 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsking the Right Questions: Improving Reasoning with Generated Stepping Stones
Feb 22, 2026Recent years have witnessed tremendous progress in enabling LLMs to solve complex reasoning tasks such as math and coding. As we start to apply LLMs to harder tasks that they may not be able to solve in one shot, it is worth paying attention to their ability to construct intermediate stepping stones that prepare them to better solve the tasks. Examples of stepping stones include simplifications, alternative framings, or subproblems. We study properties and benefits of stepping stones in the context of modern reasoning LLMs via ARQ (\textbf{A}king the \textbf{R}ight \textbf{Q}uestions), our simple framework which introduces a question generator to the default reasoning pipeline. We first show that good stepping stone questions exist and are transferrable, meaning that good questions can be generated, and they substantially help LLMs of various capabilities in solving the target tasks. We next frame stepping stone generation as a post-training task and show that we can fine-tune LLMs to generate more useful stepping stones by SFT and RL on synthetic data.
A Scalable Measure of Loss Landscape Curvature for Analyzing the Training Dynamics of LLMs
Jan 23, 2026Understanding the curvature evolution of the loss landscape is fundamental to analyzing the training dynamics of neural networks. The most commonly studied measure, Hessian sharpness ($λ_{\max}^H$) -- the largest eigenvalue of the loss Hessian -- determines local training stability and interacts with the learning rate throughout training. Despite its significance in analyzing training dynamics, direct measurement of Hessian sharpness remains prohibitive for Large Language Models (LLMs) due to high computational cost. We analyze $\textit{critical sharpness}$ ($λ_c$), a computationally efficient measure requiring fewer than $10$ forward passes given the update direction $Δ\mathbfθ$. Critically, this measure captures well-documented Hessian sharpness phenomena, including progressive sharpening and Edge of Stability. Using this measure, we provide the first demonstration of these sharpness phenomena at scale, up to $7$B parameters, spanning both pre-training and mid-training of OLMo-2 models. We further introduce $\textit{relative critical sharpness}$ ($λ_c^{1\to 2}$), which quantifies the curvature of one loss landscape while optimizing another, to analyze the transition from pre-training to fine-tuning and guide data mixing strategies. Critical sharpness provides practitioners with a practical tool for diagnosing curvature dynamics and informing data composition choices at scale. More broadly, our work shows that scalable curvature measures can provide actionable insights for large-scale training.
Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning
Oct 11, 2022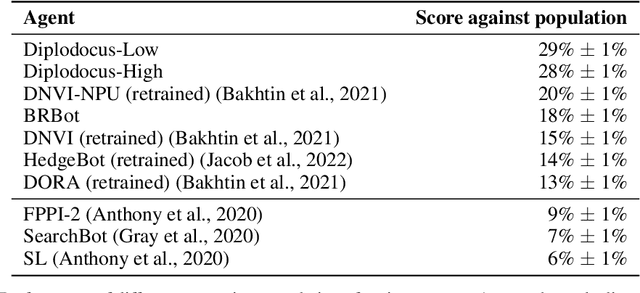

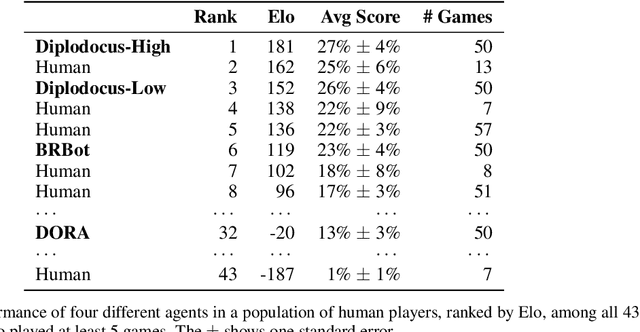
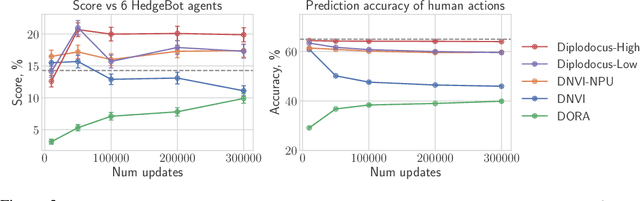
No-press Diplomacy is a complex strategy game involving both cooperation and competition that has served as a benchmark for multi-agent AI research. While self-play reinforcement learning has resulted in numerous successes in purely adversarial games like chess, Go, and poker, self-play alone is insufficient for achieving optimal performance in domains involving cooperation with humans. We address this shortcoming by first introducing a planning algorithm we call DiL-piKL that regularizes a reward-maximizing policy toward a human imitation-learned policy. We prove that this is a no-regret learning algorithm under a modified utility function. We then show that DiL-piKL can be extended into a self-play reinforcement learning algorithm we call RL-DiL-piKL that provides a model of human play while simultaneously training an agent that responds well to this human model. We used RL-DiL-piKL to train an agent we name Diplodocus. In a 200-game no-press Diplomacy tournament involving 62 human participants spanning skill levels from beginner to expert, two Diplodocus agents both achieved a higher average score than all other participants who played more than two games, and ranked first and third according to an Elo ratings model.