 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysXNet: A Customizable Approach for LearningCloth Dynamics on Dressed People
Nov 13, 2021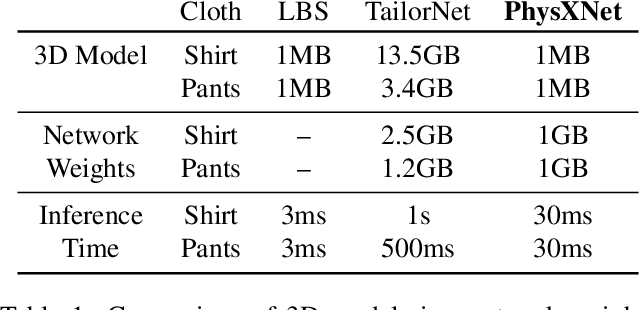
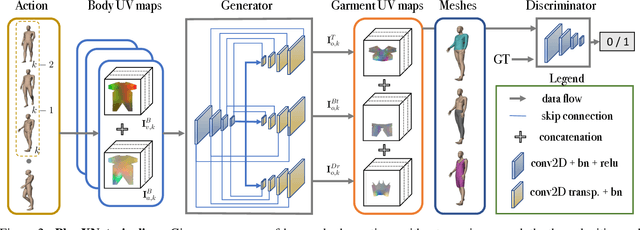
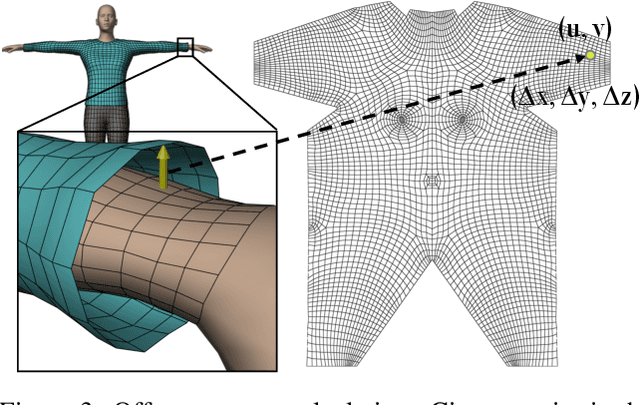
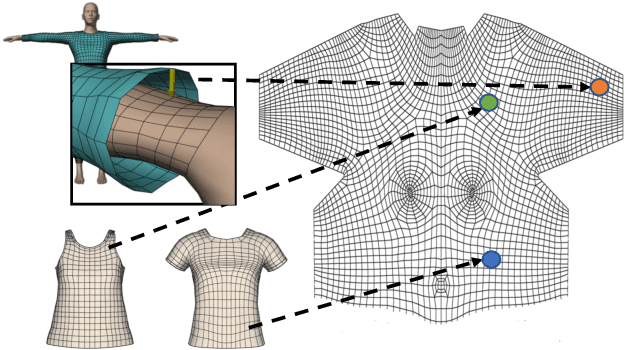
We introduce PhysXNet, a learning-based approach to predict the dynamics of deformable clothes given 3D skeleton motion sequences of humans wearing these clothes. The proposed model is adaptable to a large variety of garments and changing topologies, without need of being retrained. Such simulations are typically carried out by physics engines that require manual human expertise and are subjectto computationally intensive computations. PhysXNet, by contrast, is a fully differentiable deep network that at inference is able to estimate the geometry of dense cloth meshes in a matter of milliseconds, and thus, can be readily deployed as a layer of a larger deep learning architecture. This efficiency is achieved thanks to the specific parameterization of the clothes we consider, based on 3D UV maps encoding spatial garment displacements. The problem is then formulated as a mapping between the human kinematics space (represented also by 3D UV maps of the undressed body mesh) into the clothes displacement UV maps, which we learn using a conditional GAN with a discriminator that enforces feasible deformations. We train simultaneously our model for three garment templates, tops, bottoms and dresses for which we simulate deformations under 50 different human actions. Nevertheless, the UV map representation we consider allows encapsulating many different cloth topologies, and at test we can simulate garments even if we did not specifically train for them. A thorough evaluation demonstrates that PhysXNet delivers cloth deformations very close to those computed with the physical engine, opening the door to be effectively integrated within deeplearning pipelines.
Body Size and Depth Disambiguation in Multi-Person Reconstruction from Single Images
Nov 02, 2021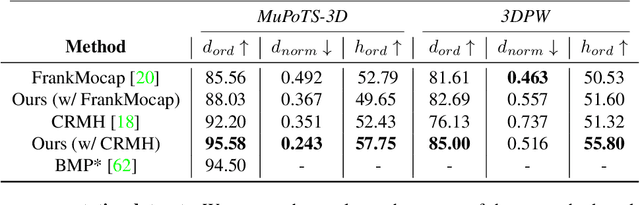
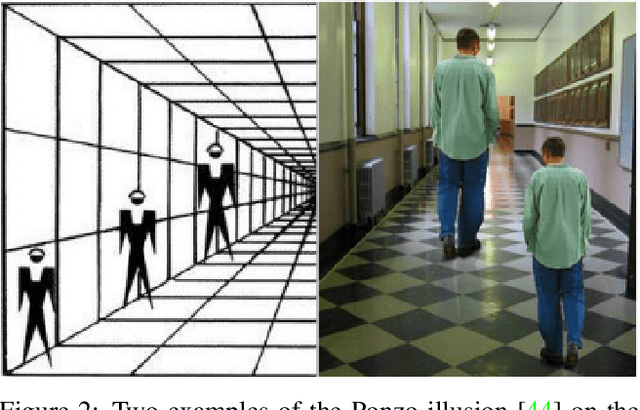
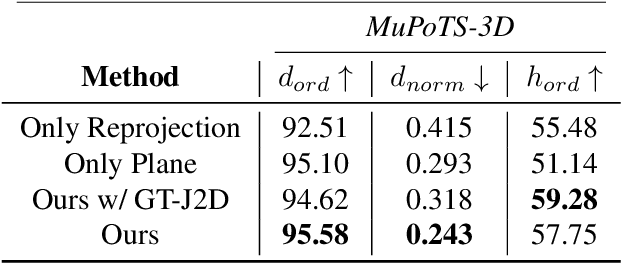
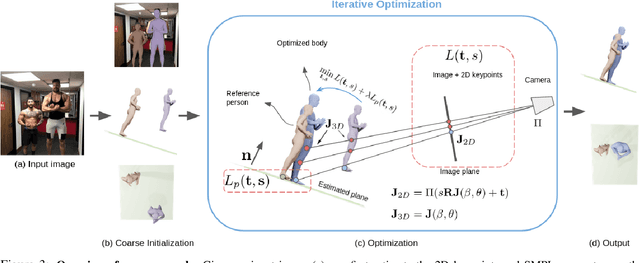
We address the problem of multi-person 3D body pose and shape estimation from a single image. While this problem can be addressed by applying single-person approaches multiple times for the same scene, recent works have shown the advantages of building upon deep architectures that simultaneously reason about all people in the scene in a holistic manner by enforcing, e.g., depth order constraints or minimizing interpenetration among reconstructed bodies. However, existing approaches are still unable to capture the size variability of people caused by the inherent body scale and depth ambiguity. In this work, we tackle this challenge by devising a novel optimization scheme that learns the appropriate body scale and relative camera pose, by enforcing the feet of all people to remain on the ground floor. A thorough evaluation on MuPoTS-3D and 3DPW datasets demonstrates that our approach is able to robustly estimate the body translation and shape of multiple people while retrieving their spatial arrangement, consistently improving current state-of-the-art, especially in scenes with people of very different heights
An Adaptable Approach to Learn Realistic Legged Locomotion without Examples
Oct 28, 2021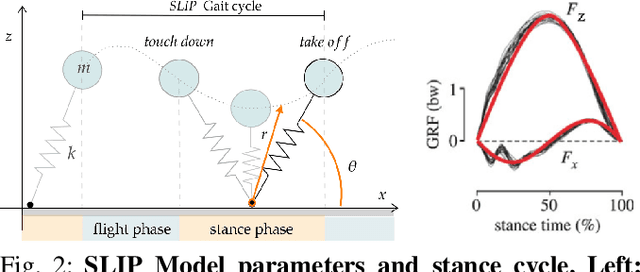
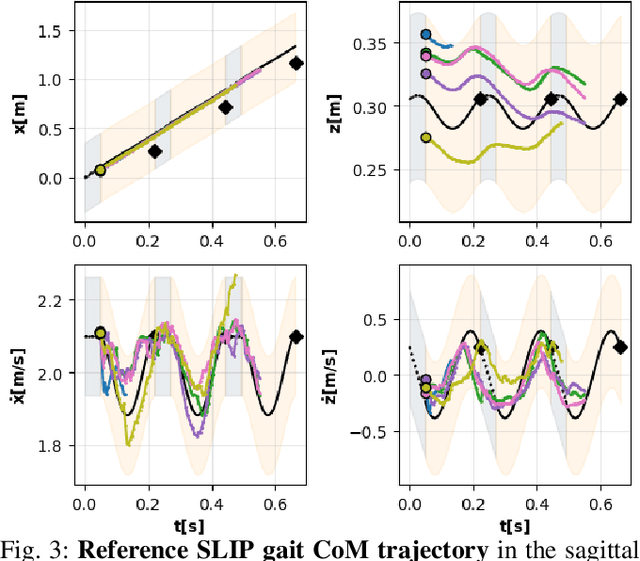
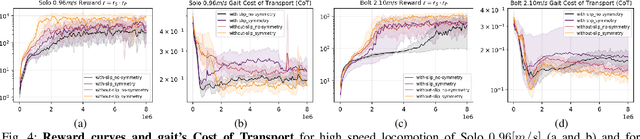
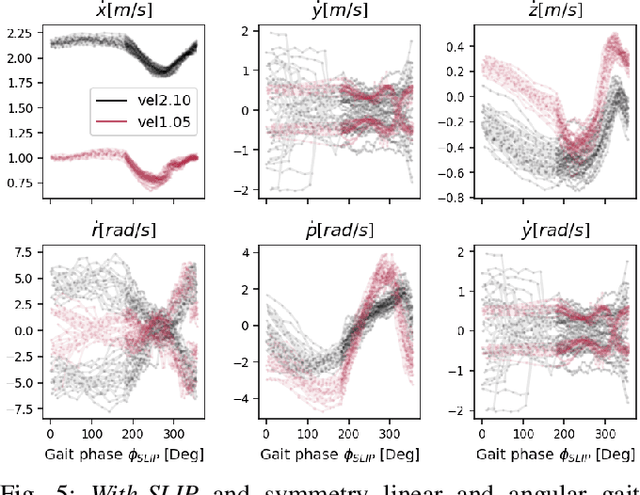
Learning controllers that reproduce legged locomotion in nature have been a long-time goal in robotics and computer graphics. While yielding promising results, recent approaches are not yet flexible enough to be applicable to legged systems of different morphologies. This is partly because they often rely on precise motion capture references or elaborate learning environments that ensure the naturality of the emergent locomotion gaits but prevent generalization. This work proposes a generic approach for ensuring realism in locomotion by guiding the learning process with the spring-loaded inverted pendulum model as a reference. Leveraging on the exploration capacities of Reinforcement Learning (RL), we learn a control policy that fills in the information gap between the template model and full-body dynamics required to maintain stable and periodic locomotion. The proposed approach can be applied to robots of different sizes and morphologies and adapted to any RL technique and control architecture. We present experimental results showing that even in a model-free setup and with a simple reactive control architecture, the learned policies can generate realistic and energy-efficient locomotion gaits for a bipedal and a quadrupedal robot. And most importantly, this is achieved without using motion capture, strong constraints in the dynamics or kinematics of the robot, nor prescribing limb coordination. We provide supplemental videos for qualitative analysis of the naturality of the learned gaits.
Grasp-Oriented Fine-grained Cloth Segmentation without Real Supervision
Oct 06, 2021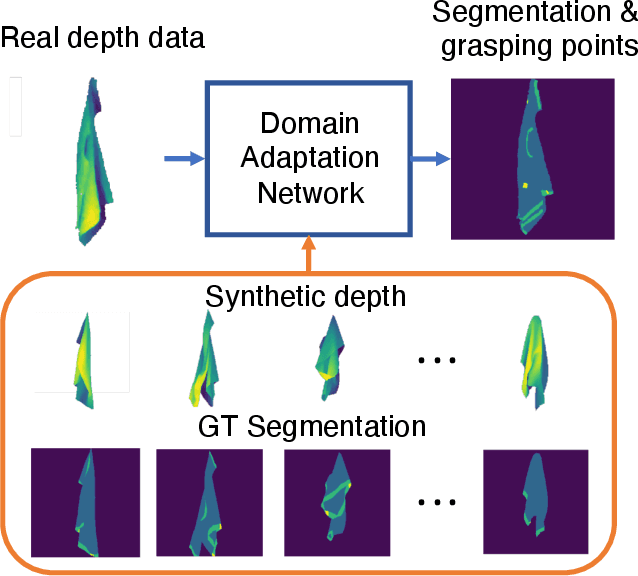
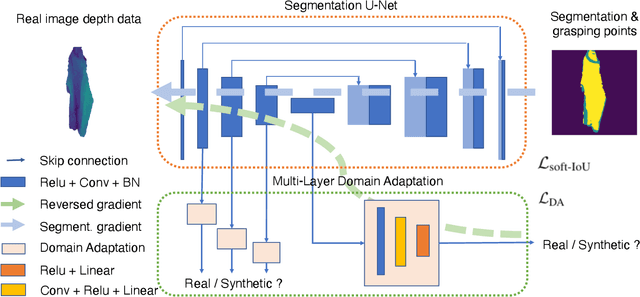

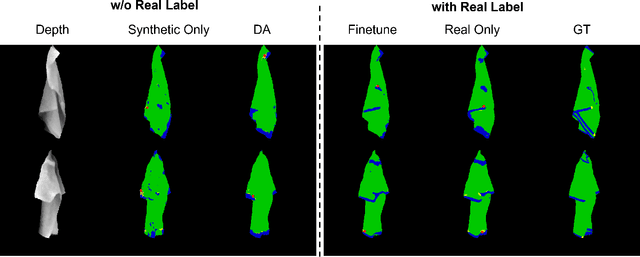
Automatically detecting graspable regions from a single depth image is a key ingredient in cloth manipulation. The large variability of cloth deformations has motivated most of the current approaches to focus on identifying specific grasping points rather than semantic parts, as the appearance and depth variations of local regions are smaller and easier to model than the larger ones. However, tasks like cloth folding or assisted dressing require recognising larger segments, such as semantic edges that carry more information than points. The first goal of this paper is therefore to tackle the problem of fine-grained region detection in deformed clothes using only a depth image. As a proof of concept, we implement an approach for T-shirts, and define up to 6 semantic regions of varying extent, including edges on the neckline, sleeve cuffs, and hem, plus top and bottom grasping points. We introduce a U-net based network to segment and label these parts. The second contribution of our work is concerned with the level of supervision that we require to train the proposed network. While most approaches learn to detect grasping points by combining real and synthetic annotations, in this work we defy the limitations of the synthetic data, and propose a multilayered domain adaptation (DA) strategy that does not use real annotations at all. We thoroughly evaluate our approach on real depth images of a T-shirt annotated with fine-grained labels. We show that training our network solely with synthetic data and the proposed DA yields results competitive with models trained on real data.
Stochastic Neural Radiance Fields: Quantifying Uncertainty in Implicit 3D Representations
Sep 28, 2021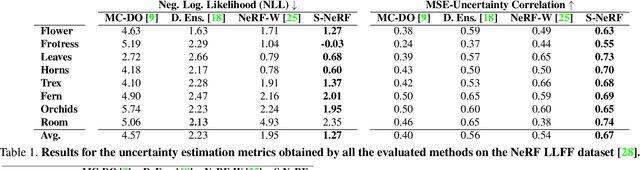
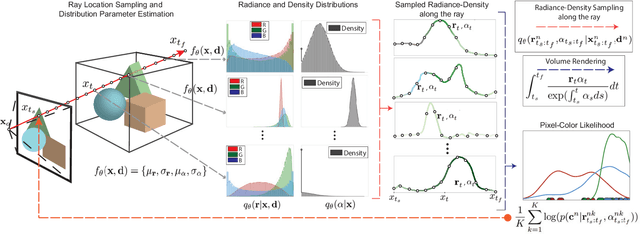
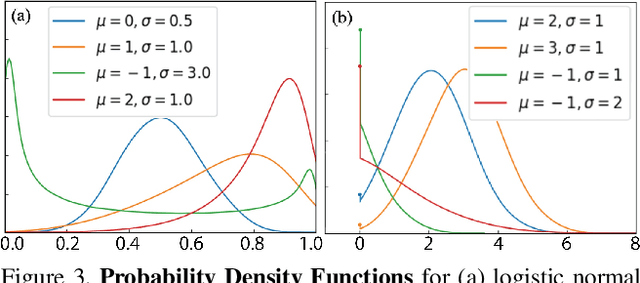
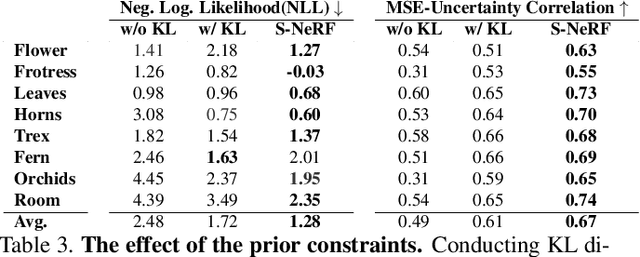
Neural Radiance Fields (NeRF) has become a popular framework for learning implicit 3D representations and addressing different tasks such as novel-view synthesis or depth-map estimation. However, in downstream applications where decisions need to be made based on automatic predictions, it is critical to leverage the confidence associated with the model estimations. Whereas uncertainty quantification is a long-standing problem in Machine Learning, it has been largely overlooked in the recent NeRF literature. In this context, we propose Stochastic Neural Radiance Fields (S-NeRF), a generalization of standard NeRF that learns a probability distribution over all the possible radiance fields modeling the scene. This distribution allows to quantify the uncertainty associated with the scene information provided by the model. S-NeRF optimization is posed as a Bayesian learning problem which is efficiently addressed using the Variational Inference framework. Exhaustive experiments over benchmark datasets demonstrate that S-NeRF is able to provide more reliable predictions and confidence values than generic approaches previously proposed for uncertainty estimation in other domains.
SIDER: Single-Image Neural Optimization for Facial Geometric Detail Recovery
Aug 11, 2021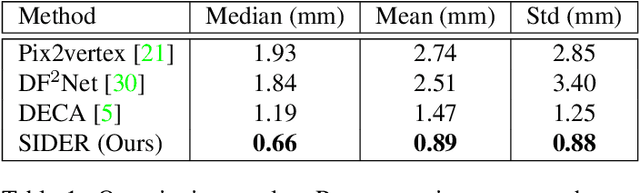
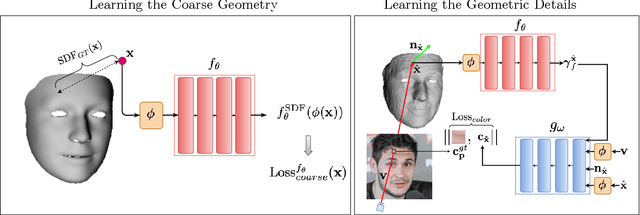


We present SIDER(Single-Image neural optimization for facial geometric DEtail Recovery), a novel photometric optimization method that recovers detailed facial geometry from a single image in an unsupervised manner. Inspired by classical techniques of coarse-to-fine optimization and recent advances in implicit neural representations of 3D shape, SIDER combines a geometry prior based on statistical models and Signed Distance Functions (SDFs) to recover facial details from single images. First, it estimates a coarse geometry using a morphable model represented as an SDF. Next, it reconstructs facial geometry details by optimizing a photometric loss with respect to the ground truth image. In contrast to prior work, SIDER does not rely on any dataset priors and does not require additional supervision from multiple views, lighting changes or ground truth 3D shape. Extensive qualitative and quantitative evaluation demonstrates that our method achieves state-of-the-art on facial geometric detail recovery, using only a single in-the-wild image.
H3D-Net: Few-Shot High-Fidelity 3D Head Reconstruction
Jul 26, 2021
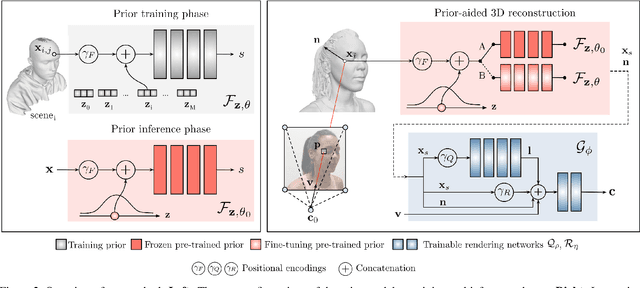


Recent learning approaches that implicitly represent surface geometry using coordinate-based neural representations have shown impressive results in the problem of multi-view 3D reconstruction. The effectiveness of these techniques is, however, subject to the availability of a large number (several tens) of input views of the scene, and computationally demanding optimizations. In this paper, we tackle these limitations for the specific problem of few-shot full 3D head reconstruction, by endowing coordinate-based representations with a probabilistic shape prior that enables faster convergence and better generalization when using few input images (down to three). First, we learn a shape model of 3D heads from thousands of incomplete raw scans using implicit representations. At test time, we jointly overfit two coordinate-based neural networks to the scene, one modeling the geometry and another estimating the surface radiance, using implicit differentiable rendering. We devise a two-stage optimization strategy in which the learned prior is used to initialize and constrain the geometry during an initial optimization phase. Then, the prior is unfrozen and fine-tuned to the scene. By doing this, we achieve high-fidelity head reconstructions, including hair and shoulders, and with a high level of detail that consistently outperforms both state-of-the-art 3D Morphable Models methods in the few-shot scenario, and non-parametric methods when large sets of views are available.
Uncertainty-Aware Camera Pose Estimation from Points and Lines
Jul 08, 2021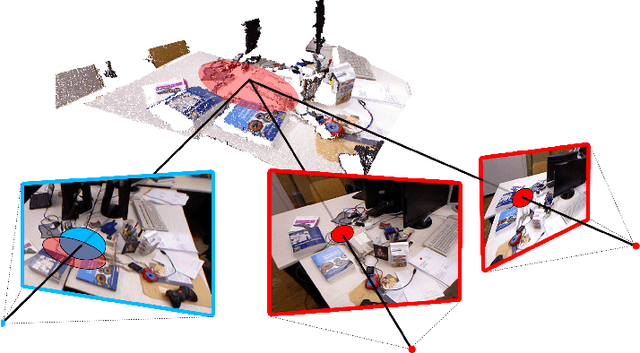
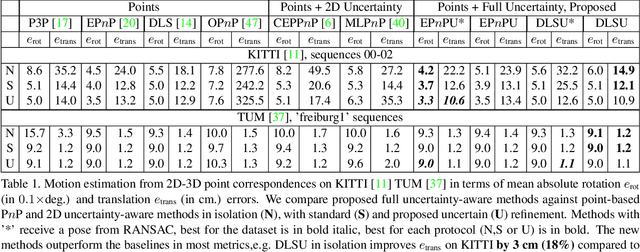
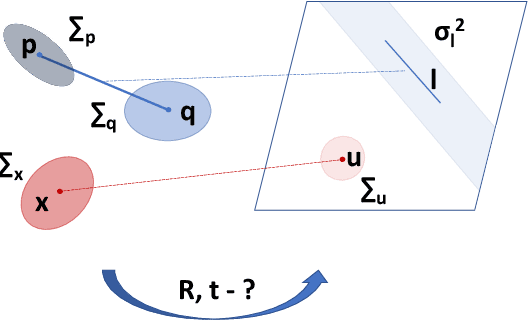
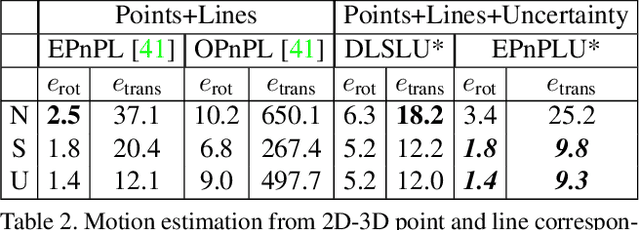
Perspective-n-Point-and-Line (P$n$PL) algorithms aim at fast, accurate, and robust camera localization with respect to a 3D model from 2D-3D feature correspondences, being a major part of modern robotic and AR/VR systems. Current point-based pose estimation methods use only 2D feature detection uncertainties, and the line-based methods do not take uncertainties into account. In our setup, both 3D coordinates and 2D projections of the features are considered uncertain. We propose PnP(L) solvers based on EPnP and DLS for the uncertainty-aware pose estimation. We also modify motion-only bundle adjustment to take 3D uncertainties into account. We perform exhaustive synthetic and real experiments on two different visual odometry datasets. The new PnP(L) methods outperform the state-of-the-art on real data in isolation, showing an increase in mean translation accuracy by 18% on a representative subset of KITTI, while the new uncertain refinement improves pose accuracy for most of the solvers, e.g. decreasing mean translation error for the EPnP by 16% compared to the standard refinement on the same dataset. The code is available at https://alexandervakhitov.github.io/uncertain-pnp/.
Multi-Person Extreme Motion Prediction with Cross-Interaction Attention
May 20, 2021
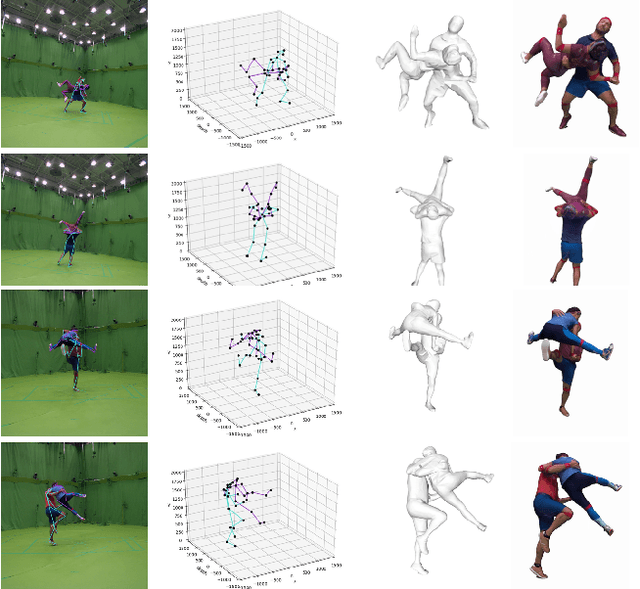

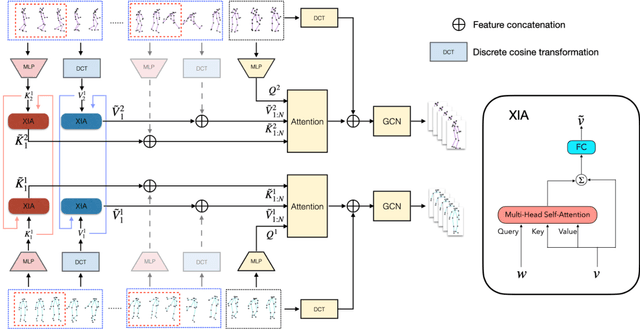
Human motion prediction aims to forecast future human poses given a sequence of past 3D skeletons. While this problem has recently received increasing attention, it has mostly been tackled for single humans in isolation. In this paper we explore this problem from a novel perspective, involving humans performing collaborative tasks. We assume that the input of our system are two sequences of past skeletons for two interacting persons, and we aim to predict the future motion for each of them. For this purpose, we devise a novel cross interaction attention mechanism that exploits historical information of both persons and learns to predict cross dependencies between self poses and the poses of the other person in spite of their spatial or temporal distance. Since no dataset to train such interactive situations is available, we have captured ExPI (Extreme Pose Interaction), a new lab-based person interaction dataset of professional dancers performing acrobatics. ExPI contains 115 sequences with 30k frames and 60k instances with annotated 3D body poses and shapes. We thoroughly evaluate our cross-interaction network on this dataset and show that both in short-term and long-term predictions, it consistently outperforms baselines that independently reason for each person. We plan to release our code jointly with the dataset and the train/test splits to spur future research on the topic.
SMPLicit: Topology-aware Generative Model for Clothed People
Apr 02, 2021
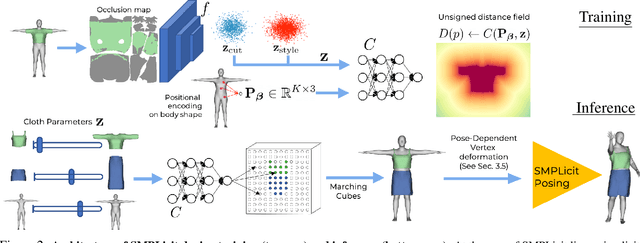
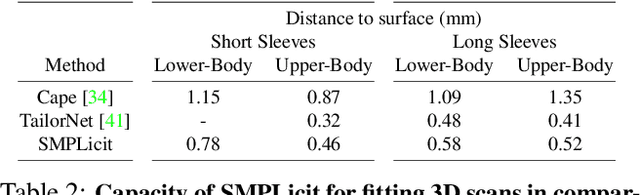
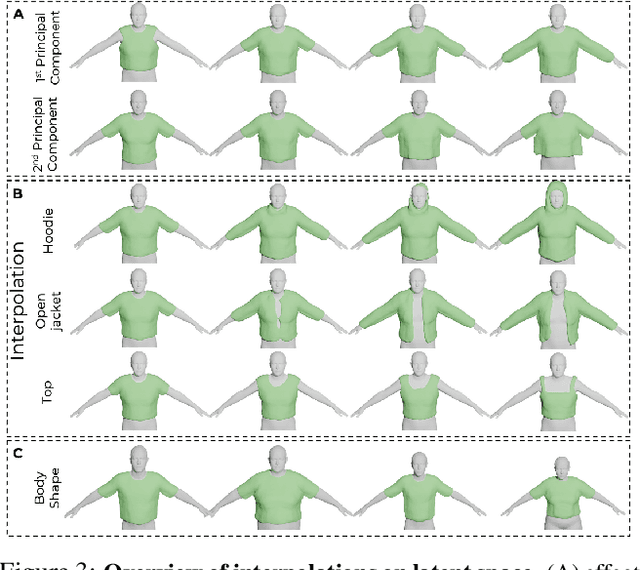
In this paper we introduce SMPLicit, a novel generative model to jointly represent body pose, shape and clothing geometry. In contrast to existing learning-based approaches that require training specific models for each type of garment, SMPLicit can represent in a unified manner different garment topologies (e.g. from sleeveless tops to hoodies and to open jackets), while controlling other properties like the garment size or tightness/looseness. We show our model to be applicable to a large variety of garments including T-shirts, hoodies, jackets, shorts, pants, skirts, shoes and even hair. The representation flexibility of SMPLicit builds upon an implicit model conditioned with the SMPL human body parameters and a learnable latent space which is semantically interpretable and aligned with the clothing attributes. The proposed model is fully differentiable, allowing for its use into larger end-to-end trainable systems. In the experimental section, we demonstrate SMPLicit can be readily used for fitting 3D scans and for 3D reconstruction in images of dressed people. In both cases we are able to go beyond state of the art, by retrieving complex garment geometries, handling situations with multiple clothing layers and providing a tool for easy outfit editing. To stimulate further research in this direction, we will make our code and model publicly available at http://www.iri.upc.edu/people/ecorona/smplicit/.