 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Price of Meaning: Why Every Semantic Memory System Forgets
Mar 28, 2026Every major AI memory system in production today organises information by meaning. That organisation enables generalisation, analogy, and conceptual retrieval -- but it comes at a price. We prove that the same geometric structure enabling semantic generalisation makes interference, forgetting, and false recall inescapable. We formalise this tradeoff for \textit{semantically continuous kernel-threshold memories}: systems whose retrieval score is a monotone function of an inner product in a semantic feature space with finite local intrinsic dimension. Within this class we derive four results: (1) semantically useful representations have finite effective rank; (2) finite local dimension implies positive competitor mass in retrieval neighbourhoods; (3) under growing memory, retention decays to zero, yielding power-law forgetting curves under power-law arrival statistics; (4) for associative lures satisfying a $δ$-convexity condition, false recall cannot be eliminated by threshold tuning. We test these predictions across five architectures: vector retrieval, graph memory, attention-based context, BM25 filesystem retrieval, and parametric memory. Pure semantic systems express the vulnerability directly as forgetting and false recall. Reasoning-augmented systems partially override these symptoms but convert graceful degradation into catastrophic failure. Systems that escape interference entirely do so by sacrificing semantic generalisation. The price of meaning is interference, and no architecture we tested avoids paying it.
K-Dense Analyst: Towards Fully Automated Scientific Analysis
Aug 09, 2025The complexity of modern bioinformatics analysis has created a critical gap between data generation and developing scientific insights. While large language models (LLMs) have shown promise in scientific reasoning, they remain fundamentally limited when dealing with real-world analytical workflows that demand iterative computation, tool integration and rigorous validation. We introduce K-Dense Analyst, a hierarchical multi-agent system that achieves autonomous bioinformatics analysis through a dual-loop architecture. K-Dense Analyst, part of the broader K-Dense platform, couples planning with validated execution using specialized agents to decompose complex objectives into executable, verifiable tasks within secure computational environments. On BixBench, a comprehensive benchmark for open-ended biological analysis, K-Dense Analyst achieves 29.2% accuracy, surpassing the best-performing language model (GPT-5) by 6.3 percentage points, representing nearly 27% improvement over what is widely considered the most powerful LLM available. Remarkably, K-Dense Analyst achieves this performance using Gemini 2.5 Pro, which attains only 18.3% accuracy when used directly, demonstrating that our architectural innovations unlock capabilities far beyond the underlying model's baseline performance. Our insights demonstrate that autonomous scientific reasoning requires more than enhanced language models, it demands purpose-built systems that can bridge the gap between high-level scientific objectives and low-level computational execution. These results represent a significant advance toward fully autonomous computational biologists capable of accelerating discovery across the life sciences.
Chaining thoughts and LLMs to learn DNA structural biophysics
Mar 02, 2024The future development of an AI scientist, a tool that is capable of integrating a variety of experimental data and generating testable hypotheses, holds immense potential. So far, bespoke machine learning models have been created to specialize in singular scientific tasks, but otherwise lack the flexibility of a general purpose model. Here, we show that a general purpose large language model, chatGPT 3.5-turbo, can be fine-tuned to learn the structural biophysics of DNA. We find that both fine-tuning models to return chain-of-thought responses and chaining together models fine-tuned for subtasks have an enhanced ability to analyze and design DNA sequences and their structures.
Reflexion: an autonomous agent with dynamic memory and self-reflection
Mar 20, 2023



Recent advancements in decision-making large language model (LLM) agents have demonstrated impressive performance across various benchmarks. However, these state-of-the-art approaches typically necessitate internal model fine-tuning, external model fine-tuning, or policy optimization over a defined state space. Implementing these methods can prove challenging due to the scarcity of high-quality training data or the lack of well-defined state space. Moreover, these agents do not possess certain qualities inherent to human decision-making processes, specifically the ability to learn from mistakes. Self-reflection allows humans to efficiently solve novel problems through a process of trial and error. Building on recent research, we propose Reflexion, an approach that endows an agent with dynamic memory and self-reflection capabilities to enhance its existing reasoning trace and task-specific action choice abilities. To achieve full automation, we introduce a straightforward yet effective heuristic that enables the agent to pinpoint hallucination instances, avoid repetition in action sequences, and, in some environments, construct an internal memory map of the given environment. To assess our approach, we evaluate the agent's ability to complete decision-making tasks in AlfWorld environments and knowledge-intensive, search-based question-and-answer tasks in HotPotQA environments. We observe success rates of 97% and 51%, respectively, and provide a discussion on the emergent property of self-reflection.
Counting in the 2020s: Binned Representations and Inclusive Performance Measures for Deep Crowd Counting Approaches
Apr 10, 2022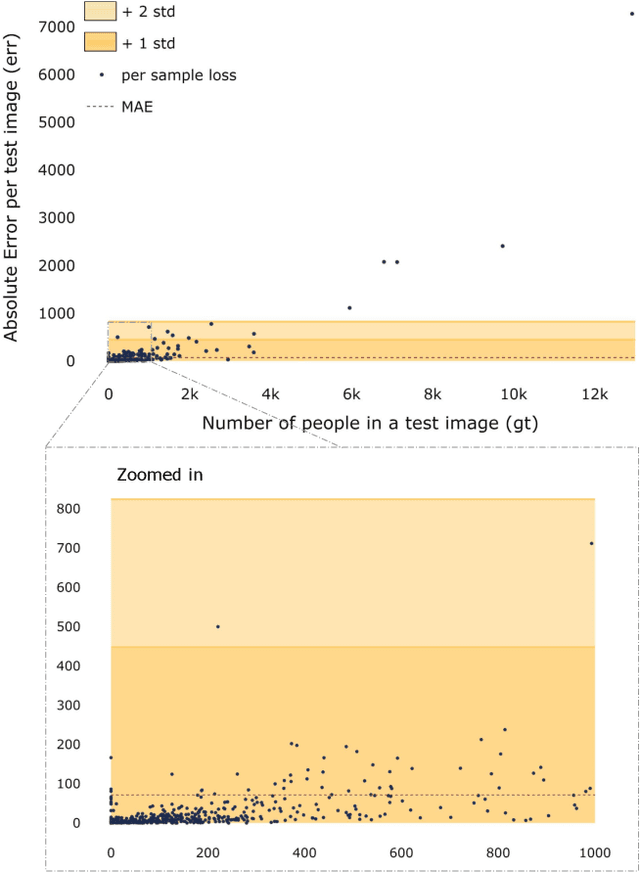
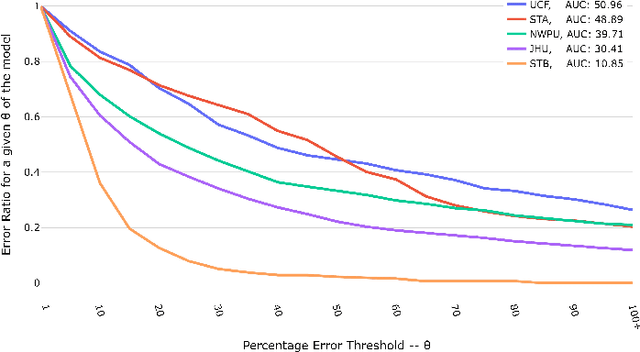
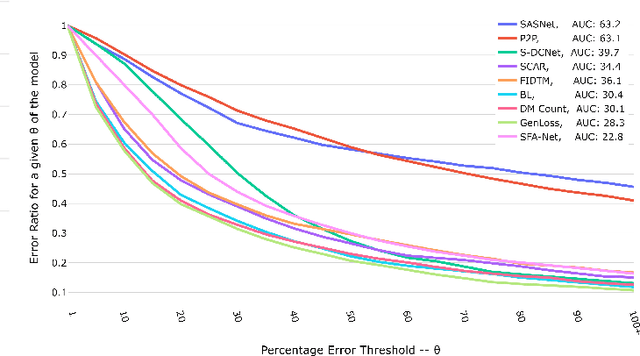
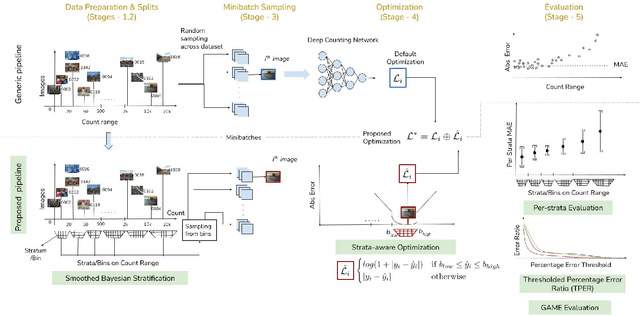
The data distribution in popular crowd counting datasets is typically heavy tailed and discontinuous. This skew affects all stages within the pipelines of deep crowd counting approaches. Specifically, the approaches exhibit unacceptably large standard deviation wrt statistical measures (MSE, MAE). To address such concerns in a holistic manner, we make two fundamental contributions. Firstly, we modify the training pipeline to accommodate the knowledge of dataset skew. To enable principled and balanced minibatch sampling, we propose a novel smoothed Bayesian binning approach. More specifically, we propose a novel cost function which can be readily incorporated into existing crowd counting deep networks to encourage bin-aware optimization. As the second contribution, we introduce additional performance measures which are more inclusive and throw light on various comparative performance aspects of the deep networks. We also show that our binning-based modifications retain their superiority wrt the newly proposed performance measures. Overall, our contributions enable a practically useful and detail-oriented characterization of performance for crowd counting approaches.