 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIRA: Relightable Avatars from a Single Image
Sep 07, 2022
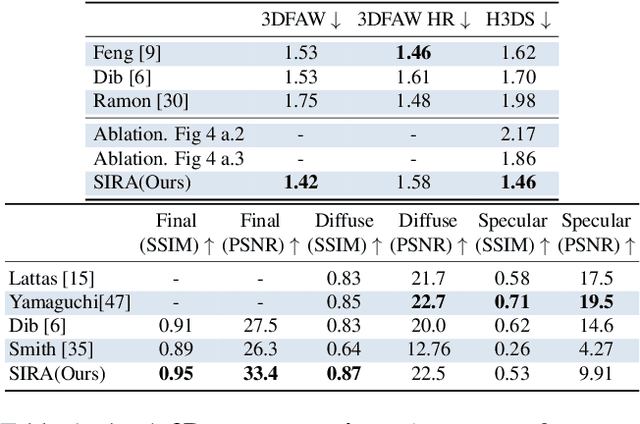


Recovering the geometry of a human head from a single image, while factorizing the materials and illumination is a severely ill-posed problem that requires prior information to be solved. Methods based on 3D Morphable Models (3DMM), and their combination with differentiable renderers, have shown promising results. However, the expressiveness of 3DMMs is limited, and they typically yield over-smoothed and identity-agnostic 3D shapes limited to the face region. Highly accurate full head reconstructions have recently been obtained with neural fields that parameterize the geometry using multilayer perceptrons. The versatility of these representations has also proved effective for disentangling geometry, materials and lighting. However, these methods require several tens of input images. In this paper, we introduce SIRA, a method which, from a single image, reconstructs human head avatars with high fidelity geometry and factorized lights and surface materials. Our key ingredients are two data-driven statistical models based on neural fields that resolve the ambiguities of single-view 3D surface reconstruction and appearance factorization. Experiments show that SIRA obtains state of the art results in 3D head reconstruction while at the same time it successfully disentangles the global illumination, and the diffuse and specular albedos. Furthermore, our reconstructions are amenable to physically-based appearance editing and head model relighting.
Topic Detection in Continuous Sign Language Videos
Sep 01, 2022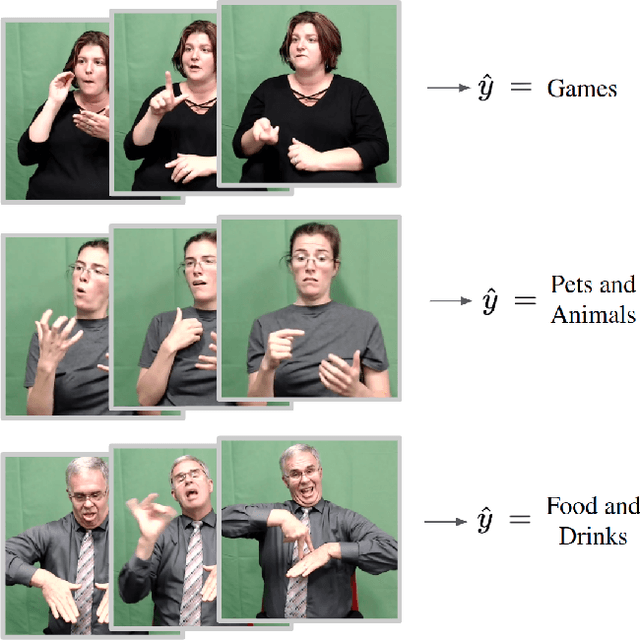
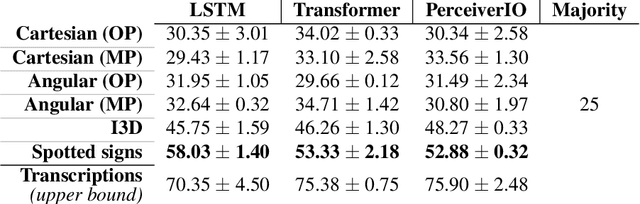
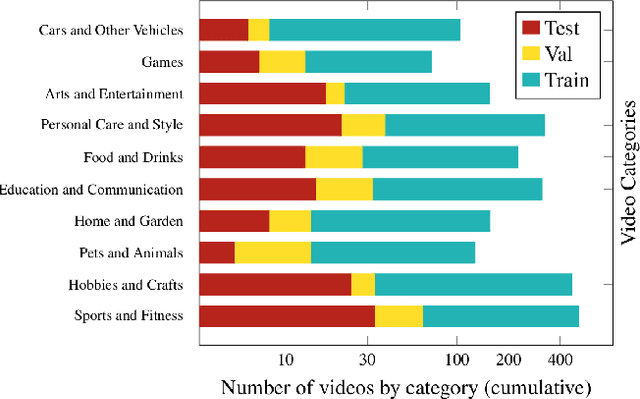
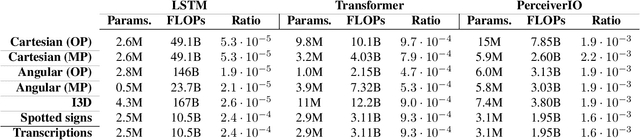
Significant progress has been made recently on challenging tasks in automatic sign language understanding, such as sign language recognition, translation and production. However, these works have focused on datasets with relatively few samples, short recordings and limited vocabulary and signing space. In this work, we introduce the novel task of sign language topic detection. We base our experiments on How2Sign, a large-scale video dataset spanning multiple semantic domains. We provide strong baselines for the task of topic detection and present a comparison between different visual features commonly used in the domain of sign language.
* Presented as an extended abstract in the "AVA: Accessibility, Vision, and Autonomy Meet" CVPR 2022 Workshop
Back to MLP: A Simple Baseline for Human Motion Prediction
Jul 04, 2022
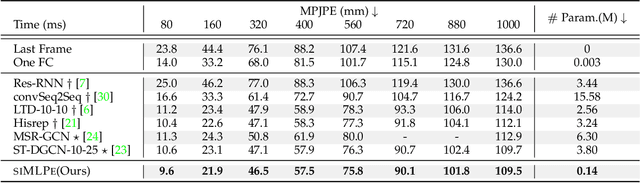
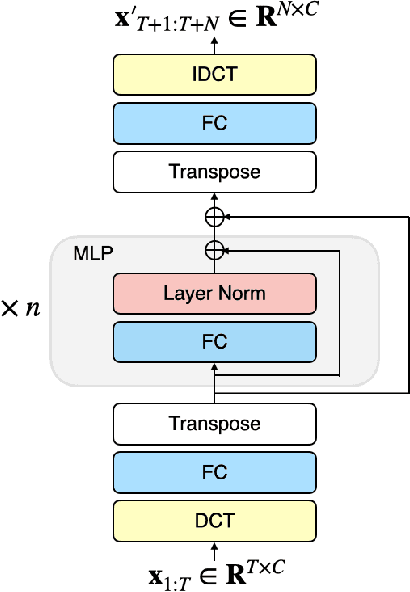

This paper tackles the problem of human motion prediction, consisting in forecasting future body poses from historically observed sequences. Despite of their performance, current state-of-the-art approaches rely on deep learning architectures of arbitrary complexity, such as Recurrent Neural Networks~(RNN), Transformers or Graph Convolutional Networks~(GCN), typically requiring multiple training stages and more than 3 million of parameters. In this paper we show that the performance of these approaches can be surpassed by a light-weight and purely MLP architecture with only 0.14M parameters when appropriately combined with several standard practices such as representing the body pose with Discrete Cosine Transform (DCT), predicting residual displacement of joints and optimizing velocity as an auxiliary loss. An exhaustive evaluation on Human3.6M, AMASS and 3DPW datasets shows that our method, which we dub siMLPe, consistently outperforms all other approaches. We hope that our simple method could serve a strong baseline to the community and allow re-thinking the problem of human motion prediction and whether current benchmarks do really need intricate architectural designs. Our code is available at \url{https://github.com/dulucas/siMLPe}.
Learned Vertex Descent: A New Direction for 3D Human Model Fitting
May 12, 2022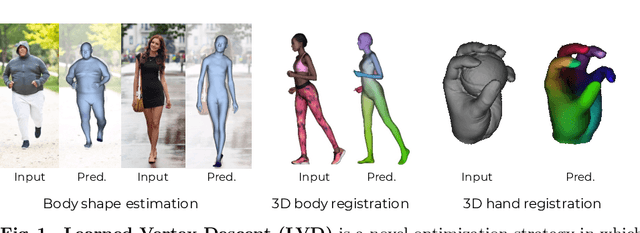
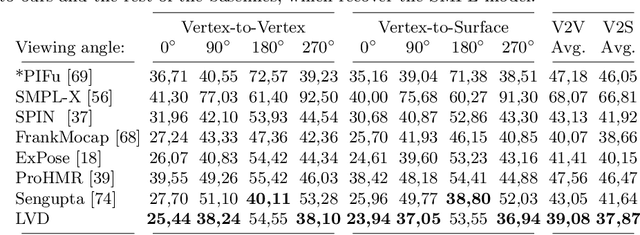
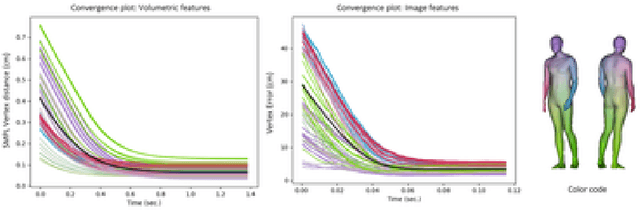
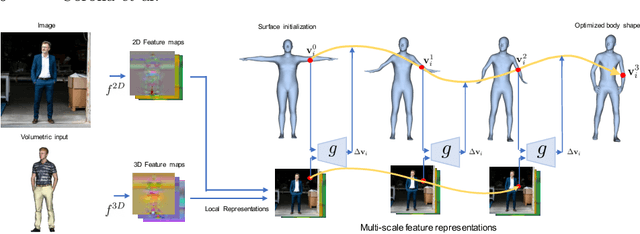
We propose a novel optimization-based paradigm for 3D human model fitting on images and scans. In contrast to existing approaches that directly regress the parameters of a low-dimensional statistical body model (e.g. SMPL) from input images, we train an ensemble of per-vertex neural fields network. The network predicts, in a distributed manner, the vertex descent direction towards the ground truth, based on neural features extracted at the current vertex projection. At inference, we employ this network, dubbed LVD, within a gradient-descent optimization pipeline until its convergence, which typically occurs in a fraction of a second even when initializing all vertices into a single point. An exhaustive evaluation demonstrates that our approach is able to capture the underlying body of clothed people with very different body shapes, achieving a significant improvement compared to state-of-the-art. LVD is also applicable to 3D model fitting of humans and hands, for which we show a significant improvement to the SOTA with a much simpler and faster method.
Single-view 3D Body and Cloth Reconstruction under Complex Poses
May 09, 2022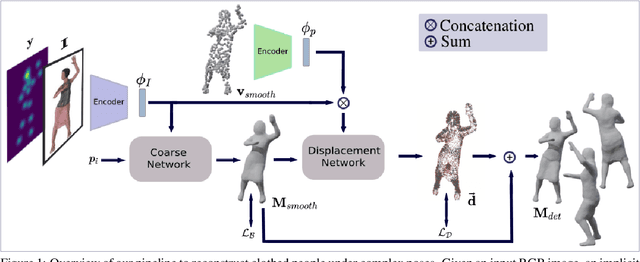
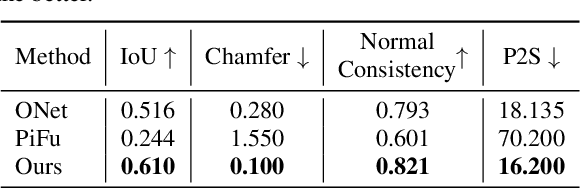
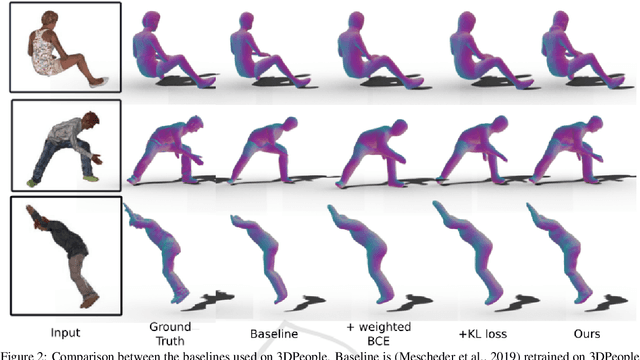

Recent advances in 3D human shape reconstruction from single images have shown impressive results, leveraging on deep networks that model the so-called implicit function to learn the occupancy status of arbitrarily dense 3D points in space. However, while current algorithms based on this paradigm, like PiFuHD, are able to estimate accurate geometry of the human shape and clothes, they require high-resolution input images and are not able to capture complex body poses. Most training and evaluation is performed on 1k-resolution images of humans standing in front of the camera under neutral body poses. In this paper, we leverage publicly available data to extend existing implicit function-based models to deal with images of humans that can have arbitrary poses and self-occluded limbs. We argue that the representation power of the implicit function is not sufficient to simultaneously model details of the geometry and of the body pose. We, therefore, propose a coarse-to-fine approach in which we first learn an implicit function that maps the input image to a 3D body shape with a low level of detail, but which correctly fits the underlying human pose, despite its complexity. We then learn a displacement map, conditioned on the smoothed surface and on the input image, which encodes the high-frequency details of the clothes and body. In the experimental section, we show that this coarse-to-fine strategy represents a very good trade-off between shape detail and pose correctness, comparing favorably to the most recent state-of-the-art approaches. Our code will be made publicly available.
Permutation-Invariant Relational Network for Multi-person 3D Pose Estimation
Apr 11, 2022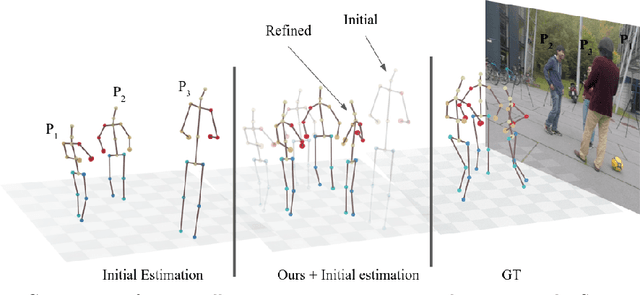
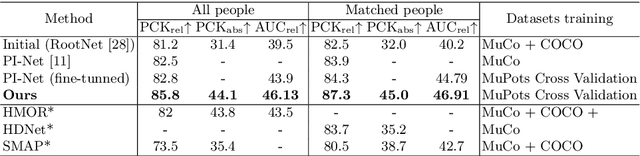
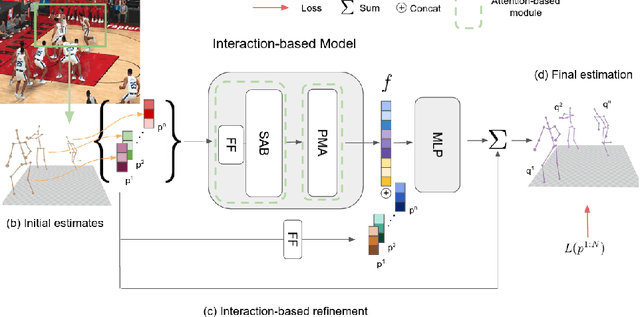
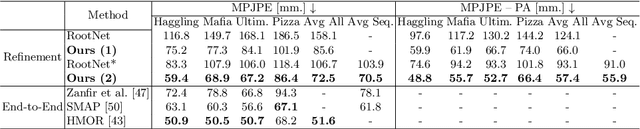
Recovering multi-person 3D poses from a single RGB image is a severely ill-conditioned problem due not only to the inherent 2D-3D depth ambiguity but also because of inter-person occlusions and body truncations. Recent works have shown promising results by simultaneously reasoning for different people but in all cases within a local neighborhood. An interesting exception is PI-Net, which introduces a self-attention block to reason for all people in the image at the same time and refine potentially noisy initial 3D poses. However, the proposed methodology requires defining one of the individuals as a reference, and the outcome of the algorithm is sensitive to this choice. In this paper, we model people interactions at a whole, independently of their number, and in a permutation-invariant manner building upon the Set Transformer. We leverage on this representation to refine the initial 3D poses estimated by off-the-shelf detectors. A thorough evaluation demonstrates that our approach is able to boost the performance of the initially estimated 3D poses by large margins, achieving state-of-the-art results on MuPoTS-3D, CMU Panoptic and NBA2K datasets. Additionally, the proposed module is computationally efficient and can be used as a drop-in complement for any 3D pose detector in multi-people scenes.
LISA: Learning Implicit Shape and Appearance of Hands
Apr 04, 2022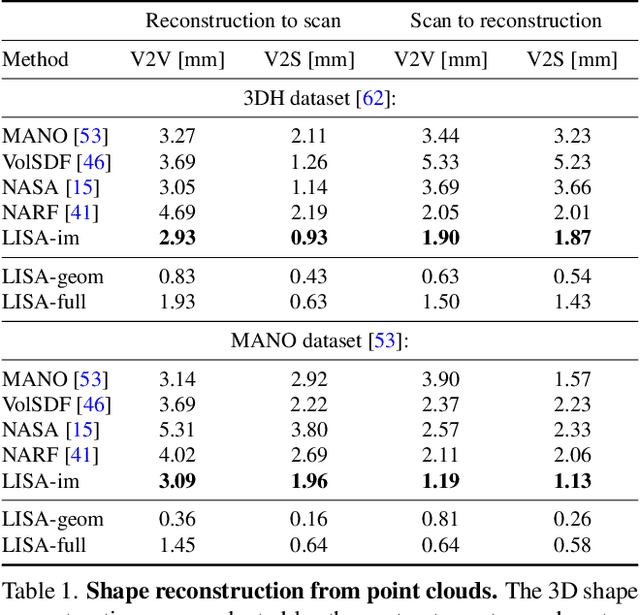
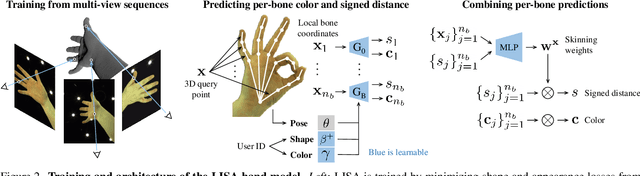
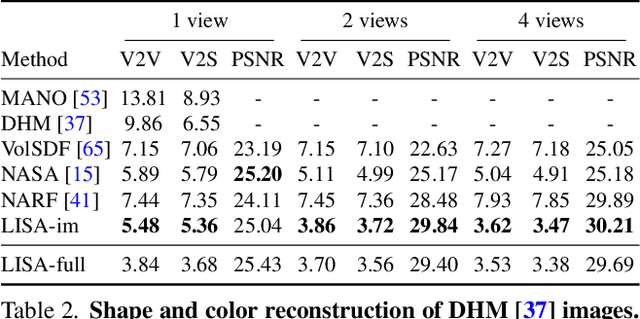
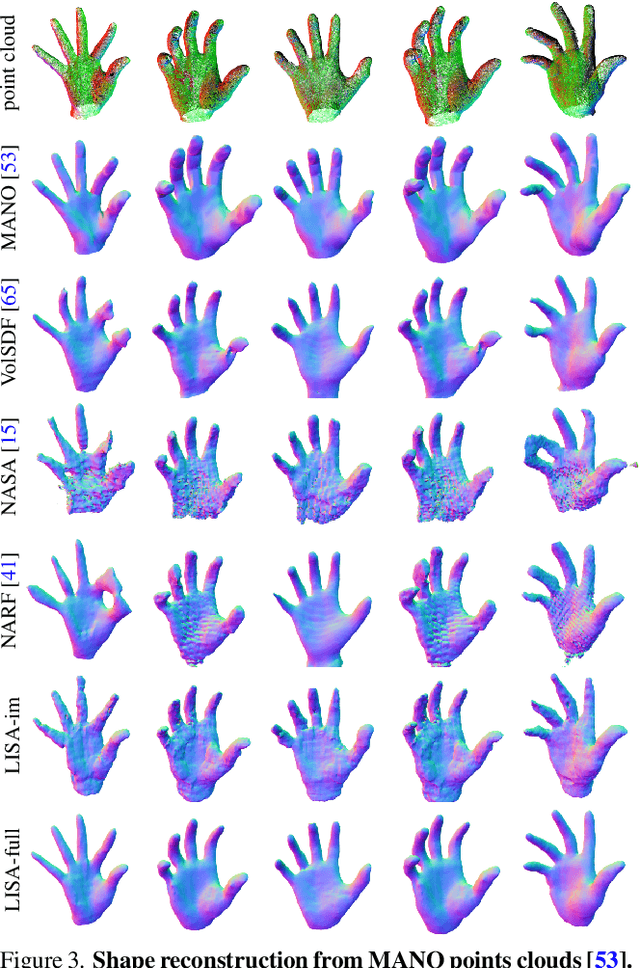
This paper proposes a do-it-all neural model of human hands, named LISA. The model can capture accurate hand shape and appearance, generalize to arbitrary hand subjects, provide dense surface correspondences, be reconstructed from images in the wild and easily animated. We train LISA by minimizing the shape and appearance losses on a large set of multi-view RGB image sequences annotated with coarse 3D poses of the hand skeleton. For a 3D point in the hand local coordinate, our model predicts the color and the signed distance with respect to each hand bone independently, and then combines the per-bone predictions using predicted skinning weights. The shape, color and pose representations are disentangled by design, allowing to estimate or animate only selected parameters. We experimentally demonstrate that LISA can accurately reconstruct a dynamic hand from monocular or multi-view sequences, achieving a noticeably higher quality of reconstructed hand shapes compared to baseline approaches. Project page: https://www.iri.upc.edu/people/ecorona/lisa/.
HiT-DVAE: Human Motion Generation via Hierarchical Transformer Dynamical VAE
Apr 04, 2022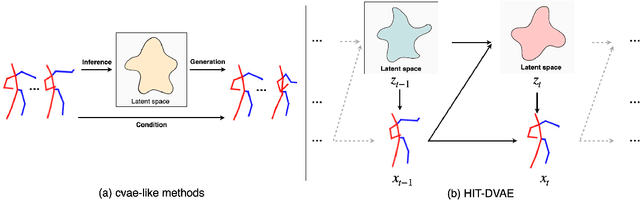
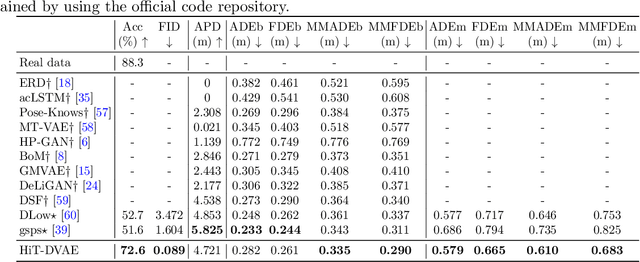
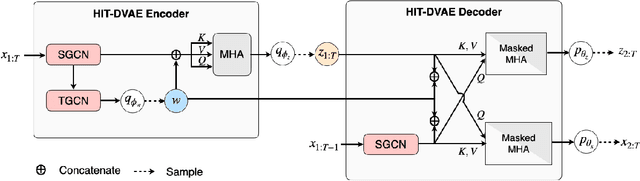
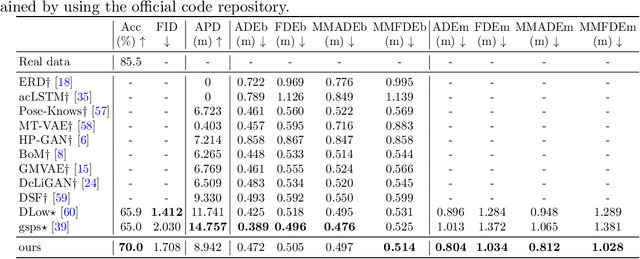
Studies on the automatic processing of 3D human pose data have flourished in the recent past. In this paper, we are interested in the generation of plausible and diverse future human poses following an observed 3D pose sequence. Current methods address this problem by injecting random variables from a single latent space into a deterministic motion prediction framework, which precludes the inherent multi-modality in human motion generation. In addition, previous works rarely explore the use of attention to select which frames are to be used to inform the generation process up to our knowledge. To overcome these limitations, we propose Hierarchical Transformer Dynamical Variational Autoencoder, HiT-DVAE, which implements auto-regressive generation with transformer-like attention mechanisms. HiT-DVAE simultaneously learns the evolution of data and latent space distribution with time correlated probabilistic dependencies, thus enabling the generative model to learn a more complex and time-varying latent space as well as diverse and realistic human motions. Furthermore, the auto-regressive generation brings more flexibility on observation and prediction, i.e. one can have any length of observation and predict arbitrary large sequences of poses with a single pre-trained model. We evaluate the proposed method on HumanEva-I and Human3.6M with various evaluation methods, and outperform the state-of-the-art methods on most of the metrics.
Conditional-Flow NeRF: Accurate 3D Modelling with Reliable Uncertainty Quantification
Mar 18, 2022
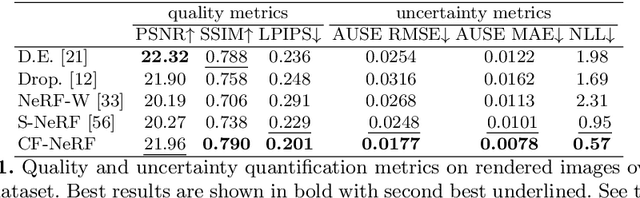

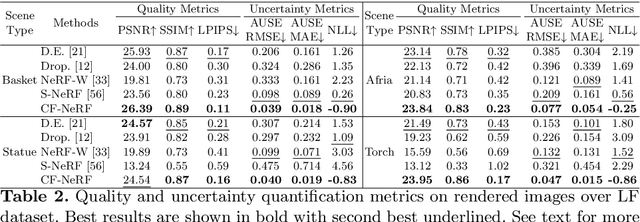
A critical limitation of current methods based on Neural Radiance Fields (NeRF) is that they are unable to quantify the uncertainty associated with the learned appearance and geometry of the scene. This information is paramount in real applications such as medical diagnosis or autonomous driving where, to reduce potentially catastrophic failures, the confidence on the model outputs must be included into the decision-making process. In this context, we introduce Conditional-Flow NeRF (CF-NeRF), a novel probabilistic framework to incorporate uncertainty quantification into NeRF-based approaches. For this purpose, our method learns a distribution over all possible radiance fields modelling which is used to quantify the uncertainty associated with the modelled scene. In contrast to previous approaches enforcing strong constraints over the radiance field distribution, CF-NeRF learns it in a flexible and fully data-driven manner by coupling Latent Variable Modelling and Conditional Normalizing Flows. This strategy allows to obtain reliable uncertainty estimation while preserving model expressivity. Compared to previous state-of-the-art methods proposed for uncertainty quantification in NeRF, our experiments show that the proposed method achieves significantly lower prediction errors and more reliable uncertainty values for synthetic novel view and depth-map estimation.
Enhancing Egocentric 3D Pose Estimation with Third Person Views
Jan 07, 2022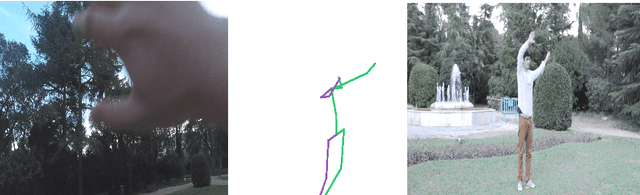


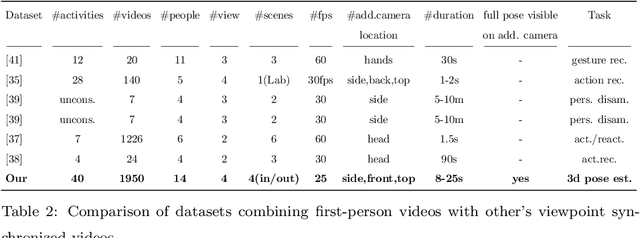
In this paper, we propose a novel approach to enhance the 3D body pose estimation of a person computed from videos captured from a single wearable camera. The key idea is to leverage high-level features linking first- and third-views in a joint embedding space. To learn such embedding space we introduce First2Third-Pose, a new paired synchronized dataset of nearly 2,000 videos depicting human activities captured from both first- and third-view perspectives. We explicitly consider spatial- and motion-domain features, combined using a semi-Siamese architecture trained in a self-supervised fashion. Experimental results demonstrate that the joint multi-view embedded space learned with our dataset is useful to extract discriminatory features from arbitrary single-view egocentric videos, without needing domain adaptation nor knowledge of camera parameters. We achieve significant improvement of egocentric 3D body pose estimation performance on two unconstrained datasets, over three supervised state-of-the-art approaches. Our dataset and code will be available for research purposes.