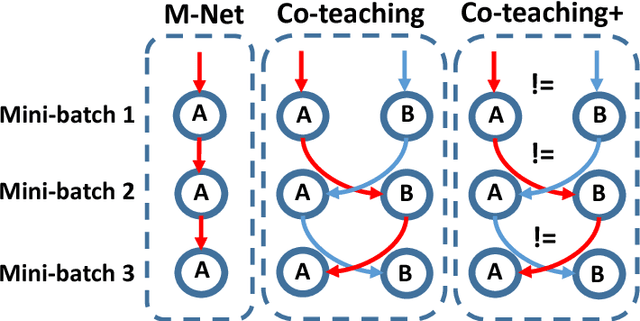
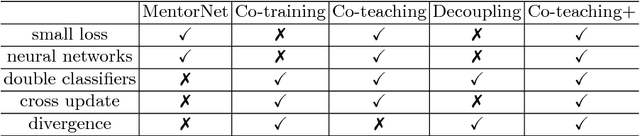
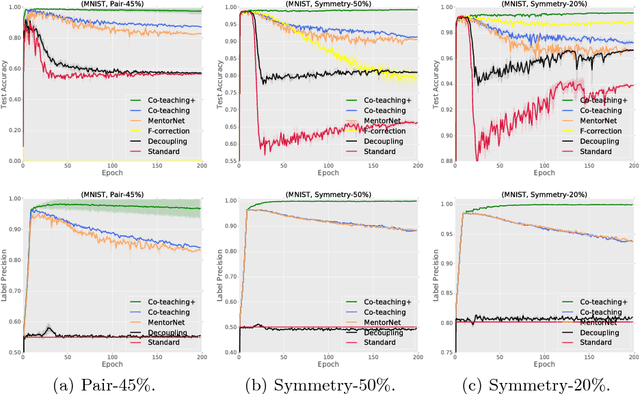
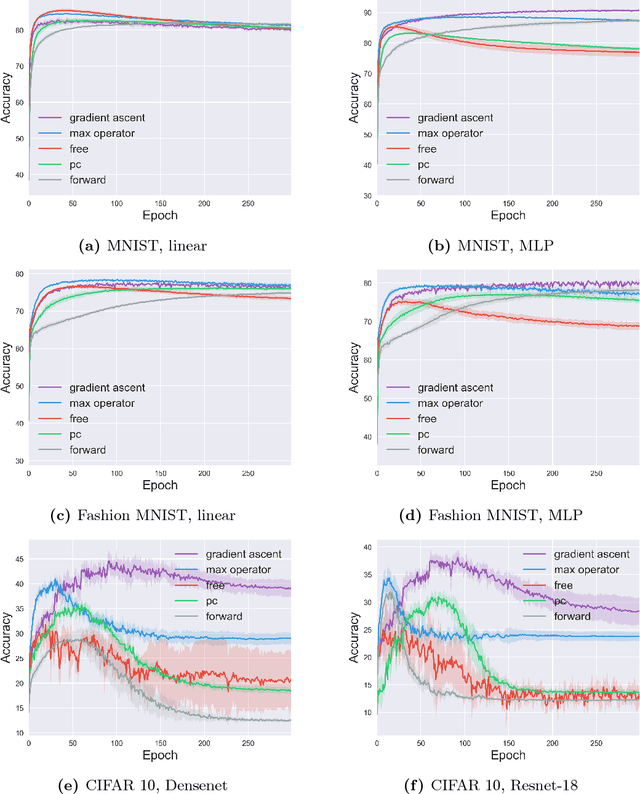
Learning with noisy labels is one of the hottest problems in weakly-supervised learning. Based on memorization effects of deep neural networks, training on small-loss instances becomes very promising for handling noisy labels. This fosters the state-of-the-art approach "Co-teaching" that cross-trains two deep neural networks using the small-loss trick. However, with the increase of epochs, two networks converge to a consensus and Co-teaching reduces to the self-training MentorNet. To tackle this issue, we propose a robust learning paradigm called Co-teaching+, which bridges the "Update by Disagreement" strategy with the original Co-teaching. First, two networks feed forward and predict all data, but keep prediction disagreement data only. Then, among such disagreement data, each network selects its small-loss data, but back propagates the small-loss data from its peer network and updates its own parameters. Empirical results on benchmark datasets demonstrate that Co-teaching+ is much superior to many state-of-the-art methods in the robustness of trained models.
Masking: A New Perspective of Noisy Supervision
Oct 31, 2018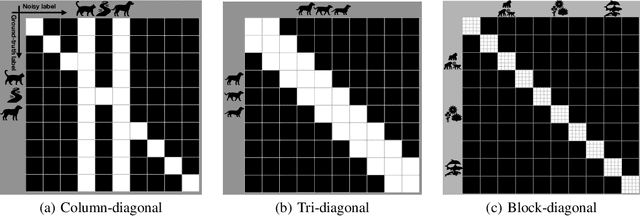
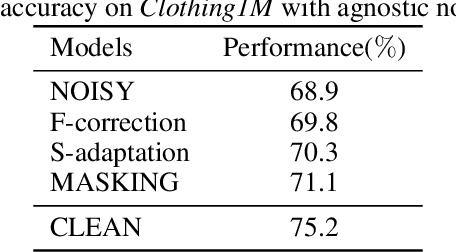
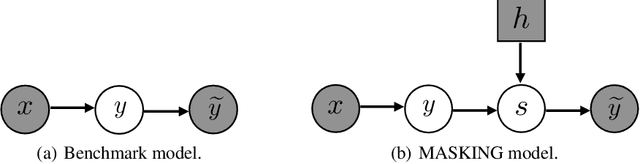
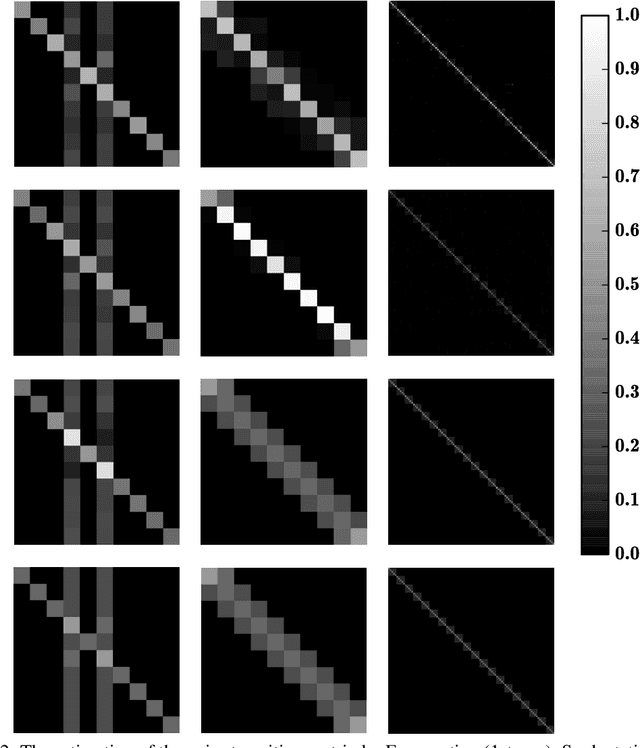
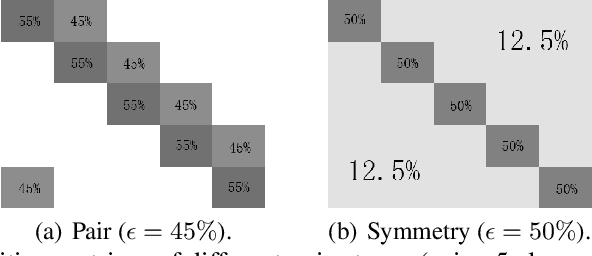
It is important to learn various types of classifiers given training data with noisy labels. Noisy labels, in the most popular noise model hitherto, are corrupted from ground-truth labels by an unknown noise transition matrix. Thus, by estimating this matrix, classifiers can escape from overfitting those noisy labels. However, such estimation is practically difficult, due to either the indirect nature of two-step approaches, or not big enough data to afford end-to-end approaches. In this paper, we propose a human-assisted approach called Masking that conveys human cognition of invalid class transitions and naturally speculates the structure of the noise transition matrix. To this end, we derive a structure-aware probabilistic model incorporating a structure prior, and solve the challenges from structure extraction and structure alignment. Thanks to Masking, we only estimate unmasked noise transition probabilities and the burden of estimation is tremendously reduced. We conduct extensive experiments on CIFAR-10 and CIFAR-100 with three noise structures as well as the industrial-level Clothing1M with agnostic noise structure, and the results show that Masking can improve the robustness of classifiers significantly.
Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels
Oct 30, 2018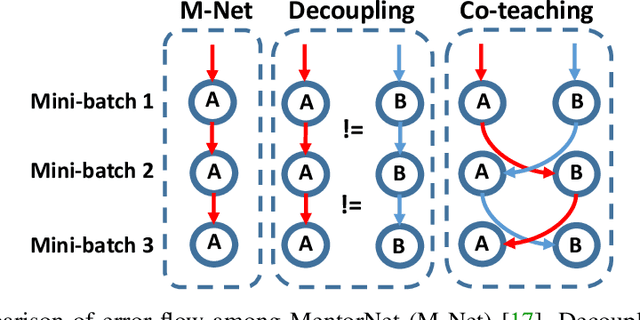

Deep learning with noisy labels is practically challenging, as the capacity of deep models is so high that they can totally memorize these noisy labels sooner or later during training. Nonetheless, recent studies on the memorization effects of deep neural networks show that they would first memorize training data of clean labels and then those of noisy labels. Therefore in this paper, we propose a new deep learning paradigm called Co-teaching for combating with noisy labels. Namely, we train two deep neural networks simultaneously, and let them teach each other given every mini-batch: firstly, each network feeds forward all data and selects some data of possibly clean labels; secondly, two networks communicate with each other what data in this mini-batch should be used for training; finally, each network back propagates the data selected by its peer network and updates itself. Empirical results on noisy versions of MNIST, CIFAR-10 and CIFAR-100 demonstrate that Co-teaching is much superior to the state-of-the-art methods in the robustness of trained deep models.
Complementary-Label Learning for Arbitrary Losses and Models
Oct 10, 2018
In contrast to the standard classification paradigm where the true (or possibly noisy) class is given to each training pattern, complementary-label learning only uses training patterns each equipped with a complementary label. This only specifies one of the classes that the pattern does not belong to. The seminal paper on complementary-label learning proposed an unbiased estimator of the classification risk that can be computed only from complementarily labeled data. However, it required a restrictive condition on the loss functions, making it impossible to use popular losses such as the softmax cross-entropy loss. Recently, another formulation with the softmax cross-entropy loss was proposed with consistency guarantee. However, this formulation does not explicitly involve a risk estimator. Thus model/hyper-parameter selection is not possible by cross-validation---we may need additional ordinarily labeled data for validation purposes, which is not available in the current setup. In this paper, we give a novel general framework of complementary-label learning, and derive an unbiased risk estimator for arbitrary losses and models. We further improve the risk estimator by non-negative correction and demonstrate its superiority through experiments.
On the Minimal Supervision for Training Any Binary Classifier from Only Unlabeled Data
Oct 05, 2018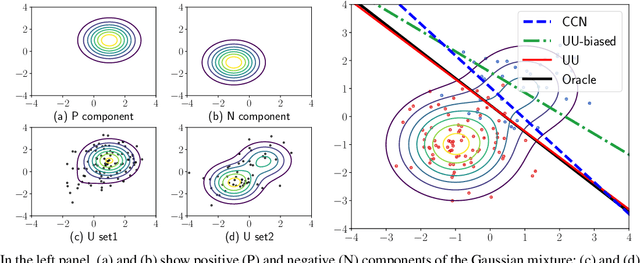
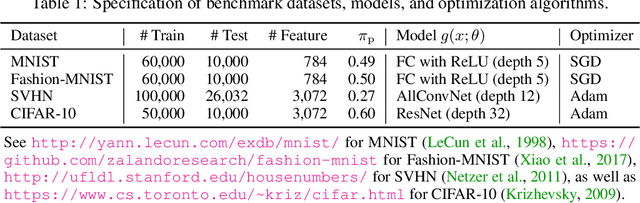
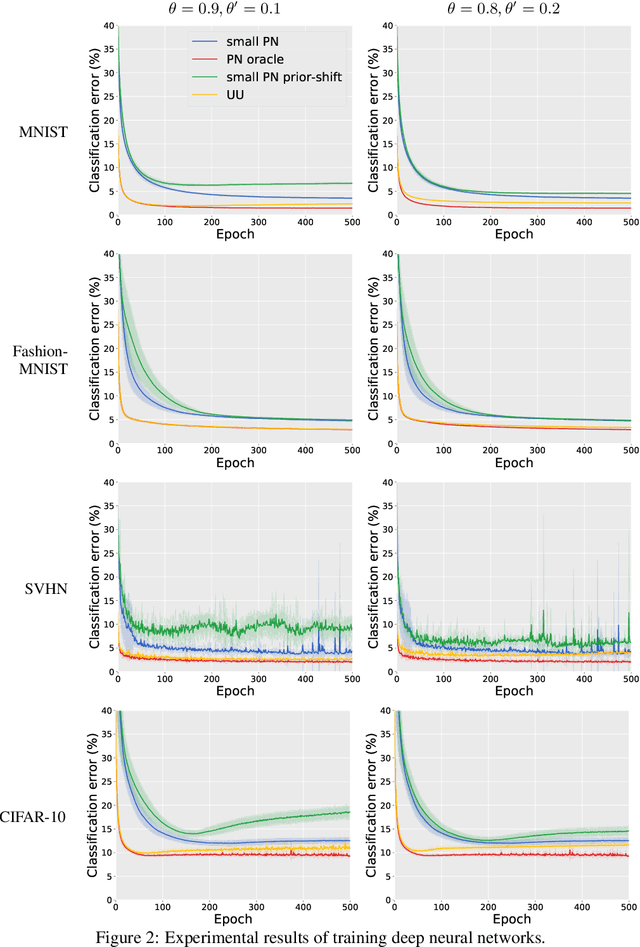
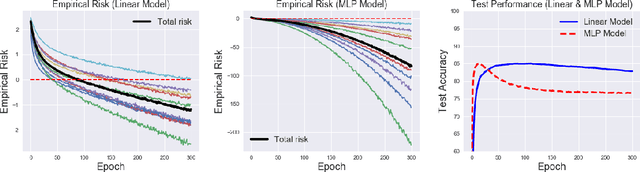
Empirical risk minimization (ERM), with proper loss function and regularization, is the common practice of supervised classification. In this paper, we study training arbitrary (from linear to deep) binary classifier from only unlabeled (U) data by ERM. We prove that it is impossible to estimate the risk of an arbitrary binary classifier in an unbiased manner given a single set of U data, but it becomes possible given two sets of U data with different class priors. These two facts answer a fundamental question---what the minimal supervision is for training any binary classifier from only U data. Following these findings, we propose an ERM-based learning method from two sets of U data, and then prove it is consistent. Experiments demonstrate the proposed method could train deep models and outperform state-of-the-art methods for learning from two sets of U data.
Classification from Positive, Unlabeled and Biased Negative Data
Oct 01, 2018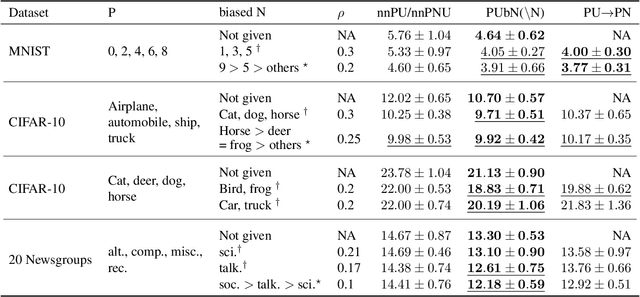
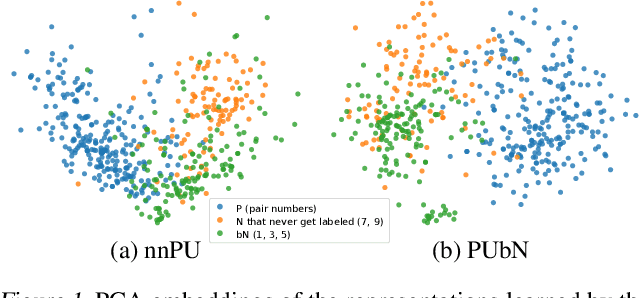
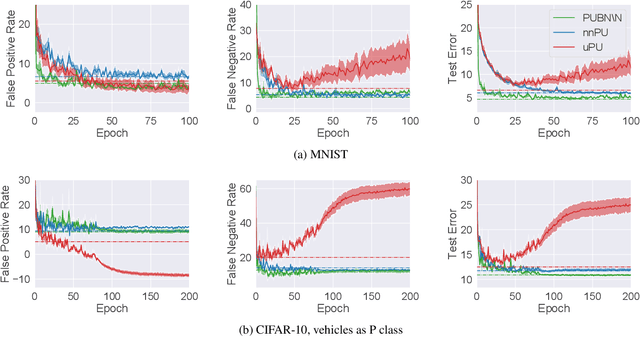
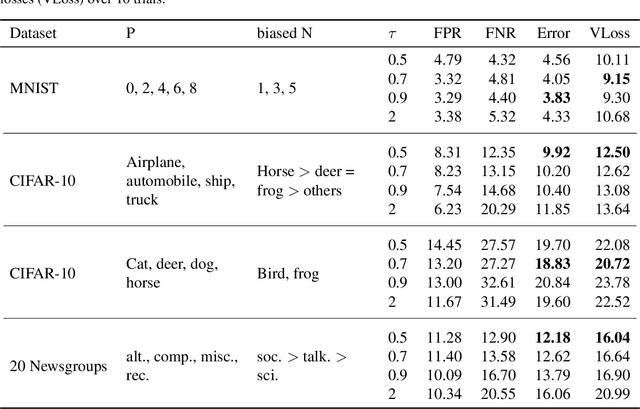
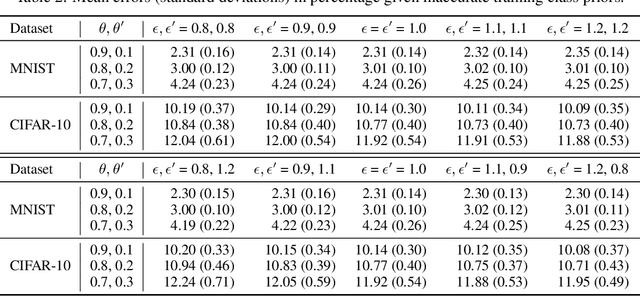
Positive-unlabeled (PU) learning addresses the problem of learning a binary classifier from positive (P) and unlabeled (U) data. It is often applied to situations where negative (N) data are difficult to be fully labeled. However, collecting a non-representative N set that contains only a small portion of all possible N data can be much easier in many practical situations. This paper studies a novel classification framework which incorporates such biased N (bN) data in PU learning. The fact that the training N data are biased also makes our work very different from those of standard semi-supervised learning. We provide an empirical risk minimization-based method to address this PUbN classification problem. Our approach can be regarded as a variant of traditional example-reweighting algorithms, with the weight of each example computed through a preliminary step that draws inspiration from PU learning. We also derive an estimation error bound for the proposed method. Experimental results demonstrate the effectiveness of our algorithm in not only PUbN learning scenarios but also ordinary PU leaning scenarios on several benchmark datasets.
Pumpout: A Meta Approach for Robustly Training Deep Neural Networks with Noisy Labels
Sep 28, 2018
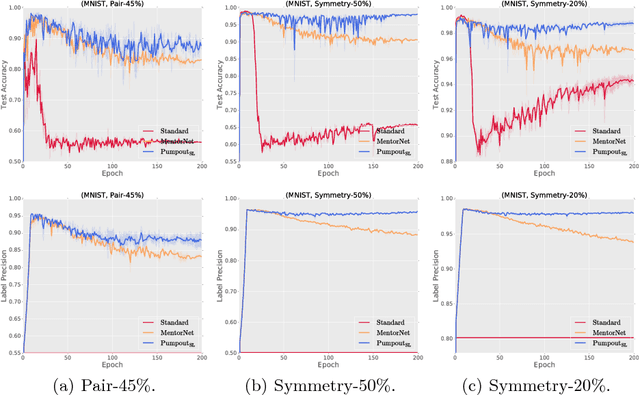
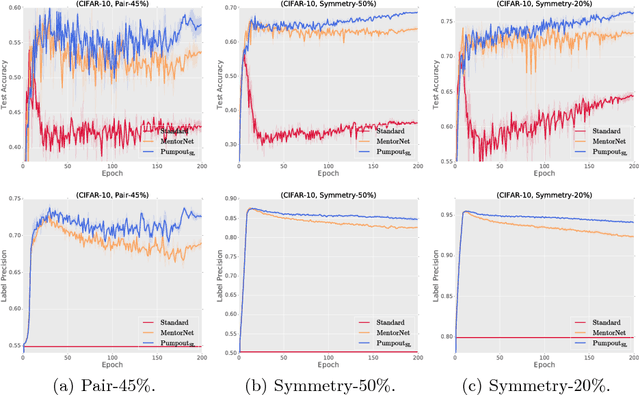
It is challenging to train deep neural networks robustly on the industrial-level data, since labels of such data are heavily noisy, and their label generation processes are normally agnostic. To handle these issues, by using the memorization effects of deep neural networks, we may train deep neural networks on the whole dataset only the first few iterations. Then, we may employ early stopping or the small-loss trick to train them on selected instances. However, in such training procedures, deep neural networks inevitably memorize some noisy labels, which will degrade their generalization. In this paper, we propose a meta algorithm called Pumpout to overcome the problem of memorizing noisy labels. By using scaled stochastic gradient ascent, Pumpout actively squeezes out the negative effects of noisy labels from the training model, instead of passively forgetting these effects. We leverage Pumpout to upgrade two representative methods: MentorNet and Backward Correction. Empirical results on benchmark datasets demonstrate that Pumpout can significantly improve the robustness of representative methods.
Alternate Estimation of a Classifier and the Class-Prior from Positive and Unlabeled Data
Sep 15, 2018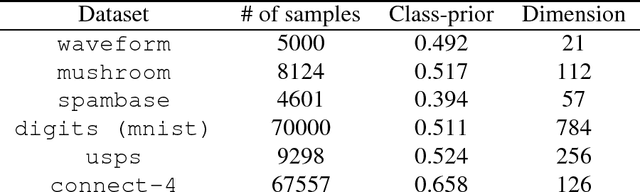
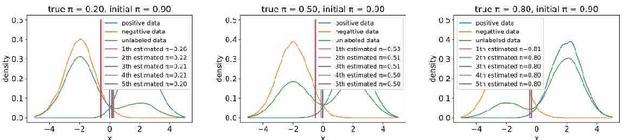
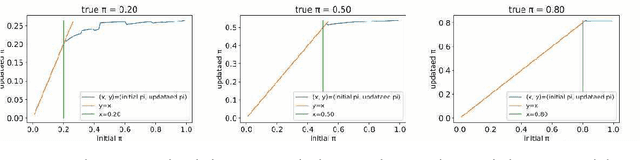
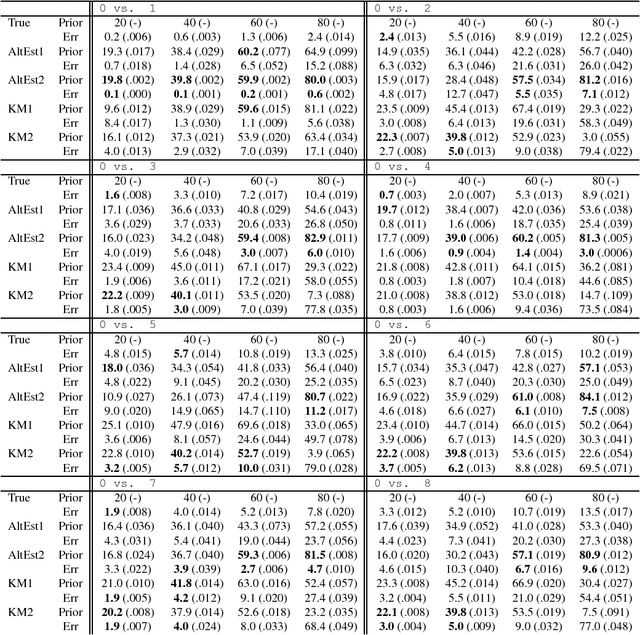
We consider a problem of learning a binary classifier only from positive data and unlabeled data (PU learning) and estimating the class-prior in unlabeled data under the case-control scenario. Most of the recent methods of PU learning require an estimate of the class-prior probability in unlabeled data, and it is estimated in advance with another method. However, such a two-step approach which first estimates the class prior and then trains a classifier may not be the optimal approach since the estimation error of the class-prior is not taken into account when a classifier is trained. In this paper, we propose a novel unified approach to estimating the class-prior and training a classifier alternately. Our proposed method is simple to implement and computationally efficient. Through experiments, we demonstrate the practical usefulness of the proposed method.
Classification from Pairwise Similarity and Unlabeled Data
Aug 15, 2018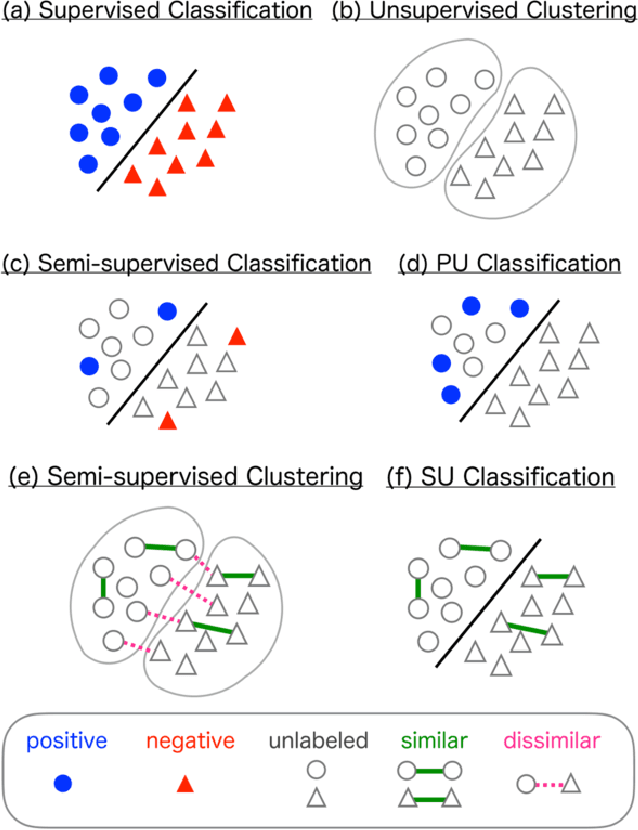
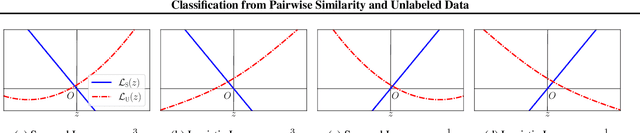
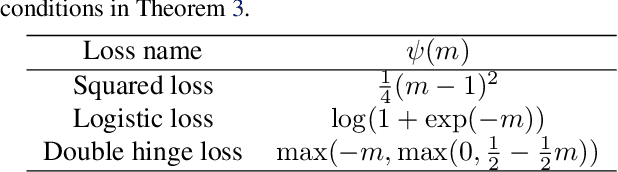
Supervised learning needs a huge amount of labeled data, which can be a big bottleneck under the situation where there is a privacy concern or labeling cost is high. To overcome this problem, we propose a new weakly-supervised learning setting where only similar (S) data pairs (two examples belong to the same class) and unlabeled (U) data points are needed instead of fully labeled data, which is called SU classification. We show that an unbiased estimator of the classification risk can be obtained only from SU data, and the estimation error of its empirical risk minimizer achieves the optimal parametric convergence rate. Finally, we demonstrate the effectiveness of the proposed method through experiments.