 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
Progressive Mixed-Precision Decoding for Efficient LLM Inference
Oct 17, 2024



In spite of the great potential of large language models (LLMs) across various tasks, their deployment on resource-constrained devices remains challenging due to their excessive computational and memory demands. Quantization has emerged as an effective solution by storing weights in reduced precision. However, utilizing low precisions (i.e.~2/3-bit) to substantially alleviate the memory-boundedness of LLM decoding, still suffers from prohibitive performance drop. In this work, we argue that existing approaches fail to explore the diversity in computational patterns, redundancy, and sensitivity to approximations of the different phases of LLM inference, resorting to a uniform quantization policy throughout. Instead, we propose a novel phase-aware method that selectively allocates precision during different phases of LLM inference, achieving both strong context extraction during prefill and efficient memory bandwidth utilization during decoding. To further address the memory-boundedness of the decoding phase, we introduce Progressive Mixed-Precision Decoding (PMPD), a technique that enables the gradual lowering of precision deeper in the generated sequence, together with a spectrum of precision-switching schedulers that dynamically drive the precision-lowering decisions in either task-adaptive or prompt-adaptive manner. Extensive evaluation across diverse language tasks shows that when targeting Nvidia GPUs, PMPD achieves 1.4$-$12.2$\times$ speedup in matrix-vector multiplications over fp16 models, while when targeting an LLM-optimized NPU, our approach delivers a throughput gain of 3.8$-$8.0$\times$ over fp16 models and up to 1.54$\times$ over uniform quantization approaches while preserving the output quality.
MobileQuant: Mobile-friendly Quantization for On-device Language Models
Aug 25, 2024



Large language models (LLMs) have revolutionized language processing, delivering outstanding results across multiple applications. However, deploying LLMs on edge devices poses several challenges with respect to memory, energy, and compute costs, limiting their widespread use in devices such as mobile phones. A promising solution is to reduce the number of bits used to represent weights and activations. While existing works have found partial success at quantizing LLMs to lower bitwidths, e.g. 4-bit weights, quantizing activations beyond 16 bits often leads to large computational overheads due to poor on-device quantization support, or a considerable accuracy drop. Yet, 8-bit activations are very attractive for on-device deployment as they would enable LLMs to fully exploit mobile-friendly hardware, e.g. Neural Processing Units (NPUs). In this work, we make a first attempt to facilitate the on-device deployment of LLMs using integer-only quantization. We first investigate the limitations of existing quantization methods for on-device deployment, with a special focus on activation quantization. We then address these limitations by introducing a simple post-training quantization method, named MobileQuant, that extends previous weight equivalent transformation works by jointly optimizing the weight transformation and activation range parameters in an end-to-end manner. MobileQuant demonstrates superior capabilities over existing methods by 1) achieving near-lossless quantization on a wide range of LLM benchmarks, 2) reducing latency and energy consumption by 20\%-50\% compared to current on-device quantization strategies, 3) requiring limited compute budget, 4) being compatible with mobile-friendly compute units, e.g. NPU.
Effective Self-supervised Pre-training on Low-compute networks without Distillation
Oct 06, 2022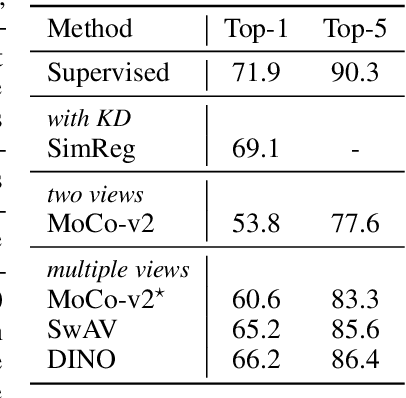
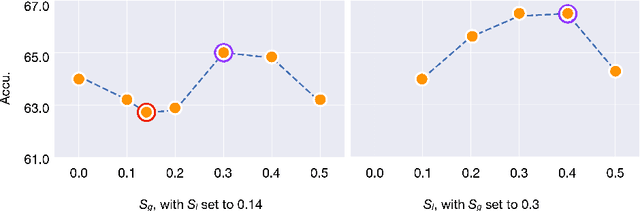
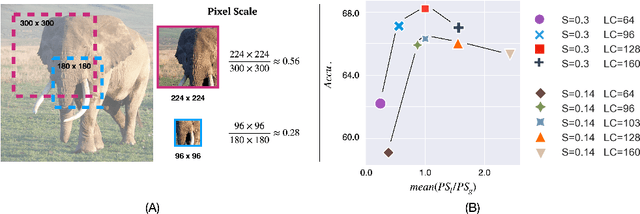
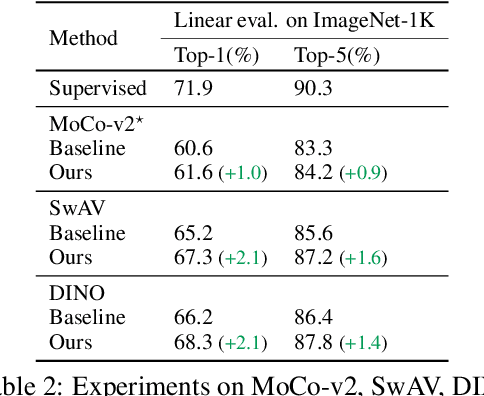
Despite the impressive progress of self-supervised learning (SSL), its applicability to low-compute networks has received limited attention. Reported performance has trailed behind standard supervised pre-training by a large margin, barring self-supervised learning from making an impact on models that are deployed on device. Most prior works attribute this poor performance to the capacity bottleneck of the low-compute networks and opt to bypass the problem through the use of knowledge distillation (KD). In this work, we revisit SSL for efficient neural networks, taking a closer at what are the detrimental factors causing the practical limitations, and whether they are intrinsic to the self-supervised low-compute setting. We find that, contrary to accepted knowledge, there is no intrinsic architectural bottleneck, we diagnose that the performance bottleneck is related to the model complexity vs regularization strength trade-off. In particular, we start by empirically observing that the use of local views can have a dramatic impact on the effectiveness of the SSL methods. This hints at view sampling being one of the performance bottlenecks for SSL on low-capacity networks. We hypothesize that the view sampling strategy for large neural networks, which requires matching views in very diverse spatial scales and contexts, is too demanding for low-capacity architectures. We systematize the design of the view sampling mechanism, leading to a new training methodology that consistently improves the performance across different SSL methods (e.g. MoCo-v2, SwAV, DINO), different low-size networks (e.g. MobileNetV2, ResNet18, ResNet34, ViT-Ti), and different tasks (linear probe, object detection, instance segmentation and semi-supervised learning). Our best models establish a new state-of-the-art for SSL methods on low-compute networks despite not using a KD loss term.
iBoot: Image-bootstrapped Self-Supervised Video Representation Learning
Jun 16, 2022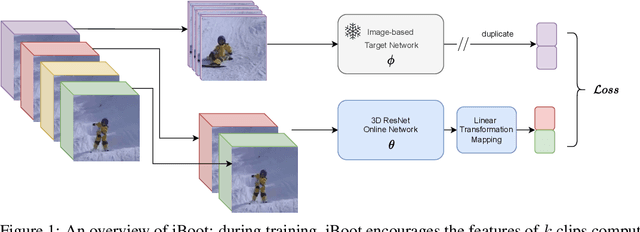



Learning visual representations through self-supervision is an extremely challenging task as the network needs to sieve relevant patterns from spurious distractors without the active guidance provided by supervision. This is achieved through heavy data augmentation, large-scale datasets and prohibitive amounts of compute. Video self-supervised learning (SSL) suffers from added challenges: video datasets are typically not as large as image datasets, compute is an order of magnitude larger, and the amount of spurious patterns the optimizer has to sieve through is multiplied several fold. Thus, directly learning self-supervised representations from video data might result in sub-optimal performance. To address this, we propose to utilize a strong image-based model, pre-trained with self- or language supervision, in a video representation learning framework, enabling the model to learn strong spatial and temporal information without relying on the video labeled data. To this end, we modify the typical video-based SSL design and objective to encourage the video encoder to \textit{subsume} the semantic content of an image-based model trained on a general domain. The proposed algorithm is shown to learn much more efficiently (i.e. in less epochs and with a smaller batch) and results in a new state-of-the-art performance on standard downstream tasks among single-modality SSL methods.
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
May 06, 2022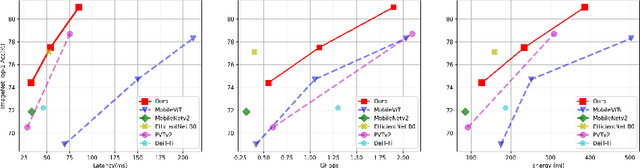
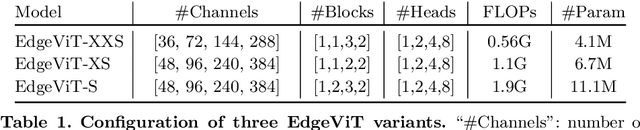
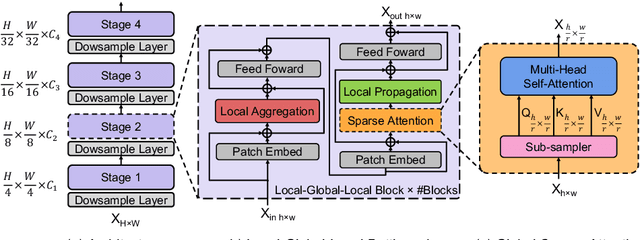
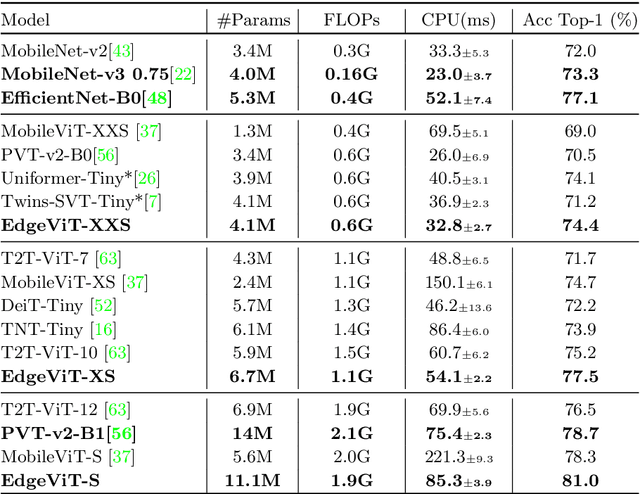
Self-attention based models such as vision transformers (ViTs) have emerged as a very competitive architecture alternative to convolutional neural networks (CNNs) in computer vision. Despite increasingly stronger variants with ever-higher recognition accuracies, due to the quadratic complexity of self-attention, existing ViTs are typically demanding in computation and model size. Although several successful design choices (e.g., the convolutions and hierarchical multi-stage structure) of prior CNNs have been reintroduced into recent ViTs, they are still not sufficient to meet the limited resource requirements of mobile devices. This motivates a very recent attempt to develop light ViTs based on the state-of-the-art MobileNet-v2, but still leaves a performance gap behind. In this work, pushing further along this under-studied direction we introduce EdgeViTs, a new family of light-weight ViTs that, for the first time, enable attention-based vision models to compete with the best light-weight CNNs in the tradeoff between accuracy and on-device efficiency. This is realized by introducing a highly cost-effective local-global-local (LGL) information exchange bottleneck based on optimal integration of self-attention and convolutions. For device-dedicated evaluation, rather than relying on inaccurate proxies like the number of FLOPs or parameters, we adopt a practical approach of focusing directly on on-device latency and, for the first time, energy efficiency. Specifically, we show that our models are Pareto-optimal when both accuracy-latency and accuracy-energy trade-offs are considered, achieving strict dominance over other ViTs in almost all cases and competing with the most efficient CNNs.
Instance-level Image Retrieval using Reranking Transformers
Mar 22, 2021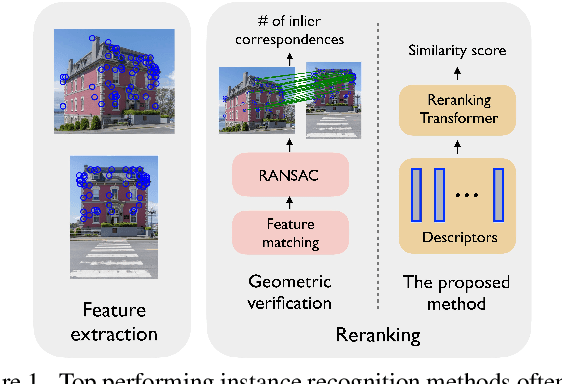
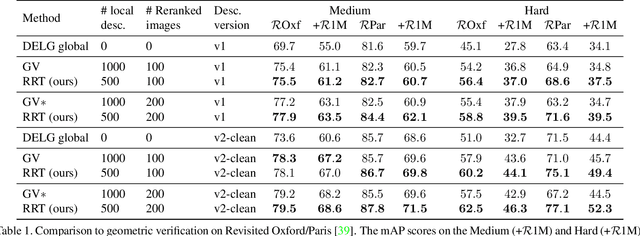
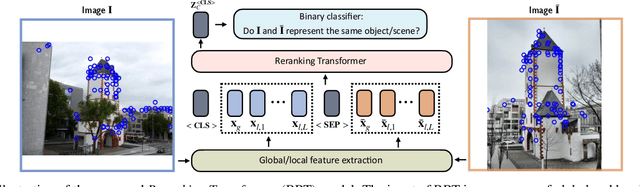
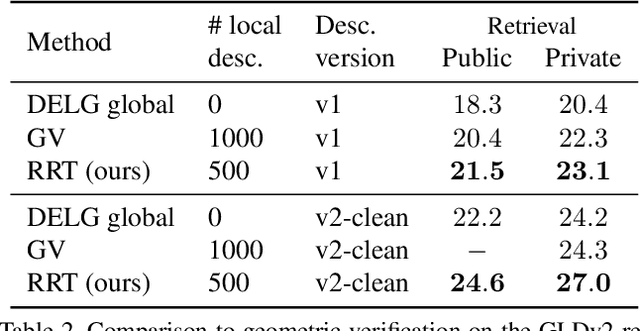
Instance-level image retrieval is the task of searching in a large database for images that match an object in a query image. To address this task, systems usually rely on a retrieval step that uses global image descriptors, and a subsequent step that performs domain-specific refinements or reranking by leveraging operations such as geometric verification based on local features. In this work, we propose Reranking Transformers (RRTs) as a general model to incorporate both local and global features to rerank the matching images in a supervised fashion and thus replace the relatively expensive process of geometric verification. RRTs are lightweight and can be easily parallelized so that reranking a set of top matching results can be performed in a single forward-pass. We perform extensive experiments on the Revisited Oxford and Paris datasets, and the Google Landmark v2 dataset, showing that RRTs outperform previous reranking approaches while using much fewer local descriptors. Moreover, we demonstrate that, unlike existing approaches, RRTs can be optimized jointly with the feature extractor, which can lead to feature representations tailored to downstream tasks and further accuracy improvements. Training code and pretrained models will be made public.
Curriculum Labeling: Self-paced Pseudo-Labeling for Semi-Supervised Learning
Jan 16, 2020
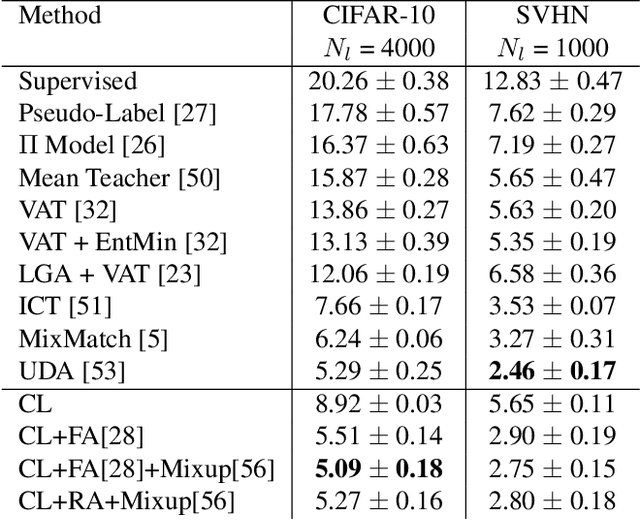
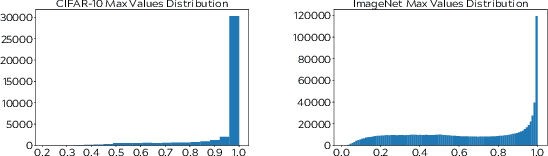
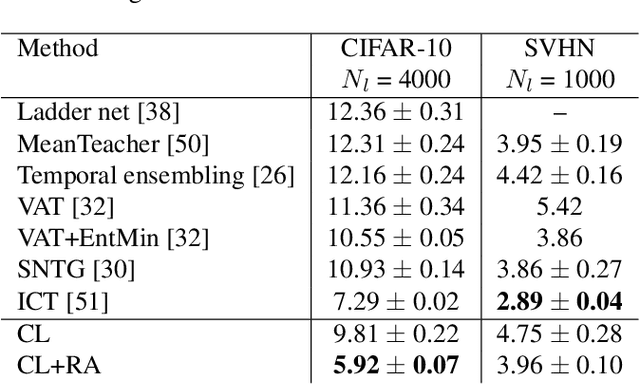
Semi-supervised learning aims to take advantage of a large amount of unlabeled data to improve the accuracy of a model that only has access to a small number of labeled examples. We propose curriculum labeling, an approach that exploits pseudo-labeling for propagating labels to unlabeled samples in an iterative and self-paced fashion. This approach is surprisingly simple and effective and surpasses or is comparable with the best methods proposed in the recent literature across all the standard benchmarks for image classification. Notably, we obtain 94.91% accuracy on CIFAR-10 using only 4,000 labeled samples, and 88.56% top-5 accuracy on Imagenet-ILSVRC using 128,000 labeled samples. In contrast to prior works, our approach shows improvements even in a more realistic scenario that leverages out-of-distribution unlabeled data samples.
Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries
Nov 10, 2019

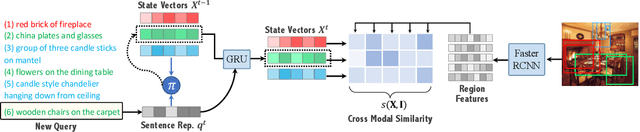
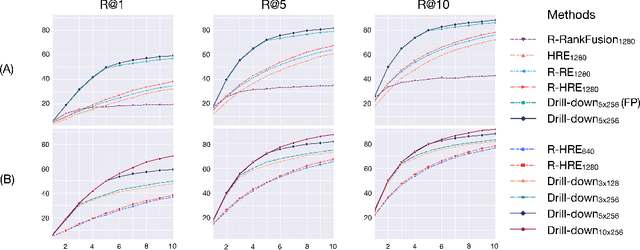
This paper explores the task of interactive image retrieval using natural language queries, where a user progressively provides input queries to refine a set of retrieval results. Moreover, our work explores this problem in the context of complex image scenes containing multiple objects. We propose Drill-down, an effective framework for encoding multiple queries with an efficient compact state representation that significantly extends current methods for single-round image retrieval. We show that using multiple rounds of natural language queries as input can be surprisingly effective to find arbitrarily specific images of complex scenes. Furthermore, we find that existing image datasets with textual captions can provide a surprisingly effective form of weak supervision for this task. We compare our method with existing sequential encoding and embedding networks, demonstrating superior performance on two proposed benchmarks: automatic image retrieval on a simulated scenario that uses region captions as queries, and interactive image retrieval using real queries from human evaluators.
Text2Scene: Generating Abstract Scenes from Textual Descriptions
Sep 04, 2018
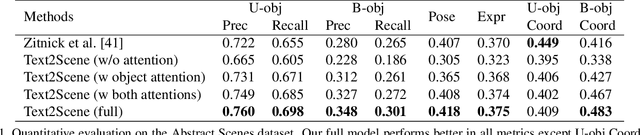
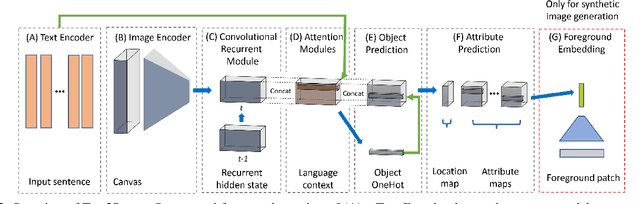

In this paper, we propose an end-to-end model that learns to interpret natural language describing a scene to generate an abstract pictorial representation. The pictorial representations generated by our model comprise the spatial distribution and attributes of the objects in the described scene. Our model uses a sequence-to-sequence network with a double attentive mechanism and introduces a regularization strategy. These scene representations can be sampled from our model similarly as in language-generation models. We show that the proposed model, initially designed to handle the generation of cartoon-like pictorial representations in the Abstract Scenes Dataset, can also handle, under minimal modifications, the generation of semantic layouts corresponding to real images in the COCO dataset. Human evaluations using a visual entailment task show that pictorial representations generated with our full model can entail at least one out of three input visual descriptions 94% of the times, and at least two out of three 62% of the times for each image.