 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Conventions: Equilibrium Computation as a Model of Pragmatic Reasoning
Nov 16, 2023



We present a model of pragmatic language understanding, where utterances are produced and understood by searching for regularized equilibria of signaling games. In this model (which we call ReCo, for Regularized Conventions), speakers and listeners search for contextually appropriate utterance--meaning mappings that are both close to game-theoretically optimal conventions and close to a shared, ''default'' semantics. By characterizing pragmatic communication as equilibrium search, we obtain principled sampling algorithms and formal guarantees about the trade-off between communicative success and naturalness. Across several datasets capturing real and idealized human judgments about pragmatic implicatures, ReCo matches or improves upon predictions made by best response and rational speech act models of language understanding.
Last-Iterate Convergence Properties of Regret-Matching Algorithms in Games
Nov 01, 2023Algorithms based on regret matching, specifically regret matching$^+$ (RM$^+$), and its variants are the most popular approaches for solving large-scale two-player zero-sum games in practice. Unlike algorithms such as optimistic gradient descent ascent, which have strong last-iterate and ergodic convergence properties for zero-sum games, virtually nothing is known about the last-iterate properties of regret-matching algorithms. Given the importance of last-iterate convergence for numerical optimization reasons and relevance as modeling real-word learning in games, in this paper, we study the last-iterate convergence properties of various popular variants of RM$^+$. First, we show numerically that several practical variants such as simultaneous RM$^+$, alternating RM$^+$, and simultaneous predictive RM$^+$, all lack last-iterate convergence guarantees even on a simple $3\times 3$ game. We then prove that recent variants of these algorithms based on a smoothing technique do enjoy last-iterate convergence: we prove that extragradient RM$^{+}$ and smooth Predictive RM$^+$ enjoy asymptotic last-iterate convergence (without a rate) and $1/\sqrt{t}$ best-iterate convergence. Finally, we introduce restarted variants of these algorithms, and show that they enjoy linear-rate last-iterate convergence.
The Consensus Game: Language Model Generation via Equilibrium Search
Oct 13, 2023



When applied to question answering and other text generation tasks, language models (LMs) may be queried generatively (by sampling answers from their output distribution) or discriminatively (by using them to score or rank a set of candidate outputs). These procedures sometimes yield very different predictions. How do we reconcile mutually incompatible scoring procedures to obtain coherent LM predictions? We introduce a new, a training-free, game-theoretic procedure for language model decoding. Our approach casts language model decoding as a regularized imperfect-information sequential signaling game - which we term the CONSENSUS GAME - in which a GENERATOR seeks to communicate an abstract correctness parameter using natural language sentences to a DISCRIMINATOR. We develop computational procedures for finding approximate equilibria of this game, resulting in a decoding algorithm we call EQUILIBRIUM-RANKING. Applied to a large number of tasks (including reading comprehension, commonsense reasoning, mathematical problem-solving, and dialog), EQUILIBRIUM-RANKING consistently, and sometimes substantially, improves performance over existing LM decoding procedures - on multiple benchmarks, we observe that applying EQUILIBRIUM-RANKING to LLaMA-7B outperforms the much larger LLaMA-65B and PaLM-540B models. These results highlight the promise of game-theoretic tools for addressing fundamental challenges of truthfulness and consistency in LMs.
Regret Matching+: (In)Stability and Fast Convergence in Games
May 24, 2023Regret Matching+ (RM+) and its variants are important algorithms for solving large-scale games. However, a theoretical understanding of their success in practice is still a mystery. Moreover, recent advances on fast convergence in games are limited to no-regret algorithms such as online mirror descent, which satisfy stability. In this paper, we first give counterexamples showing that RM+ and its predictive version can be unstable, which might cause other players to suffer large regret. We then provide two fixes: restarting and chopping off the positive orthant that RM+ works in. We show that these fixes are sufficient to get $O(T^{1/4})$ individual regret and $O(1)$ social regret in normal-form games via RM+ with predictions. We also apply our stabilizing techniques to clairvoyant updates in the uncoupled learning setting for RM+ and prove desirable results akin to recent works for Clairvoyant online mirror descent. Our experiments show the advantages of our algorithms over vanilla RM+-based algorithms in matrix and extensive-form games.
The Update Equivalence Framework for Decision-Time Planning
Apr 25, 2023



The process of revising (or constructing) a policy immediately prior to execution -- known as decision-time planning -- is key to achieving superhuman performance in perfect-information settings like chess and Go. A recent line of work has extended decision-time planning to more general imperfect-information settings, leading to superhuman performance in poker. However, these methods requires considering subgames whose sizes grow quickly in the amount of non-public information, making them unhelpful when the amount of non-public information is large. Motivated by this issue, we introduce an alternative framework for decision-time planning that is not based on subgames but rather on the notion of update equivalence. In this framework, decision-time planning algorithms simulate updates of synchronous learning algorithms. This framework enables us to introduce a new family of principled decision-time planning algorithms that do not rely on public information, opening the door to sound and effective decision-time planning in settings with large amounts of non-public information. In experiments, members of this family produce comparable or superior results compared to state-of-the-art approaches in Hanabi and improve performance in 3x3 Abrupt Dark Hex and Phantom Tic-Tac-Toe.
On the Convergence of No-Regret Learning Dynamics in Time-Varying Games
Jan 26, 2023



Most of the literature on learning in games has focused on the restrictive setting where the underlying repeated game does not change over time. Much less is known about the convergence of no-regret learning algorithms in dynamic multiagent settings. In this paper, we characterize the convergence of \emph{optimistic gradient descent (OGD)} in time-varying games by drawing a strong connection with \emph{dynamic regret}. Our framework yields sharp convergence bounds for the equilibrium gap of OGD in zero-sum games parameterized on the \emph{minimal} first-order variation of the Nash equilibria and the second-order variation of the payoff matrices, subsuming known results for static games. Furthermore, we establish improved \emph{second-order} variation bounds under strong convexity-concavity, as long as each game is repeated multiple times. Our results also apply to time-varying \emph{general-sum} multi-player games via a bilinear formulation of correlated equilibria, which has novel implications for meta-learning and for obtaining refined variation-dependent regret bounds, addressing questions left open in prior papers. Finally, we leverage our framework to also provide new insights on dynamic regret guarantees in static games.
Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning
Oct 11, 2022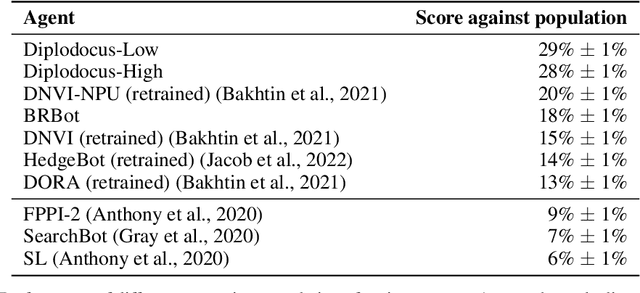

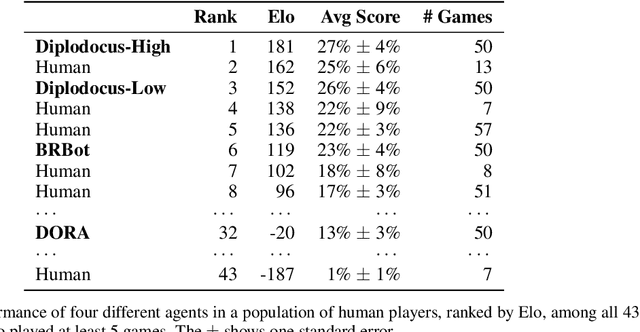
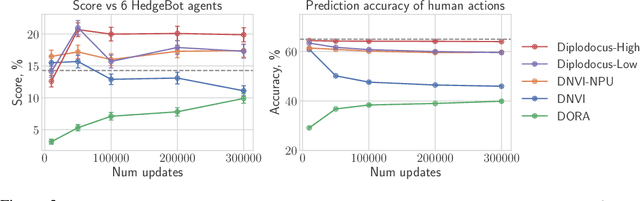
No-press Diplomacy is a complex strategy game involving both cooperation and competition that has served as a benchmark for multi-agent AI research. While self-play reinforcement learning has resulted in numerous successes in purely adversarial games like chess, Go, and poker, self-play alone is insufficient for achieving optimal performance in domains involving cooperation with humans. We address this shortcoming by first introducing a planning algorithm we call DiL-piKL that regularizes a reward-maximizing policy toward a human imitation-learned policy. We prove that this is a no-regret learning algorithm under a modified utility function. We then show that DiL-piKL can be extended into a self-play reinforcement learning algorithm we call RL-DiL-piKL that provides a model of human play while simultaneously training an agent that responds well to this human model. We used RL-DiL-piKL to train an agent we name Diplodocus. In a 200-game no-press Diplomacy tournament involving 62 human participants spanning skill levels from beginner to expert, two Diplodocus agents both achieved a higher average score than all other participants who played more than two games, and ranked first and third according to an Elo ratings model.
Near-Optimal $Φ$-Regret Learning in Extensive-Form Games
Aug 20, 2022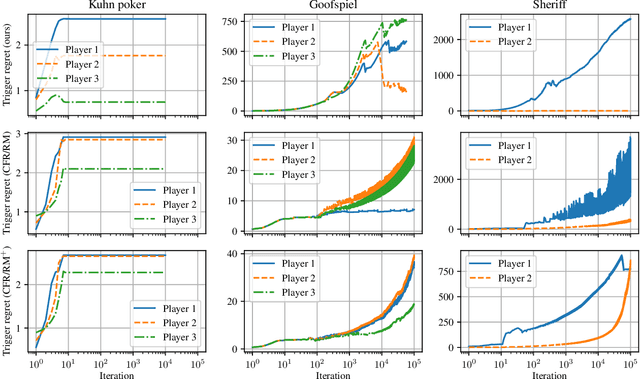
In this paper, we establish efficient and uncoupled learning dynamics so that, when employed by all players in multiplayer perfect-recall imperfect-information extensive-form games, the \emph{trigger regret} of each player grows as $O(\log T)$ after $T$ repetitions of play. This improves exponentially over the prior best known trigger-regret bound of $O(T^{1/4})$, and settles a recent open question by Bai et al. (2022). As an immediate consequence, we guarantee convergence to the set of \emph{extensive-form correlated equilibria} and \emph{coarse correlated equilibria} at a near-optimal rate of $\frac{\log T}{T}$. Building on prior work, at the heart of our construction lies a more general result regarding fixed points deriving from rational functions with \emph{polynomial degree}, a property that we establish for the fixed points of \emph{(coarse) trigger deviation functions}. Moreover, our construction leverages a refined \textit{regret circuit} for the convex hull, which -- unlike prior guarantees -- preserves the \emph{RVU property} introduced by Syrgkanis et al. (NIPS, 2015); this observation has an independent interest in establishing near-optimal regret under learning dynamics based on a CFR-type decomposition of the regret.
Near-Optimal No-Regret Learning for General Convex Games
Jun 20, 2022
A recent line of work has established uncoupled learning dynamics such that, when employed by all players in a game, each player's \emph{regret} after $T$ repetitions grows polylogarithmically in $T$, an exponential improvement over the traditional guarantees within the no-regret framework. However, so far these results have only been limited to certain classes of games with structured strategy spaces -- such as normal-form and extensive-form games. The question as to whether $O(\text{polylog} T)$ regret bounds can be obtained for general convex and compact strategy sets -- which occur in many fundamental models in economics and multiagent systems -- while retaining efficient strategy updates is an important question. In this paper, we answer this in the positive by establishing the first uncoupled learning algorithm with $O(\log T)$ per-player regret in general \emph{convex games}, that is, games with concave utility functions supported on arbitrary convex and compact strategy sets. Our learning dynamics are based on an instantiation of optimistic follow-the-regularized-leader over an appropriately \emph{lifted} space using a \emph{self-concordant regularizer} that is, peculiarly, not a barrier for the feasible region. Further, our learning dynamics are efficiently implementable given access to a proximal oracle for the convex strategy set, leading to $O(\log\log T)$ per-iteration complexity; we also give extensions when access to only a \emph{linear} optimization oracle is assumed. Finally, we adapt our dynamics to guarantee $O(\sqrt{T})$ regret in the adversarial regime. Even in those special cases where prior results apply, our algorithm improves over the state-of-the-art regret bounds either in terms of the dependence on the number of iterations or on the dimension of the strategy sets.
ESCHER: Eschewing Importance Sampling in Games by Computing a History Value Function to Estimate Regret
Jun 08, 2022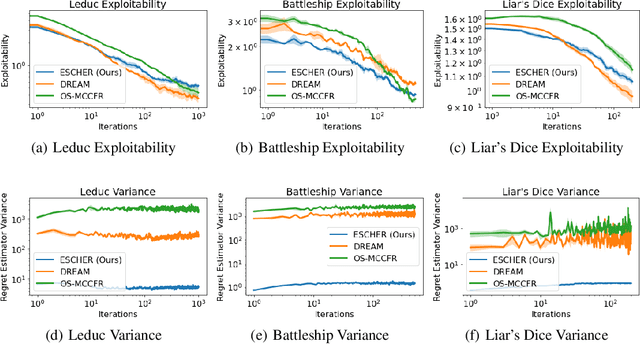

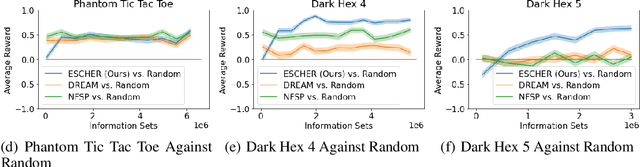

Recent techniques for approximating Nash equilibria in very large games leverage neural networks to learn approximately optimal policies (strategies). One promising line of research uses neural networks to approximate counterfactual regret minimization (CFR) or its modern variants. DREAM, the only current CFR-based neural method that is model free and therefore scalable to very large games, trains a neural network on an estimated regret target that can have extremely high variance due to an importance sampling term inherited from Monte Carlo CFR (MCCFR). In this paper we propose an unbiased model-free method that does not require any importance sampling. Our method, ESCHER, is principled and is guaranteed to converge to an approximate Nash equilibrium with high probability in the tabular case. We show that the variance of the estimated regret of a tabular version of ESCHER with an oracle value function is significantly lower than that of outcome sampling MCCFR and tabular DREAM with an oracle value function. We then show that a deep learning version of ESCHER outperforms the prior state of the art -- DREAM and neural fictitious self play (NFSP) -- and the difference becomes dramatic as game size increases.