 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Diffusion For Aerial Object Detection
Nov 21, 2023



Aerial object detection is a challenging task, in which one major obstacle lies in the limitations of large-scale data collection and the long-tail distribution of certain classes. Synthetic data offers a promising solution, especially with recent advances in diffusion-based methods like stable diffusion (SD). However, the direct application of diffusion methods to aerial domains poses unique challenges: stable diffusion's optimization for rich ground-level semantics doesn't align with the sparse nature of aerial objects, and the extraction of post-synthesis object coordinates remains problematic. To address these challenges, we introduce a synthetic data augmentation framework tailored for aerial images. It encompasses sparse-to-dense region of interest (ROI) extraction to bridge the semantic gap, fine-tuning the diffusion model with low-rank adaptation (LORA) to circumvent exhaustive retraining, and finally, a Copy-Paste method to compose synthesized objects with backgrounds, providing a nuanced approach to aerial object detection through synthetic data.
QuadraLib: A Performant Quadratic Neural Network Library for Architecture Optimization and Design Exploration
Apr 01, 2022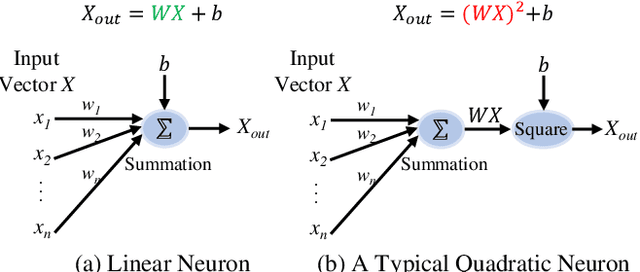

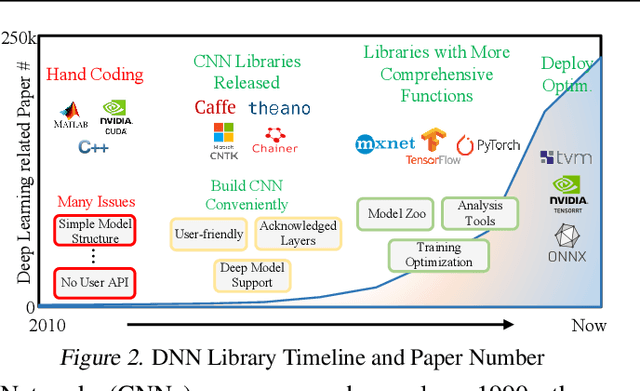
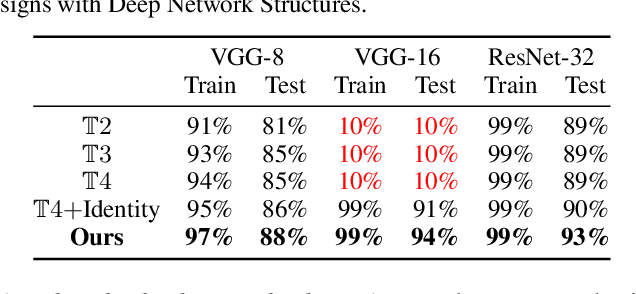
The significant success of Deep Neural Networks (DNNs) is highly promoted by the multiple sophisticated DNN libraries. On the contrary, although some work have proved that Quadratic Deep Neuron Networks (QDNNs) show better non-linearity and learning capability than the first-order DNNs, their neuron design suffers certain drawbacks from theoretical performance to practical deployment. In this paper, we first proposed a new QDNN neuron architecture design, and further developed QuadraLib, a QDNN library to provide architecture optimization and design exploration for QDNNs. Extensive experiments show that our design has good performance regarding prediction accuracy and computation consumption on multiple learning tasks.
Fed2: Feature-Aligned Federated Learning
Nov 28, 2021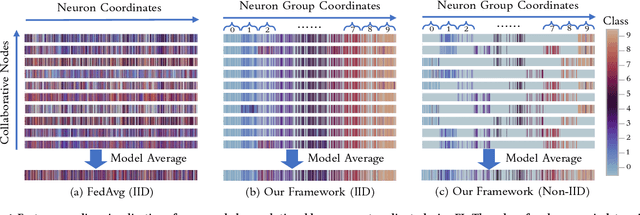
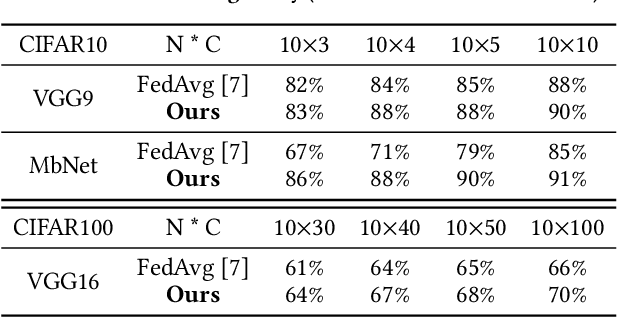
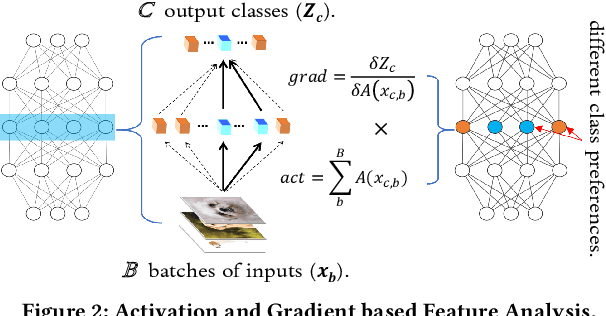
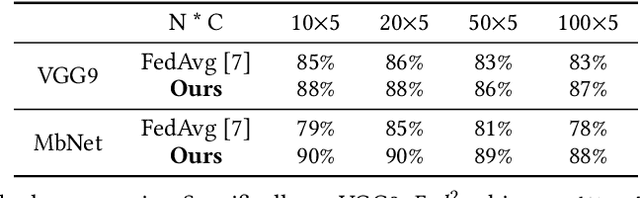
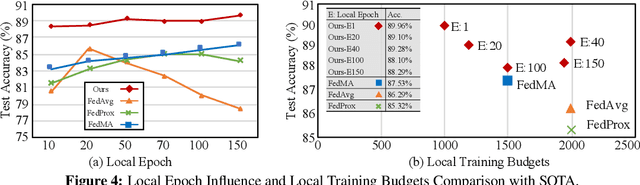
Federated learning learns from scattered data by fusing collaborative models from local nodes. However, the conventional coordinate-based model averaging by FedAvg ignored the random information encoded per parameter and may suffer from structural feature misalignment. In this work, we propose Fed2, a feature-aligned federated learning framework to resolve this issue by establishing a firm structure-feature alignment across the collaborative models. Fed2 is composed of two major designs: First, we design a feature-oriented model structure adaptation method to ensure explicit feature allocation in different neural network structures. Applying the structure adaptation to collaborative models, matchable structures with similar feature information can be initialized at the very early training stage. During the federated learning process, we then propose a feature paired averaging scheme to guarantee aligned feature distribution and maintain no feature fusion conflicts under either IID or non-IID scenarios. Eventually, Fed2 could effectively enhance the federated learning convergence performance under extensive homo- and heterogeneous settings, providing excellent convergence speed, accuracy, and computation/communication efficiency.
A Survey of Large-Scale Deep Learning Serving System Optimization: Challenges and Opportunities
Nov 28, 2021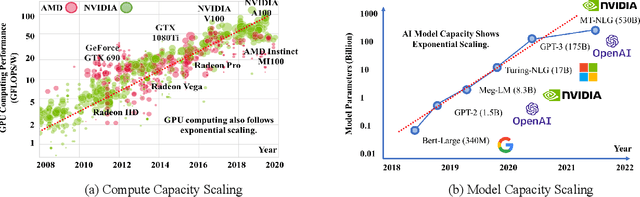
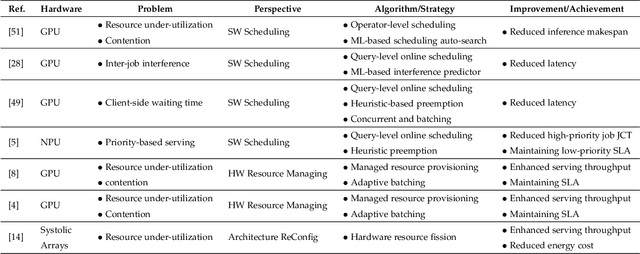
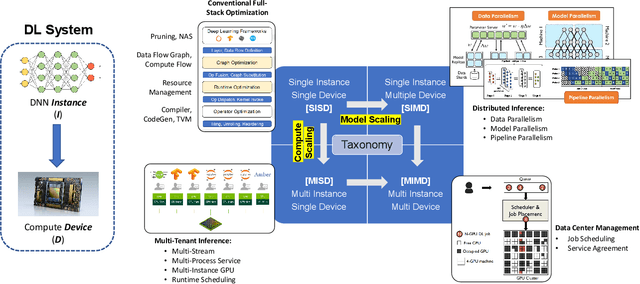
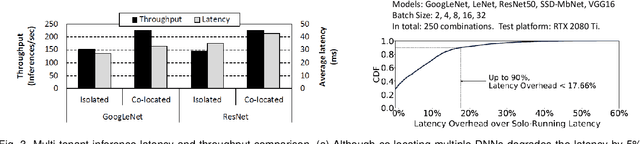
Deep Learning (DL) models have achieved superior performance in many application domains, including vision, language, medical, commercial ads, entertainment, etc. With the fast development, both DL applications and the underlying serving hardware have demonstrated strong scaling trends, i.e., Model Scaling and Compute Scaling, for example, the recent pre-trained model with hundreds of billions of parameters with ~TB level memory consumption, as well as the newest GPU accelerators providing hundreds of TFLOPS. With both scaling trends, new problems and challenges emerge in DL inference serving systems, which gradually trends towards Large-scale Deep learning Serving systems (LDS). This survey aims to summarize and categorize the emerging challenges and optimization opportunities for large-scale deep learning serving systems. By providing a novel taxonomy, summarizing the computing paradigms, and elaborating the recent technique advances, we hope that this survey could shed light on new optimization perspectives and motivate novel works in large-scale deep learning system optimization.
Supporting Massive DLRM Inference Through Software Defined Memory
Nov 08, 2021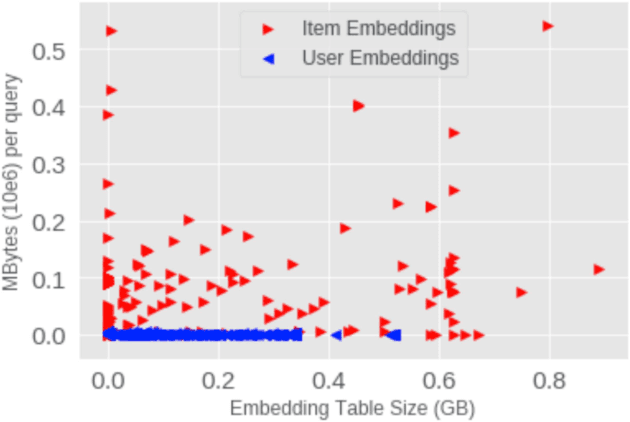

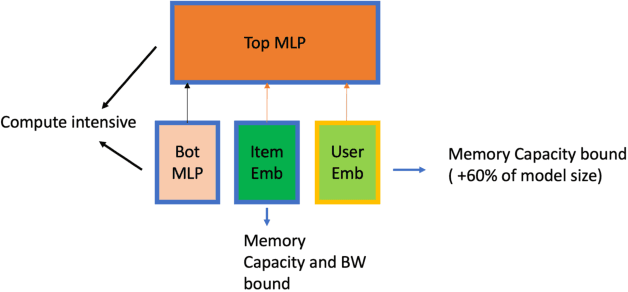

Deep Learning Recommendation Models (DLRM) are widespread, account for a considerable data center footprint, and grow by more than 1.5x per year. With model size soon to be in terabytes range, leveraging Storage ClassMemory (SCM) for inference enables lower power consumption and cost. This paper evaluates the major challenges in extending the memory hierarchy to SCM for DLRM, and presents different techniques to improve performance through a Software Defined Memory. We show how underlying technologies such as Nand Flash and 3DXP differentiate, and relate to real world scenarios, enabling from 5% to 29% power savings.
Third ArchEdge Workshop: Exploring the Design Space of Efficient Deep Neural Networks
Nov 22, 2020This paper gives an overview of our ongoing work on the design space exploration of efficient deep neural networks (DNNs). Specifically, we cover two aspects: (1) static architecture design efficiency and (2) dynamic model execution efficiency. For static architecture design, different from existing end-to-end hardware modeling assumptions, we conduct full-stack profiling at the GPU core level to identify better accuracy-latency trade-offs for DNN designs. For dynamic model execution, different from prior work that tackles model redundancy at the DNN-channels level, we explore a new dimension of DNN feature map redundancy to be dynamically traversed at runtime. Last, we highlight several open questions that are poised to draw research attention in the next few years.
Heterogeneous Federated Learning
Aug 15, 2020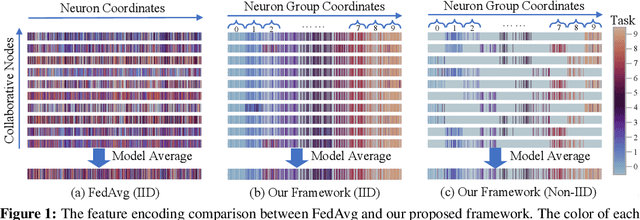
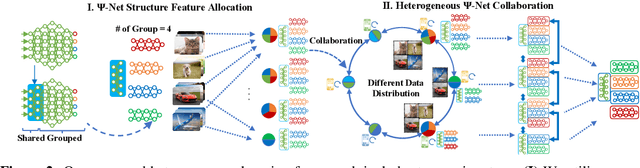
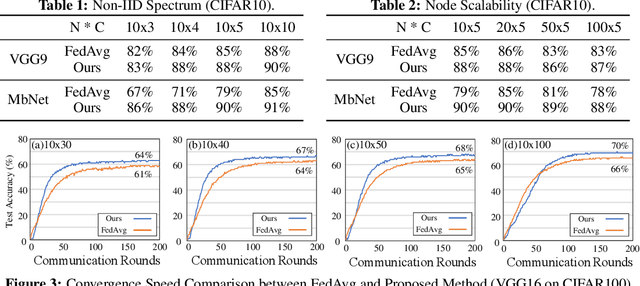
Federated learning learns from scattered data by fusing collaborative models from local nodes. However, due to chaotic information distribution, the model fusion may suffer from structural misalignment with regard to unmatched parameters. In this work, we propose a novel federated learning framework to resolve this issue by establishing a firm structure-information alignment across collaborative models. Specifically, we design a feature-oriented regulation method ({$\Psi$-Net}) to ensure explicit feature information allocation in different neural network structures. Applying this regulating method to collaborative models, matchable structures with similar feature information can be initialized at the very early training stage. During the federated learning process under either IID or non-IID scenarios, dedicated collaboration schemes further guarantee ordered information distribution with definite structure matching, so as the comprehensive model alignment. Eventually, this framework effectively enhances the federated learning applicability to extensive heterogeneous settings, while providing excellent convergence speed, accuracy, and computation/communication efficiency.
AntiDote: Attention-based Dynamic Optimization for Neural Network Runtime Efficiency
Aug 14, 2020



Convolutional Neural Networks (CNNs) achieved great cognitive performance at the expense of considerable computation load. To relieve the computation load, many optimization works are developed to reduce the model redundancy by identifying and removing insignificant model components, such as weight sparsity and filter pruning. However, these works only evaluate model components' static significance with internal parameter information, ignoring their dynamic interaction with external inputs. With per-input feature activation, the model component significance can dynamically change, and thus the static methods can only achieve sub-optimal results. Therefore, we propose a dynamic CNN optimization framework in this work. Based on the neural network attention mechanism, we propose a comprehensive dynamic optimization framework including (1) testing-phase channel and column feature map pruning, as well as (2) training-phase optimization by targeted dropout. Such a dynamic optimization framework has several benefits: (1) First, it can accurately identify and aggressively remove per-input feature redundancy with considering the model-input interaction; (2) Meanwhile, it can maximally remove the feature map redundancy in various dimensions thanks to the multi-dimension flexibility; (3) The training-testing co-optimization favors the dynamic pruning and helps maintain the model accuracy even with very high feature pruning ratio. Extensive experiments show that our method could bring 37.4% to 54.5% FLOPs reduction with negligible accuracy drop on various of test networks.
Unsupervised Domain Adaptation for Object Detection via Cross-Domain Semi-Supervised Learning
Nov 24, 2019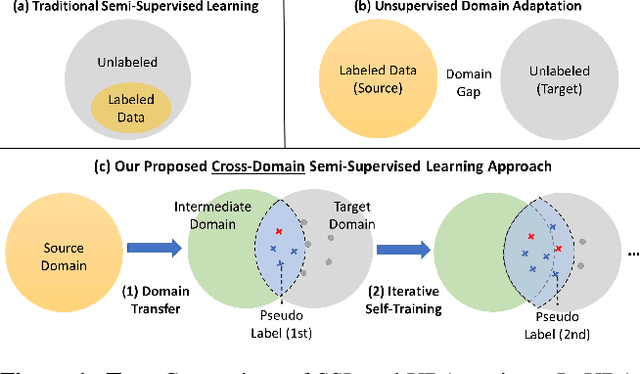
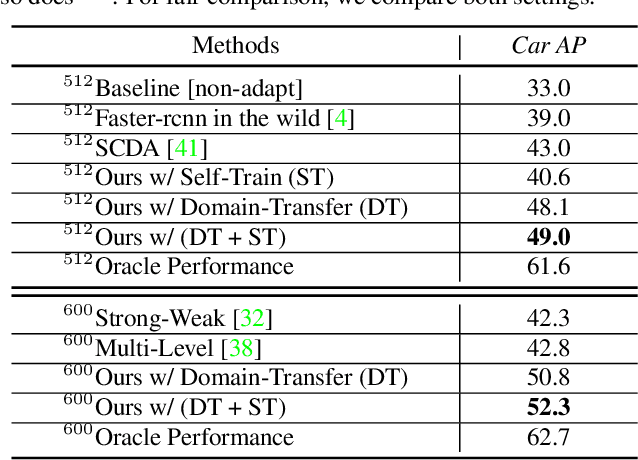
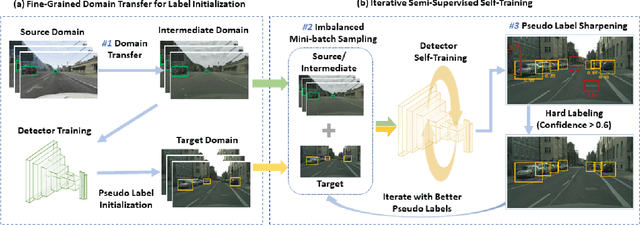
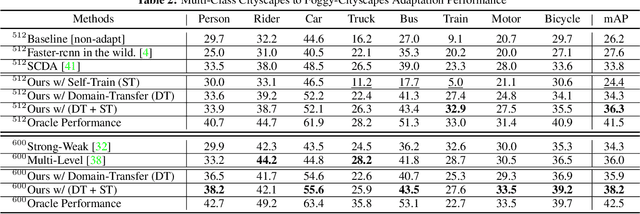
Current state-of-the-art object detectors can have significant performance drop when deployed in the wild due to domain gaps with training data. Unsupervised Domain Adaptation (UDA) is a promising approach to adapt models for new domains/environments without any expensive label cost. However, without ground truth labels, most prior works on UDA for object detection tasks can only perform coarse image-level and/or feature-level adaptation by using adversarial learning methods. In this work, we show that such adversarial-based methods can only reduce the domain style gap, but cannot address the domain content distribution gap that is shown to be important for object detectors. To overcome this limitation, we propose the Cross-Domain Semi-Supervised Learning (CDSSL) framework by leveraging high-quality pseudo labels to learn better representations from the target domain directly. To enable SSL for cross-domain object detection, we propose fine-grained domain transfer, progressive-confidence-based label sharpening and imbalanced sampling strategy to address two challenges: (i) non-identical distribution between source and target domain data, (ii) error amplification/accumulation due to noisy pseudo labeling on the target domain. Experiment results show that our proposed approach consistently achieves new state-of-the-art performance (2.2% - 9.5% better than prior best work on mAP) under various domain gap scenarios. The code will be released.
LanCe: A Comprehensive and Lightweight CNN Defense Methodology against Physical Adversarial Attacks on Embedded Multimedia Applications
Oct 17, 2019
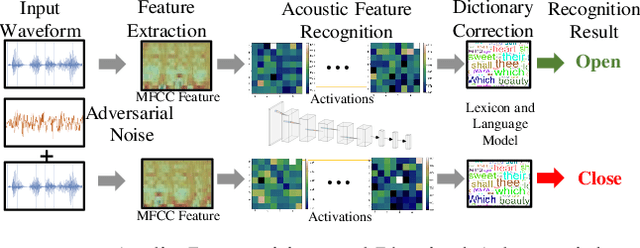

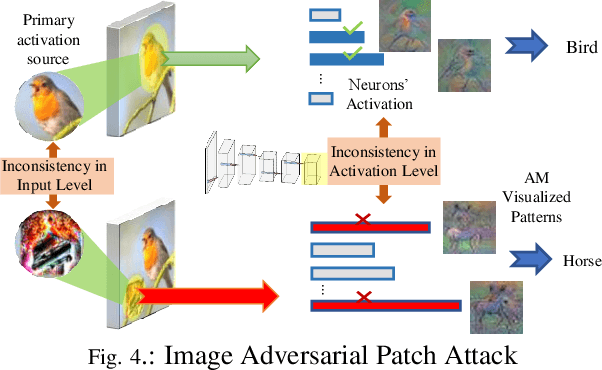
Recently, adversarial attacks can be applied to the physical world, causing practical issues to various Convolutional Neural Networks (CNNs) powered applications. Most existing physical adversarial attack defense works only focus on eliminating explicit perturbation patterns from inputs, ignoring interpretation to CNN's intrinsic vulnerability. Therefore, they lack the expected versatility to different attacks and thereby depend on considerable data processing costs. In this paper, we propose LanCe -- a comprehensive and lightweight CNN defense methodology against different physical adversarial attacks. By interpreting CNN's vulnerability, we find that non-semantic adversarial perturbations can activate CNN with significantly abnormal activations and even overwhelm other semantic input patterns' activations. We improve the CNN recognition process by adding a self-verification stage to detect the potential adversarial input with only one CNN inference cost. Based on the detection result, we further propose a data recovery methodology to defend the physical adversarial attacks. We apply such defense methodology into both image and audio CNN recognition scenarios and analyze the computational complexity for each scenario, respectively. Experiments show that our methodology can achieve an average 91% successful rate for attack detection and 89% accuracy recovery. Moreover, it is at most 3x faster compared with the state-of-the-art defense methods, making it feasible to resource-constrained embedded systems, such as mobile devices.