 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Pose, Shape and Texture from Low-Resolution Images and Videos
Mar 11, 2021
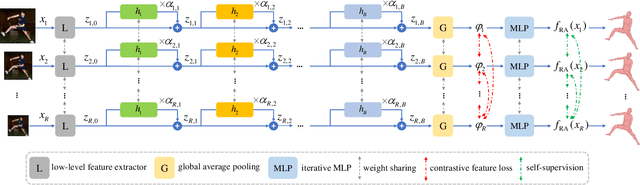
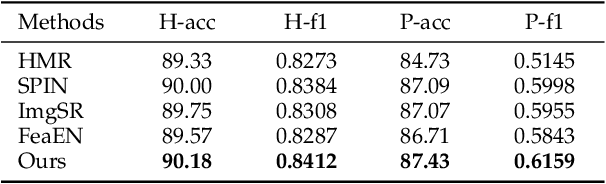
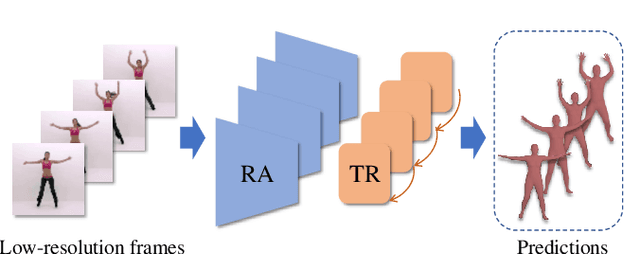
3D human pose and shape estimation from monocular images has been an active research area in computer vision. Existing deep learning methods for this task rely on high-resolution input, which however, is not always available in many scenarios such as video surveillance and sports broadcasting. Two common approaches to deal with low-resolution images are applying super-resolution techniques to the input, which may result in unpleasant artifacts, or simply training one model for each resolution, which is impractical in many realistic applications. To address the above issues, this paper proposes a novel algorithm called RSC-Net, which consists of a Resolution-aware network, a Self-supervision loss, and a Contrastive learning scheme. The proposed method is able to learn 3D body pose and shape across different resolutions with one single model. The self-supervision loss enforces scale-consistency of the output, and the contrastive learning scheme enforces scale-consistency of the deep features. We show that both these new losses provide robustness when learning in a weakly-supervised manner. Moreover, we extend the RSC-Net to handle low-resolution videos and apply it to reconstruct textured 3D pedestrians from low-resolution input. Extensive experiments demonstrate that the RSC-Net can achieve consistently better results than the state-of-the-art methods for challenging low-resolution images.
FaceDet3D: Facial Expressions with 3D Geometric Detail Prediction
Dec 23, 2020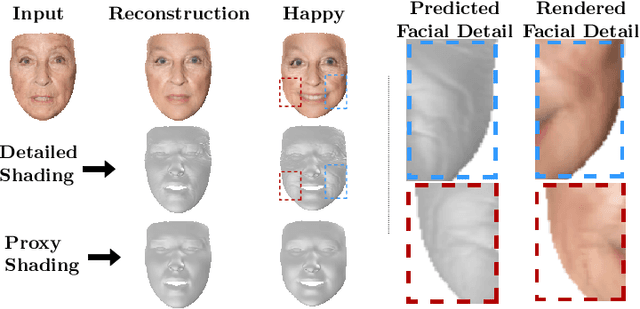
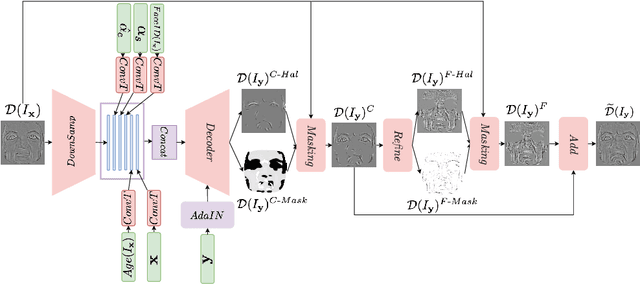
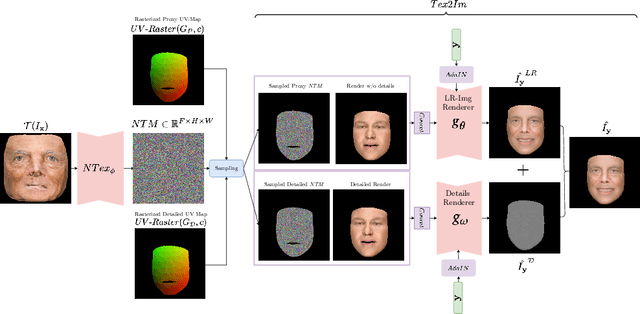

Facial Expressions induce a variety of high-level details on the 3D face geometry. For example, a smile causes the wrinkling of cheeks or the formation of dimples, while being angry often causes wrinkling of the forehead. Morphable Models (3DMMs) of the human face fail to capture such fine details in their PCA-based representations and consequently cannot generate such details when used to edit expressions. In this work, we introduce FaceDet3D, a first-of-its-kind method that generates - from a single image - geometric facial details that are consistent with any desired target expression. The facial details are represented as a vertex displacement map and used then by a Neural Renderer to photo-realistically render novel images of any single image in any desired expression and view. The project website is: http://shahrukhathar.github.io/2020/12/14/FaceDet3D.html
Multi-FinGAN: Generative Coarse-To-Fine Sampling of Multi-Finger Grasps
Dec 17, 2020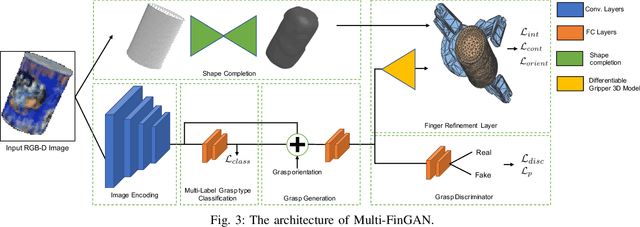

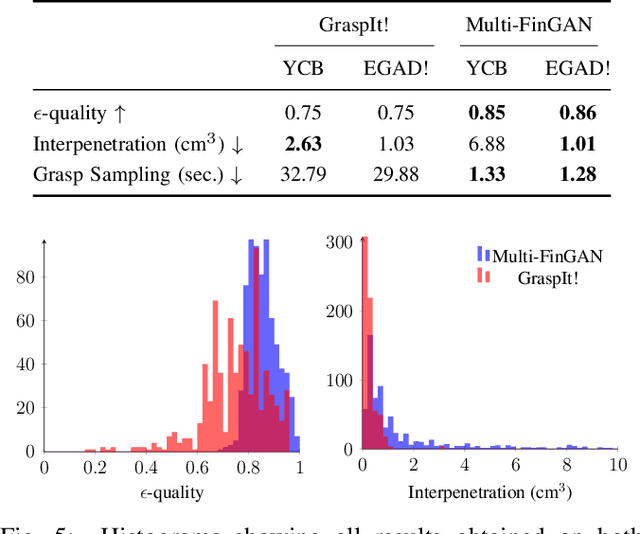
While there exists a large number of methods for manipulating rigid objects with parallel-jaw grippers, grasping with multi-finger robotic hands remains a quite unexplored research topic. Reasoning and planning collision-free trajectories on the additional degrees of freedom of several fingers represents an important challenge that, so far, involves computationally costly and slow processes. In this work, we present Multi-FinGAN, a fast generative multi-finger grasp sampling method that synthesizes high quality grasps directly from RGB-D images in about a second. We achieve this by training in an end-to-end fashion a coarse-to-fine model composed of a classification network that distinguishes grasp types according to a specific taxonomy and a refinement network that produces refined grasp poses and joint angles. We experimentally validate and benchmark our method against standard grasp-sampling methods on 790 grasps in simulation and 20 grasps on a real Franka Emika Panda. All experimental results using our method show consistent improvements both in terms of grasp quality metrics and grasp success rate. Remarkably, our approach is up to 20-30 times faster than the baseline, a significant improvement that opens the door to feedback-based grasp re-planning and task informative grasping.
D-NeRF: Neural Radiance Fields for Dynamic Scenes
Nov 27, 2020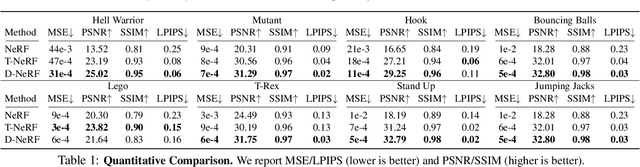
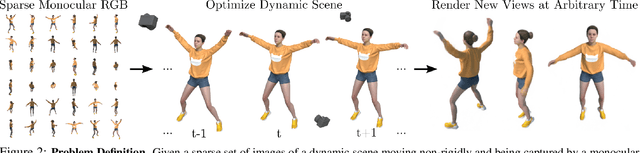
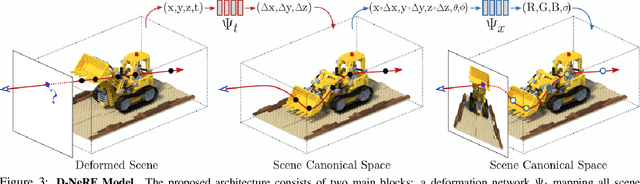

Neural rendering techniques combining machine learning with geometric reasoning have arisen as one of the most promising approaches for synthesizing novel views of a scene from a sparse set of images. Among these, stands out the Neural radiance fields (NeRF), which trains a deep network to map 5D input coordinates (representing spatial location and viewing direction) into a volume density and view-dependent emitted radiance. However, despite achieving an unprecedented level of photorealism on the generated images, NeRF is only applicable to static scenes, where the same spatial location can be queried from different images. In this paper we introduce D-NeRF, a method that extends neural radiance fields to a dynamic domain, allowing to reconstruct and render novel images of objects under rigid and non-rigid motions from a \emph{single} camera moving around the scene. For this purpose we consider time as an additional input to the system, and split the learning process in two main stages: one that encodes the scene into a canonical space and another that maps this canonical representation into the deformed scene at a particular time. Both mappings are simultaneously learned using fully-connected networks. Once the networks are trained, D-NeRF can render novel images, controlling both the camera view and the time variable, and thus, the object movement. We demonstrate the effectiveness of our approach on scenes with objects under rigid, articulated and non-rigid motions. Code, model weights and the dynamic scenes dataset will be released.
PI-Net: Pose Interacting Network for Multi-Person Monocular 3D Pose Estimation
Oct 11, 2020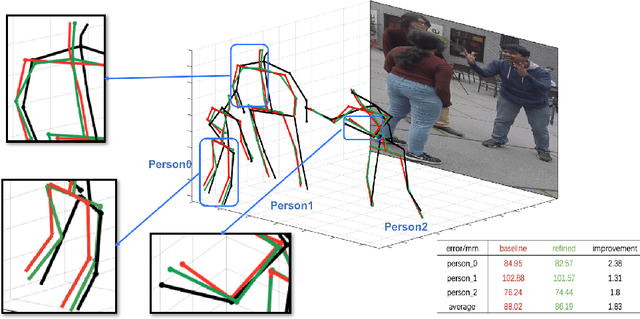
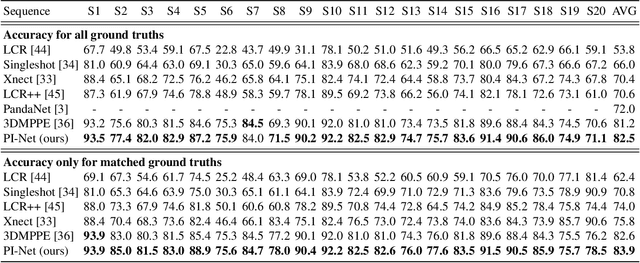
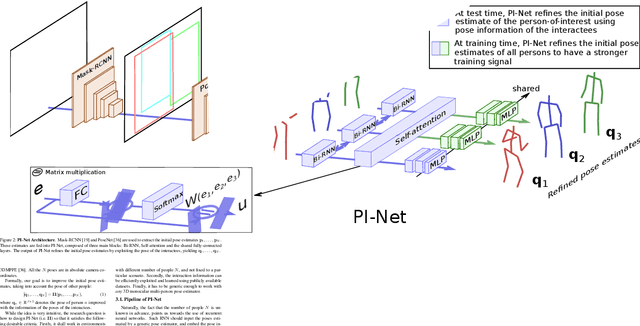
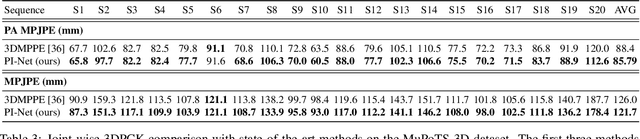
Recent literature addressed the monocular 3D pose estimation task very satisfactorily. In these studies, different persons are usually treated as independent pose instances to estimate. However, in many every-day situations, people are interacting, and the pose of an individual depends on the pose of his/her interactees. In this paper, we investigate how to exploit this dependency to enhance current - and possibly future - deep networks for 3D monocular pose estimation. Our pose interacting network, or PI-Net, inputs the initial pose estimates of a variable number of interactees into a recurrent architecture used to refine the pose of the person-of-interest. Evaluating such a method is challenging due to the limited availability of public annotated multi-person 3D human pose datasets. We demonstrate the effectiveness of our method in the MuPoTS dataset, setting the new state-of-the-art on it. Qualitative results on other multi-person datasets (for which 3D pose ground-truth is not available) showcase the proposed PI-Net. PI-Net is implemented in PyTorch and the code will be made available upon acceptance of the paper.
3D Human Shape and Pose from a Single Low-Resolution Image with Self-Supervised Learning
Aug 09, 2020
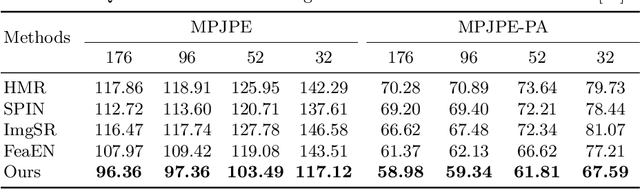
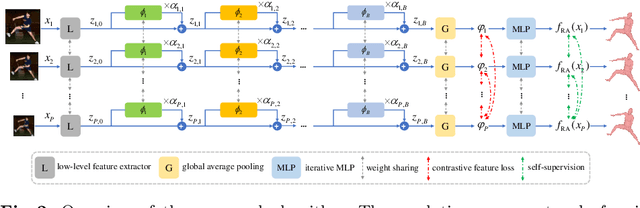
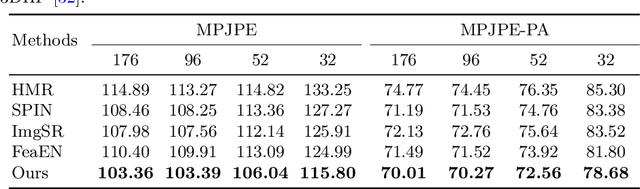
3D human shape and pose estimation from monocular images has been an active area of research in computer vision, having a substantial impact on the development of new applications, from activity recognition to creating virtual avatars. Existing deep learning methods for 3D human shape and pose estimation rely on relatively high-resolution input images; however, high-resolution visual content is not always available in several practical scenarios such as video surveillance and sports broadcasting. Low-resolution images in real scenarios can vary in a wide range of sizes, and a model trained in one resolution does not typically degrade gracefully across resolutions. Two common approaches to solve the problem of low-resolution input are applying super-resolution techniques to the input images which may result in visual artifacts, or simply training one model for each resolution, which is impractical in many realistic applications. To address the above issues, this paper proposes a novel algorithm called RSC-Net, which consists of a Resolution-aware network, a Self-supervision loss, and a Contrastive learning scheme. The proposed network is able to learn the 3D body shape and pose across different resolutions with a single model. The self-supervision loss encourages scale-consistency of the output, and the contrastive learning scheme enforces scale-consistency of the deep features. We show that both these new training losses provide robustness when learning 3D shape and pose in a weakly-supervised manner. Extensive experiments demonstrate that the RSC-Net can achieve consistently better results than the state-of-the-art methods for challenging low-resolution images.
Neural Cellular Automata Manifold
Jun 22, 2020
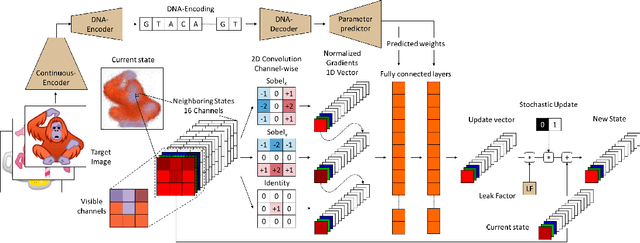
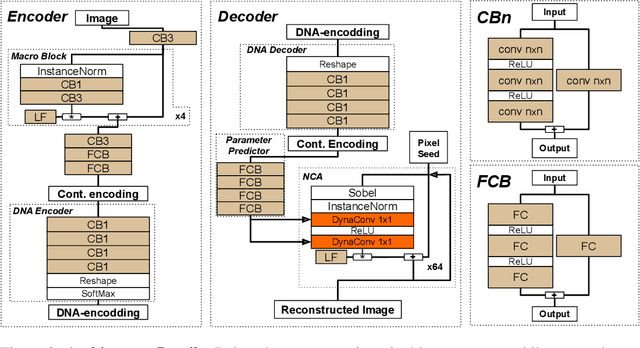

Very recently, a deep Neural Cellular Automata (NCA)[1] has been proposed to simulate the complex morphogenesis process with deep networks. This model learns to grow an image starting from a fixed single pixel. In this paper, we move a step further and propose a new model that extends the expressive power of NCA from a single image to an manifold of images. In biological terms, our approach would play the role of the transcription factors, modulating the mapping of genes into specific proteins that drive cellular differentiation, which occurs right before the morphogenesis. We accomplish this by introducing dynamic convolutions inside an Auto-Encoder architecture, for the first time used to join two different sources of information, the encoding and cell's environment information. The proposed model also extends the capabilities of the NCA to a general purpose network, which can be used in a broad range of problems. We thoroughly evaluate our approach in a dataset of synthetic emojis and also in real images of CIFAR-10.
Textual Visual Semantic Dataset for Text Spotting
Apr 21, 2020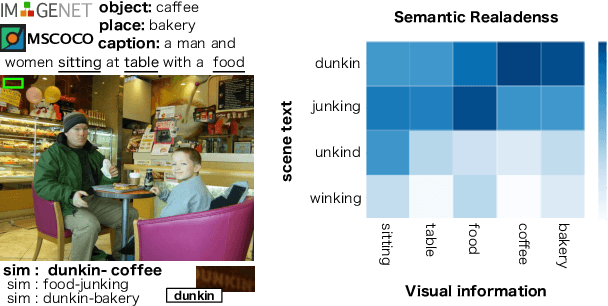

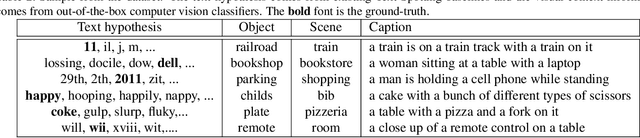

Text Spotting in the wild consists of detecting and recognizing text appearing in images (e.g. signboards, traffic signals or brands in clothing or objects). This is a challenging problem due to the complexity of the context where texts appear (uneven backgrounds, shading, occlusions, perspective distortions, etc.). Only a few approaches try to exploit the relation between text and its surrounding environment to better recognize text in the scene. In this paper, we propose a visual context dataset for Text Spotting in the wild, where the publicly available dataset COCO-text [Veit et al. 2016] has been extended with information about the scene (such as objects and places appearing in the image) to enable researchers to include semantic relations between texts and scene in their Text Spotting systems, and to offer a common framework for such approaches. For each text in an image, we extract three kinds of context information: objects in the scene, image location label and a textual image description (caption). We use state-of-the-art out-of-the-box available tools to extract this additional information. Since this information has textual form, it can be used to leverage text similarity or semantic relation methods into Text Spotting systems, either as a post-processing or in an end-to-end training strategy. Our data is publicly available at https://git.io/JeZTb.
C-Flow: Conditional Generative Flow Models for Images and 3D Point Clouds
Dec 15, 2019
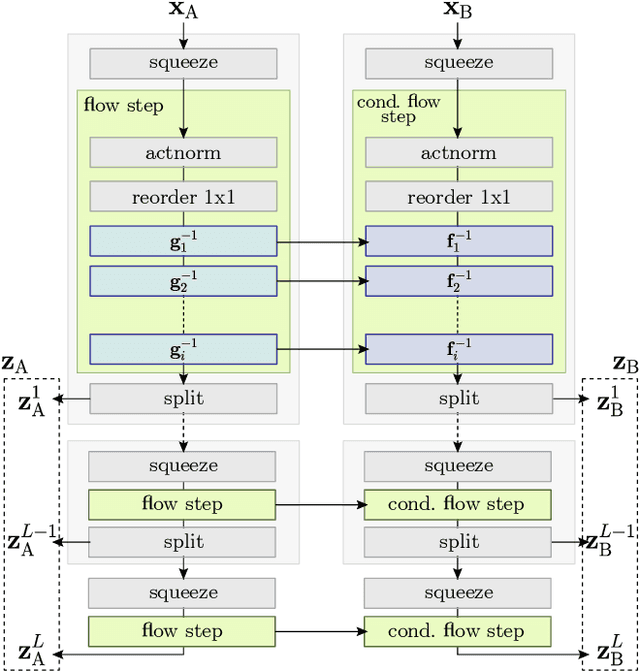
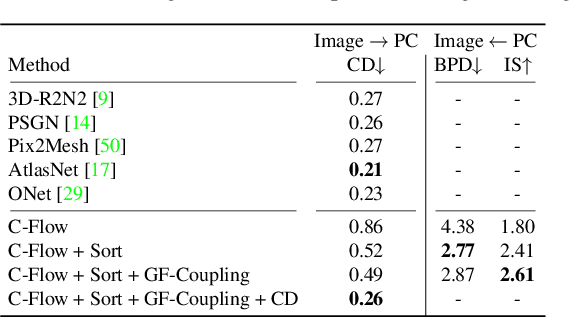
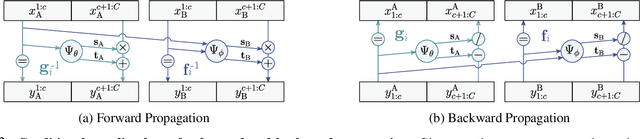
Flow-based generative models have highly desirable properties like exact log-likelihood evaluation and exact latent-variable inference, however they are still in their infancy and have not received as much attention as alternative generative models. In this paper, we introduce C-Flow, a novel conditioning scheme that brings normalizing flows to an entirely new scenario with great possibilities for multi-modal data modeling. C-Flow is based on a parallel sequence of invertible mappings in which a source flow guides the target flow at every step, enabling fine-grained control over the generation process. We also devise a new strategy to model unordered 3D point clouds that, in combination with the conditioning scheme, makes it possible to address 3D reconstruction from a single image and its inverse problem of rendering an image given a point cloud. We demonstrate our conditioning method to be very adaptable, being also applicable to image manipulation, style transfer and multi-modal image-to-image mapping in a diversity of domains, including RGB images, segmentation maps, and edge masks.
Improving Map Re-localization with Deep 'Movable' Objects Segmentation on 3D LiDAR Point Clouds
Oct 08, 2019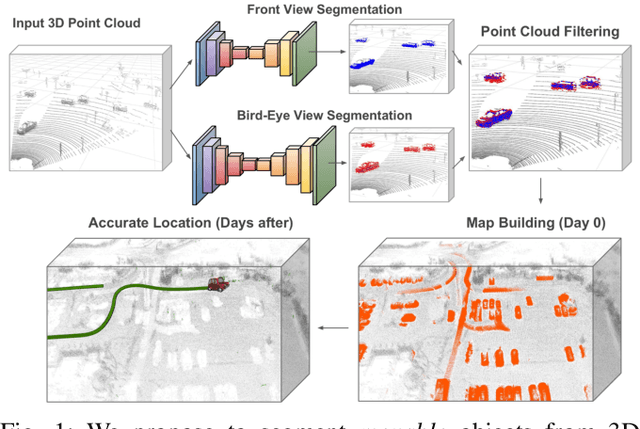
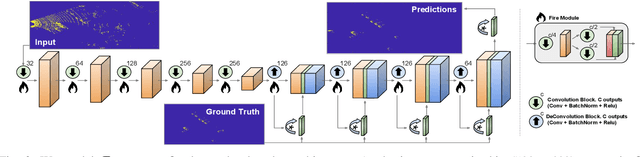
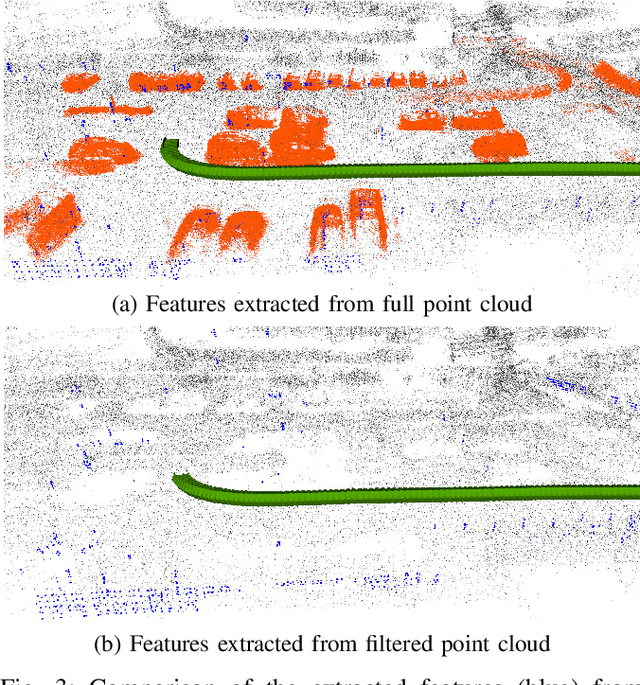
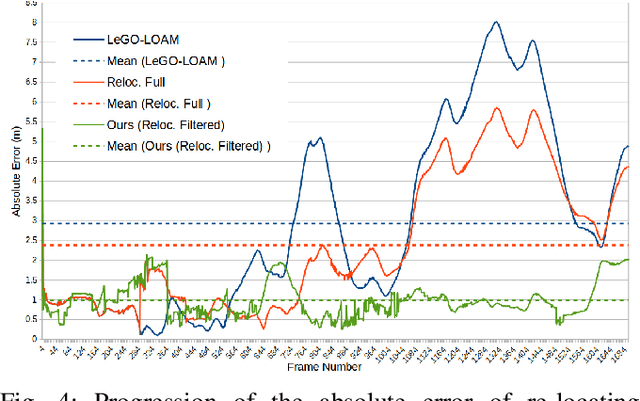
Localization and Mapping is an essential component to enable Autonomous Vehicles navigation, and requires an accuracy exceeding that of commercial GPS-based systems. Current odometry and mapping algorithms are able to provide this accurate information. However, the lack of robustness of these algorithms against dynamic obstacles and environmental changes, even for short time periods, forces the generation of new maps on every session without taking advantage of previously obtained ones. In this paper we propose the use of a deep learning architecture to segment movable objects from 3D LiDAR point clouds in order to obtain longer-lasting 3D maps. This will in turn allow for better, faster and more accurate re-localization and trajectoy estimation on subsequent days. We show the effectiveness of our approach in a very dynamic and cluttered scenario, a supermarket parking lot. For that, we record several sequences on different days and compare localization errors with and without our movable objects segmentation method. Results show that we are able to accurately re-locate over a filtered map, consistently reducing trajectory errors between an average of 35.1% with respect to a non-filtered map version and of 47.9% with respect to a standalone map created on the current session.