 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Reasoning Failures via Synthetic Data Generation
Apr 20, 2025Training models on synthetic data has emerged as an increasingly important strategy for improving the performance of generative AI. This approach is particularly helpful for large multimodal models (LMMs) due to the relative scarcity of high-quality paired image-text data compared to language-only data. While a variety of methods have been proposed for generating large multimodal datasets, they do not tailor the synthetic data to address specific deficiencies in the reasoning abilities of LMMs which will be trained with the generated dataset. In contrast, humans often learn in a more efficient manner by seeking out examples related to the types of reasoning where they have failed previously. Inspired by this observation, we propose a new approach for synthetic data generation which is grounded in the analysis of an existing LMM's reasoning failures. Our methodology leverages frontier models to automatically analyze errors produced by a weaker LMM and propose new examples which can be used to correct the reasoning failure via additional training, which are then further filtered to ensure high quality. We generate a large multimodal instruction tuning dataset containing over 553k examples using our approach and conduct extensive experiments demonstrating its utility for improving the performance of LMMs on multiple downstream tasks. Our results show that models trained on our synthetic data can even exceed the performance of LMMs trained on an equivalent amount of additional real data, demonstrating the high value of generating synthetic data targeted to specific reasoning failure modes in LMMs. We will make our dataset and code publicly available.
FiVL: A Framework for Improved Vision-Language Alignment
Dec 19, 2024



Large Vision Language Models (LVLMs) have achieved significant progress in integrating visual and textual inputs for multimodal reasoning. However, a recurring challenge is ensuring these models utilize visual information as effectively as linguistic content when both modalities are necessary to formulate an accurate answer. We hypothesize that hallucinations arise due to the lack of effective visual grounding in current LVLMs. This issue extends to vision-language benchmarks, where it is difficult to make the image indispensable for accurate answer generation, particularly in vision question-answering tasks. In this work, we introduce FiVL, a novel method for constructing datasets designed to train LVLMs for enhanced visual grounding and to evaluate their effectiveness in achieving it. These datasets can be utilized for both training and assessing an LVLM's ability to use image content as substantive evidence rather than relying solely on linguistic priors, providing insights into the model's reliance on visual information. To demonstrate the utility of our dataset, we introduce an innovative training task that outperforms baselines alongside a validation method and application for explainability. The code is available at https://github.com/IntelLabs/fivl.
LVLM-Intrepret: An Interpretability Tool for Large Vision-Language Models
Apr 03, 2024



In the rapidly evolving landscape of artificial intelligence, multi-modal large language models are emerging as a significant area of interest. These models, which combine various forms of data input, are becoming increasingly popular. However, understanding their internal mechanisms remains a complex task. Numerous advancements have been made in the field of explainability tools and mechanisms, yet there is still much to explore. In this work, we present a novel interactive application aimed towards understanding the internal mechanisms of large vision-language models. Our interface is designed to enhance the interpretability of the image patches, which are instrumental in generating an answer, and assess the efficacy of the language model in grounding its output in the image. With our application, a user can systematically investigate the model and uncover system limitations, paving the way for enhancements in system capabilities. Finally, we present a case study of how our application can aid in understanding failure mechanisms in a popular large multi-modal model: LLaVA.
Getting it Right: Improving Spatial Consistency in Text-to-Image Models
Apr 01, 2024One of the key shortcomings in current text-to-image (T2I) models is their inability to consistently generate images which faithfully follow the spatial relationships specified in the text prompt. In this paper, we offer a comprehensive investigation of this limitation, while also developing datasets and methods that achieve state-of-the-art performance. First, we find that current vision-language datasets do not represent spatial relationships well enough; to alleviate this bottleneck, we create SPRIGHT, the first spatially-focused, large scale dataset, by re-captioning 6 million images from 4 widely used vision datasets. Through a 3-fold evaluation and analysis pipeline, we find that SPRIGHT largely improves upon existing datasets in capturing spatial relationships. To demonstrate its efficacy, we leverage only ~0.25% of SPRIGHT and achieve a 22% improvement in generating spatially accurate images while also improving the FID and CMMD scores. Secondly, we find that training on images containing a large number of objects results in substantial improvements in spatial consistency. Notably, we attain state-of-the-art on T2I-CompBench with a spatial score of 0.2133, by fine-tuning on <500 images. Finally, through a set of controlled experiments and ablations, we document multiple findings that we believe will enhance the understanding of factors that affect spatial consistency in text-to-image models. We publicly release our dataset and model to foster further research in this area.
LDM3D-VR: Latent Diffusion Model for 3D VR
Nov 06, 2023


Latent diffusion models have proven to be state-of-the-art in the creation and manipulation of visual outputs. However, as far as we know, the generation of depth maps jointly with RGB is still limited. We introduce LDM3D-VR, a suite of diffusion models targeting virtual reality development that includes LDM3D-pano and LDM3D-SR. These models enable the generation of panoramic RGBD based on textual prompts and the upscaling of low-resolution inputs to high-resolution RGBD, respectively. Our models are fine-tuned from existing pretrained models on datasets containing panoramic/high-resolution RGB images, depth maps and captions. Both models are evaluated in comparison to existing related methods.
LDM3D: Latent Diffusion Model for 3D
May 21, 2023



This research paper proposes a Latent Diffusion Model for 3D (LDM3D) that generates both image and depth map data from a given text prompt, allowing users to generate RGBD images from text prompts. The LDM3D model is fine-tuned on a dataset of tuples containing an RGB image, depth map and caption, and validated through extensive experiments. We also develop an application called DepthFusion, which uses the generated RGB images and depth maps to create immersive and interactive 360-degree-view experiences using TouchDesigner. This technology has the potential to transform a wide range of industries, from entertainment and gaming to architecture and design. Overall, this paper presents a significant contribution to the field of generative AI and computer vision, and showcases the potential of LDM3D and DepthFusion to revolutionize content creation and digital experiences. A short video summarizing the approach can be found at https://t.ly/tdi2.
Improving video retrieval using multilingual knowledge transfer
Aug 28, 2022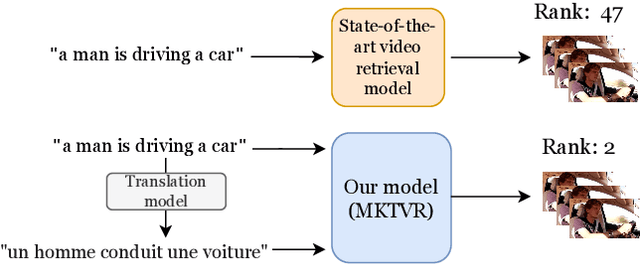
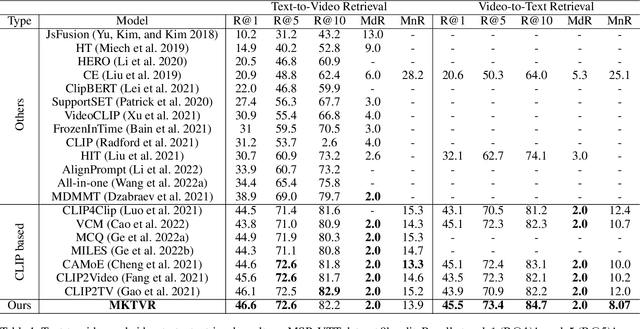
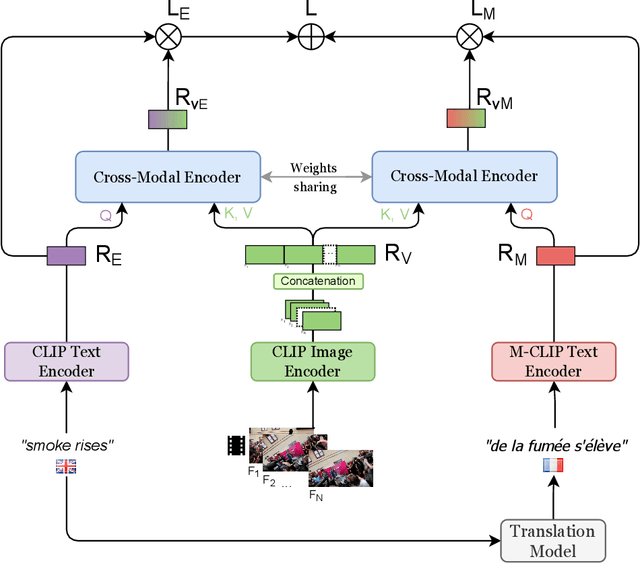
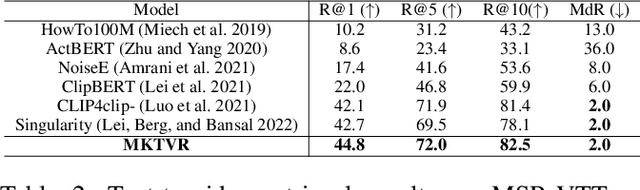
Video retrieval has seen tremendous progress with the development of vision-language models. However, further improving these models require additional labelled data which is a huge manual effort. In this paper, we propose a framework MKTVR, that utilizes knowledge transfer from a multilingual model to boost the performance of video retrieval. We first use state-of-the-art machine translation models to construct pseudo ground-truth multilingual video-text pairs. We then use this data to learn a video-text representation where English and non-English text queries are represented in a common embedding space based on pretrained multilingual models. We evaluate our proposed approach on four English video retrieval datasets such as MSRVTT, MSVD, DiDeMo and Charades. Experimental results demonstrate that our approach achieves state-of-the-art results on all datasets outperforming previous models. Finally, we also evaluate our model on a multilingual video-retrieval dataset encompassing six languages and show that our model outperforms previous multilingual video retrieval models in a zero-shot setting.