 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis-driven Stream Learning with Augmented Memory
Apr 07, 2021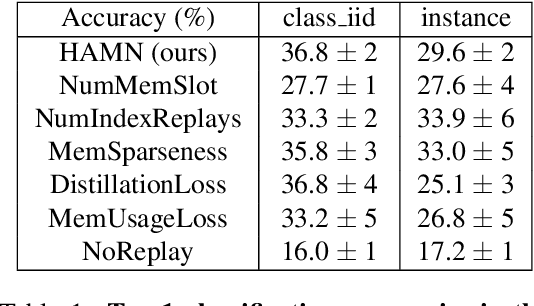
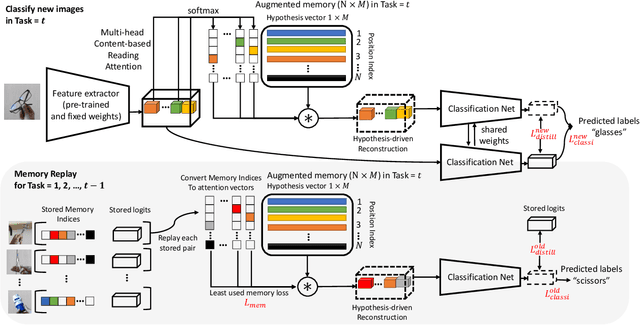
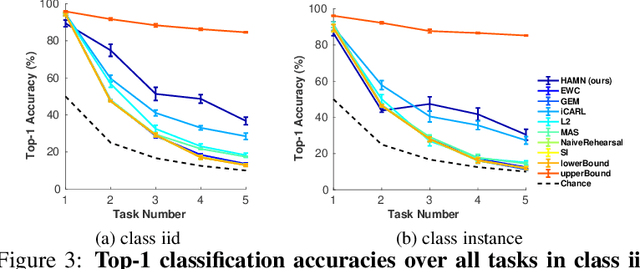
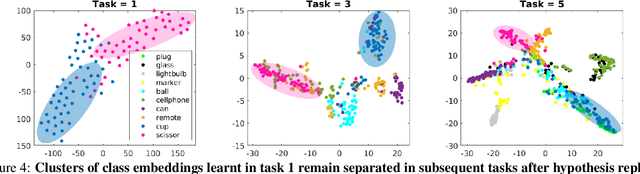
Stream learning refers to the ability to acquire and transfer knowledge across a continuous stream of data without forgetting and without repeated passes over the data. A common way to avoid catastrophic forgetting is to intersperse new examples with replays of old examples stored as image pixels or reproduced by generative models. Here, we considered stream learning in image classification tasks and proposed a novel hypotheses-driven Augmented Memory Network, which efficiently consolidates previous knowledge with a limited number of hypotheses in the augmented memory and replays relevant hypotheses to avoid catastrophic forgetting. The advantages of hypothesis-driven replay over image pixel replay and generative replay are two-fold. First, hypothesis-based knowledge consolidation avoids redundant information in the image pixel space and makes memory usage more efficient. Second, hypotheses in the augmented memory can be re-used for learning new tasks, improving generalization and transfer learning ability. We evaluated our method on three stream learning object recognition datasets. Our method performs comparably well or better than SOTA methods, while offering more efficient memory usage. All source code and data are publicly available https://github.com/kreimanlab/AugMem.
When Pigs Fly: Contextual Reasoning in Synthetic and Natural Scenes
Apr 06, 2021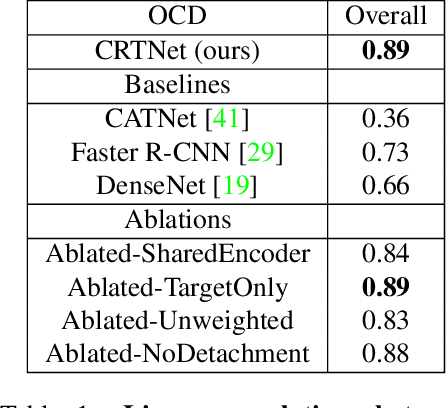
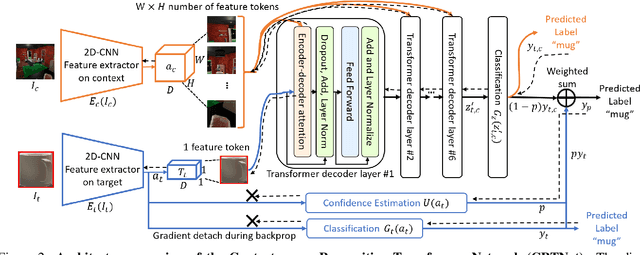
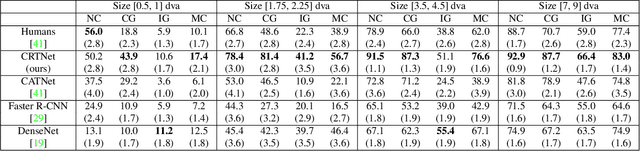
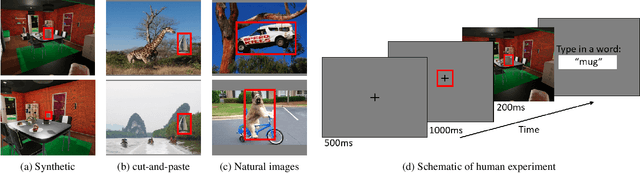
Context is of fundamental importance to both human and machine vision -- an object in the air is more likely to be an airplane, than a pig. The rich notion of context incorporates several aspects including physics rules, statistical co-occurrences, and relative object sizes, among others. While previous works have crowd-sourced out-of-context photographs from the web to study scene context, controlling the nature and extent of contextual violations has been an extremely daunting task. Here we introduce a diverse, synthetic Out-of-Context Dataset (OCD) with fine-grained control over scene context. By leveraging a 3D simulation engine, we systematically control the gravity, object co-occurrences and relative sizes across 36 object categories in a virtual household environment. We then conduct a series of experiments to gain insights into the impact of contextual cues on both human and machine vision using OCD. First, we conduct psycho-physics experiments to establish a human benchmark for out-of-context recognition, and then compare it with state-of-the-art computer vision models to quantify the gap between the two. Finally, we propose a context-aware recognition transformer model, fusing object and contextual information via multi-head attention. Our model captures useful information for contextual reasoning, enabling human-level performance and significantly better robustness in out-of-context conditions compared to baseline models across OCD and other existing out-of-context natural image datasets. All source code and data are publicly available https://github.com/kreimanlab/WhenPigsFlyContext.
Look Twice: A Computational Model of Return Fixations across Tasks and Species
Jan 05, 2021
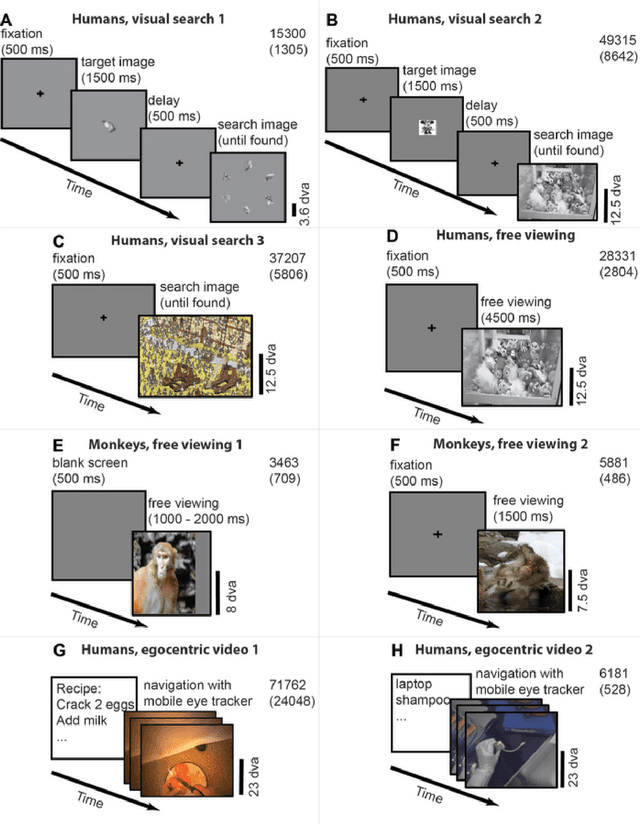
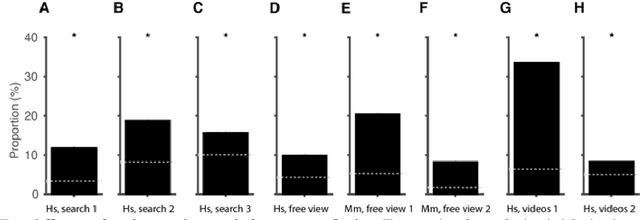
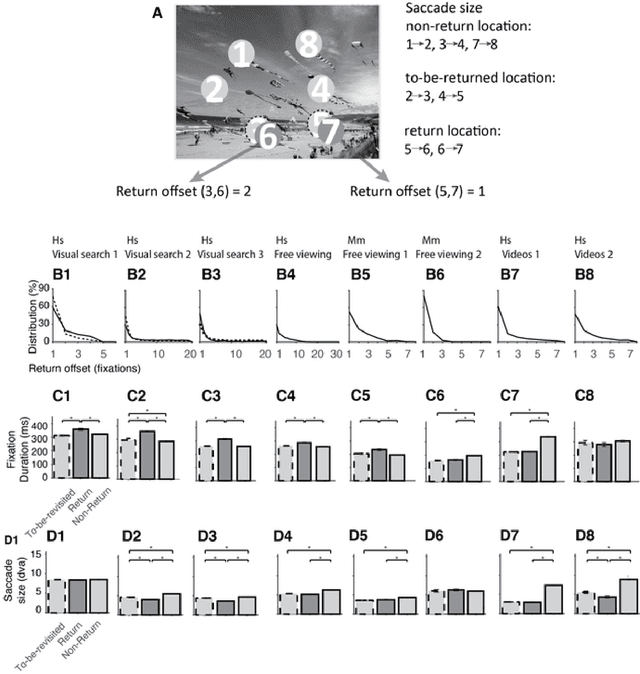
Saccadic eye movements allow animals to bring different parts of an image into high-resolution. During free viewing, inhibition of return incentivizes exploration by discouraging previously visited locations. Despite this inhibition, here we show that subjects make frequent return fixations. We systematically studied a total of 44,328 return fixations out of 217,440 fixations across different tasks, in monkeys and humans, and in static images or egocentric videos. The ubiquitous return fixations were consistent across subjects, tended to occur within short offsets, and were characterized by longer duration than non-return fixations. The locations of return fixations corresponded to image areas of higher saliency and higher similarity to the sought target during visual search tasks. We propose a biologically-inspired computational model that capitalizes on a deep convolutional neural network for object recognition to predict a sequence of fixations. Given an input image, the model computes four maps that constrain the location of the next saccade: a saliency map, a target similarity map, a saccade size map, and a memory map. The model exhibits frequent return fixations and approximates the properties of return fixations across tasks and species. The model provides initial steps towards capturing the trade-off between exploitation of informative image locations combined with exploration of novel image locations during scene viewing.
Adversarial images for the primate brain
Nov 11, 2020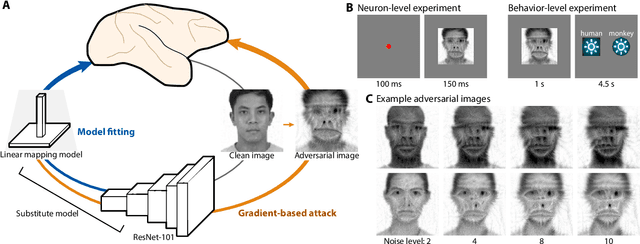
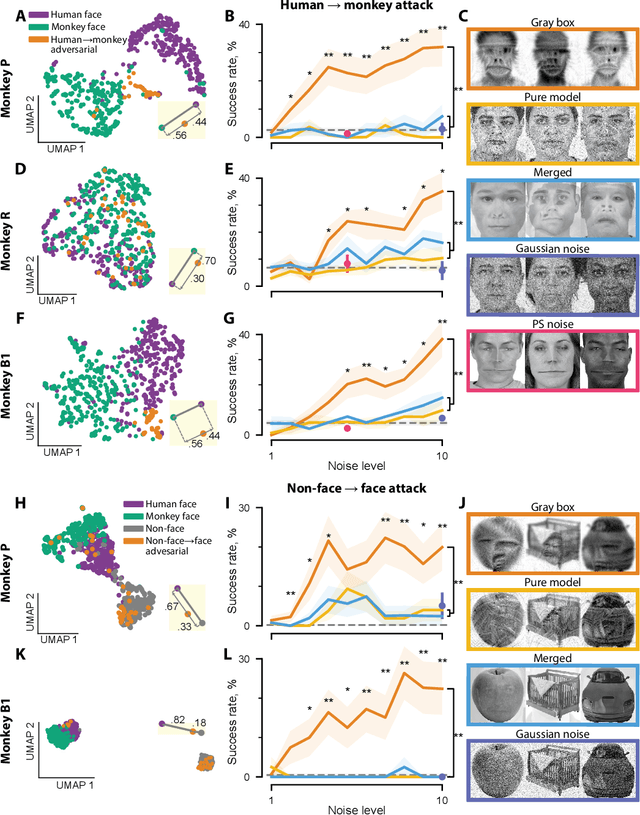
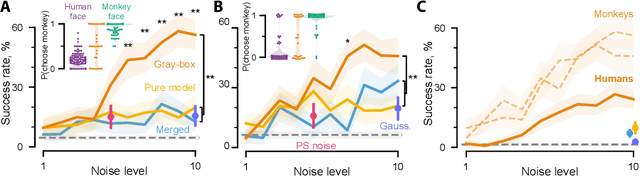
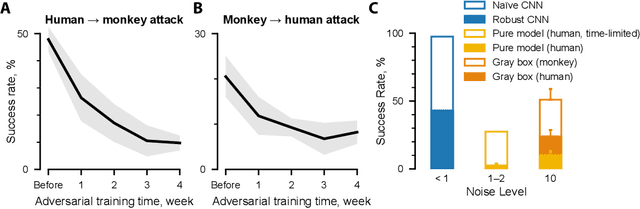
Deep artificial neural networks have been proposed as a model of primate vision. However, these networks are vulnerable to adversarial attacks, whereby introducing minimal noise can fool networks into misclassifying images. Primate vision is thought to be robust to such adversarial images. We evaluated this assumption by designing adversarial images to fool primate vision. To do so, we first trained a model to predict responses of face-selective neurons in macaque inferior temporal cortex. Next, we modified images, such as human faces, to match their model-predicted neuronal responses to a target category, such as monkey faces. These adversarial images elicited neuronal responses similar to the target category. Remarkably, the same images fooled monkeys and humans at the behavioral level. These results challenge fundamental assumptions about the similarity between computer and primate vision and show that a model of neuronal activity can selectively direct primate visual behavior.
What am I Searching for: Zero-shot Target Identity Inference in Visual Search
May 28, 2020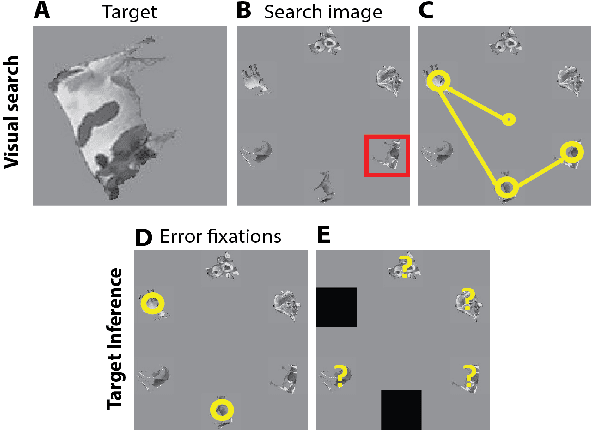
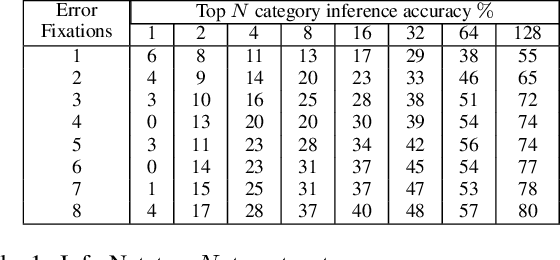
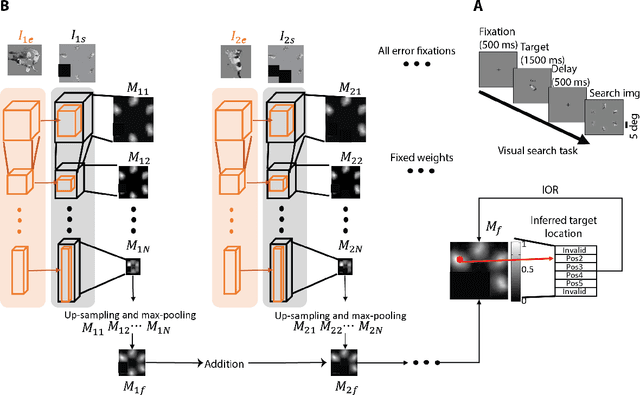
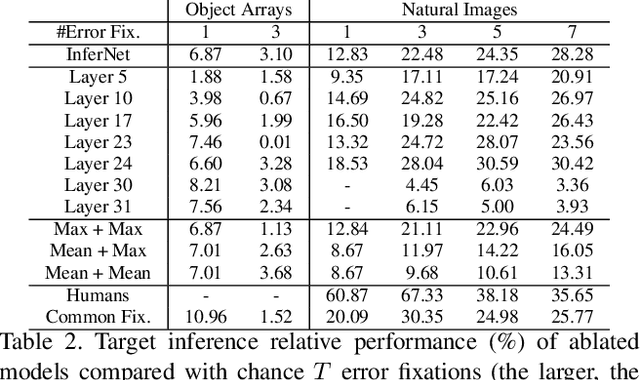
Can we infer intentions from a person's actions? As an example problem, here we consider how to decipher what a person is searching for by decoding their eye movement behavior. We conducted two psychophysics experiments where we monitored eye movements while subjects searched for a target object. We defined the fixations falling on \textit{non-target} objects as "error fixations". Using those error fixations, we developed a model (InferNet) to infer what the target was. InferNet uses a pre-trained convolutional neural network to extract features from the error fixations and computes a similarity map between the error fixations and all locations across the search image. The model consolidates the similarity maps across layers and integrates these maps across all error fixations. InferNet successfully identifies the subject's goal and outperforms competitive null models, even without any object-specific training on the inference task.
Can Deep Learning Recognize Subtle Human Activities?
Mar 30, 2020
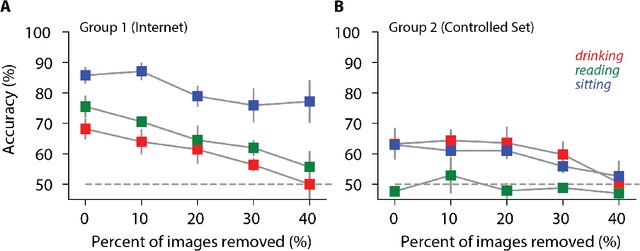
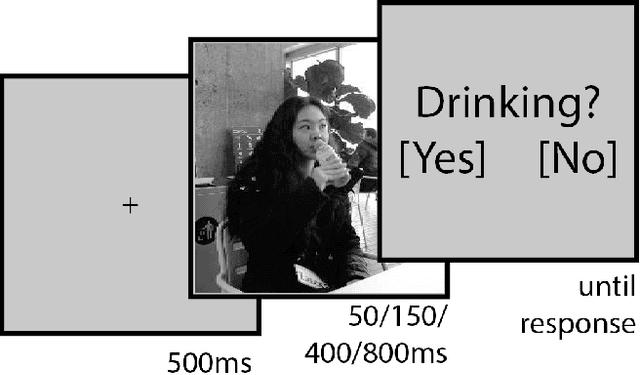
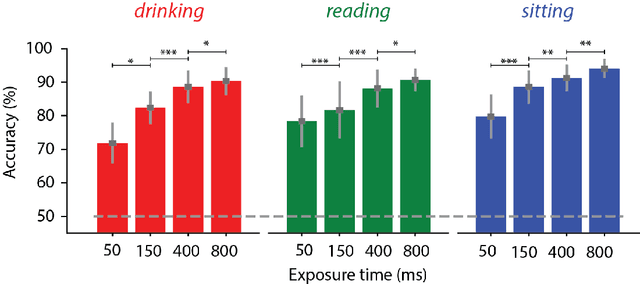
Deep Learning has driven recent and exciting progress in computer vision, instilling the belief that these algorithms could solve any visual task. Yet, datasets commonly used to train and test computer vision algorithms have pervasive confounding factors. Such biases make it difficult to truly estimate the performance of those algorithms and how well computer vision models can extrapolate outside the distribution in which they were trained. In this work, we propose a new action classification challenge that is performed well by humans, but poorly by state-of-the-art Deep Learning models. As a proof-of-principle, we consider three exemplary tasks: drinking, reading, and sitting. The best accuracies reached using state-of-the-art computer vision models were 61.7%, 62.8%, and 76.8%, respectively, while human participants scored above 90% accuracy on the three tasks. We propose a rigorous method to reduce confounds when creating datasets, and when comparing human versus computer vision performance. Source code and datasets are publicly available.
Removable and/or Repeated Units Emerge in Overparametrized Deep Neural Networks
Dec 21, 2019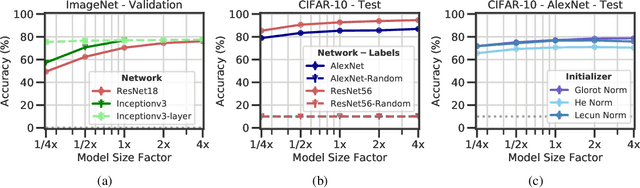

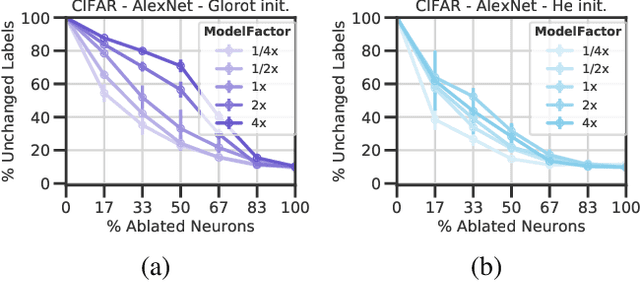
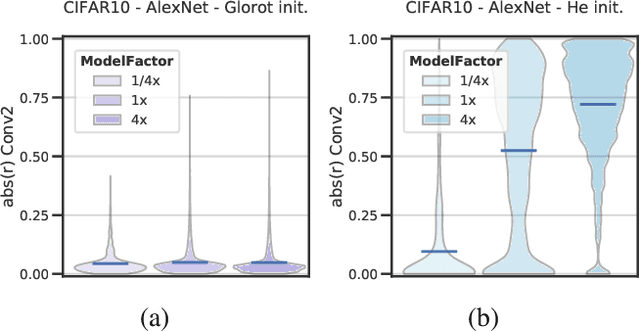
Deep neural networks (DNNs) perform well on a variety of tasks despite the fact that most networks used in practice are vastly overparametrized and even capable of perfectly fitting randomly labeled data. Recent evidence suggests that developing compressible representations is key for adjusting the complexity of overparametrized networks to the task at hand. In this paper, we provide new empirical evidence that supports this hypothesis by identifying two types of units that emerge when the network's width is increased: removable units which can be dropped out of the network without significant change to the output and repeated units whose activities are highly correlated with other units. The emergence of these units implies capacity constraints as the function the network represents could be expressed by a smaller network without these units. In a series of experiments with AlexNet, ResNet and Inception networks in the CIFAR-10 and ImageNet datasets, and also using shallow networks with synthetic data, we show that DNNs consistently increase either the number of removable units, repeated units, or both at greater widths for a comprehensive set of hyperparameters. These results suggest that the mechanisms by which networks in the deep learning regime adjust their complexity operate at the unit level and highlight the need for additional research into what drives the emergence of such units.
Putting visual object recognition in context
Dec 09, 2019


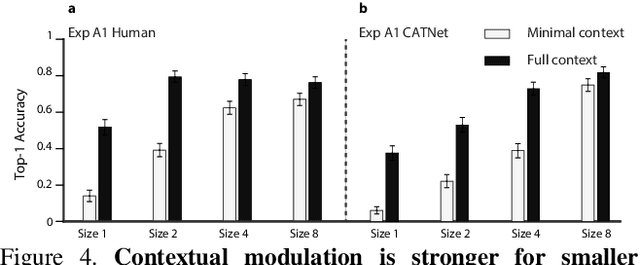
Context plays an important role in visual recognition. Recent studies have shown that visual recognition networks can be fooled by placing objects in inconsistent contexts (e.g. a cow in the ocean). To understand and model the role of contextual information in visual recognition, we systematically and quantitatively investigated ten critical properties of where, when, and how context modulates recognition including amount of context, context and object resolution, geometrical structure of context, context congruence, time required to incorporate contextual information, and temporal dynamics of contextual modulation. The tasks involve recognizing a target object surrounded with context in a natural image. As an essential benchmark, we first describe a series of psychophysics experiments, where we alter one aspect of context at a time, and quantify human recognition accuracy. To computationally assess performance on the same tasks, we propose a biologically inspired context aware object recognition model consisting of a two-stream architecture. The model processes visual information at the fovea and periphery in parallel, dynamically incorporates both object and contextual information, and sequentially reasons about the class label for the target object. Across a wide range of behavioral tasks, the model approximates human level performance without retraining for each task, captures the dependence of context enhancement on image properties, and provides initial steps towards integrating scene and object information for visual recognition.
Gradient-free activation maximization for identifying effective stimuli
May 01, 2019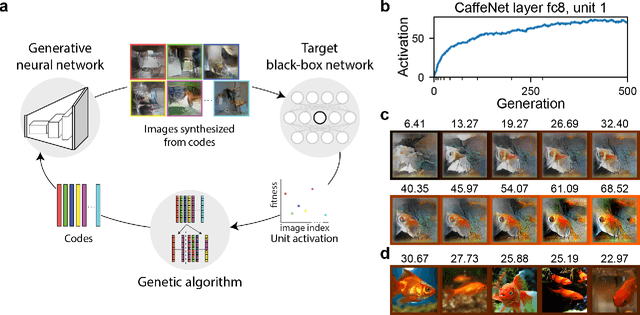
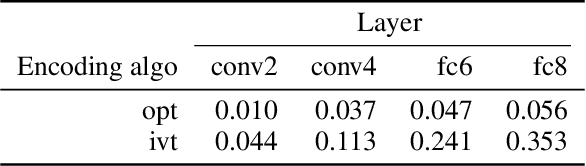
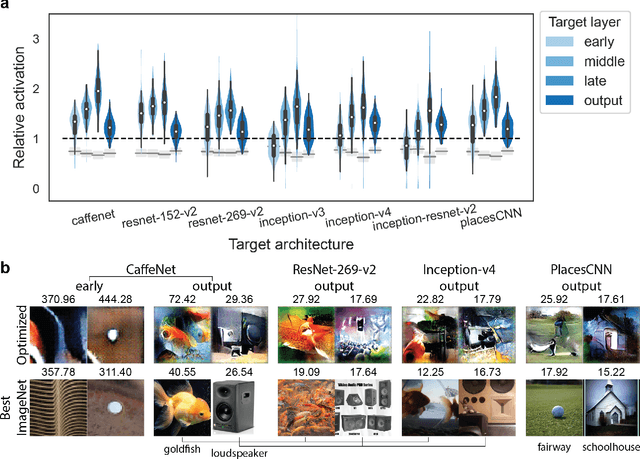
A fundamental question for understanding brain function is what types of stimuli drive neurons to fire. In visual neuroscience, this question has also been posted as characterizing the receptive field of a neuron. The search for effective stimuli has traditionally been based on a combination of insights from previous studies, intuition, and luck. Recently, the same question has emerged in the study of units in convolutional neural networks (ConvNets), and together with this question a family of solutions were developed that are generally referred to as "feature visualization by activation maximization." We sought to bring in tools and techniques developed for studying ConvNets to the study of biological neural networks. However, one key difference that impedes direct translation of tools is that gradients can be obtained from ConvNets using backpropagation, but such gradients are not available from the brain. To circumvent this problem, we developed a method for gradient-free activation maximization by combining a generative neural network with a genetic algorithm. We termed this method XDream (EXtending DeepDream with real-time evolution for activation maximization), and we have shown that this method can reliably create strong stimuli for neurons in the macaque visual cortex (Ponce et al., 2019). In this paper, we describe extensive experiments characterizing the XDream method by using ConvNet units as in silico models of neurons. We show that XDream is applicable across network layers, architectures, and training sets; examine design choices in the algorithm; and provide practical guides for choosing hyperparameters in the algorithm. XDream is an efficient algorithm for uncovering neuronal tuning preferences in black-box networks using a vast and diverse stimulus space.
Lift-the-Flap: Context Reasoning Using Object-Centered Graphs
Feb 01, 2019
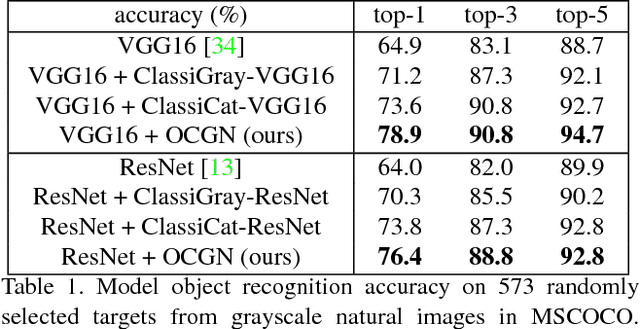
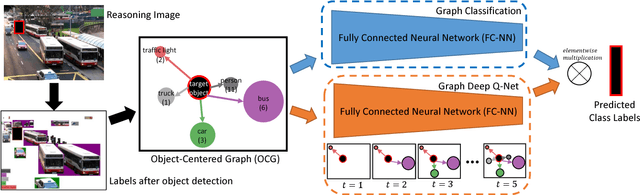
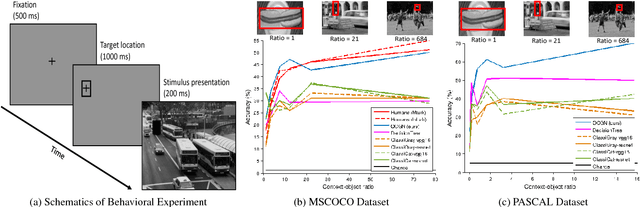
Children benefit from lift-the-flap books by taking on an active role in guessing what is behind the flap based on the context. In this paper, we introduce lift-the-flap games for computational models. The task is to reason about the scene context and infer what the target behind the flap is in a natural image. Context reasoning is critical in many computer vision applications, such as object recognition and semantic segmentation. To tackle this problem, we propose an object-centered graph representing the scene configuration of the image where each node corresponds to a group of objects belonging to the same category. To infer the target's class label, we introduce an object-centered graph network model consisting of two sub-networks. The classification sub-network takes the complete graph as input and outputs a classification vector assigning the probability for each class. The reinforcement learning sub-network exploits the class label dependencies and learns the joint probability among objects in order to generate multiple reasonable answers for the missing target. To evaluate our model's performance, we carry out human behavioral experiments for lift-the-flap games as a benchmark. Our model makes reasonable inferences compared to humans, and significantly outperforms all the null models. We also demonstrate the usefulness of our object-centered graph network model in context-aware object recognition and target priming in visual search.