 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFolding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition
Sep 21, 2023



Transformer-based models excel in speech recognition. Existing efforts to optimize Transformer inference, typically for long-context applications, center on simplifying attention score calculations. However, streaming speech recognition models usually process a limited number of tokens each time, making attention score calculation less of a bottleneck. Instead, the bottleneck lies in the linear projection layers of multi-head attention and feedforward networks, constituting a substantial portion of the model size and contributing significantly to computation, memory, and power usage. To address this bottleneck, we propose folding attention, a technique targeting these linear layers, significantly reducing model size and improving memory and power efficiency. Experiments on on-device Transformer-based streaming speech recognition models show that folding attention reduces model size (and corresponding memory consumption) by up to 24% and power consumption by up to 23%, all without compromising model accuracy or computation overhead.
SqueezeBERT: What can computer vision teach NLP about efficient neural networks?
Jun 19, 2020
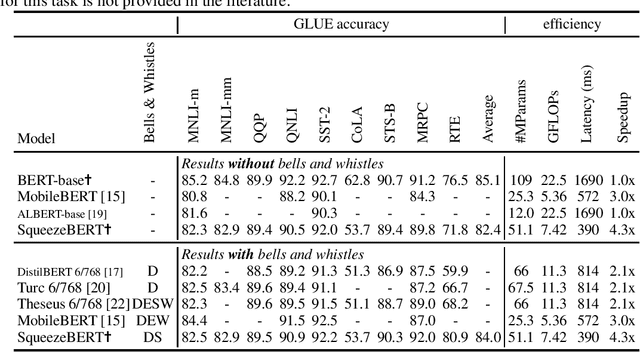
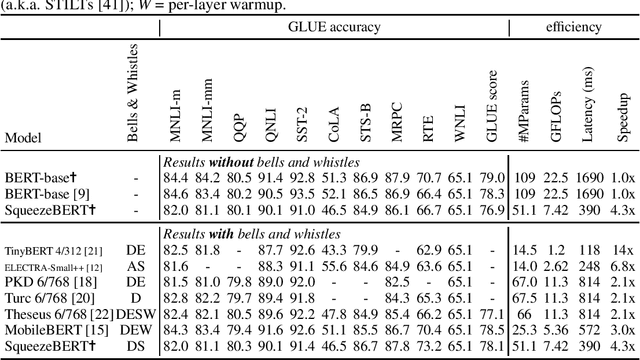

Humans read and write hundreds of billions of messages every day. Further, due to the availability of large datasets, large computing systems, and better neural network models, natural language processing (NLP) technology has made significant strides in understanding, proofreading, and organizing these messages. Thus, there is a significant opportunity to deploy NLP in myriad applications to help web users, social networks, and businesses. In particular, we consider smartphones and other mobile devices as crucial platforms for deploying NLP models at scale. However, today's highly-accurate NLP neural network models such as BERT and RoBERTa are extremely computationally expensive, with BERT-base taking 1.7 seconds to classify a text snippet on a Pixel 3 smartphone. In this work, we observe that methods such as grouped convolutions have yielded significant speedups for computer vision networks, but many of these techniques have not been adopted by NLP neural network designers. We demonstrate how to replace several operations in self-attention layers with grouped convolutions, and we use this technique in a novel network architecture called SqueezeBERT, which runs 4.3x faster than BERT-base on the Pixel 3 while achieving competitive accuracy on the GLUE test set. The SqueezeBERT code will be released.
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Nov 04, 2016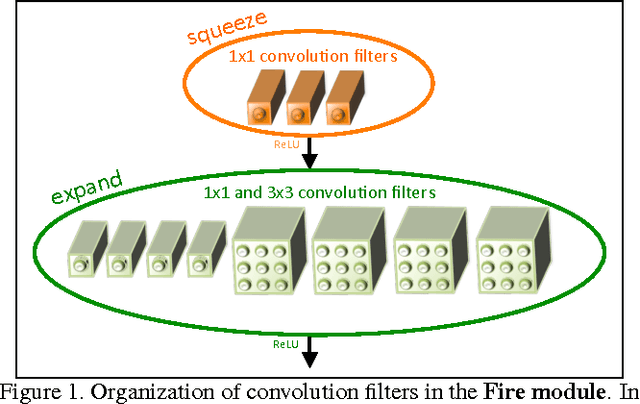
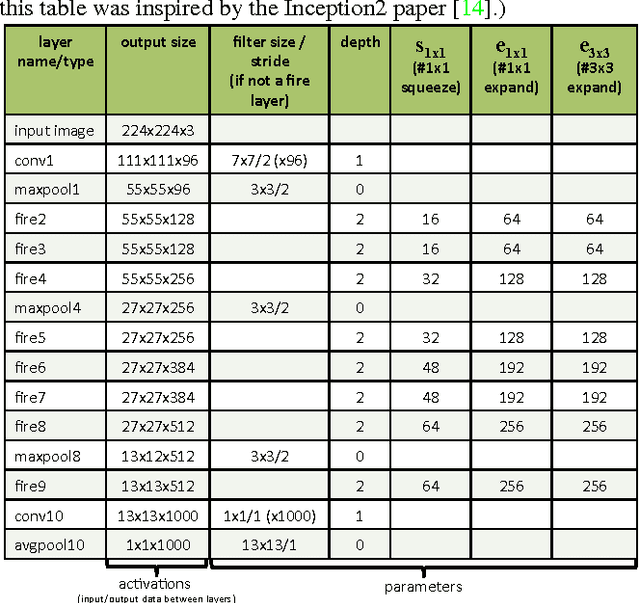
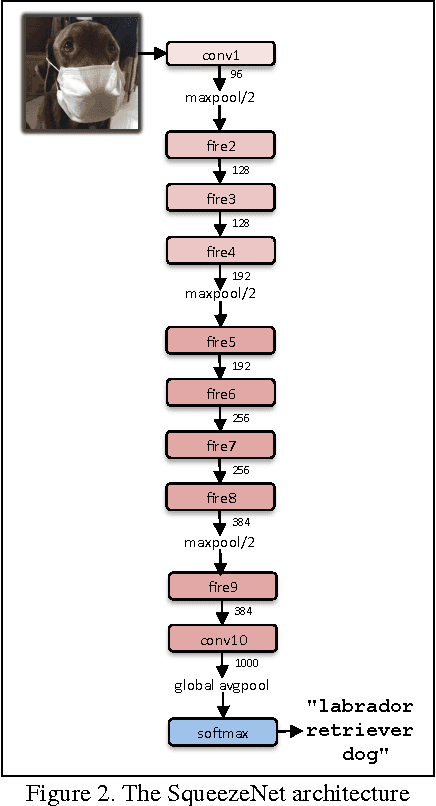
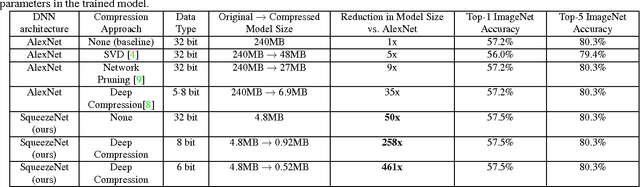
Recent research on deep neural networks has focused primarily on improving accuracy. For a given accuracy level, it is typically possible to identify multiple DNN architectures that achieve that accuracy level. With equivalent accuracy, smaller DNN architectures offer at least three advantages: (1) Smaller DNNs require less communication across servers during distributed training. (2) Smaller DNNs require less bandwidth to export a new model from the cloud to an autonomous car. (3) Smaller DNNs are more feasible to deploy on FPGAs and other hardware with limited memory. To provide all of these advantages, we propose a small DNN architecture called SqueezeNet. SqueezeNet achieves AlexNet-level accuracy on ImageNet with 50x fewer parameters. Additionally, with model compression techniques we are able to compress SqueezeNet to less than 0.5MB (510x smaller than AlexNet). The SqueezeNet architecture is available for download here: https://github.com/DeepScale/SqueezeNet
Shallow Networks for High-Accuracy Road Object-Detection
Jun 05, 2016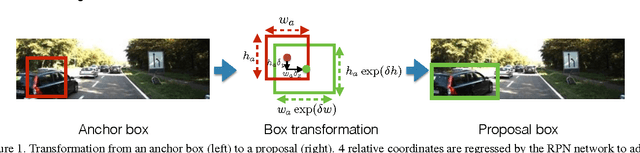

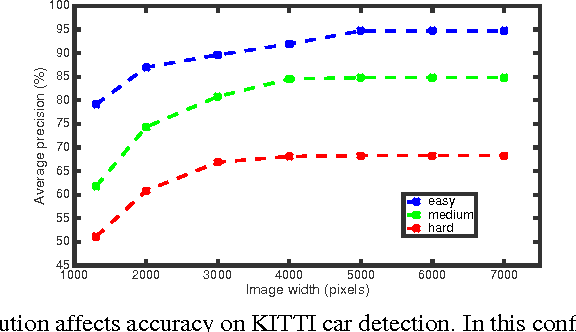

The ability to automatically detect other vehicles on the road is vital to the safety of partially-autonomous and fully-autonomous vehicles. Most of the high-accuracy techniques for this task are based on R-CNN or one of its faster variants. In the research community, much emphasis has been applied to using 3D vision or complex R-CNN variants to achieve higher accuracy. However, are there more straightforward modifications that could deliver higher accuracy? Yes. We show that increasing input image resolution (i.e. upsampling) offers up to 12 percentage-points higher accuracy compared to an off-the-shelf baseline. We also find situations where earlier/shallower layers of CNN provide higher accuracy than later/deeper layers. We further show that shallow models and upsampled images yield competitive accuracy. Our findings contrast with the current trend towards deeper and larger models to achieve high accuracy in domain specific detection tasks.
FireCaffe: near-linear acceleration of deep neural network training on compute clusters
Jan 08, 2016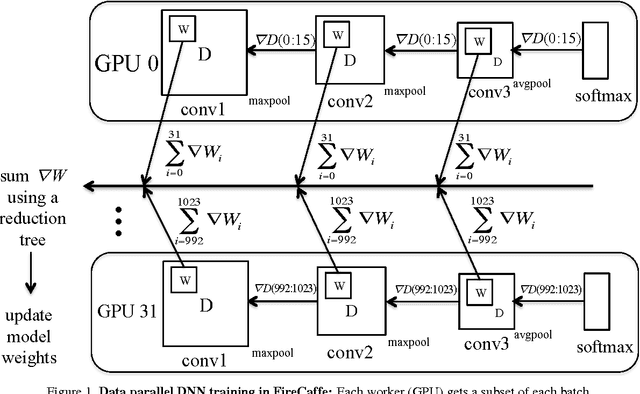

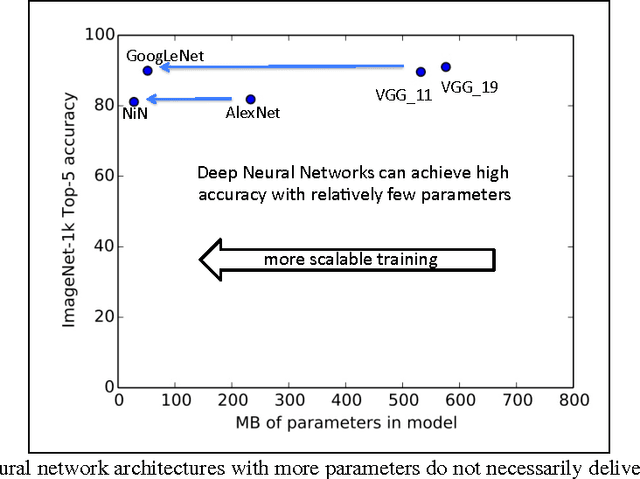
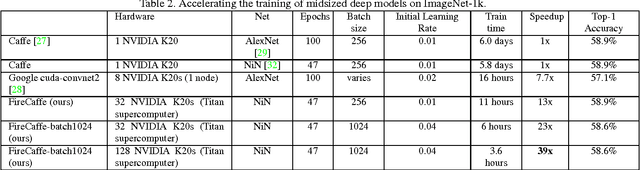
Long training times for high-accuracy deep neural networks (DNNs) impede research into new DNN architectures and slow the development of high-accuracy DNNs. In this paper we present FireCaffe, which successfully scales deep neural network training across a cluster of GPUs. We also present a number of best practices to aid in comparing advancements in methods for scaling and accelerating the training of deep neural networks. The speed and scalability of distributed algorithms is almost always limited by the overhead of communicating between servers; DNN training is not an exception to this rule. Therefore, the key consideration here is to reduce communication overhead wherever possible, while not degrading the accuracy of the DNN models that we train. Our approach has three key pillars. First, we select network hardware that achieves high bandwidth between GPU servers -- Infiniband or Cray interconnects are ideal for this. Second, we consider a number of communication algorithms, and we find that reduction trees are more efficient and scalable than the traditional parameter server approach. Third, we optionally increase the batch size to reduce the total quantity of communication during DNN training, and we identify hyperparameters that allow us to reproduce the small-batch accuracy while training with large batch sizes. When training GoogLeNet and Network-in-Network on ImageNet, we achieve a 47x and 39x speedup, respectively, when training on a cluster of 128 GPUs.
DeepLogo: Hitting Logo Recognition with the Deep Neural Network Hammer
Oct 07, 2015

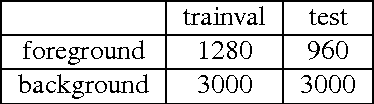
Recently, there has been a flurry of industrial activity around logo recognition, such as Ditto's service for marketers to track their brands in user-generated images, and LogoGrab's mobile app platform for logo recognition. However, relatively little academic or open-source logo recognition progress has been made in the last four years. Meanwhile, deep convolutional neural networks (DCNNs) have revolutionized a broad range of object recognition applications. In this work, we apply DCNNs to logo recognition. We propose several DCNN architectures, with which we surpass published state-of-art accuracy on a popular logo recognition dataset.