 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDICTDIS: Dictionary Constrained Disambiguation for Improved NMT
Oct 13, 2022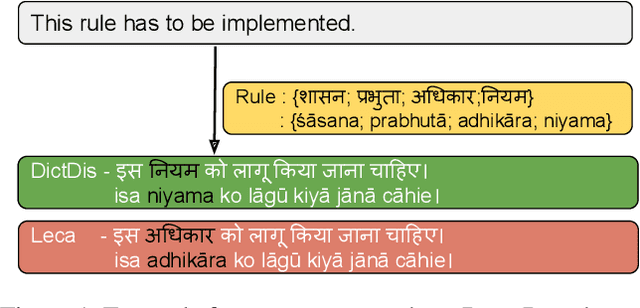

Domain-specific neural machine translation (NMT) systems (e.g., in educational applications) are socially significant with the potential to help make information accessible to a diverse set of users in multilingual societies. It is desirable that such NMT systems be lexically constrained and draw from domain-specific dictionaries. Dictionaries could present multiple candidate translations for a source words/phrases on account of the polysemous nature of words. The onus is then on the NMT model to choose the contextually most appropriate candidate. Prior work has largely ignored this problem and focused on the single candidate setting where the target word or phrase is replaced by a single constraint. In this work we present DICTDIS, a lexically constrained NMT system that disambiguates between multiple candidate translations derived from dictionaries. We achieve this by augmenting training data with multiple dictionary candidates to actively encourage disambiguation during training. We demonstrate the utility of DICTDIS via extensive experiments on English-Hindi sentences in a variety of domains including news, finance, medicine and engineering. We obtain superior disambiguation performance on all domains with improved fluency in some domains of up to 4 BLEU points, when compared with existing approaches for lexically constrained and unconstrained NMT.
AutoML for Climate Change: A Call to Action
Oct 07, 2022


The challenge that climate change poses to humanity has spurred a rapidly developing field of artificial intelligence research focused on climate change applications. The climate change AI (CCAI) community works on a diverse, challenging set of problems which often involve physics-constrained ML or heterogeneous spatiotemporal data. It would be desirable to use automated machine learning (AutoML) techniques to automatically find high-performing architectures and hyperparameters for a given dataset. In this work, we benchmark popular AutoML libraries on three high-leverage CCAI applications: climate modeling, wind power forecasting, and catalyst discovery. We find that out-of-the-box AutoML libraries currently fail to meaningfully surpass the performance of human-designed CCAI models. However, we also identify a few key weaknesses, which stem from the fact that most AutoML techniques are tailored to computer vision and NLP applications. For example, while dozens of search spaces have been designed for image and language data, none have been designed for spatiotemporal data. Addressing these key weaknesses can lead to the discovery of novel architectures that yield substantial performance gains across numerous CCAI applications. Therefore, we present a call to action to the AutoML community, since there are a number of concrete, promising directions for future work in the space of AutoML for CCAI. We release our code and a list of resources at https://github.com/climate-change-automl/climate-change-automl.
DIAGNOSE: Avoiding Out-of-distribution Data using Submodular Information Measures
Oct 04, 2022Avoiding out-of-distribution (OOD) data is critical for training supervised machine learning models in the medical imaging domain. Furthermore, obtaining labeled medical data is difficult and expensive since it requires expert annotators like doctors, radiologists, etc. Active learning (AL) is a well-known method to mitigate labeling costs by selecting the most diverse or uncertain samples. However, current AL methods do not work well in the medical imaging domain with OOD data. We propose Diagnose (avoiDing out-of-dIstribution dAta usinG submodular iNfOrmation meaSurEs), a novel active learning framework that can jointly model similarity and dissimilarity, which is crucial in mining in-distribution data and avoiding OOD data at the same time. Particularly, we use a small number of data points as exemplars that represent a query set of in-distribution data points and a private set of OOD data points. We illustrate the generalizability of our framework by evaluating it on a wide variety of real-world OOD scenarios. Our experiments verify the superiority of Diagnose over the state-of-the-art AL methods across multiple domains of medical imaging.
CLINICAL: Targeted Active Learning for Imbalanced Medical Image Classification
Oct 04, 2022Training deep learning models on medical datasets that perform well for all classes is a challenging task. It is often the case that a suboptimal performance is obtained on some classes due to the natural class imbalance issue that comes with medical data. An effective way to tackle this problem is by using targeted active learning, where we iteratively add data points to the training data that belong to the rare classes. However, existing active learning methods are ineffective in targeting rare classes in medical datasets. In this work, we propose Clinical (targeted aCtive Learning for ImbalaNced medICal imAge cLassification) a framework that uses submodular mutual information functions as acquisition functions to mine critical data points from rare classes. We apply our framework to a wide-array of medical imaging datasets on a variety of real-world class imbalance scenarios - namely, binary imbalance and long-tail imbalance. We show that Clinical outperforms the state-of-the-art active learning methods by acquiring a diverse set of data points that belong to the rare classes.
Counting in the 2020s: Binned Representations and Inclusive Performance Measures for Deep Crowd Counting Approaches
Apr 10, 2022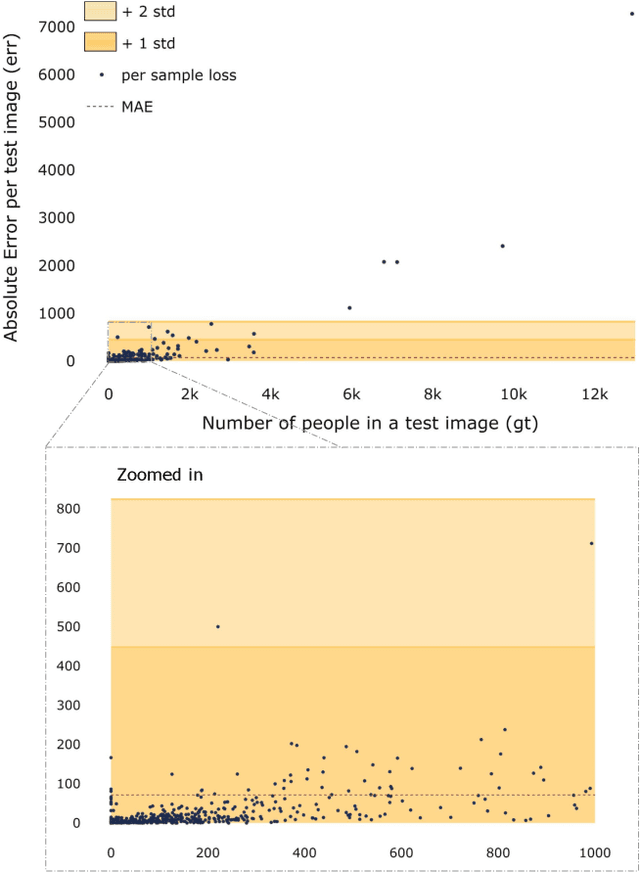
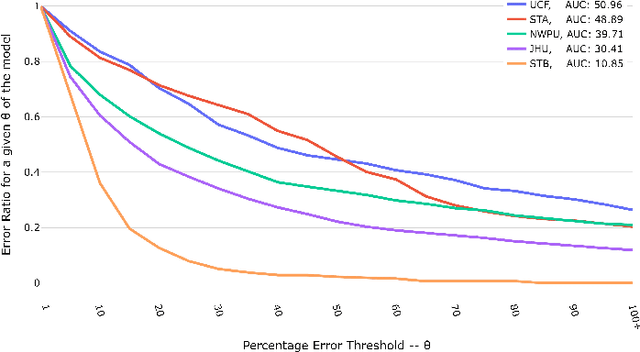
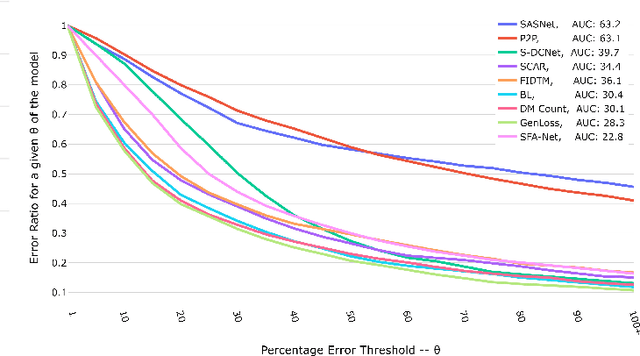
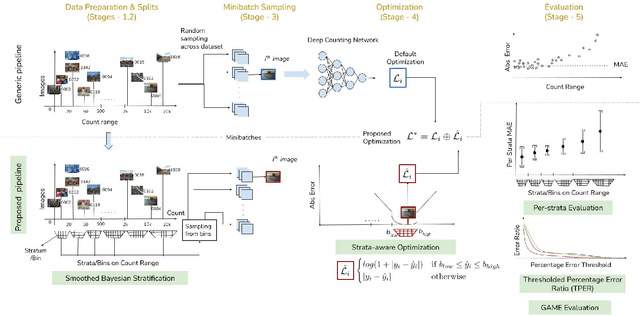
The data distribution in popular crowd counting datasets is typically heavy tailed and discontinuous. This skew affects all stages within the pipelines of deep crowd counting approaches. Specifically, the approaches exhibit unacceptably large standard deviation wrt statistical measures (MSE, MAE). To address such concerns in a holistic manner, we make two fundamental contributions. Firstly, we modify the training pipeline to accommodate the knowledge of dataset skew. To enable principled and balanced minibatch sampling, we propose a novel smoothed Bayesian binning approach. More specifically, we propose a novel cost function which can be readily incorporated into existing crowd counting deep networks to encourage bin-aware optimization. As the second contribution, we introduce additional performance measures which are more inclusive and throw light on various comparative performance aspects of the deep networks. We also show that our binning-based modifications retain their superiority wrt the newly proposed performance measures. Overall, our contributions enable a practically useful and detail-oriented characterization of performance for crowd counting approaches.
Investigating Modality Bias in Audio Visual Video Parsing
Mar 31, 2022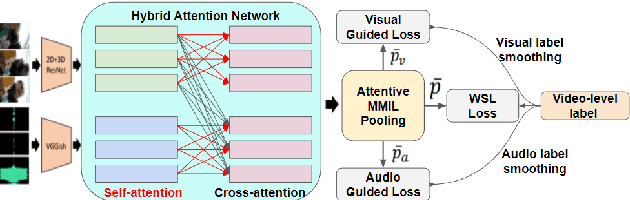
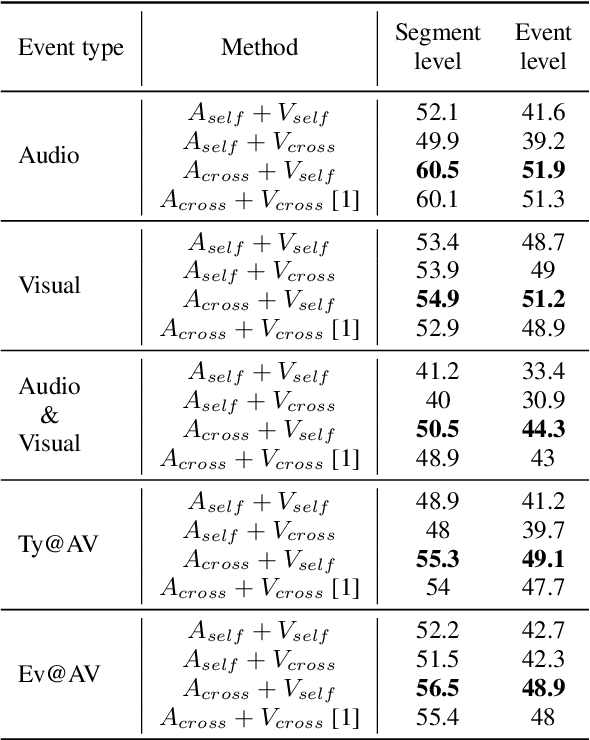
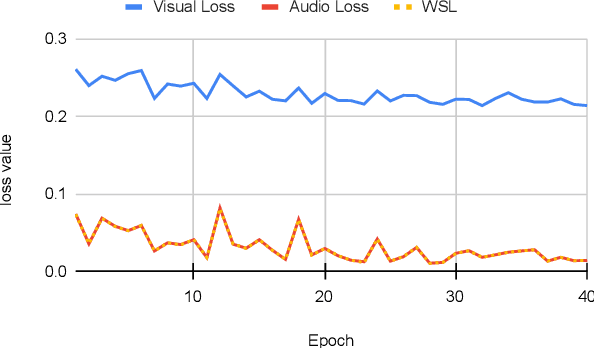
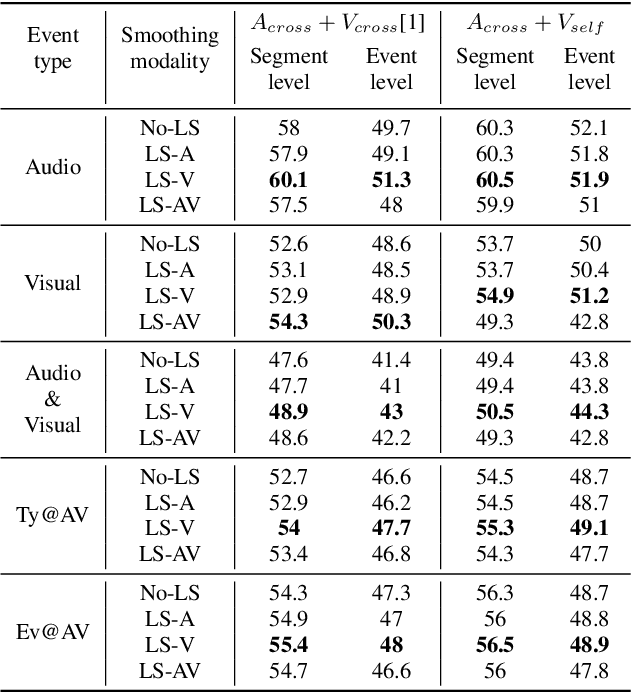
We focus on the audio-visual video parsing (AVVP) problem that involves detecting audio and visual event labels with temporal boundaries. The task is especially challenging since it is weakly supervised with only event labels available as a bag of labels for each video. An existing state-of-the-art model for AVVP uses a hybrid attention network (HAN) to generate cross-modal features for both audio and visual modalities, and an attentive pooling module that aggregates predicted audio and visual segment-level event probabilities to yield video-level event probabilities. We provide a detailed analysis of modality bias in the existing HAN architecture, where a modality is completely ignored during prediction. We also propose a variant of feature aggregation in HAN that leads to an absolute gain in F-scores of about 2% and 1.6% for visual and audio-visual events at both segment-level and event-level, in comparison to the existing HAN model.
AUTOMATA: Gradient Based Data Subset Selection for Compute-Efficient Hyper-parameter Tuning
Mar 15, 2022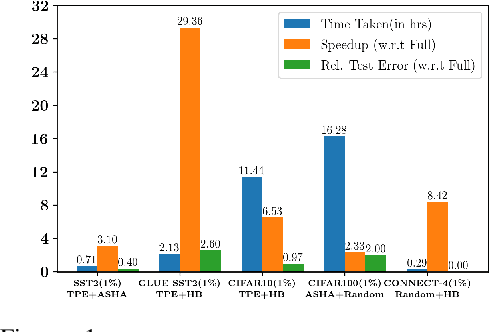


Deep neural networks have seen great success in recent years; however, training a deep model is often challenging as its performance heavily depends on the hyper-parameters used. In addition, finding the optimal hyper-parameter configuration, even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms, can be time-consuming, requiring multiple training runs over the entire dataset for different possible sets of hyper-parameters. Our central insight is that using an informative subset of the dataset for model training runs involved in hyper-parameter optimization, allows us to find the optimal hyper-parameter configuration significantly faster. In this work, we propose AUTOMATA, a gradient-based subset selection framework for hyper-parameter tuning. We empirically evaluate the effectiveness of AUTOMATA in hyper-parameter tuning through several experiments on real-world datasets in the text, vision, and tabular domains. Our experiments show that using gradient-based data subsets for hyper-parameter tuning achieves significantly faster turnaround times and speedups of 3$\times$-30$\times$ while achieving comparable performance to the hyper-parameters found using the entire dataset.
BASIL: Balanced Active Semi-supervised Learning for Class Imbalanced Datasets
Mar 10, 2022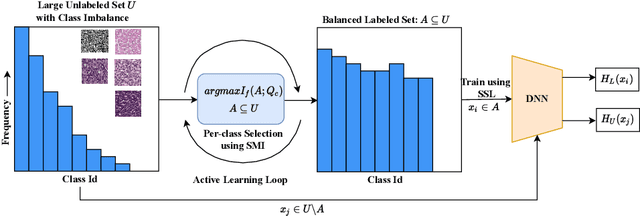

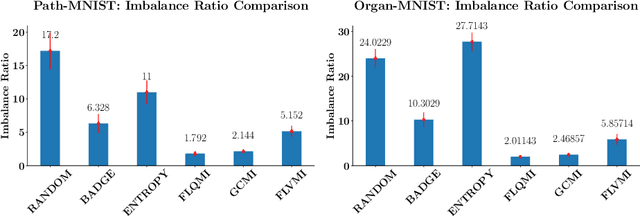
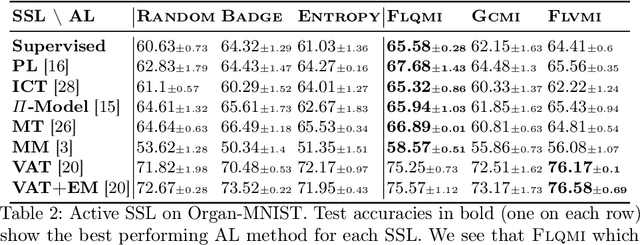
Current semi-supervised learning (SSL) methods assume a balance between the number of data points available for each class in both the labeled and the unlabeled data sets. However, there naturally exists a class imbalance in most real-world datasets. It is known that training models on such imbalanced datasets leads to biased models, which in turn lead to biased predictions towards the more frequent classes. This issue is further pronounced in SSL methods, as they would use this biased model to obtain psuedo-labels (on the unlabeled data) during training. In this paper, we tackle this problem by attempting to select a balanced labeled dataset for SSL that would result in an unbiased model. Unfortunately, acquiring a balanced labeled dataset from a class imbalanced distribution in one shot is challenging. We propose BASIL (Balanced Active Semi-supervIsed Learning), a novel algorithm that optimizes the submodular mutual information (SMI) functions in a per-class fashion to gradually select a balanced dataset in an active learning loop. Importantly, our technique can be efficiently used to improve the performance of any SSL method. Our experiments on Path-MNIST and Organ-MNIST medical datasets for a wide array of SSL methods show the effectiveness of Basil. Furthermore, we observe that Basil outperforms the state-of-the-art diversity and uncertainty based active learning methods since the SMI functions select a more balanced dataset.
UDAAN - Machine Learning based Post-Editing tool for Document Translation
Mar 03, 2022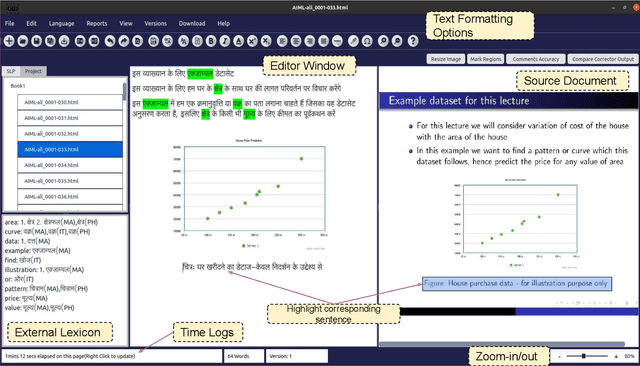
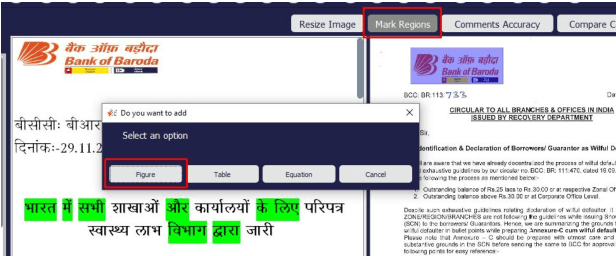
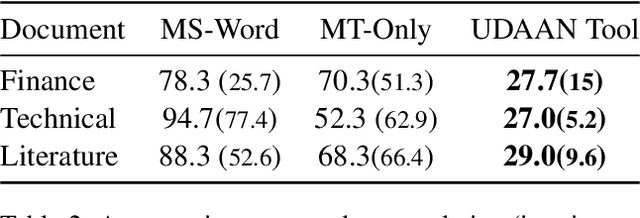
We introduce UDAAN, an open-source post-editing tool that can reduce manual editing efforts to quickly produce publishable-standard documents in different languages. UDAAN has an end-to-end Machine Translation (MT) plus post-editing pipeline wherein users can upload a document to obtain raw MT output. Further, users can edit the raw translations using our tool. UDAAN offers several advantages: a) Domain-aware, vocabulary-based lexical constrained MT. b) source-target and target-target lexicon suggestions for users. Replacements are based on the source and target texts lexicon alignment. c) Suggestions for translations are based on logs created during user interaction. d) Source-target sentence alignment visualisation that reduces the cognitive load of users during editing. e) Translated outputs from our tool are available in multiple formats: docs, latex, and PDF. Although we limit our experiments to English-to-Hindi translation for the current study, our tool is independent of the source and target languages. Experimental results based on the usage of the tools and users feedback show that our tool speeds up the translation time approximately by a factor of three compared to the baseline method of translating documents from scratch.
Submodlib: A Submodular Optimization Library
Feb 23, 2022
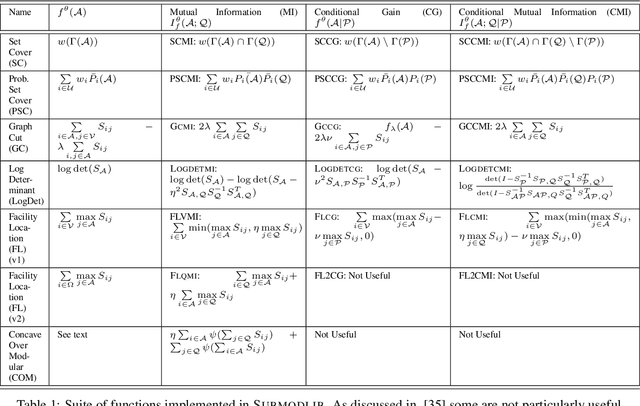

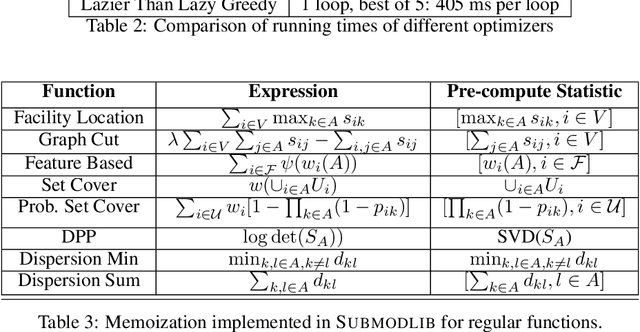
Submodular functions are a special class of set functions which naturally model the notion of representativeness, diversity, coverage etc. and have been shown to be computationally very efficient. A lot of past work has applied submodular optimization to find optimal subsets in various contexts. Some examples include data summarization for efficient human consumption, finding effective smaller subsets of training data to reduce the model development time (training, hyper parameter tuning), finding effective subsets of unlabeled data to reduce the labeling costs, etc. A recent work has also leveraged submodular functions to propose submodular information measures which have been found to be very useful in solving the problems of guided subset selection and guided summarization. In this work, we present Submodlib which is an open-source, easy-to-use, efficient and scalable Python library for submodular optimization with a C++ optimization engine. Submodlib finds its application in summarization, data subset selection, hyper parameter tuning, efficient training and more. Through a rich API, it offers a great deal of flexibility in the way it can be used. Source of Submodlib is available at https://github.com/decile-team/submodlib.